






关单操作?
- 优先考虑定时任务、Redisson+redis、RocketMQ延迟消息实现(订单量特别大的时候,不建议使用MQ)
- 每个订单都有一个消息会增加资源消耗
- 可靠性问题(丢失)
- 大量的无效消息
- 不是所有消息队列都支持,像kafka就没有
- 一般通过定时任务实现,像阿里内部就是超时中心(TOC)
- 定时任务:Timer、定时任务线程池、XXL-JOB这种、quartz定时
- 时间不精确--订单场景实际上不是很需要时间很精确
- 无法处理大量订单--数据库字段加索引+标志位
- 扫描数据库造成压力大+扫描子库
- 分库分表后需要全表扫描
- Redisson+redis
- Redisson定义了分布式延迟队列RDelayedQueue,实际上就是在zset的基础上增加了一个基于内存的延迟队列
- 当添加一个元素到延迟队列的时候,将数据和超时时间放进zset中,启动一个延时任务,当任务到期的时候,就将zset中的数据取出来,返回给客户端使用。
- 支付成功了就移除,阻塞队列也能移除。
分布式环境下,事务传播行为怎么弄?
- 像下单,扣款,物流,发短信
- 首先开启一个全局事务,下单和扣款required,物流和发短信required_new,不用mandatory是因为服务也会单独使用。
每天100w次登录请求,4核8G机器如何做JVM调优?
- 首先确定有没有流量高峰?假设存在某一段时间有峰值,比如30min,那么QPS就是600左右,应该做怎样的优化?
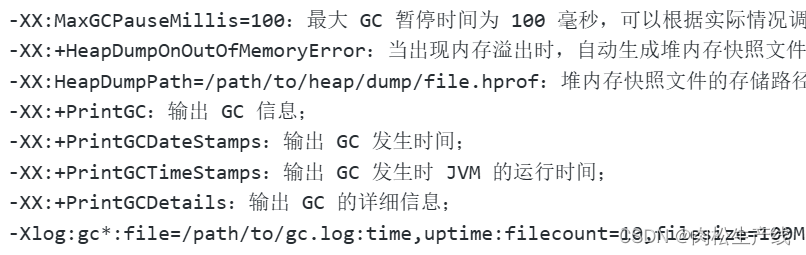
- 将堆内存设置为操作系统的一半。初始和最大设置成一样的,避免扩容收缩操作,提高稳定性。
- 垃圾收集器选择:
- 考虑STW和吞吐量的问题
- serial排除,parnew和parallel scavange更关注吞吐量,4G可以使用G1
- 通过-XX:MaxGCPauseMills=100~200之间
- 然后调节G1的一些配置,比如并行线程数,并发线程数
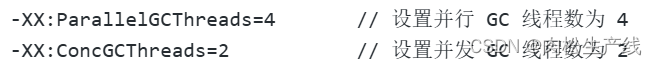

- 添加日志,动态调整
如果QPS提高了一百倍,应该怎么办?
- DDOS攻击
- 设计一个支持高并发的系统:
- 架构、性能优化、容错、可伸缩性等等
- 分布式架构:降低单点故障的风险,提高可伸缩性和性能
- 集群部署:负载均衡,提高可用性和性能
- 缓存
- 异步处理:消息队列等降低请求响应时间和提高吞吐量
- 预加载:预先加载需要的资源,减少等待时间
- 代码优化和调优:避免长事务、减小锁的粒度等,提高性能
- 数据库优化:索引设计、分库分表、读写分离
- 熔断降级限流:防止雪崩
- 压力测试
- 容错和监控
不使用redis分布式锁,如何防止用户重复点击?
- 滑动窗口限流
- token,判断token有没有被消费过,在数据库判断
- 前端按钮
- 一般redis使用不了一般是降级成直接使用数据库。
购物车功能?
- 不需要把商品的所有信息保存下来,只需要保存SKUID加上数量时间等,至于其他的到时候反查数据库就可以。
- 未登录用户存在cookie和LocalStorage里面
- 登陆的要么存数据库,要么存redis
- 数据库和redis各有好处,可靠性,性能权衡,mysql有事务机制。
秒杀系统?
- 首先需要设计一个高并发系统:
- 什么是高并发?
- 高并发简而言之就是流量大,请求多,QPS高等等,针对这些情况,在保证系统稳定的情况下,尽可能满足这些请求。流量变大,有两种方式,增加单台服务器的性能,这就是垂直扩容,第二是增加服务器的数量,这种叫水平扩容。
- 接下来请求分为读请求和写请求,针对读多写少的系统,经常是和缓存打交道,涉及到的就是数据一致性,对于写少读多的系统,就是数据库的容量,不同表之间的数据一致性,第三就是同样请求的幂等性
- 读请求的话:主要就是解决一致性问题,比如秒杀系统,可以将请求打到redis上面,再将数据库的更新同步到redis,腾讯用的就是Mysql+DTS,阿里Inventory Hint(数据库排队)
- 写请求:
- 1、数据量大:分库分表(todo)
- 2、数据一致性:涉及到单机事务和分布式事务,然后还有下面的对账机制
- 3、并发:分布式锁,乐观锁等
- 读写分离!
- 最重要的,分清楚高并发和高并行,高并行没有共享资源加服务器就可以,高并发有共享资源,说白了就是绕过共享资源,变成高并行,Redis绕过的就是共享DIsk的IO,CQRS(读写分离)绕过的就是互斥锁。
- 包含但不限于:分布式、集群、缓存、异步、mysql调优、预加载、服务器熔断限流降级、本地缓存、代码优化等等。
- 什么是高并发?
- 高并发瞬时流量
- 架构方面做逐层的流量过滤,经过客户端、CDN(内容缓存)、WEB、缓存、数据库
- 负载均衡:通过gateway和nacos做负载均衡,拿到服务列表后通过loadBalance负载均衡
- 多层负载均衡结构:第一层做全局流量分配,第二层在进一步细分
- 客户端做一些随机请求的过滤
- Nginx做一些流量的过滤,IP限流等等
- 服务器sentinel限流
- 查询操作写操作用缓存抗一下,缓存上本地缓存性能要高于分布式缓存
- 热点数据:
- 拆分+缓存
- 缓存就是做一些预热,不仅redis做预热,本地缓存也做预热,防止热点key问题
- 数据量大:
- 分库分表
- 库存正确扣减:
- 如何避免超卖少卖
- 从redis中取出当前库存,lua脚本执行达到原子性+有序性,redisson的信号量
- redis中先扣减,发一个MQ消息,之后再做真正的数据库扣减操作
- 阿里的inventory hint直接访问数据库
- 导致少卖:
- 引入对账机制,比如用zset添加流水记录,定时拉取一段时间内的所有记录,然后数据库比对,发现不一致就进行补偿处理
- 对账分为离线对账和实时对账
- 离线对账是在(D+1)第二天进行核对
- 实时对账控制在秒级延迟内进行对账
- 编写代码核对和编写SQL核对,代码核对一般用定时任务,比如上面那种,但是成本高,一般是用SQL核对
- 如果商家在过程中补货了?
- 增加一个全局标志位,在补货过程中不允许扣减库存,补货的数量相应的去redis里更新,这样会导致用户停滞
- 订阅binlog,补了多少就去redis修改多少。
- 先加到redis里面,发一个mq消息去数据库真正增加
- 业务手段:
- 预约
- 预售
- 前端弄些验证码
Zset实现点赞和排行榜?
- 朋友圈点赞:
- 首先分析朋友圈点赞是什么功能
- 被点赞人的微信号
- 点赞人的微信号
- 点赞时间
- 通过zset实现
- key被点赞人的这篇朋友圈的ID
- value表示点赞人的微信号
- score表示点赞的时间
- 点赞就更新score,jedis.zadd(key,cow,userId)
- 取消点赞就移除,jedis.zrem(key,userId)
- 查询就通过ZREVRANGEBYSCORE命令逆序返回点赞人的微信号


- 首先分析朋友圈点赞是什么功能
- 排行榜
- 在score相同时,会按照value排序
- 那么score设置为分数+(1-时间戳小数)
查找附近的人的功能?
- 通过Redis的GEOADD将用户的经纬度存在一个指定的键值中,然后通过redis的GEORADIUS命令查询指定经纬度附近一定范围的用户。
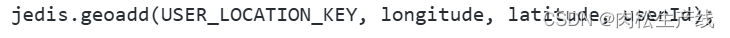
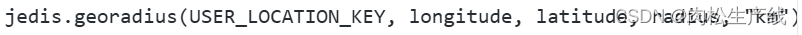
消息队列推好还是拉好?
- 推模式就是在消费端和消息中间件建立TCP长连接或者注册一个回调,有数据就通过长连接或者回调将数据推送
- 拉就是消费者轮询,通过不断轮询检查有没有数据。
- 拉可以自己掌握消息数量和速度,但是轮询有对中间件有一定的压力
- 推消息是实时的,缺点就是如果生产速度大于消费速度消费者会产生堆积,容易压垮。
- 看消费者和消息中间件是不是双向通信。
- 使用长轮询:发起一个长轮询请求,有消息就返回,没有就等一会儿,等到有新消息到达。还没有就等下一次长轮询。
如何进行SQL调优的?
- 首先定位到慢sql的地方
- 接下来分析
- 索引失效:查询执行计划是否执行了索引
- 多表join:嵌套循环,外循环的每条记录都要和内循环的记录做比较,n张表就O(N^n)的复杂度。Mysql8中增加了Hash join,驱动表的数据会构建一张hash表,然后被驱动表的去进行匹配,最后聚合,但是有内存限制,此时就可以通过基于磁盘的hash joi,分批加载,到达O(N)的复杂度。
- 索引离散度低:
- 查询字段太多:避免冗余查询
- 表数据量太大:建立索引不一定能解决了,通过数据归档,比如只保留半年内的数据,或者说是分库分表、分区。
- 数据库连接不够:业务量大就分库,慢SQL、长事务,并发大的情况下存在排队,就可以像上迷案的秒杀服务那样解决。还有一个改造Mysql,比如阿里的Inventory-Hint。
- 表结构不合理:做一些反范式化,冗余字段,避免join。
- 数据库参数不合理,增加事务文件大小,缓冲池大小,read线程数
- 参数调优
mysql连接优化:
- 使用连接池,druid,C3P0等
- 调整配置,最大连接数,最小空闲连接数,连接超时,调整隔离等级
- 使用预编译语句,可以提高性能,并防止SQL注入
- 批量处理
- 关闭连接
- 缩小事务范围(大事务会造成占用数据库连接和日志空间占用)
- 阿里的inventory-hint能够优化查询间接优化到连接(核心思想之一确实是通过顺序排队执行来减少锁竞争)
- 同理腾讯云数据库,当开启热点更新自动探测时,系统会自动探测是否有单行的热点更新,如果有,则会让大量的并发 update 排队执行,以减少大量行锁造成的并发性能下降
如何设计一个数据库连接池?
- 可以想一下线程池是怎么实现的,阻塞队列,线程工厂,最大线程数,核心线程数
- 数据结构就选择LinkedBlocking,两把锁,两个condition互相唤醒,效率较高
- 仿照着线程池说就可以
不用synchronized实现线程安全单例?
饿汉可以,静态内部类、枚举也可以,还能用CAS实现,但是其实loadclass就是synchronized修饰的。
private static final AtomicReference<Lazy> INSTANCE=new AtomicReference<>();
//CAS实现
//原子性可见性有序性都保证了,但是会造成CPU开销
public static Lazy casInstance(){
while (true){
Lazy singleton = INSTANCE.get();
if (null!=singleton){
return singleton;
}
Lazy ans = new Lazy();
if (INSTANCE.compareAndSet(null,ans)){
return singleton;
}
}
}本地缓存和分布式缓存有什么区别?
- 两种不同的缓存架构,主要区别在于数据的存储和管理方式
- 本地缓存是指将数据存储在单个应用程序中,提高性能,减少数据库访问次数,但是在集群环境中,多个本地缓存中数据可能不一致。Caffeine,异步化比较好
- 分布式缓存的优点在于共享数据,提高系统的可伸缩性和可用性,但是有数据一致性、故障恢复,管理和维护成本。
多级缓存是怎么应用的?
- 客户端缓存、CDN缓存、Nginx这两个放静态资源,然后本地、分布式缓存
Innodb用跳表,redis用B+数可以吗?
-
关系型数据库以表的形式存储,非关系型以key-value的形式存储
-
B+磁盘友好(顺序性,以及磁盘预读,页分裂时就读取或者修改一页),跳表内存友好(多级索引结构,磁盘IO性能低)
由于上面的问题,引入块存储设备顺序写入和随机写入差距的描述:
- 以机械硬盘举例,数据时通过磁盘上的读写头写入的,顺序写入减少了寻道时间以及旋转延迟
- 固态硬盘:随机写入会导致内部块被频繁擦写。
接口很慢如何定位问题?
- 阿里的arthas定位,比如是哪个商品相关的,然后分析SQL,进行SQL调优
如何保证REDIS中的数据都是热点数据?
- 数据预热,先将热的数据先加进去
- 热点数据更新:热key检测
- 过期策略:LRU或者LFU
- 缓存淘汰策略:每秒执行10次,每次选20个,超过1/4过期就继续淘汰,还有懒、lazyfree
设计一个接口要考虑哪些方面?
- 明确需求
- 安全性
- 性能和效率
- 幂等性
- 错误处理
- 用户体验
用了一锁二判三更新,为什么还有重复数据?
- 存在锁已经释放了,但是事务还没提交,然后后面进来的接着操作。
- 主要就是因为事务的粒度大于锁的粒度
- 声明式事务@Transactional改为编程式事务

一个接口QPS3000,接口RT为200ms,需要几台机器?
- 那么就是单线程一秒处理5个请求,假设tomcat有200个线程,那么吞吐量就是1000个/s
- 实际需要做压测,然后预估2-3倍数,大概6-9台机器。
商城系统如何设计一个数据一致性方案?
- 比如下单的时候需要有订单系统、库存系统、积分系统、邮件系统、外部机构这些组成
- 像完整的分布式事务的话:
- 订单系统和库存系统就考虑强一致性
- 积分系统考虑最终一致性
- 邮件考虑最大努力通知
- 像外部的话,很多因素影响,一般是在协议上约定:
- 风控通过,投保一定成功
- 先资金流理赔,再补齐信息流
- 每天异步同步一次就可以了
如何实现缓存预热?
- 启动预热:

- @EventListener
- 定时任务:类似于秒杀活动,开始前一天先把相关数据放进redis里面
- 用时加载
- 缓存加载器:比如caffeine就有,定义一些机制
应用占用内存持续升高,堆内存、元空间都没变化,可能原因?
- bytebuffer使用直接内存,未回收
- 线程栈
- JNI或者本地代码
常见的解决Hash冲突的方法及例子?
- 开放地址法:ThreadLocalMap
- 拉链法:HashMap、ConcurrentHashMap、Redis
- 再Hash:HashMap、ConcurrentHashMap、Redis(通过渐进式Hash扩容)
异步编排任务的使用?
- 在商城项目中的订单模块,比如下订单的时候,首先是需要用户的信息,然后是购物车的信息,接下来就是商品信息,库存信息之类的,最后返回订单的vo,大概模拟就是:需要完成了上面的任务拿到返回结果才能继续下一步的操作...
import java.util.concurrent.*;
public class AsyncExample {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(10);
CompletableFuture<Product> productFuture = CompletableFuture.supplyAsync(() -> {
// 模拟加载商品信息的耗时操作
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return new Product("产品A", "描述A", 100.0);
}, executor);
CompletableFuture<Inventory> inventoryFuture = CompletableFuture.supplyAsync(() -> {
// 模拟加载库存信息的耗时操作
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return new Inventory(100);
}, executor);
CompletableFuture<Order> orderFuture = CompletableFuture.allOf(productFuture, inventoryFuture)
.thenApply(v -> {
Product product = productFuture.join();
Inventory inventory = inventoryFuture.join();
return new Order(product, inventory);
});
try {
Order order = orderFuture.get();
System.out.println("订单创建成功: " + order);
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
} finally {
executor.shutdownNow();
}
}
}
class Product {
private String name;
private String description;
private double price;
public Product(String name, String description, double price) {
this.name = name;
this.description = description;
this.price = price;
}
// getters and setters...
}
class Inventory {
private int quantity;
public Inventory(int quantity) {
this.quantity = quantity;
}
// getters and setters...
}
class Order {
private Product product;
private Inventory inventory;
public Order(Product product, Inventory inventory) {
this.product = product;
this.inventory = inventory;
}
// getters and setters...
}使用分布式锁会降低系统的性能吗?
- 加分布式锁的意义是什么,是防止同一个行为的重复操作,比如一个用户重复下单这种行为,拦截的基本都是不希望发生的
- 包括缓存击穿的时候加入分布式锁进来一个用户更新缓存,这也是利于系统的稳定性和后面的并发的
长短连接问题,后端如何做到长短连接的转换,同时访问资源不变?
- 首先建立mapping关系,给每个短链接建立出
 这样的关系
这样的关系 - 创建短链接,比如:

- 通过短链接的访问被重定向到HttpResponse.direct转换
Redis 的简单评论系统需要支持发布评论回复评论和分页展示。请描述你的数据结构设计。
- 每条评论和下面的回复都是独立的整体,可以采用hash存储,每条评论有个自增的id,如内容、作者、时间戳、父评论 ID(用于作为回复) 等。
- 通过zset,key是评论的id,然后value是具体评论的id,score是时间
- 通过INCR id自增id
后端服务器开发过程中应该关注哪些方面?
- 除了业务逻辑之外还需要:
- 性能优化:集群、分布式、代码优化、异步处理、缓存
- 安全性
- 可扩展性、容错性、可用性
- 技术更新
负载均衡组件及要点?
- 请求收收器
- 负载均衡策略
- 健康检查
- 请求转发















 2329
2329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









