







一,Queue简介
队列是一种常见的数据结构,它遵循先进先出(FIFO)的原则。队列的头部元素是在队列中存储时间最长的元素(AA)。队列的尾部是在队列中停留时间最短的元素(NN)。在队列的尾部插入新元素,队列检索操作在队列的头部获取元素。如下图所示:

Queue 队列接口是在JDK1.5之后提供的;Queue队列是单向队列的接口,Queue队列接口除了继承Collection拥有基本集合业务操作之外;队列还提供了额外的插入(),删除,检查元素等队列需要的业务功能;


从Queue队列继承图和官网文档中可以得知;Queue队列的插入功能[add(E), offer(E)], 删除功能[remove(), poll()],还有检查功能[element(), peek()] 都提供两个方法;它们之间主要区别在于操作失败之后是否抛会异常;官网文档中表示插入,删除,检查这些方法都提供了两种形式。
- 一种方法是在操作失败时抛出异常;
- 另一种方法是在操作失败时返回特殊值( null / false);
add(E), remove(), element() 是在操作失败时抛出异常;
offer(E), poll(), peek() 是在操作失败时返回特殊值(null/ false)
官网文档还表明,后面这种操作失败返回特殊值的处理是专门为有容量限制的队列而提供的,因为在大多设计当中,插入操作不会失败!
二,Queue单向队列继承结构

三,Queue 接口
package java.util;
/**
* @since 1.5
* @author Doug Lea
* @param <E> the type of elements held in this queue
*/
public interface Queue<E> extends Collection<E> {
/**
* 将指定元素插入到队列中,成功时返回true,如果当前没有可用空间则抛出IllegalStateException
*/
boolean add(E e);
/**
* 将指定元素插入到队列中,成功时返回true,失败返回 false
*/
boolean offer(E e);
/**
* 检索并删除队列的头部元素。此方法与poll()的唯一不同之处在于,如果此队列为空,它将抛出异常 NoSuchElementException
*/
E remove();
/**
* 检索并删除队列的头部元素,如果此队列为空,则返回null。
*/
E poll();
/**
* 检索队列的头部。此方法与peek的唯一不同之处在于,如果此队列为空,它将抛出异常。NoSuchElementException
*/
E element();
/**
* 检索队列的头部,如果此队列为空则返回null。
*/
E peek();
}
Queue 单向队列接口定义了单向队列需要的业务方法(API);为单向队列业务提供了标准的业务接口;开发者直接调用对应的方法即可;对于开发者不需要知道具体实现是什么;这也是面向接口而非实现编程的思想;
面向接口而非实现编程的思想,通常是指在设计和编写代码时,应该依赖于抽象(这个抽象可以是接口,也可以抽象类),而不是具体实现类
因为接口为软件组件/业务定义了清晰的行为契约,而不依赖于具体实现,所以,只要满足了接口的约定,就可以自由地更换具体实现子类,而不会影响到依赖于这些接口的代码;(这样就有很好的解耦合)
同时,也提高系统对于这一块业务的扩展;这种抽象层次的提升使得开发者可以在不修改现有代码的情况下,引入新的实现子类,进行扩充;
四,AbstractQueue 抽象类

4.1 AbstractQueue 构造器
package java.util;
/**
* @since 1.5
* @author Doug Lea
* @param <E> the type of elements held in this queue
*/
public abstract class AbstractQueue<E>
extends AbstractCollection<E>
implements Queue<E> {
/** 该构造器由 protected 关键字修饰 */
protected AbstractQueue() {
}
}
AbstractQueue 接口实现了Queue 接口,还继承了AbstractCollection 意味着有Collection 集合接口的功能;
构造器使用 protected 关键字修饰;我们都知道,protected 关键字修饰的属性,方法,构造只能在同一包下才能进行访问;但是Java里的抽象类的构造器是不能进行 new ;那同包下也无法使用?那作用是什么?
提到 protected 关键字,该关键字除了在同一包下引用范围做了限制,还提供了只要是这个类的子类;即使在不同的包中也能进行访问。也就是不同包下的子类可以访问该属性,方法;对于抽象类,当然是用来继承;根据自己的业务来实现一个队列子类;这样及对外提供扩展的同时也有着封闭作用!
4.2 AbstractQueue 新增业务
/** 新增指定元素,成功返回true, 失败抛IllegalStateException异常 */
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}对于add(E) 操作失败抛异常的实现;内部调用的还是 offer(E) 方法;该方法操作失败并不会抛异常,而是返回true或false; 所以,AbstractQueue 队列 add()默认的实现方式就是借助offer来实现的。
4.3 AbstractQueue 删除业务
public E remove() {
E x = poll(); // 获取头部的元素,并删除
if (x != null)
return x;
else
throw new NoSuchElementException();
}该remove()删除业务,也是借助 poll() 来判断获取头部的元素是否为空,如果为空则抛异常;
4.4 AbstractQueue 查询业务
public E element() {
E x = peek();
if (x != null)
return x;
else
throw new NoSuchElementException();
}通过该方法可以得知;所有因操作失败而抛异常的业务方法;都是借助与对应的操作失败不抛异常,返回特殊值的方法(null/ boolean)进行实现的。
AbstractQueue 抽象类定义了操作失败抛异常的业务模块,而具体的子类只需要实现对应返回特殊值的方法(0ffer(), poll(), peek());
4.5 AbstractQueue 批量新增
public boolean addAll(Collection<? extends E> c) {
if (c == null)
throw new NullPointerException(); // 元素集是否为空
if (c == this)
throw new IllegalArgumentException(); // 元素集是否为当前自己
boolean modified = false;
// 循环迭代逐个追加
for (E e : c)
if (add(e))
modified = true;
return modified;
}4.6 AbstractQueue 清空业务
public void clear() {
while (poll() != null)
;
}循环调用 poll()方法,逐个将元素删除;队列没有元素,为空时。poll()方法返回null;
总结,AbstractQueue 队列定义了操作失败抛异常的模块方法。都是借助于操作失败返回特殊值来实现的。顺便还提供了批量新增,与清空业务!
五,PriorityQueue 优先级队列
PriorityQueue优先级队列,该优先级队列是无界的,也就意味着它没有范围的可以进行动态扩容,但一般扩容到Intger的最大值;
优先级队列的元素默认是根据自然排序进行排序,或者在构造时指定了比较器,则使用指定的比较器进行排序;
优先级队列不允许存储 null 元素;
优先级队列不允许存储不可比较的对象(这样会抛出类转换异常:ClassCastException);
5.1 PriorityQueue 属性
package java.util;
import java.util.function.Consumer;
import java.util.function.Predicate;
import jdk.internal.access.SharedSecrets;
import jdk.internal.util.ArraysSupport;
/**
* @since 1.5
* @author Josh Bloch, Doug Lea
* @param <E> the type of elements held in this queue
*/
@SuppressWarnings("unchecked")
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
@java.io.Serial
private static final long serialVersionUID = -7720805057305804111L;
/** 初始化容量大小 11 */
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/** 优先级队列;并且它是一个平衡二叉树堆数据结构 */
transient Object[] queue;
/** 队列大小 */
int size;
/** 队列的比较器 */
@SuppressWarnings("serial")
private final Comparator<? super E> comparator;
/** 修改次数,用于判断是否并发修改异常 */
transient int modCount;
// ... ...
}
5.2 PriorityQueue 构造器
/** 创建一个默认大小为11的PriorityQueue队列 */
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
/** 创建一个指定容量大小的PriorityQueue队列 */
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
/** 创建一个指定比较器的PriorityQueue队列,默认容量大小: 11 */
public PriorityQueue(Comparator<? super E> comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
/**
* 使用指定的容量大小和比较器创建一个PriorityQueue队列
* @param initialCapacity 队列的容量大小
* @param comparator 队列的比较器
*/
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// 容量不能小于1
if (initialCapacity < 1) throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
/** 将指定元素集内容传入并创建一个PriorityQueue队列 */
public PriorityQueue(Collection<? extends E> c) {
// 如果元素集是SortedSet类型,则该PriorityQueue 排序使用指定SortedSet的比较器。
if (c instanceof SortedSet<?>) {
SortedSet<? extends E> ss = (SortedSet<? extends E>) c;
this.comparator = (Comparator<? super E>) ss.comparator();
initElementsFromCollection(ss);
}
// 如果元素集是PriorityQueue类型,则该PriorityQueue 排序使用指定PriorityQueue的比较器。
else if (c instanceof PriorityQueue<?>) {
PriorityQueue<? extends E> pq = (PriorityQueue<? extends E>) c;
this.comparator = (Comparator<? super E>) pq.comparator();
initFromPriorityQueue(pq);
}
// 否则,PriorityQueue 排序使用自然排序
else {
this.comparator = null;
initFromCollection(c);
}
}
/** 创建一个PriorityQueue,其中包含指定优先队列中的元素。该优先级队列将按照与给定优先级队列相同的顺序进行排序 */
public PriorityQueue(PriorityQueue<? extends E> c) {
this.comparator = (Comparator<? super E>) c.comparator();
initFromPriorityQueue(c);
}
/** 创建一个PriorityQueue,其中包含指定排序集中的元素。这个优先级队列将按照与给定排序集相同的顺序进行排序*/
public PriorityQueue(SortedSet<? extends E> c) {
this.comparator = (Comparator<? super E>) c.comparator();
initElementsFromCollection(c);
}
5.3 PriorityQueue 队列初始化业务
在上面的构造器当中,可以看到后面的一个构造器都调用的对应的初始化方法,现在来讲解一下对应的初始化方法 ;主要有三个初始化方法
- initElementsFromCollection(Collection<? extends E> c)
- initFromPriorityQueue(PriorityQueue<? extends E> c)
- initFromCollection(Collection<? extends E> c)
5.3.1 initElementsFromCollection
private void initElementsFromCollection(Collection<? extends E> c) {
Object[] es = c.toArray(); // 将c 集合转换成数组
int len = es.length;
// 判断集合c是否为ArrayList, 如果不是则使用Arrays.copyOf 将数据复制到数组中,
// 这样做的目的是确保数组的数据类型为Object
if (c.getClass() != ArrayList.class)
es = Arrays.copyOf(es, len, Object[].class);
// 判断 长度是否为1或者比较器不为空,则循环遍历元素是否有null,有null则抛空指针异常
if (len == 1 || this.comparator != null)
for (Object e : es)
if (e == null)
throw new NullPointerException();
// 再一次确保数组不为空
this.queue = ensureNonEmpty(es);
this.size = len;
}
private static Object[] ensureNonEmpty(Object[] es) {
return (es.length > 0) ? es : new Object[1];
}5.3.2 initFromPriorityQueue
/** 创建一个PriorityQueue队列,并初始化指定PriorityQueue优先级队列的内容 */
private void initFromPriorityQueue(PriorityQueue<? extends E> c) {
if (c.getClass() == PriorityQueue.class) { // 如果队列数据为PriorityQueue类型,则只需要校验是否为空,就直接用,不需要再做null判断,因为PriorityQueue是不允许存储null
this.queue = ensureNonEmpty(c.toArray());
this.size = c.size();
} else { // 不是PriorityQueue类型,则初始化一个
initFromCollection(c);
}
}5.3.3 initFromCollection
private void initFromCollection(Collection<? extends E> c) {
initElementsFromCollection(c); // 创建一个PriorityQueue队列,并将指定集合元素添加到PriorityQueue队列里面
heapify(); // 堆数据结构化处理5.3.4 heapify() 堆数据结构化处理
在讲解heapify()方法之前,先讲解一个堆数据结构的概念。
这里堆数据结构并非是内存里面的堆概念,而是数据结构里面的一种树结构。堆是一个完全二叉树结构的数据结构;它和平常我们听到的二叉树又有什么区别?
二叉树是一种通用的二叉树,每个节点只有两个子节点,没有特定的约束条件
堆是一种特殊的二叉树,通常是完全二叉树,并且具有最大堆和最小堆的性质,用于高效进行元素插入,删除和查找操作,特别适用于优先级的相关场景!举一个例子来表示它们之间不同的应用场景!
【二叉树应用场景例子】
比如家谱树图,可以通过家谱树来表示每一个成员和他们的关系!
John
/ \
Lisa Adam
/ \ / \
Mike Nina Carl NULL
家谱树当中的案例,只反应了家族之间成员的层级关系,并没有额外特定的约束,排序或者结构约束之类的。所以二叉树通常用于数据的层级组织,比如家谱,文件系统结构等等,或者作为其他更复杂数据结构的基础
【堆数据结构(完全二叉树)】
比如任务列表,其中每一个人物都有一个优先级,我们需要确保总是先执行优先级最高的任务(数字越小,任务级别越高);可以通过堆的数据结构进行管理这些任务;因为堆不仅有二叉树的基本性质,而且还具有层级之间还具有排序的特性!
10
/ \
15 20
/ \ / \
30 40 50 60
所以,堆主要用于优先级队列的实现,如操作系统的任务调度器,网络路由器中的数据包调度等等。它可以快速移除和添加元素,并保持优先级队列的性能。
【最大堆与最小堆】
堆数据结构,还有一个概念就是最大堆和最小堆。简单就是顺序比较,一个倒叙比较,如下案例
【最大堆】倒叙排序
100
/ \
60 70
/ \ / \
20 30 40 50
【堆小堆】顺序排序
5
/ \
10 15
/ \ / \
20 25 30 35
堆的数据结构概念讲解了之后,回归主题接着继续阅读heapify()方法。代码如下
/** 该方法让PriorityQueue队列中的元素重新排列成堆数据结构(完全二叉树) */
private void heapify() {
final Object[] es = queue;
int n = size, i = (n >>> 1) - 1;
final Comparator<? super E> cmp;
// 如果当前PriorityQueue队列的比较器为null,则进行自然排序
if ((cmp = comparator) == null)
for (; i >= 0; i--)
siftDownComparable(i, (E) es[i], es, n);
// 或者使用指定的比较器进行排序
else
for (; i >= 0; i--)
siftDownUsingComparator(i, (E) es[i], es, n, cmp);
}该方法让PriorityQueue队列中的元素重新排列成堆数据结构(完全二叉树),如果PriorityQueue队列指定比较器则按指定的比较器来进行排序。否则默认使用自然排序;
总结:
一,PriorityQueue 队列从构造器开始创建,如果指定元素集内容,则将元素逐个追加到PriorityQueue优先级队列当中,之后通过heapify()进行堆化处理!。如果在创建PriorityQueue队列的时候指定了比较器,则使用指定的比较器进行堆化处理,如果没有指定比较器,默认使用自然排序进行堆化处理!
二,如果指定的元素集本身就具有比较特性,则直接使用该元素集本身的比较器进行堆化处理!这个逻辑在initElementsFromCollection() 方法中可以看到
5.4 PriorityQueue 堆数据结构业务
在2.3.3.4 小结当中 heapify() 讲解解释了堆数据结构的概念! 再把代码拿过来看
/** 该方法让PriorityQueue队列中的元素重新排列成堆数据结构(完全二叉树) */
private void heapify() {
final Object[] es = queue;
int n = size, i = (n >>> 1) - 1;
final Comparator<? super E> cmp;
// 如果当前PriorityQueue队列的比较器为null,则进行自然排序
if ((cmp = comparator) == null)
for (; i >= 0; i--)
siftDownComparable(i, (E) es[i], es, n);
// 或者使用指定的比较器进行排序
else
for (; i >= 0; i--)
siftDownUsingComparator(i, (E) es[i], es, n, cmp);
}从上面的得知siftDownComparable()方法是自然排序的堆化处理过程!那另一个方法自然而然就是比较器的堆化处理过程,方法名称siftDownUsingComparator();
在PriorityQueue优先级队列当中提供两个方向的对堆化处理方式,一种是将元素往下排序,一种是将元素往上排序;这两种方式都是实现堆化处理。不管是哪一种PriorityQueue优先级队列的堆都是默认最小堆(正序);如果用最大堆可以通过一些Collections 工具类进行一个倒叙处理就是一个最大堆;
5.4.1 siftDown 向下排序
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x, queue, size, comparator);
else
siftDownComparable(k, x, queue, size);
}从该方法可以得知使用哪种方式进行排序,取决于是否有比较器,没有就使用自然排序进行向下排序,有就使用比较器进行向下排序
5.4.2 siftDownComparable 自然比较的向下排序
/**
* @params k 是将要向下排序的节点索引
* @params x 是将要向下排序的元素
* @params es 堆的数组
* @params n 是堆的大小
*/
private static <T> void siftDownComparable(int k, T x, Object[] es, int n) {
// 将元素转换为自然排序的比较器,从这里也可以看出PriorityQueue队列不能存储不可比较的对象
// 不然会抛ClassCastException 异常
Comparable<? super T> key = (Comparable<? super T>)x;
// 向右移动一位,等于 n / 2 ;来判断是否为非叶子节点;
// 因为叶子节点是没有子节点的,所以也无需做比较
int half = n >>> 1;
while (k < half) { // 有子节点,是非叶子节点,进行比较
int child = (k << 1) + 1; // 获取左边子节点索引
Object c = es[child];
int right = child + 1; // 获取右边子节点索引
// 下面整段是一个冒泡顺序比较,进行位置移动; 大的节点往下移动
if (right < n && ((Comparable<? super T>) c).compareTo((T) es[right]) > 0)
c = es[child = right];
if (key.compareTo((T) c) <= 0)
break;
es[k] = c;
k = child;
}
es[k] = key;
}5.4.3 siftDownUsingComparator 比较器向下排序
/**
* @params k 是将要向下排序的节点索引
* @params x 是将要向下排序的元素
* @params es 堆的数组
* @params n 是堆的大小
* @params cmp 比较器
*/
private static <T> void siftDownUsingComparator(
int k, T x, Object[] es, int n, Comparator<? super T> cmp) {
int half = n >>> 1; // 计算堆中非叶子节点的数量。在循环中只需要考虑非叶子节点。
while (k < half) {
int child = (k << 1) + 1; // 获取左边子节点索引
Object c = es[child];
int right = child + 1; // 获取右边子节点索引
// 后面整段一个冒泡顺序排序;进行元素位置移动
if (right < n && cmp.compare((T) c, (T) es[right]) > 0)
c = es[child = right];
if (cmp.compare(x, (T) c) <= 0)
break;
es[k] = c;
k = child;
}
es[k] = x;
}比较器和自然排序处理方式是一样的
5.4.4 siftUp 向上排序
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x, queue, comparator);
else
siftUpComparable(k, x, queue);
}该方法也是通过比较器进行判断采取哪种方式进行堆化处理;
5.4.5 siftUpComparable 自然比较的向上排序
/**
* k 要向上移动的节点索引
* x 要向上移动的元素 (目标元素)
* es 堆的数组
*/
private static <T> void siftUpComparable(int k, T x, Object[] es) {
// 转换成Comparable 意味着元素本身就比较特性才能进行转换;所以PriorityQueue优先级队列是不允许存储不可比较的对象
Comparable<? super T> key = (Comparable<? super T>) x;
while (k > 0) { // 当前节点不是根节点时才会执行,0 就是 根节点的索引
int parent = (k - 1) >>> 1; // 计算当前父节点的索引
Object e = es[parent]; // 获取当前父节点元素
// 目标元素与父节点进行比较,如果目标元素大于或等于父节点元素;则它们两个位置互换
if (key.compareTo((T) e) >= 0)
break;
es[k] = e;
k = parent;
}
es[k] = key;
}5.4.6 siftUpUsingComparator 比较器的向上排序
/**
* k 要向上移动的索引
* x 要向上移动的元素(目标元素)
* es 堆的数组
* cmp 比较器
*/
private static <T> void siftUpUsingComparator(
int k, T x, Object[] es, Comparator<? super T> cmp) {
while (k > 0) { // 当前节点不为根节点则一直向上循环
int parent = (k - 1) >>> 1; // 获取当前节点的父节点
Object e = es[parent]; // 获取当前节点的父元素
// 目标元素与父元素进行比较,如果目标元素大于或等于父节点,则位置进行互换
if (cmp.compare(x, (T) e) >= 0)
break;
es[k] = e;
k = parent;
}
es[k] = x;
}5.5 测试案例
5.5.1 测试案例 - 自然排序
package com.toast.queue;
import java.util.PriorityQueue;
import java.util.Queue;
/**
* @author toast
* @time 2024/5/4
* @remark
*/
public class TestPriorityQueue {
public static void main(String[] args) {
/*
* 优先级队列只能存储可比较的对象也是说只能存储
* java.util.Comparator或者java.lang.Comparable 这两脉的子类
* Long 是属于 java.lang.Comparable 这一脉的
*/
Queue<Long> priorityQueue = new PriorityQueue<>();
priorityQueue.add(1000120241201L); // 这里JVM会将long封装成Long包装类
priorityQueue.add(1000120241205L);
priorityQueue.add(1000120241202L);
priorityQueue.add(1000120241204L);
priorityQueue.add(1000120241203L);
int size = priorityQueue.size();
System.out.println("=================单向队列-先进先出==================");
for (int i = 0; i < size; i ++) {
System.out.println("【从头开始打印流水号】" + priorityQueue.poll());
}
}
}

5.5.2 测试案例 - 比较器排序
package com.toast.queue;
import java.util.PriorityQueue;
/**
* @author toast
* @time 2024/5/4
* @remark 自定义编码打印任务
*/
public class ToastTask {
/**
* 任务优先级
*/
private int order;
/**
* 任务名称
*/
private String name;
/**
* 任务打印的码
*/
private PriorityQueue<String> codes;
public int getOrder() {
return order;
}
public String getName() {
return name;
}
public ToastTask(int order, String name, PriorityQueue<String> codes) {
this.order = order;
this.name = name;
this.codes = codes;
}
/**
* 编码打印
*/
public void print() {
this.codes.forEach(System.out::println);
}
}
package com.toast.queue;
import java.util.List;
import java.util.PriorityQueue;
/**
* @author toast
* @time 2024/5/4
* @remark
*/
public class TestComparatorPriorityQueue {
public static void main(String[] args) {
// 自定义一个比较器;优先级队列按照给定的优先级进行排序; 该比较器是一个是一个倒叙(也就是最大堆)
PriorityQueue<ToastTask> taskDescQueue = new PriorityQueue<>((o1, o2) -> {
if (o2.getOrder() - o1.getOrder() < 0) return -1;
if (o2.getOrder() - o1.getOrder() > 0) return 1;
return 0;
});
// 自定义一个比较器;优先级队列按照给定的优先级进行排序; 该比较器是一个是一个顺序(也就是最小堆)
// PriorityQueue<ToastTask> taskASCQueue = new PriorityQueue<>((o1, o2) -> {
// if (o1.getOrder() - o2.getOrder() < 0) return -1;
// if (o1.getOrder() - o2.getOrder() > 0) return 1;
// return 0;
// });
PriorityQueue<String> codes1 = new PriorityQueue<>(List.of("1000120241201", "1000120241202", "1000120241203"));
PriorityQueue<String> codes2 = new PriorityQueue<>(List.of("CODE-10001", "CODE-10002", "CODE-10003"));
PriorityQueue<String> codes3 = new PriorityQueue<>(List.of("serial-30001", "serial-30002", "serial-30003"));
taskDescQueue.add(new ToastTask(10, "打印任务一", codes1));
taskDescQueue.add(new ToastTask(200, "打印任务二", codes2));
taskDescQueue.add(new ToastTask(5, "打印任务三", codes3));
int size = taskDescQueue.size();
System.out.println("=================单向队列-先进先出-依次调用不同的任务进行打印==================");
for (int i = 0; i < size; i ++) {
ToastTask task = taskDescQueue.poll();
System.out.printf("【%s】%n" ,task.getName());
task.print();
}
}
}

5.6 PriorityQueue 新增业务
/** 该新增方法是属于操作失败抛异常那一类的,并且在AbstractQueue 定义add业务模块
* 在这里PriorityQueue 优先级队列自己重写了一遍,并且操作失败根据offer
*
*/
public boolean add(E e) {
return offer(e);
}
/**
* 新增元素,该新增方法是属于操作失败返回特殊值那一类的
*/
public boolean offer(E e) {
if (e == null) throw new NullPointerException(); // 不运行添加null 值
modCount++; // 记录修改次数
int i = size;
if (i >= queue.length) grow(i + 1); // 容量满了进行扩容
siftUp(i, e); // 进行向上排序插入
size = i + 1;
return true;
}5.7 PriorityQueue 删除业务
/** 删除队列中和指定的元素一样的元素,只删除一个 */
public boolean remove(Object o) {
int i = indexOf(o); // 根据元素获取索引
if (i == -1) // 元素不存在
return false;
else {
removeAt(i); // 根据索引删除元素,
return true;
}
}
/** 删除队列中和指定的元素一样的元素,删除所有一样的 */
void removeEq(Object o) {
final Object[] es = queue;
for (int i = 0, n = size; i < n; i++) {
if (o == es[i]) {
removeAt(i);
break;
}
}
}
E removeAt(int i) {
final Object[] es = queue; // 获取当前堆的数组
modCount++;
int s = --size;
if (s == i) es[i] = null; // 索引是最后一位直接删除
else {// 否则,将最后一个元素(索引为 s)移动到被移除的元素的位置 i,并调用 siftDown 方法来保持堆的性质
E moved = (E) es[s];
es[s] = null;
siftDown(i, moved);
// 如果移除的元素在 siftDown 后没有改变位置,则调用 siftUp 方法来进一步调整堆。如果元素的位置发生了改变,则返回移除的元素。
if (es[i] == moved) {
siftUp(i, moved);
if (es[i] != moved)
return moved;
}
}
// 如果没有发生任何调整,则返回 null。
return null;
} /** 该删除方法是属于操作失败返回特殊值那一类的;并且会返回所删除的元素 */
public E poll() {
final Object[] es;
final E result;
// 头部元素不为null,就可以进行删除
if ((result = (E) ((es = queue)[0])) != null) {
modCount++;
final int n;
final E x = (E) es[(n = --size)]; // 获取尾部元素
es[n] = null; // 进行删除,数组的删除就是设置为null
if (n > 0) {// 队列还有元素,需要进行一次堆数据结构化的处理,保证队列的有序性
final Comparator<? super E> cmp;
if ((cmp = comparator) == null)
siftDownComparable(0, x, es, n);
else
siftDownUsingComparator(0, x, es, n, cmp);
}
}
return result;
}5.8 PriorityQueue 检查业务
public E peek() {
return (E) queue[0];
}很直观,只获取头部元素
5.9 PriorityQueue 扩容机制
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// 根据当前容量和所需的最小容量,计算新的容量。
// 这里使用了一个辅助方法 ArraysSupport.newLength 来确定新容量。
// 如果当前容量小于 64,新容量将是当前容量的两倍加上 2;
// 否则,新容量将是当前容量的 50% 增长。
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity,
oldCapacity < 64 ? oldCapacity + 2 : oldCapacity >> 1);
queue = Arrays.copyOf(queue, newCapacity);
}至于PriorityQueue 里面其他的业务方法都属于Collection集合的通用业务方法,和优先级队列关系不是很大。这边不展开详情讲解,如果对Collection 业务感兴趣可以看小编同学对应的Collection,List等集合的讲解这里对Collection业务进行了讲解;
java-01基础篇-04 Java 集合-01-Collection接口-CSDN博客
java-01基础篇-04 Java集合-02-List接口(一)-CSDN博客
java-01基础篇-04 Java集合-02-List接口(二)-CSDN博客
java-01基础篇-04 Java集合-02-List接口(三)之多学一点系列-CSDN博客
六,Todo & ListBuffer

Todo与ListBuffer 这两类都不属于java.base模块的类。是jdk.compiler 模块的类;这个两类的全限定类名如下:
com.sun.tools.javac.comp.Todo
com.sun.tools.javac.util.ListBuffer
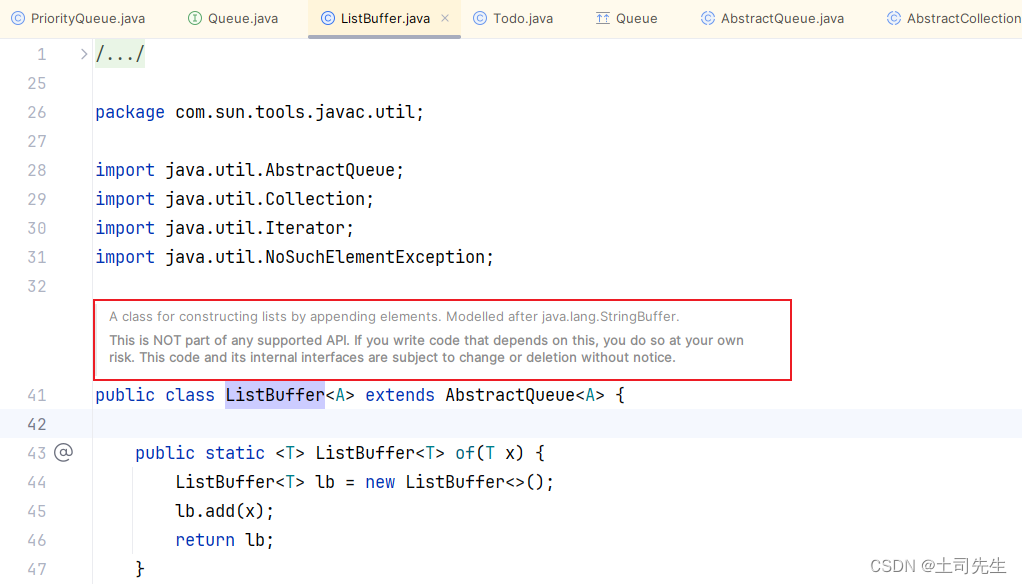

上面这两个类红框框的描述是一样的;上面说该类是模仿java.lang.StringBuffer。这不是任何受支持的API的一部分。并且还警告如果编写的代码依赖于此类,那么自己将自担风险。本代码及其内部接口可随时更改或删除,恕不另行通知
jdk.compiler 模块,从名称不难看出,该模块是Java编译器的一部分,是用于编译代码方面使用的。 Todo是编译器的开发过程中,开发人员可能会在代码中标记一些需要后续处理的任务或功能。
而另一个ListBuffer 也是Java 编译器的一部分,主要用于在编译过程中构建和管理列表数据结构。它提供了一种可变的列表容器,可以动态地添加、删除和修改列表中的元素。该类通常用于编译器内部,用于管理各种编译过程中产生的数据,例如语法树节点、符号、类型等。它的设计使得在编译过程中能够高效地操作列表,同时保持列表的有序性;
七,ConcurrentLinkedQueue

java.util.concurrent.ConcurrentLinkedQueue 是JDK 1.5 提供一个支持并发编程的类。队列的知识还是一样的,只不过需要更多的是需要并发编程方面的业务思想;各种锁,JDK 1.8 的 CAS是通过 sun.misc.Unsafe 类来完成,而JDK 9之后用的java.lang.invoke.VarHandle 等等概念都偏向于并发;所以小编同学是打算在日后的多线程,JUC 这一系列文章中专门有一章是讲解线程安全对集合的实现处理。包括List, Set, Map, Queue 等常见集合处理的方式;















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









