






* * * The Machine Learning Noting Series * * *
导航
1、解决线性不可分问题的一般解决方式
2、支持向量分类克服维灾难的途径
4、核函数与线性变换
3、python实现
1、解决线性不可分问题的一般解决方式
核心思想:
将低维空间中线性不可分问题,通过恰当的非线性变换转化为高维空间中的线性可分(使用曲面)问题。
例如,将X1,X2这一二维空间上线性不可分的严格不能,进行非线性变换称X1,X2,Z三维空间上的分布,而在三维空间上就可以找到一个平面将两类分开。
建模思路:
1)映射。使用特定的非线性映射函数,将原来低维空间上的点映射到M维空间
上;

2)寻找超平面。
为找到低维空间中可将两类分开的分类曲线(曲面),需到高维空间中寻找与其对应的平面。
缺陷:
在高维空间中会出现维灾难(Curse of Dimensionality):因超平面待估参数过多而导致的计算问题或无法估计。
原因:对原p维空间通过d阶交乘变换到高维空间后,待估参数变为个。例如,当p=10,d=3时,需估计220个参数,可见高维将导致计算复杂度急剧增加,而在小样本下几乎无法实现。
2、支持向量机克服维灾难的途径
分类结果取决于点积
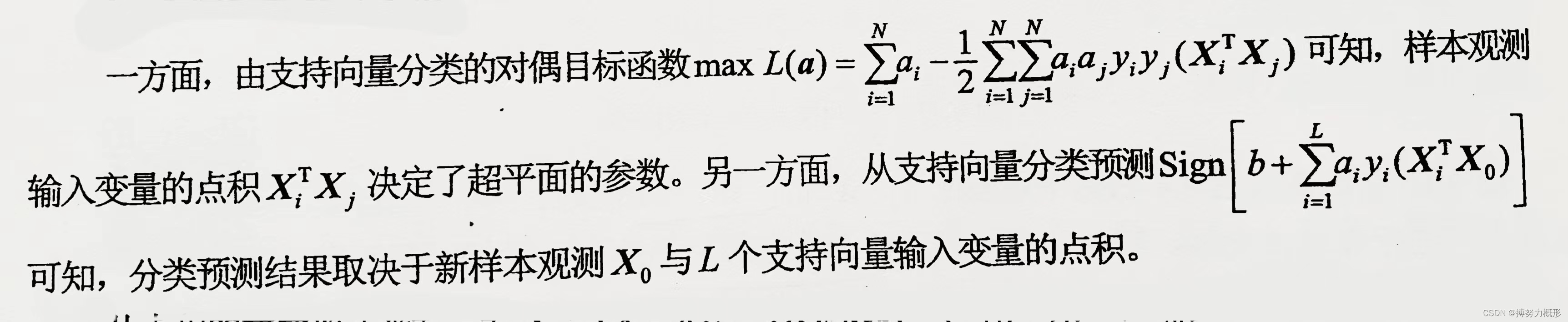
点积度量了两样本点相似性

两点空间位置关系代表相似性,由点积度量

3、核函数与线性变换
非线性可分下支持向量分类的基本思路是,找到一个函数,若它基于低维空间的特征就能度量出两点Xi,Xj在高维空间中的位置关系,即其函数值恰好等于变换后的点积:
则有对偶目标函数式(9.21)成立:

常见核函数


3、python实现
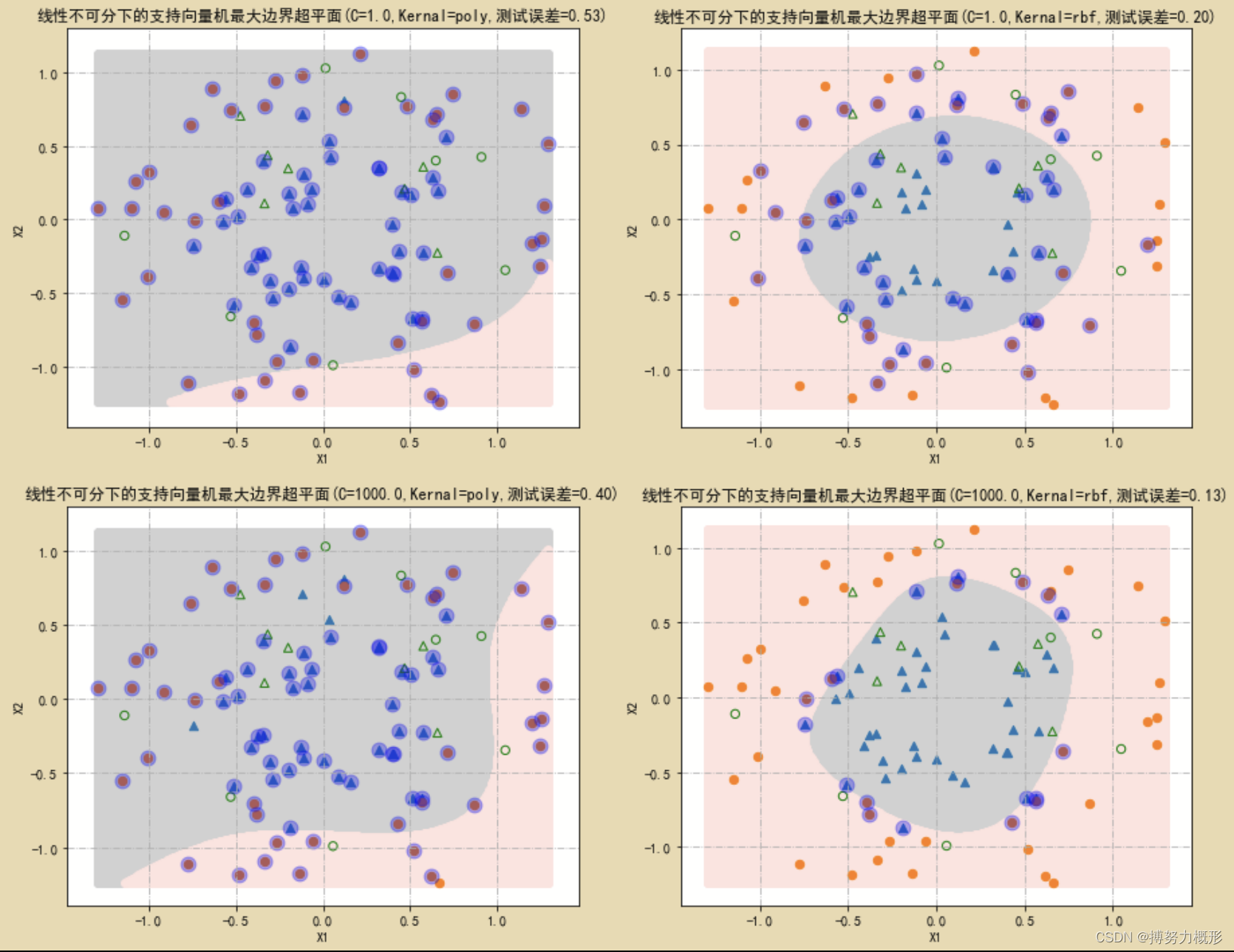
基于模拟数据,使用多项式核和径向基核,在不同惩罚参数C下进行分类。
#导入模块
import numpy as np
from numpy import random
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.model_selection import train_test_split,KFold
import sklearn.neural_network as net
import sklearn.linear_model as LM
from scipy.stats import multivariate_normal
from sklearn.metrics import r2_score,mean_squared_error,classification_report
from sklearn import svm
import os# 采用不同核函数和惩罚参数C进行分类
N=100
X,Y=make_circles(n_samples=N,noise=0.2,factor=0.5,random_state=123)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.85, random_state=1)
X1,X2= np.meshgrid(np.linspace(X_train[:,0].min(),X_train[:,0].max(),500),np.linspace(X_train[:,1].min(),X_train[:,1].max(),500))
X0=np.hstack((X1.reshape(len(X1)*len(X2),1),X2.reshape(len(X1)*len(X2),1)))
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(15,12))
for C,ker,H,L in [(1,'poly',0,0),(1,'rbf',0,1),(1000,'poly',1,0),(1000,'rbf',1,1)]:
modelSVC=svm.SVC(kernel=ker,random_state=123,C=C)
modelSVC.fit(X_train,Y_train)
Y0=modelSVC.predict(X0)
axes[H,L].scatter(X0[np.where(Y0==1),0],X0[np.where(Y0==1),1],c='lightgray')
axes[H,L].scatter(X0[np.where(Y0==0),0],X0[np.where(Y0==0),1],c='mistyrose')
for k,m in [(1,'^'),(0,'o')]:
axes[H,L].scatter(X_train[Y_train==k,0],X_train[Y_train==k,1],marker=m,s=40)
axes[H,L].scatter(X_test[Y_test==k,0],X_test[Y_test==k,1],marker=m,s=40,c='',edgecolors='g')
axes[H,L].scatter(modelSVC.support_vectors_[:,0],modelSVC.support_vectors_[:,1],marker='o',c='b',s=120,alpha=0.3)
axes[H,L].set_xlabel("X1")
axes[H,L].set_ylabel("X2")
axes[H,L].set_title("线性不可分下的支持向量机最大边界超平面(C=%.1f,Kernal=%s,测试误差=%.2f)"%(C,ker,1-modelSVC.score(X_test,Y_test)))
axes[H,L].grid(True,linestyle='-.')分类结果如下图所示:其中深色和浅色分别对应两个预测类别区域。大圆圈圈住的点为支持向量。左侧两图使用3阶多项式核。可以看出,惩罚参数C越大,将导致分类边界更加“努力”拟合边界点,从而呈现出更多的弯曲变化。从样本分布特点和测试误差来看,这里应采用径向基核。

参考文献
《Python机器学习 数据建模与分析》,薛薇 等/著















 4741
4741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









