






* * * The Machine Learning Noting Series * * *
目 录 | Content
1. 支持向量回归的基本思路与优点
ε-带与“管道”
决定“管道”宽度的可调参数ε
2. 支持向量回归的目标函数和约束条件
目标函数
约束条件
3. python实现
1. 支持向量回归的基本思路与优点
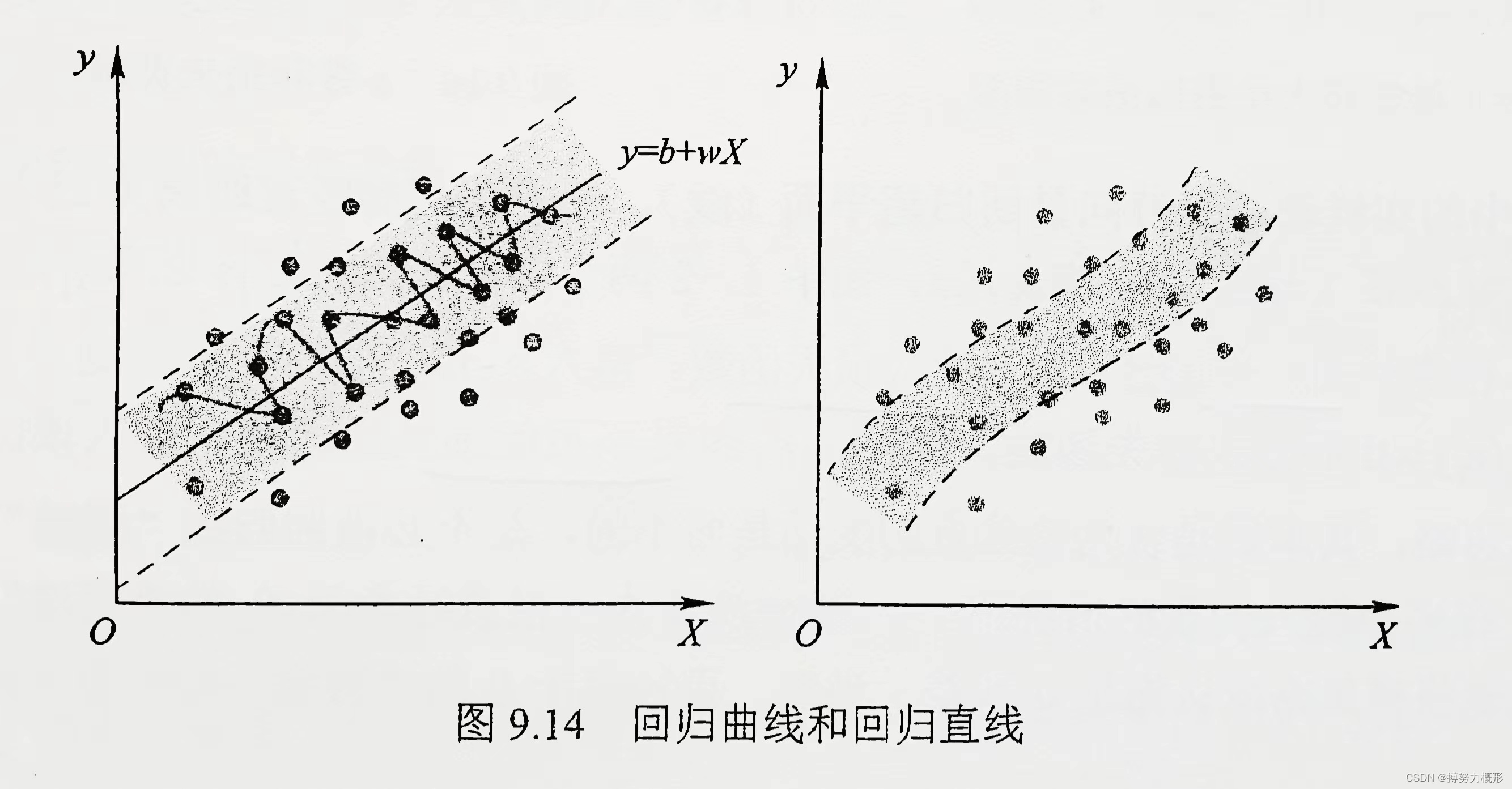
线性不可分支持向量缺点:
如上左图所示,支持向量机使用核函数给出一个弯曲多变的不规则超平面(中间的曲线即回归线)。这是一个复杂的模型,因其预测结果对训练集中数据的微小波动较为敏感,故预测的鲁棒性差且预测误差较大。
支持向量回归的思路与优点:
支持向量回归同样寻找具有最大边界的回归面。如上左图所示,两平行虚线为分类边界(其宽度可调,见下文),中间的实直线为回归线,分类边界内的点不计入损失函数,即用一条扁平化(Flatten)的平整“宽带”代替传统的“细线”去贯穿和拟合样本。当然,若数据存在较大规律性变化或者对预测误差严格要求的话,这条带宽也会随之弯曲,如上右图所示。
ε-带与“管道”
支持向量回归的根本是认为“宽带”内样本观测点的变动是微小可忽略的,此“宽带”被称为ε-带。
一般的线性回归模型以残差平方和()最小为原则求解参数,支持向量回归的主要区别在于:若样本观测
的残差
不大于实现给定的可调参数ε>0,则
不计入损失函数,损失函数对此呈不敏感“反应”。因此,样本观测
对损失函数的贡献定义为:
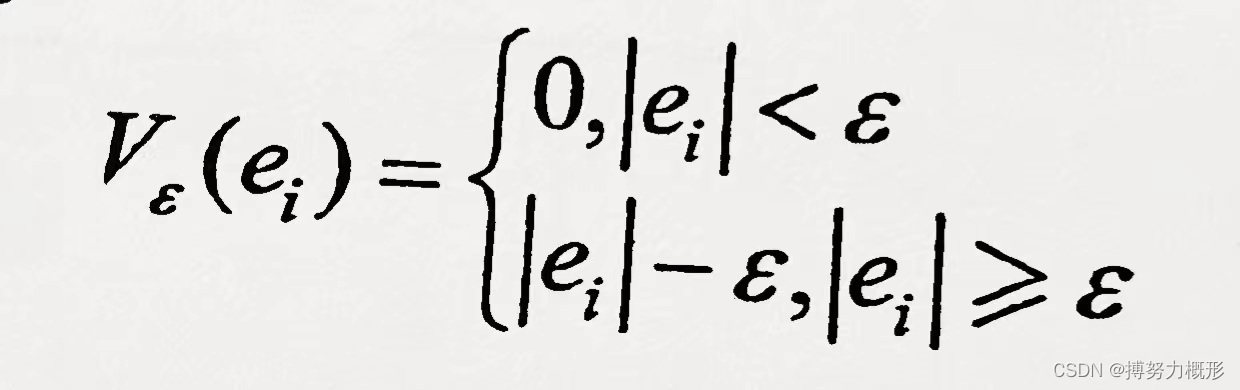
具体如下图所示,样本1和2的残差将通过计入损失函数(),而样本3因为位于ε-带中而不计入损失函数。
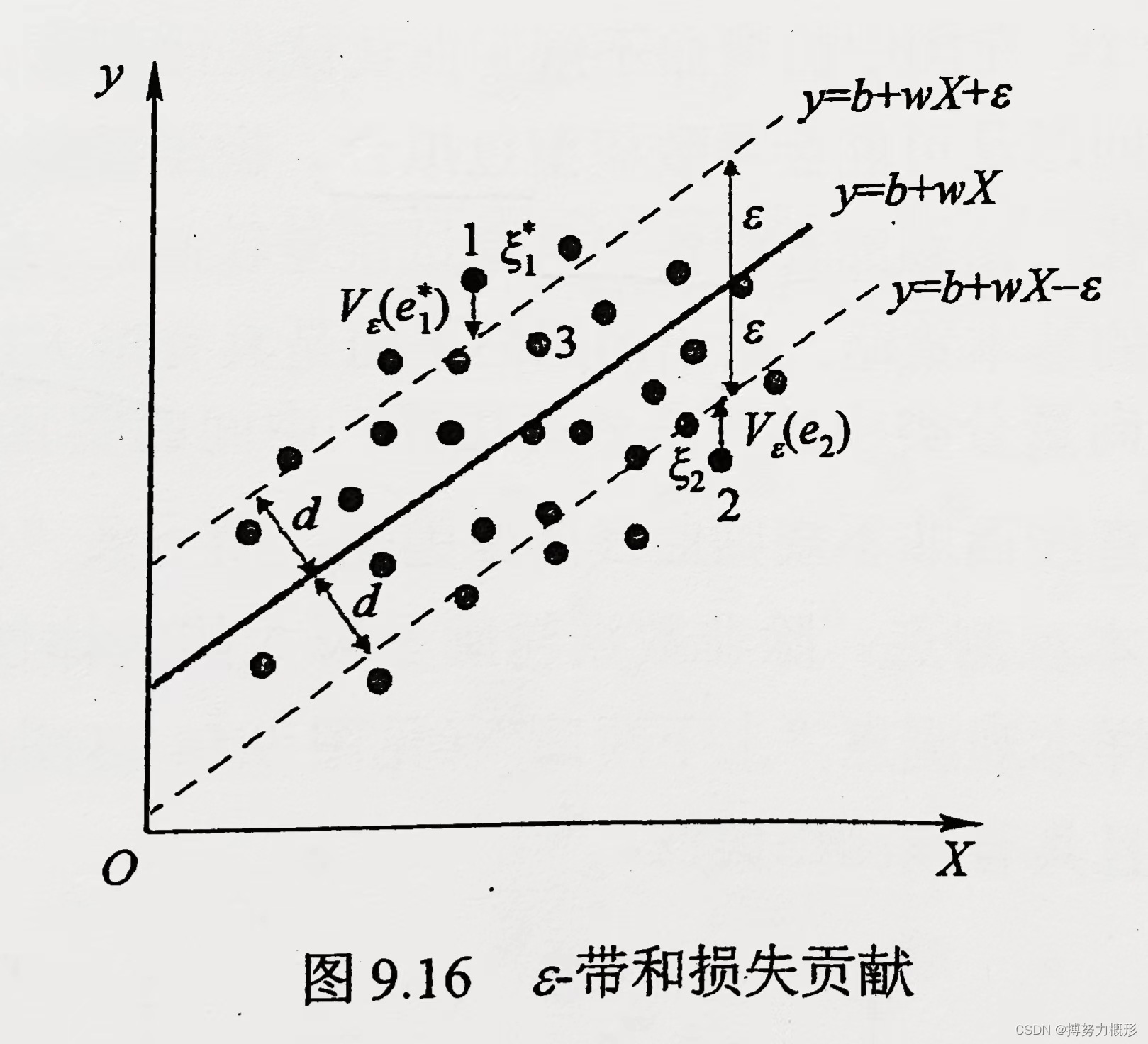
推广到多维情形,在多个输入变量情况下,ε-带会演变成一根直径大于0的“管道”,其内的样本残差将被忽略。
决定“管道”宽度的可调参数ε
参数ε可通过K-折交叉验证确定。
● 若ε过大:极端情况为“管道”过宽,则所有样本观测点均位于其内,此时损失函数为0,变为不考虑任何输入变量影响下的回归线,此模型只会输出输入变量均值,且预测误差较大,不具备实用价值。如下左图所示。
● 若ε过小:管道过窄,极端情况下所有观测点均位于管道外,模型容易过拟合、过于复杂,违背文件预测的初衷。如下右图所示。

2. 支持向量回归的目标函数和约束条件
设置松弛变量:

设置目标函数:
目标函数体现“最宽管道”和最低误差的权衡,故设置为两者相加形式:
● 上式第一项体现“最宽管道”的目标,通常希望其较小(此时管道较宽,模型鲁棒性强),但管道过宽会导致超平面位置不恰当,并使得第二项过大,模型整体误差过高;
● 上式第二项体现最低误差的目标:通常希望其较小,可通过两个方法实现:①增大第一项来减少管道宽度,但此时模型较复杂且易过拟合,②将超平面放置于最佳位置来降低第二项(通过最小化确定超平面位置和角度)。
惩罚参数C用于调整对预测误差容忍度,在管道宽度确定的前提下:● 若C较大,则目标函数倾向于最小化第二项,即超平面将努力跟随管道外部样本点变化并呈弯曲多变(复杂模型)的形态;● 若C较小,意味着允许管道外部较大的误差,此时超平面倾向于扁平化(简单模型)。C可通过K-折交叉验证确定。
约束条件


3. python实现
这里通过模拟数据,通过调整ε和C来说明两者对于支持向量回归模型结果的影响。
#导入模块
import numpy as np
from numpy import random
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.model_selection import train_test_split,KFold
import sklearn.neural_network as net
import sklearn.linear_model as LM
from scipy.stats import multivariate_normal
from sklearn.metrics import r2_score,mean_squared_error,classification_report
from sklearn import svm
import osN=100
X,Y=make_regression(n_samples=N,n_features=1,random_state=123,noise=50,bias=0)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.85, random_state=123)
plt.scatter(X_train,Y_train,s=20)
plt.scatter(X_test,Y_test,s=20,marker='*')
plt.title("100个样本观测点的SVR和线性回归")
plt.xlabel("X")
plt.ylabel("Y")
modelLM=LM.LinearRegression()
modelLM.fit(X_train,Y_train)
X[:,0].sort()
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(12,9))
for C,E,H,L in [(1,0.1,0,0),(1,100,0,1),(100,0.1,1,0),(10000,0.01,1,1)]:
modelSVR=svm.SVR(C=C,epsilon=E)
modelSVR.fit(X_train,Y_train)
axes[H,L].scatter(X_train,Y_train,s=20)
axes[H,L].scatter(X_test,Y_test,s=20,marker='*')
axes[H,L].scatter(X[modelSVR.support_],Y[modelSVR.support_],marker='o',c='b',s=120,alpha=0.2)
axes[H,L].plot(X,modelSVR.predict(X),linestyle='-',label="SVR")
axes[H,L].plot(X,modelLM.predict(X),linestyle='--',label="线性回归",linewidth=1)
axes[H,L].legend()
ytrain=modelSVR.predict(X_train)
ytest=modelSVR.predict(X_test)
axes[H,L].set_title("SVR(C=%d,epsilon=%.2f,训练MSE=%.2f,测试MSE=%.2f)"%(C,E,mean_squared_error(Y_train,ytrain),
mean_squared_error(Y_test,ytest)))
axes[H,L].set_xlabel("X")
axes[H,L].set_ylabel("Y")
axes[H,L].grid(True,linestyle='-.')
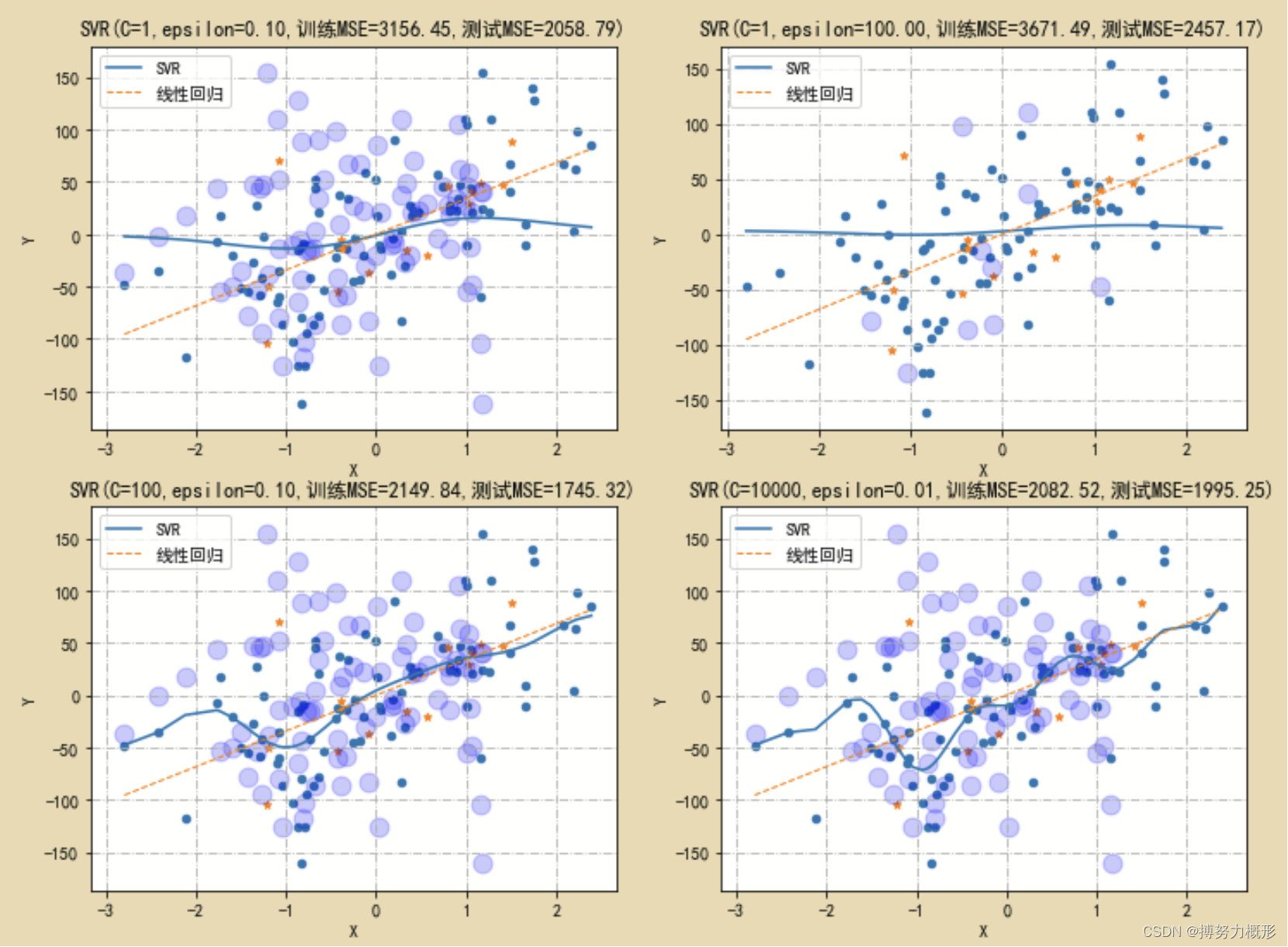
结果如下图所示:第一行中右图ε较大,因此所允许的误差上限更大,模型更简单更扁平,且管道外的支持向量较少;第一列中下图的C较大,因而模型更不扁平、回归线更复杂、训练误差更低;右下角的C最大,ε最小,因此模型最复杂,训练误差最小,但测试误差大于左下图,说明模型出现过拟合。
参考文献
《Python机器学习 数据建模与分析》,薛薇 等/著















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









