







老年代的担保机制:当一个大对象分配不到young区的时候就会分配到老年代,当young gc后仍有大量对象存活,也需要老年代进行分配担保,把survivor无法容纳的对象直接送入老年代。默认2:1(9:1)
增量回收:无论是标记清除-标记复制、标记整理(随机(双指针)、线性、滑动(Lisp2))算法,都类似于大扫除,增量回收是与运用程序交替回收,三色标记算法为例子。
hotspot每个垃圾收集器都会STW
三色标记:
并发导致的
多标-浮动垃圾
本应该回收,但是没有回收
当成黑色的,下一轮再回收
漏标-读写屏障(保证在并发的过程中,对象的引用更新不会导致某些对象错过标记)
1、灰色断开白色,灰色引用发生了变化 原始快照,记录下删除引用,再以灰色对象为根,重新扫描 G1
2、黑色引用上面的同一白色 增量更新,把这个引用记录下来,并发结束后以黑色对象为根重新扫描 CMS
两个要同时满足,才满足漏标的情况
SERIAL:单核性能高,没有线程上下文切换代价 标记复制
SERIALOLD:标记整理
ParNew:serial多线程版本,标记复制,多线程减小stw时间
parallel scavenge:关注吞吐量
parallel old:吞吐量 标记整理
垃圾回收算法:
- 标记清除算法
- 找出需要回收的对象,并且标记
- 清除被标记的对象,释放内存空间
- 缺点:大量空间碎片,标记和清除效率都很低
- 算法:首次适应算法、最佳适应算法、最差适应算法(分配最大的分块)
- 标记复制算法
- 将内存划分出两块相等的区域,一块使用完了就拷贝到另外一块,空间利用率比较低
- 标记整理算法
- 标记清除的基础上再多了整理
- 随机整理
- 与刚开始的排列关系以及引用关系无关
- 双指针整理算法:先移动位置在更新标记
 前面预估大小,后面找对象判断大小,留出空间
前面预估大小,后面找对象判断大小,留出空间
- 线性整理
- 将有关联的对象放在一起
- 滑动整理
- 按照原有的顺序进行整理
- Lisp2:三指针算法,Free留位置,Scan找存活对象,第二次更新对象地址,第三次移动对象,需要额外空间存储
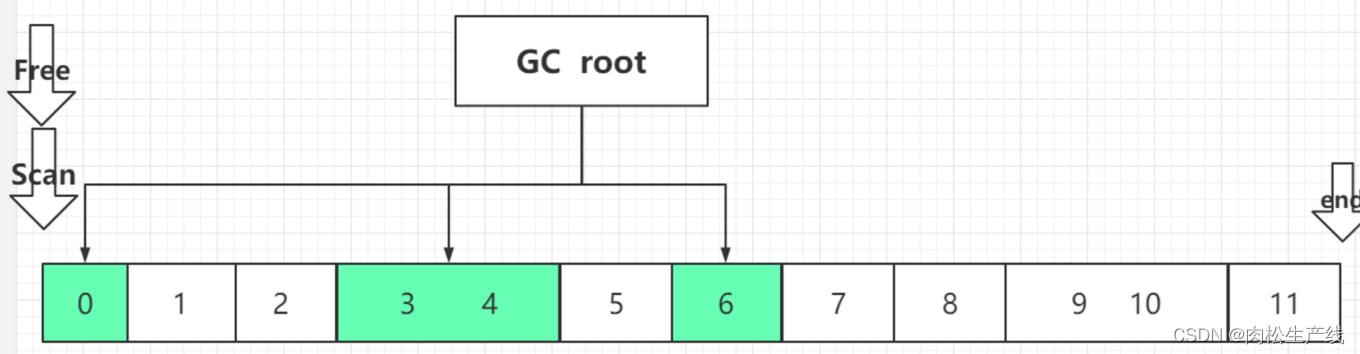
- 随机整理
- 标记清除的基础上再多了整理
CMS:最短停顿时间,标记清除算法!!!!内存碎片 CMS和paraller old可以一起使用
大量空间碎片,吞吐量低
- 初始标记:找到所有GCROOT STW,并且找到与之相关联的第一个对象
- 并发标记:找到引用链上所有节点(并发),此时有个问题,如果老年代的对象被新生代引用了,该怎么办,结合CMS目的是最短停顿时间,那就先进行一次young gc
- 并发预处理:
- 可中断的预处理:必须重新扫描新生代,但是新生代不清理对象很多,所以minor gc一下,预处理就是并发前的工作做完,可终止的并发预处理就是等5s进行一次young gc,如果没有发生的话有提供的参数,可以强制进行
- 重新标记:增量更新,重新对新增的引用深度扫描
- 并发清理
记忆集:针对跨代引用问题提出的思想,非收集区域指向收集区域的数据结构 卡表是具体实现,字节数组 一字节,标记脏卡什么的,一个卡表对应一个512字节卡页,同时增量更新原始快照也会用到,提高回收效率
Foregroud CMS:
并发搜集器不能在年老代填满之前完成不可达(unreachable)对象的回收 ,或者 老年代中有效的空闲内存空间不能满足某一个内存的分配请求 ,此时应用会被暂停,并在此暂停期间开始垃圾回收,直到回收完成才会恢复应用程序。这种无法并发完成搜集的情况就成为 并发模式失败(concurrent mode failure) ,而且这种情况的发生也意味着我们需要调节并发搜集器的参数了。
简单来说,也就是我去进行并发标记的时候,内存不够了,这个时候我会进入STW,并且开始全局Full GC.
MSC(标记整理)他的回收方式其实就是我们的滑动整理,并且进行整理的时候一般都是两个参数
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=0
这两个参数表示多少次FullGC后采用MSC算法压缩堆内存,0表示每次FullGC后都会压缩,同时0也是默认值
G1:垃圾优先
划分为2048个region ,每个1~32M

原文是copy-整理算法--标记整理
分代收集
可预测的停顿,优先回收垃圾最多的Region区域
初始标记 GCRoots
并发标记 可达性分析
最终标记 修正变动数据 原始快照
筛选回收 对回收价值和成本进行排序,根据用户所期望的GC停顿时间指定回收计划
除了并发标记都STW
Tlab本地线程缓冲区:分配空间时,为了提高JVM的运行效率,应当尽量减少临界区范围,避免全局锁。G1的通常的应用场景中,会存在大量的访问器同时执行,为减少锁冲突,JVM引入了TLAB(线程本地分配缓冲区 Thread Local Allocation Buffer)机制。
Rset类似于记忆集
稀疏表:本质上就是一种Hash表,Key是Region的起始地址,Value是一个数组,里面存储的元素是卡页的索引号。
细粒度位图:就是一个C位图,但是这个位图,可以详细的记录我们的内存变化,包括并发标记修改,对应元素标识等 当稀疏表指定region的card数量超过阈值时,则在细粒度位图中创建一个对应的PerRegionTable对象。一个Region地址链表,维护当前Region中所有card对应的一个BitMap集合。
粗粒度位图:当细粒度位图 size超过阈值时,所有region 形成一个 bitMap。如果有region 对当前 Region 有指针指向,就设置其对应的bit 为1,也就是粗粒度位图
CSET
-
年轻代区块:在每次垃圾收集循环中,所有的年轻代区块都会被包括在CSet中,因为G1 GC采用的是分代收集策略,必须定期清理年轻代以回收空间。
-
选定的老年代区块:除了年轻代区块,CSet还可能包括一些老年代区块。G1 GC会根据各个区块的回收价值(即,预期能够回收的内存量与收集该区块所需时间的比率)和GC停顿时间目标来选择一些老年代区块进行清理。这样做旨在平衡垃圾收集的效率和应用程序的停顿时间。
写屏障:因为Store Buffer导致读写的顺序不一致,而写屏障可以解决这个问题
当CPU执行写操作时,出于性能优化的考虑,写操作不是直接写入主内存,而是首先被写入到该CPU核心的StoreBuffer中。StoreBuffer允许CPU继续执行后续指令而不必等待写操作实际完成。因为重排会有读写不一致!如果一个核心在其Store Buffer中有未刷新到主内存的写操作,而另一个核心尝试读取相同的内存位置,它可能读到旧的数据,从而导致数据不一致。

内存伪共享:
写屏障的内存伪共享问题: 如果不同线程对对象引用的更新操作,恰好位于同一个64B区域内,这将导致同时更新卡表的同一个缓存行,从而造成缓存行的写回、无效化或者同步操作,间接影响程序性能。
不采用无条件的写屏障,而是先检查卡表标记,只有当该卡表项未被标记过才将其标记为dirty。 这就是JDK 7中引入的解决方法,引入了一个新的JVM参数-XX:+UseCondCardMark,















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









