







目录
def build_loaders(cfgs: TotalConfigs, is_total=False):
train_dataset = CaptionDataset(cfgs=cfgs, mode='train', save_on_disk=False, is_total=is_total)
valid_dataset = CaptionDataset(cfgs=cfgs, mode='valid', save_on_disk=False, is_total=is_total)
test_dataset = CaptionDataset(cfgs=cfgs, mode='test', save_on_disk=True, is_total=is_total)
train_loader = DataLoader(dataset=train_dataset, batch_size=cfgs.bsz, shuffle=True,
collate_fn=collate_fn_caption, num_workers=0)
valid_loader = DataLoader(dataset=valid_dataset, batch_size=cfgs.bsz, shuffle=True,
collate_fn=collate_fn_caption, num_workers=0)
test_loader = DataLoader(dataset=test_dataset, batch_size=cfgs.bsz, shuffle=False,
collate_fn=collate_fn_caption, num_workers=0)
return train_loader, valid_loader, test_loader
class CaptionDataset(Dataset):
def __init__(self, cfgs: TotalConfigs, mode, save_on_disk=False, is_total=False):
"""
Args:
args: configurations.
mode: train/valid/test.
save_on_disk: whether save the prediction on disk or not.
True->Each video only appears once.
False->The number of times each video appears depends on
the number of its corresponding captions.
"""
super(CaptionDataset, self).__init__()
self.mode = mode
self.save_on_disk = save_on_disk
self.is_total = is_total
sample_numb = cfgs.sample_numb # how many frames are sampled to perform video captioning?
max_caption_len = cfgs.test.max_caption_len
# language part
vid2language_path = cfgs.data.vid2language_path
vid2fillmask_path = cfgs.data.vid2fillmask_path
# visual part
backbone2d_path = cfgs.data.backbone2d_path_tpl.format(mode)
backbone3d_path = cfgs.data.backbone3d_path_tpl.format(mode)
objects_path = cfgs.data.objects_path_tpl.format(mode)
# dataset split part
videos_split_path = cfgs.data.videos_split_path_tpl.format(mode)
with open(videos_split_path, 'rb') as f:
video_ids = pickle.load(f)
self.video_ids = video_ids
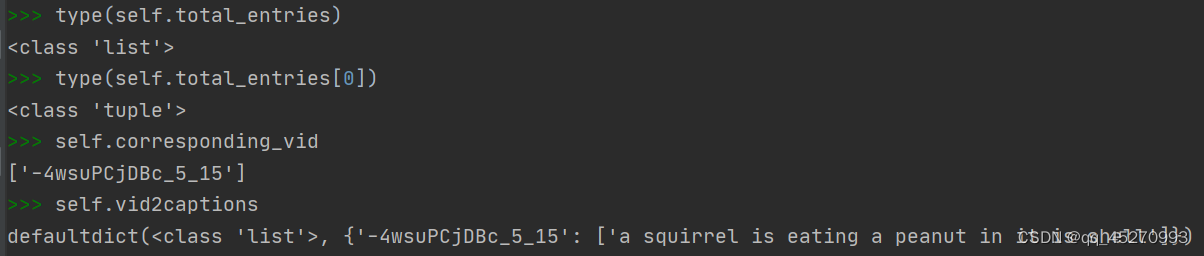
self.corresponding_vid = []
self.backbone_2d_dict = {}
self.backbone_3d_dict = {}
self.objects_dict = {}
self.total_entries = [] # (numberic words, original caption)
self.vid2captions = defaultdict(list)
# feature 2d dict
with h5py.File(backbone2d_path, 'r') as f:
for vid in video_ids:
temp_feat = f[vid][()]
sampled_idxs = np.linspace(0, len(temp_feat) - 1, sample_numb, dtype=int)
self.backbone_2d_dict[vid] = temp_feat[sampled_idxs]
# feature 3d dict
with h5py.File(backbone3d_path, 'r') as f:
for vid in video_ids:
temp_feat = f[vid][()]
sampled_idxs = np.linspace(0, len(temp_feat) - 1, sample_numb, dtype=int)
self.backbone_3d_dict[vid] = temp_feat[sampled_idxs]
# feature object dict
with h5py.File(objects_path, 'r') as f:
for vid in video_ids:
temp_feat = f[vid]['feats'][()]
self.objects_dict[vid] = temp_feat
with open(vid2language_path, 'rb') as f:
self.vid2language = pickle.load(f)
if cfgs.train.lambda_soft > 0 and not save_on_disk:
with open(vid2fillmask_path, 'rb') as f:
self.vid2fillmask = pickle.load(f)
for vid in video_ids:
fillmask_dict = self.vid2fillmask[vid] if cfgs.train.lambda_soft > 0 and not save_on_disk and vid in self.vid2fillmask else None
for item in self.vid2language[vid]:
caption, numberic_cap, vp_semantics, caption_semantics, nouns, nouns_vec = item
current_mask = fillmask_dict[caption] if fillmask_dict is not None else None
vocab_ids, vocab_probs, fillmasks = get_ids_and_probs(current_mask, max_caption_len)
self.total_entries.append((numberic_cap, vp_semantics, caption_semantics, nouns, nouns_vec, vocab_ids, vocab_probs, fillmasks))
self.corresponding_vid.append(vid)
self.vid2captions[vid].append(caption)
print('{} dataset complete'.format(self.mode))
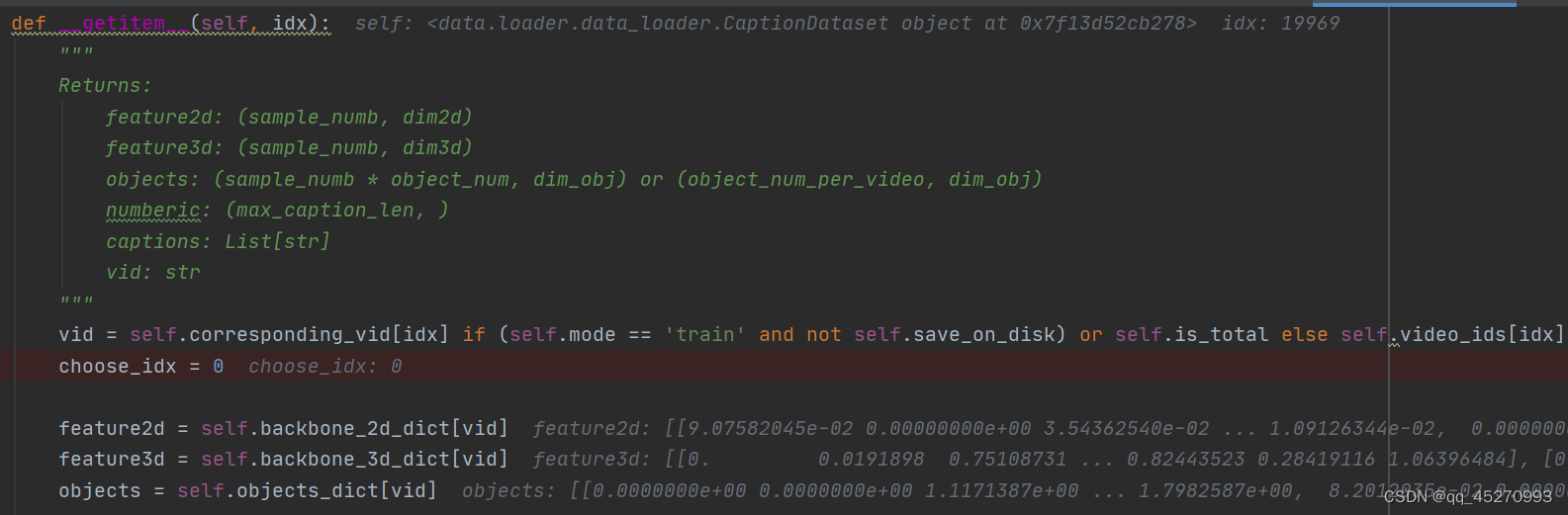
def __getitem__(self, idx):
"""
Returns:
feature2d: (sample_numb, dim2d)
feature3d: (sample_numb, dim3d)
objects: (sample_numb * object_num, dim_obj) or (object_num_per_video, dim_obj)
numberic: (max_caption_len, )
captions: List[str]
vid: str
"""
vid = self.corresponding_vid[idx] if (self.mode == 'train' and not self.save_on_disk) or self.is_total else self.video_ids[idx]
choose_idx = 0
feature2d = self.backbone_2d_dict[vid]
feature3d = self.backbone_3d_dict[vid]
objects = self.objects_dict[vid]
if (self.mode == 'train' and not self.save_on_disk) or self.is_total:
numberic_cap, vp_semantics, caption_semantics, nouns, nouns_vec, vocab_ids, vocab_probs, fillmasks = self.total_entries[idx]
else:
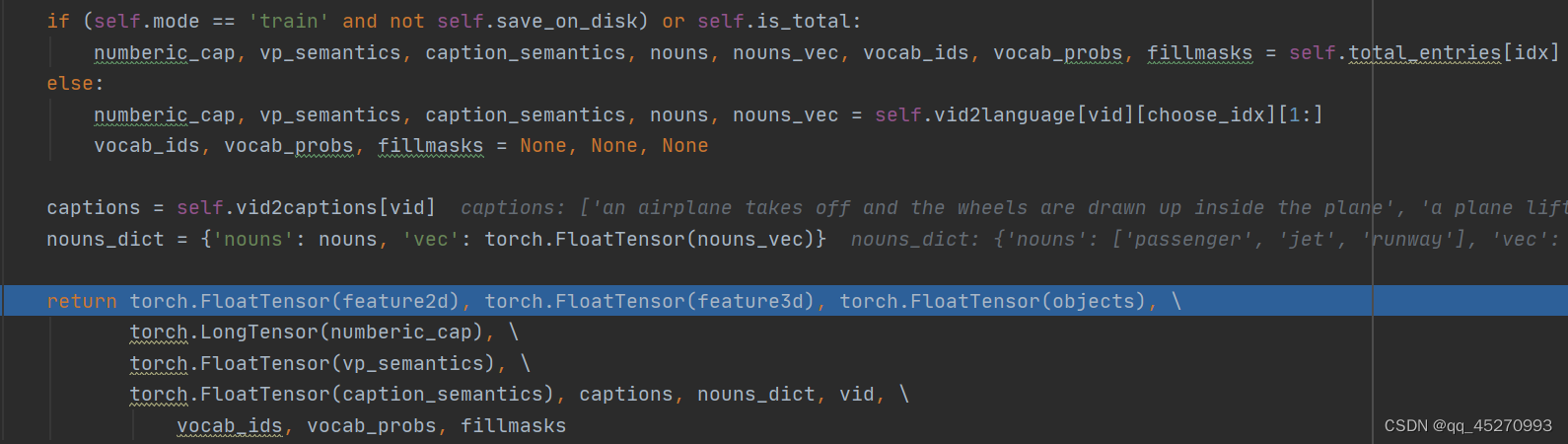
numberic_cap, vp_semantics, caption_semantics, nouns, nouns_vec = self.vid2language[vid][choose_idx][1:]
vocab_ids, vocab_probs, fillmasks = None, None, None
captions = self.vid2captions[vid]
nouns_dict = {'nouns': nouns, 'vec': torch.FloatTensor(nouns_vec)}
return torch.FloatTensor(feature2d), torch.FloatTensor(feature3d), torch.FloatTensor(objects), \
torch.LongTensor(numberic_cap), \
torch.FloatTensor(vp_semantics), \
torch.FloatTensor(caption_semantics), captions, nouns_dict, vid, \
vocab_ids, vocab_probs, fillmasks
def __len__(self):
if (self.mode == 'train' and not self.save_on_disk) or self.is_total:
return len(self.total_entries)
else:
return len(self.video_ids)
逐行分析
当参数设置为mode=‘train’, save_on_disk=False, is_total=False:
with open(videos_split_path, 'rb') as f:
video_ids = pickle.load(f)
加载MSVD_train_list.pkl文件,self.video_ids为包含所有训练集vid且vid数目为1200的一个列表。
建立一系列空字典,空列表
with h5py.File(backbone2d_path, 'r') as f:
for vid in video_ids:
temp_feat = f[vid][()]
sampled_idxs = np.linspace(0, len(temp_feat) - 1, sample_numb, dtype=int)
self.backbone_2d_dict[vid] = temp_feat[sampled_idxs]
2d feature 字典
加载MSVD_inceptionresnetv2_train.hdf5文件(存储2d feature的字典,格式为{vid:2d feature}),遍历vid,temp_feat为vid对应的2d feature。当vid为’-4wsuPCjDBc_5_15’,temp_feat的shape为(57,1536)。sampled_idxs是存储均匀抽取15帧的序号的一个列表,temp_feat[sampled_idxs]是对应15帧的2d feature,shape为(15,1536)。self.backbone_2d_dict添加vid对应的15帧特征,是字典,格式为{vid:temp_feat[sampled_idxs]}。
with h5py.File(backbone3d_path, 'r') as f:
for vid in video_ids:
temp_feat = f[vid][()]
sampled_idxs = np.linspace(0, len(temp_feat) - 1, sample_numb, dtype=int)
self.backbone_3d_dict[vid] = temp_feat[sampled_idxs]
3d feature 字典
同理,加载MSVD_C3D_train.hdf5文件,最后self.backbone_3d_dict存储vid对应的15个关键帧特征,shape为(15,2048),格式为{vid:temp_feat[sampled_idxs]}。
with h5py.File(objects_path, 'r') as f:
for vid in video_ids:
temp_feat = f[vid]['feats'][()]
self.objects_dict[vid] = temp_feat
object feature 字典
加载MSVD_vg_objects_train.hdf5文件,self.objects_dict存储vid对应的object特征,temp_feat.shape为(num_object,2048),不同vid的num_object不同,self.objects_dict格式为{vid:temp_feat}。
with open(vid2language_path, 'rb') as f:
self.vid2language = pickle.load(f)
加载vid2language.pkl,self.vid2language为字典,key为vid,数目为1970,覆盖了整个数据集。
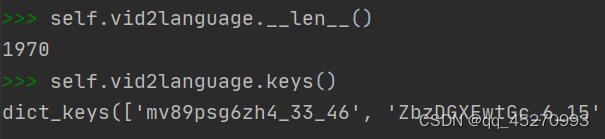

vid对应的value是一个二维列表。可以看到value第一个维度代表的是句子的数目。每一维包含6种信息。分别是caption, numberic_cap, vp_semantics, caption_semantics, nouns, nouns_vec。
if cfgs.train.lambda_soft > 0 and not save_on_disk:
with open(vid2fillmask_path, 'rb') as f:
self.vid2fillmask = pickle.load(f)
加载vid2fillmask_MSVD.pkl,self.vid2fillmask是字典,key为vid,长度为1200,也就是训练集的部分,value仍然是一个字典fillmask_dict。
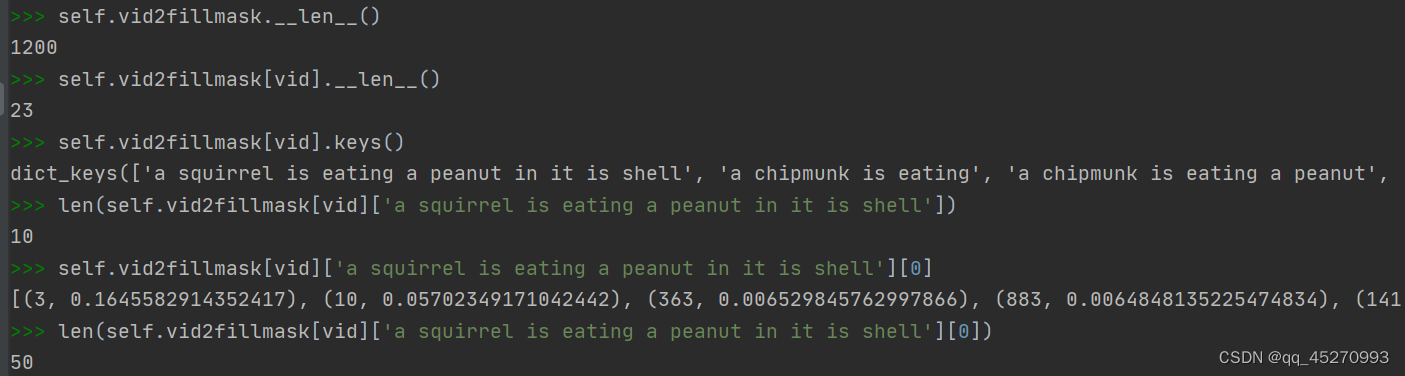
fillmask_dict的key为caption,也就是对应的句子字符串,value为一个二维列表,内容为二维元组。第一维的数目为对应的caption的单词数目,第二维的维度为50,也就是覆盖了50个可能的单词。元组包含2个值,第一个值为单词表的索引,第二个值为概率。如下所示:

除了a,is等少数简单单词有一定概率保留,其余词会被mask掉,也就是用错误的词覆盖。
for vid in video_ids:
fillmask_dict = self.vid2fillmask[vid] if cfgs.train.lambda_soft > 0 and not save_on_disk and vid in self.vid2fillmask else None
for item in self.vid2language[vid]:
caption, numberic_cap, vp_semantics, caption_semantics, nouns, nouns_vec = item
current_mask = fillmask_dict[caption] if fillmask_dict is not None else None
vocab_ids, vocab_probs, fillmasks = get_ids_and_probs(current_mask, max_caption_len)
self.total_entries.append((numberic_cap, vp_semantics, caption_semantics, nouns, nouns_vec, vocab_ids, vocab_probs, fillmasks))
self.corresponding_vid.append(vid)
self.vid2captions[vid].append(caption)
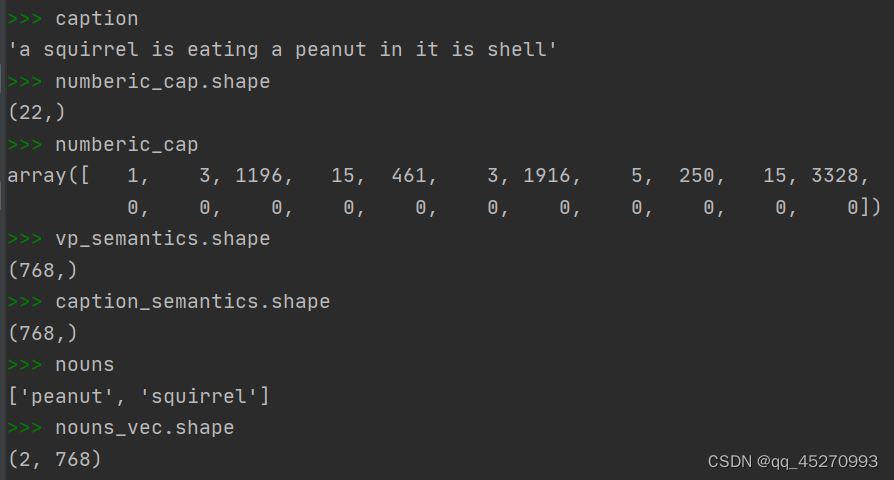
caption, numberic_cap, vp_semantics, caption_semantics, nouns, nouns_vec的值。
current_mask,也就是是上面提到的fillmask_dict的value,也就是每句caption对应的mask。
接下来讲解get_ids_and_probs方法。
def get_ids_and_probs(fillmask_steps, max_caption_len):
if fillmask_steps is None:
return None, None, None
ret_ids, ret_probs = [], []
ret_mask = torch.zeros(max_caption_len)
for step in fillmask_steps:
step_ids, step_probs = zip(*step)
step_ids, step_probs = torch.Tensor(step_ids).long(), torch.Tensor(step_probs).float()
ret_ids.append(step_ids)
ret_probs.append(step_probs)
gap = max_caption_len - len(fillmask_steps)
for i in range(gap):
zero_ids, zero_probs = torch.zeros(50).long(), torch.zeros(50).float()
ret_ids.append(zero_ids)
ret_probs.append(zero_probs)
ret_ids = torch.cat([item[None, ...] for item in ret_ids], dim=0)
ret_probs = torch.cat([item[None, ...] for item in ret_probs], dim=0)
ret_mask[:len(fillmask_steps)] = 1
return ret_ids, ret_probs, ret_mask
首先返回step_ids,step_probs,也就是单词索引和概率。ret_ids, ret_probs为两个列表,覆盖了整个句子。元素为step_ids, step_probs。

len(ret_ids),len(ret_probs)为22,添加了一些id为0,概率为0的元素。

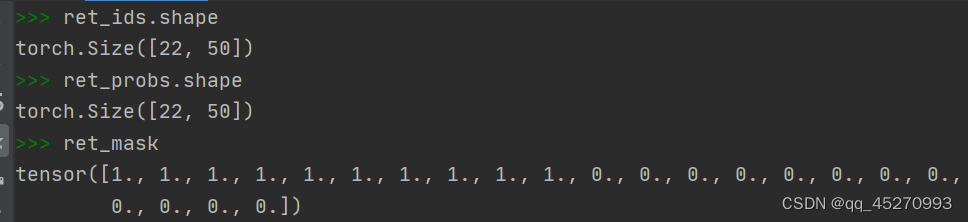
以tensor的格式返回。
也就是vocab_ids, vocab_probs, fillmasks。

接着说dataloader

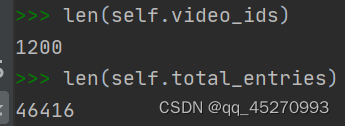
train_dataset的len为46416,接下来调用train_dataset.getitem(self, idx)处理索引idx对应的数据
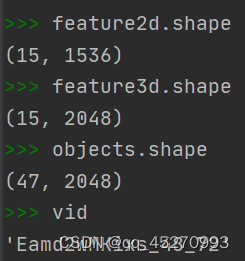
最终返回以下结果
重写Dataloader的collate_fn方法,因为batch中的数据size不一致,也就是object_num不一致。
def collate_fn_caption(batch):
feature2ds, feature3ds, objects, numberic_caps, \
vp_semantics, caption_semantics, captions, nouns_dict_list, vids, \
vocab_ids, vocab_probs, fillmasks = zip(*batch)
bsz, obj_dim = len(feature2ds), objects[0].shape[-1]
longest_objects_num = max([item.shape[0] for item in objects])
ret_objects = torch.zeros([bsz, longest_objects_num, obj_dim])
ret_objects_mask = torch.ones([bsz, longest_objects_num])
for i in range(bsz):
ret_objects[i, :objects[i].shape[0], :] = objects[i]
ret_objects_mask[i, :objects[i].shape[0]] = 0.0
feature2ds = torch.cat([item[None, ...] for item in feature2ds], dim=0) # (bsz, sample_numb, dim_2d)
feature3ds = torch.cat([item[None, ...] for item in feature3ds], dim=0) # (bsz, sample_numb, dim_3d)
vp_semantics = torch.cat([item[None, ...] for item in vp_semantics], dim=0) # (bsz, dim_sem)
caption_semantics = torch.cat([item[None, ...] for item in caption_semantics], dim=0) # (bsz, dim_sem)
numberic_caps = torch.cat([item[None, ...] for item in numberic_caps], dim=0) # (bsz, seq_len)
masks = numberic_caps > 0
captions = [item for item in captions]
nouns = list(nouns_dict_list)
vids = list(vids)
vocab_ids = torch.cat([item[None, ...] for item in vocab_ids], dim=0).long() if vocab_ids[0] is not None else None # (bsz, seq_len, 50)
vocab_probs = torch.cat([item[None, ...] for item in vocab_probs], dim=0).float() if vocab_probs[0] is not None else None # (bsz, seq_len, 50)
fillmasks = torch.cat([item[None, ...] for item in fillmasks], dim=0).float() if fillmasks[0] is not None else None # (bsz, seq_len)
return feature2ds.float(), feature3ds.float(), ret_objects.float(), ret_objects_mask.float(), \
vp_semantics.float(), caption_semantics.float(), \
numberic_caps.long(), masks.float(), captions, nouns, vids, \
vocab_ids, vocab_probs, fillmasks
主要的操作,取batch中object_num最大的数,将batch中所有数据保持一致,然后补0。
最后返回14个值
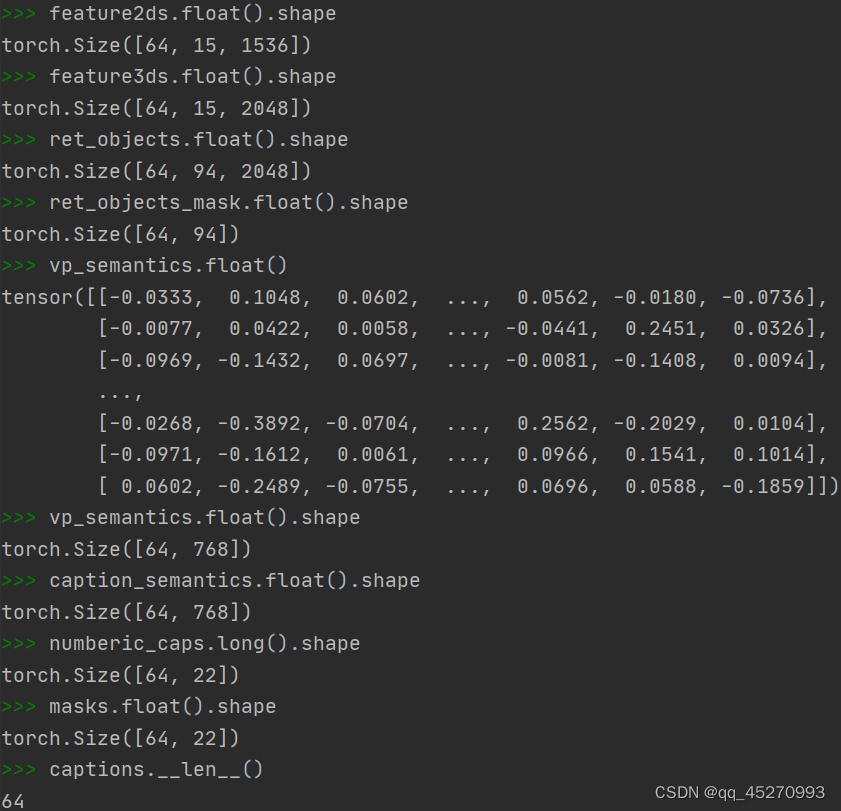
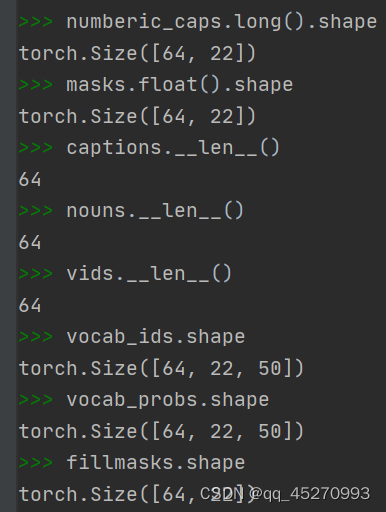
numberic_caps为索引,第一个值为1,即,起始符。
masks和numberic_caps对应。
vocab_ids不包含起始符。
fillmasks和vocab_ids对应。
















 4767
4767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









