






* * * The Machine Learning Noting Series * * *
泛化误差估计
💠训练集:用于训练模型的数据集称为训练集(training set),其中的样本观测称为“袋内观测”。
💠训练误差:即经验误差,是基于训练集“袋内观测”建模并计算得到的模型误差。
例如,回归中基于训练集(样本量为)的 MSE就是典型的训练误差:
泛化误差是基于“袋外观测”的误差,而非训练误差。训练误差不能作为泛化误差的估计,原因是:①未来的新数据集都是“袋外观测”(Out of Bag,OOB);②损失函数最小原则下的模型参数估计策略决定了训练误差是基于“袋内观测”的当下最小值,是一个相对于OOB误差的偏低估计. 。因此,为满足泛化误差应基于OOB 的特点,预测建模时通常将数据集擦拆分为训练集T和测试集两部分,只抽取训练集训练模型,因此:
💠测试集:除训练集外剩余的样本观测全体称为测试集(test set)
💠测试误差:使用训练集上训练的模型在测试集上计算的误差称为测试误差(test error)
例如,回归中由训练集得到的模型,基于测试集(样本量为)的 MSE就是典型的测试误差:
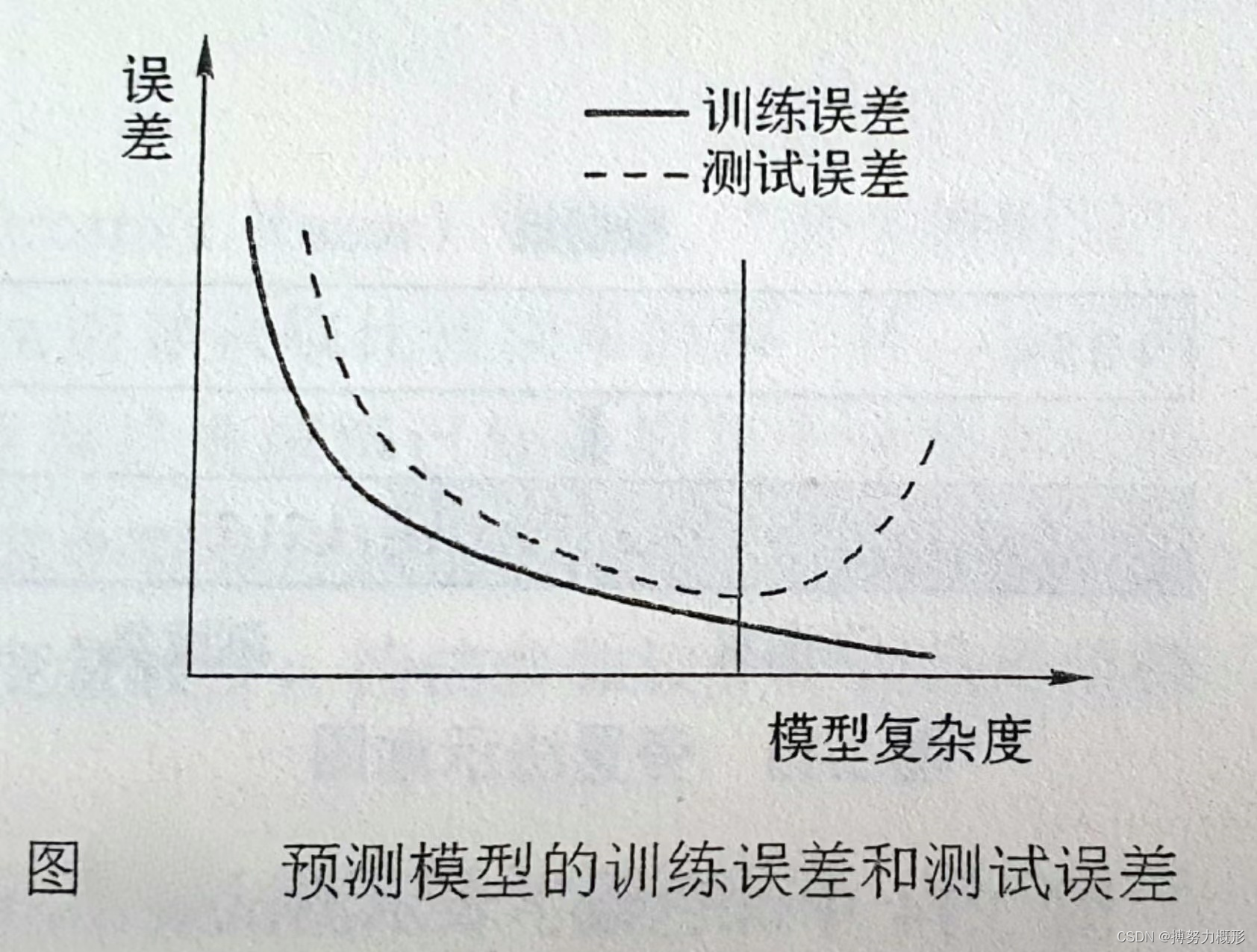
训练误差一般低于测试误差(因为它是泛化误差的乐观估计),且两者随模型复杂度增加而有不同趋势,例如下图:
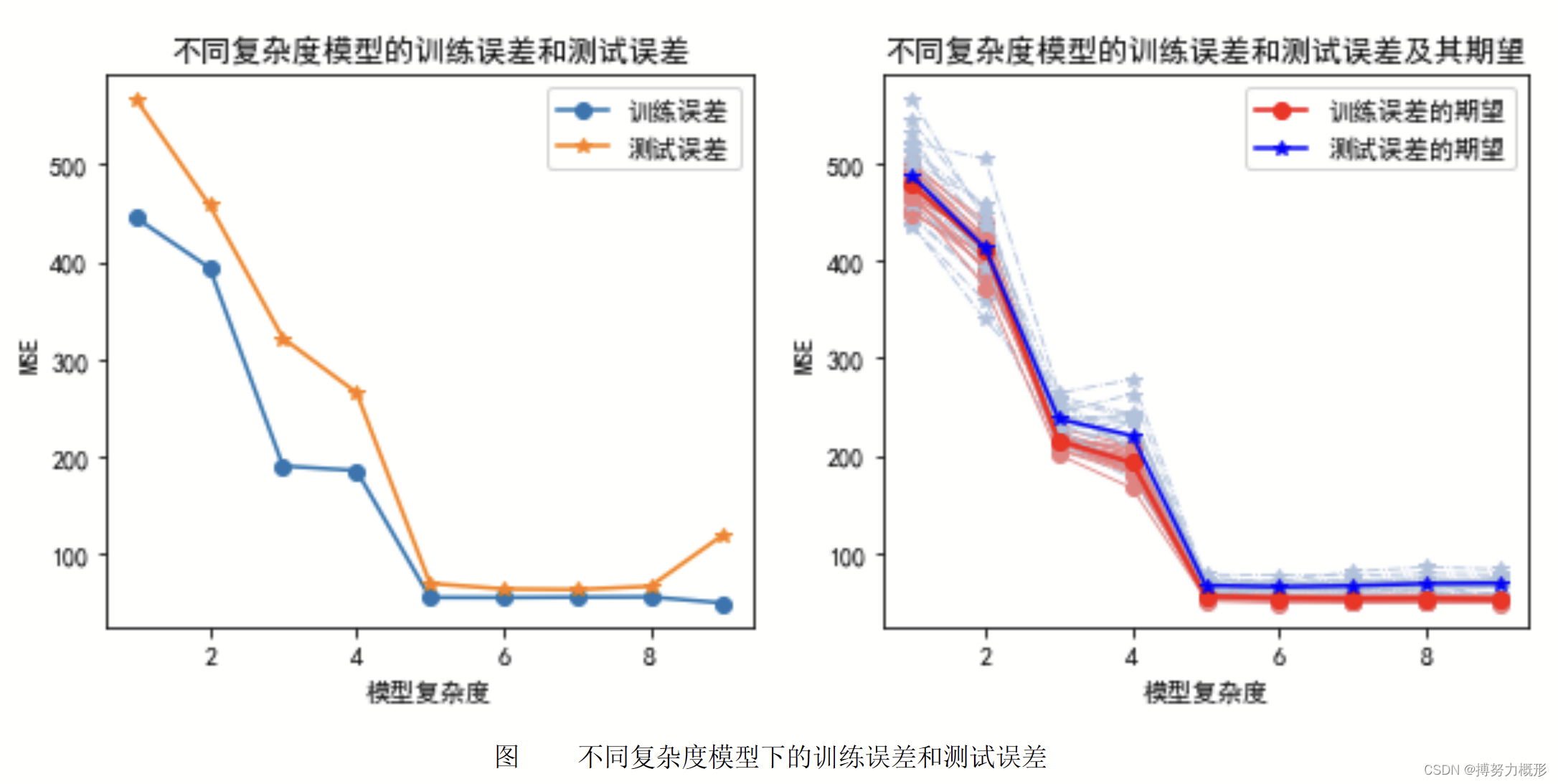
结论
① 训练误差是泛化误差的低估,应用测试误差估计泛化误差。
② 训练误差最小时测试误差不一定最小,即训练误差最小时的模型泛化能力不一定最强(如下图所示)。
③ 理想的预测模型应是泛化能力最强的模型,即测试误差最小。
数据集的划分策略
数据集划分是将所得数据集划分为训练集和测试集,测试误差会因划分方式不同存在差异。
旁置法(Hold out)
方法:将整个数据集随机划分为训练集(一般包含60%~70%样本观测)和测试集两部分。
缺点:仅适合样本量较大的情况,否则不具备“充分学习”之条件,会使测试误差偏大而高估泛化误差。此时可采用留一法。
留一法(Leave One Out,LOO)
方法:用N-1个样本观测作为训练集训练一个模型,剩余一个样本观测放入测试集。重复该过程N次,即会有N个预测模型,测试集包含N个样本。
优点:每次有N-1个样本(绝大多数样本)参与建模,在样本量较小时没有破坏“充分学习”之条件,测试误差低于旁置法,是泛化误差的近似无偏估计。
缺点:N较大时计算成本较高,此时可采用K折交叉验证法。
K折交叉验证法(Cross-Validation,CV,一般采用10折交叉验证)
方法:将数据集随机近似等分为不相交的K份,称为K折,然后将其中K-1份作为训练集训练一个模型,剩余一份放入测试集,此过程重复K次,即会有K个预测模型,测试集包含N个样本。
与留一法比较:
同:当K=N时两者相同
异:留一法每个训练集差别很小,因此是对测试误差的估计;K折交叉验证法的每个数据集可能与原数据集有较大不同,因此是对测试误差之数学期望的估计。
优点:还可用于模型选择,即可以不断调整K,从而找到使测试误差最小下的K并用于最终模型。















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









