







目录
2.5.3 第三种新增:操作发生阻塞,一直阻塞下去,不会中断,直到新增成功为止
2.5.4 第四种新增:操作发生阻塞,阻塞时长超出指定时长,则中断处理或者操作成功也会释放锁
2.6.3 第三种删除:操作发生阻塞,一直阻塞下去,不会中断,直到删除成功为止
2.6.4 第四种删除:操作发生阻塞,阻塞时长超出指定时长,则中断处理!或者操作成功也会释放锁
3.4.3 第三种新增:操作发生阻塞,一直阻塞下去,不会中断,直到新增成功为止
3.4.4 第四种新增:操作发生阻塞,阻塞时长超出指定时长,则中断处理或者操作成功也会释放锁
3.5.3 第三种删除:操作发生阻塞,一直阻塞下去,不会中断,直到删除成功为止
3.5.4 第四种删除:操作发生阻塞,阻塞时长超出指定时长,则中断处理!或者操作成功也会释放锁
3.8.4 跳过已匹配的节点(即“死节点”)来保持队列的连贯性和高效性
上一章:java-01-源码篇-04 Java集合-03-BlockingQueue(二)-CSDN博客
这张沿着上一章继续讲解剩余几个没有讲解完的BlockingQueue 子类阻塞队列。还剩余图中四个红圈圈的实例没有讲解。继续进行讲解

在讲解DelayQueue之前先讲解一下leader-follower模式。
一,Leader-Follower模式
Leader-Follower 模式是一种常用的并发设计模式,用于高效地管理多个工作线程处理事件驱动任务。该模式的核心思想是通过一组工作线程来轮流充当Leader,负责处理新的时间并将其分发给其他线程(Followers)。这有助于减少上下文切换和竞争,提高系统的并发性能和吞吐量。
Leader-Follower 模式中一个重要的概念:
Leader: 当前负责处理新事件的线程
Follower: 等待被唤醒以处理任务的线程
Event Queue: 存储待处理事件的队列
Event Handler: 处理事件的逻辑
1.1 leader-follower 测试案例
/**
* 事件
*/
class ToastEvent {
private final String message;
public ToastEvent(String message) {
this.message = message;
}
public String getMessage() {
return message;
}
}/**
* 事件处理器
*/
class ToastEventHandler {
/**
* 处理event事件业务
* @param event
*/
public void handle(ToastEvent event) {
System.out.println(Thread.currentThread().getName() + " handling event: " + event.getMessage());
}
}/**
* 工作线程,轮流充当Leader处理事件
*/
class Worker implements Runnable {
/** event queue 事件队列 */
private static final BlockingQueue<ToastEvent> eventQueue = new LinkedBlockingQueue<>();
/** 事件处理器 */
private static final ToastEventHandler eventHandler = new ToastEventHandler();
/** 领导者:true - 已选举出来 | false - 未选择出来 */
private static volatile boolean leader = false;
@Override
public void run() {
while (true) {
if (becomeLeader()) { // 选举出成为Leader
try {
System.out.println(Thread.currentThread().getName() + " became Leader");
ToastEvent event = eventQueue.take();
eventHandler.handle(event);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
} finally {
leader = false;
}
} else { // 否则成为 Follower进行等待
System.out.println(Thread.currentThread().getName() + " is Follower");
Thread.yield(); // 优雅的让出CPU
}
}
}
/**
* 选择出leader
* @return
*/
private boolean becomeLeader() {
synchronized (Worker.class) {
if (!leader) {
leader = true;
return true;
}
return false;
}
}
/**
* 添加事件
* @param event
*/
public static void addEvent(ToastEvent event) {
eventQueue.add(event);
}
}public class TestLeaderFollower {
public static void main(String[] args) {
int numberOfWorkers = 3;
// 创建3个工作线程
for (int i = 0; i < numberOfWorkers; i++) {
new Thread(new Worker(), "工作线程-" + i).start();
}
// 第一次添加10个event事件,让3个工作线程进行处理
for (int i = 0; i < 10; i++) {
Worker.addEvent(new ToastEvent("处理事件-" + i));
}
}
}
本次案例中ToastEvent 表示需要处理的事件,ToastEventHandler 表示事件处理器,里面编写着处理事件的业务逻辑; 也就是handler()方法
public void handle(ToastEvent event) {
System.out.println(Thread.currentThread().getName() + " handling event: " + event.getMessage());
}最后定义Worker 工作线程类,该类的作用是用来定义工作流程,也就是说用来实现Leader-Follower模式的轮流充当Leader处理事件。通过becomeLeader()来选举出leader来。
private boolean becomeLeader() {
synchronized (Worker.class) {
if (!leader) {
leader = true;
return true;
}
return false;
}
}选择出来的成为 Leader ;没有的则成为 Follower;代码如下
@Override
public void run() {
while (true) {
if (becomeLeader()) { // 选举出成为Leader
try {
System.out.println(Thread.currentThread().getName() + " became Leader");
ToastEvent event = eventQueue.take();
eventHandler.handle(event);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
} finally {
leader = false;
}
} else { // 否则成为 Follower进行等待
System.out.println(Thread.currentThread().getName() + " is Follower");
Thread.yield(); // 优雅的让出CPU
}
}
}这里的案例之所以使用 while(true) 一直循环等待,表示的是本次追加的3个事件;进行处理,处理完之后,三个Worker工作线程都进入Follower等在状态;等待下一次事件添加将继续进行处理事件;这样就达到了循环使用线程;从而减少了上下文的切换;
public class TestLeaderFollower {
public static void main(String[] args) throws InterruptedException {
int numberOfWorkers = 3;
// 创建3个工作线程
for (int i = 0; i < numberOfWorkers; i++) {
new Thread(new Worker(), "工作线程-" + i).start();
}
// 第一次添加10个event事件,让3个工作线程进行处理
System.out.println("【第一次】添加10个事件");
for (int i = 0; i < 10; i++) {
Worker.addEvent(new ToastEvent("one-batch-event-" + i));
}
System.out.println("【第一次处理完】睡眠三秒");
TimeUnit.SECONDS.sleep(3);
System.out.println("【第二次】再添加10个事件");
for (int i = 0; i < 10; i++) {
Worker.addEvent(new ToastEvent("two-batch-event-" + i));
}
}
}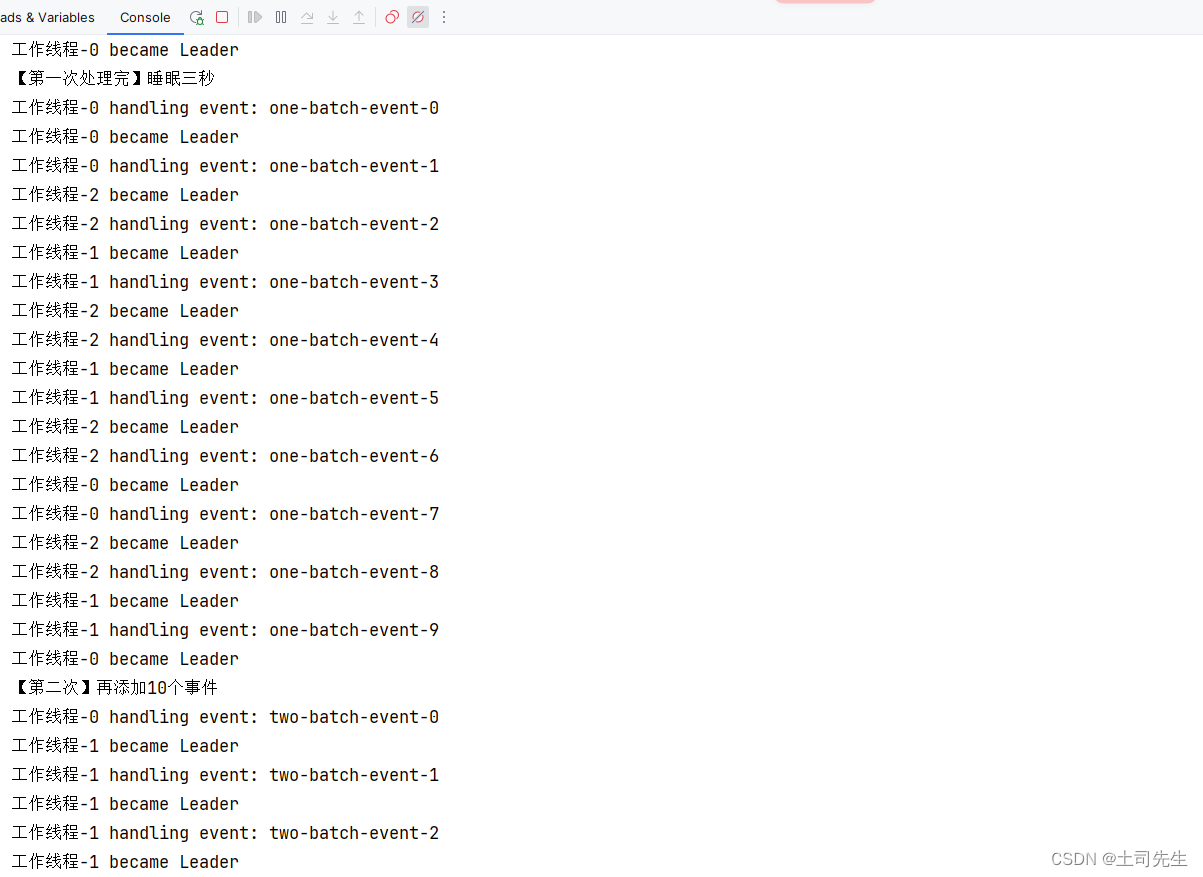
本次输出,为了方便观察把 Follower 状态的输出语句给注释了。从上面可以得知把第一次事件处理完之后,都将进行Follower状态,等待新事件加入之后,再次通过轮流leader进行处理事件!
 本次案例主要是为了更好理解什么是Leader-Follower模式!因为在DelayQueue 延迟队列里面运用到了Leader-Follower 设计模式
本次案例主要是为了更好理解什么是Leader-Follower模式!因为在DelayQueue 延迟队列里面运用到了Leader-Follower 设计模式
二,DelayQueue
DelayQueue(延迟队列),该队列是没有界限的,也就意味着有扩容机制。如果是固定大小集合则没有扩容机制;该队列中新增的元素的只有其指定的时间已延期过时才能够被拿到;没有还没有延迟过期则拿到的内容为null;继承结构如下:
public class DelayQueue<E extends Delayed> extends AbstractQueue<E>
implements BlockingQueue<E> {}从中可以看出DelayQueue 的元素只能是Delayed 这个类的子类;
2.1 Delayed
刚才我们讲了DelayQueue 延迟队列只返回元素已延迟过时的对象,那这个判断该怎么实现?在JDK1.5提供一个 java.util.concurrent.Delayed 接口;该接口为已延迟对象提供一个标准处理方法getDelay;getDelay() 获取对象的剩余时间,如果剩余时间是0或者是负数表示已过时;代码如下:
package java.util.concurrent;
/**
* @since 1.5
* @author Doug Lea
*/
public interface Delayed extends Comparable<Delayed> {
/**
* 在给定的时间单位内返回与此对象关联的剩余延迟
* @param unit 时间单位
* @return 返回剩余延迟时间;0或者负数表示延迟时间已过期
*/
long getDelay(TimeUnit unit);
}
从源码中可以得知Delayed接口还是Comparable 接口的子类;意味着该Delayed接口还具有可比较的特性;通过 Comparable的compareTo来实现。
2.2 Delayed案例
/**
* @author toast
* @time 2024/5/15
* @remark 自定义一个延迟实体
*/
class ToastDelayTask implements Delayed {
/**
* 延迟时间
*/
private final long delayTime;
/**
* 过期时间
*/
private final long expireTime;
/**
* 消息内容
*/
private final String message;
public ToastDelayTask(long delay, String message) {
this.delayTime = delay;
this.expireTime = System.currentTimeMillis() + delay;
this.message = message;
}
@Override
public long getDelay(TimeUnit unit) {
long diff = expireTime - System.currentTimeMillis();
return unit.convert(diff, TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
if (this.expireTime < ((ToastDelayTask) o).expireTime) {
return -1;
}
if (this.expireTime > ((ToastDelayTask) o).expireTime) {
return 1;
}
return 0;
}
@Override
public String toString() {
return message;
}
}/**
* @author toast
* @time 2024/5/15
* @remark
*/
public class TestDelayedQueue {
public static void main(String[] args) throws InterruptedException {
DelayQueue<Delayed> queue = new DelayQueue<>();
queue.put(new ToastDelayTask(2000, "【任务一】2秒延迟时间"));
queue.put(new ToastDelayTask(4000, "【任务二】4秒延迟时间"));
queue.put(new ToastDelayTask(1000, "【任务三】1秒延迟时间"));
while (!queue.isEmpty()) {
long startTime = System.currentTimeMillis();
Delayed task = queue.take();
long endTime = System.currentTimeMillis();
System.out.println("开始时间:" + startTime);
System.out.println("结束时间:" + endTime);
System.out.println("时间间隔:" + (endTime - startTime));
System.out.println("Executed: " + task);
}
}
}
2.3 DelayQueue 属性分析
public class DelayQueue<E extends Delayed> extends AbstractQueue<E>
implements BlockingQueue<E> {
/** ReentrantLock 可重入锁 被transient锁修饰意味着不可被序列化 */
private final transient ReentrantLock lock = new ReentrantLock();
/**
* q-延迟队列,从这里大概可以得知DelayQueue 延迟队列是借助PriorityQueue优先级队列实现的
* 也就是意味着延迟队列的新增,删除,检索都是调用PriorityQueue优先级队列的方法;
* 只不过是在为延迟业务在包一层,对延迟时间做一层处理;这样就达到了延迟队列的需求;
*/
private final PriorityQueue<E> q = new PriorityQueue<E>();
/**
* Leader-Follower 模式中的Leader;可以看出该leader直接是一条线程;
*/
private Thread leader;
/**
* 该Condition 表示可用的Leader;当需要进行leader与Follower轮流时通过这个来做判断;
* 所以属性名称叫做available 表示可用的 (leader)
*/
private final Condition available = lock.newCondition();
// ......
}2.4 DelayQueue 构造器
public DelayQueue() {} /**
* 创建一个延迟队列,并将指定的元素集添加到延迟队列里面
* @param c 元素集
*/
public DelayQueue(Collection<? extends E> c) {
this.addAll(c);
}
/** 调用的是AbstractQueue的addAll 方法 */
public boolean addAll(Collection<? extends E> c) {
if (c == null)
throw new NullPointerException();
if (c == this)
throw new IllegalArgumentException();
boolean modified = false;
for (E e : c)
if (add(e))
modified = true;
return modified;
}2.5 DelayQueue 新增业务
2.5.1 第一种新增:操作失败抛异常
/**
* 新增元素
* @param e 要新增的元素
*/
public boolean add(E e) {
return offer(e);
}2.5.2 第二种新增:操作失败返回特殊值
/**
* 新增元素
* @param e 新增元素
*/
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e); // 委托调用优先级队列的新增
/*
* 进行队首进行检索,如果刚刚新增的元素是队首的元素
* 表示它是当前最早的元素
* 唤醒一条leader 进行处理
*/
if (q.peek() == e) {
leader = null;
available.signal();
}
return true;
} finally { // 新增无论是否失败都将释放锁
lock.unlock();
}
}2.5.3 第三种新增:操作发生阻塞,一直阻塞下去,不会中断,直到新增成功为止
public void put(E e) {
offer(e);
}2.5.4 第四种新增:操作发生阻塞,阻塞时长超出指定时长,则中断处理或者操作成功也会释放锁
public boolean offer(E e, long timeout, TimeUnit unit) {
return offer(e);
}2.6 DelayQueue 删除业务
2.6.1 第一种删除:操作失败抛异常
public boolean remove(Object o) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return q.remove(o); // 直接调用优先级队列进行删除
} finally { // 无论删除是否成功都将释放锁
lock.unlock();
}
}2.6.2 第二种删除:操作失败返回特殊值
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E first = q.peek(); // 获取队列的元素
/*
* 如果 first 元素延迟时间大于0,则返回null;
* 否则就是小于0;表示延迟时间已过时
* 则调用q.poll() 进行删除
*/
return (first == null || first.getDelay(NANOSECONDS) > 0)
? null
: q.poll();
} finally {
lock.unlock();
}
}2.6.3 第三种删除:操作发生阻塞,一直阻塞下去,不会中断,直到删除成功为止
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 实现一个无限循环,直到成功获取到期元素
for (;;) {
E first = q.peek(); // 获取队首元素
// 如果队列为空,则线程陷入阻塞
if (first == null)
available.await();
// 如果队列不为空的处理
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0L) // 元素的延迟时间已过期,进行删除
return q.poll();
first = null;
// 如果元素的延迟时间没有过期,但是有leader在处理其他业务,则进入阻塞
if (leader != null)
available.await();
// 如果元素的延迟时间没有过期,也没有leader在处理其他业务,则进入阻塞
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}2.6.4 第四种删除:操作发生阻塞,阻塞时长超出指定时长,则中断处理!或者操作成功也会释放锁
/**
* 删除元素,在指定的时间内;
*
*/
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// for 循环是为了在超时时间内反复尝试获取队列元素
for (;;) {
E first = q.peek(); // 获取队首元素
// 处理延迟队列为空的情况
if (first == null) {
// 指定的时间已到,则返回null;表示在超时时间内没有获取到任何元素
if (nanos <= 0L)
return null;
// 指定的时间未到,将该删除线程进行阻塞等待;并更新nanos
else
nanos = available.awaitNanos(nanos);
// 处理延迟队列为不空的情况
} else {
// 获取元素的延迟时间
long delay = first.getDelay(NANOSECONDS);
// 时间已过期,进行删除
if (delay <= 0L) return q.poll();
// 指定范围的时间已到,直接返回null;表示在超时时间内没有获取到任何元素
if (nanos <= 0L) return null;
first = null;
/*有leader进行处理时或者指定时间nanos 小于 延迟时间 ;此时线程进入阻塞状态*/
if (nanos < delay || leader != null)
nanos = available.awaitNanos(nanos);
// 否则,当前线程设置为leader,等待delay时间,然后更新nanos值
// 其实这一段就是leader的轮流;只有当leader为null时,才将当前线程切换为leader
// 之前的leader的线程要么进行阻塞,要么已完成
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
long timeLeft = available.awaitNanos(delay);
nanos -= delay - timeLeft;
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally { // 最终是否删除元素成功都将释放锁,并且如果此时队列不为空,并且没有leader进行处理,则唤醒一条leader进行处理
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}2.7 DelayQueue 检索业务
public E peek() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return q.peek();
} finally {
lock.unlock();
}
}2.8 DelayQueue 扩容机制
由于DelayQueue是无界队列;所以是有扩容机制的,但是从源码的角度来讲,延迟队列的无界性是根据优先级队列来的,因为延迟队列里面用的就是优先级队列;所以扩容机制用的也是优先级队列的扩容机制
有关于优先级队列讲解:java-01-基础篇-04 Java集合-03-Queue-CSDN博客
这里面讲解到了优先级队列的实现业务;所以延迟队列的扩容机制实际上就是优先级队列的扩容机制
三,TransferQueue 传输队列
在上一章讲解到了SynchronousQueue 同步队列;在同步队列里面内置一个Transfer 传输队列;那这个TransferQueue 同步队列接口和SynchronousQueue 同步队列内置的Transfer 传输队列区别在哪里?为什么又要定义一个接口这样子的接口?并且我们从继承图可以得知,这是一个独单的接口。
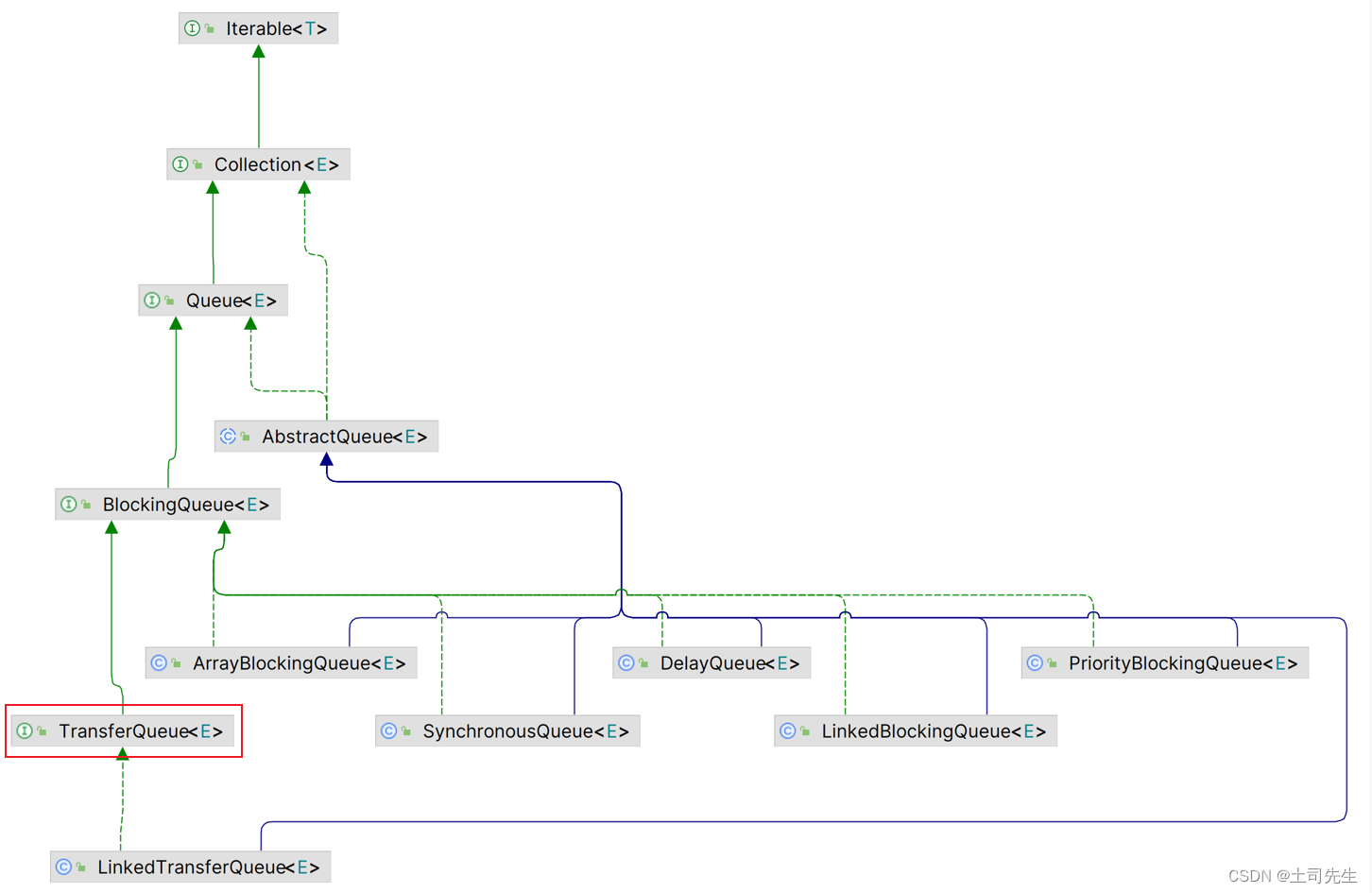
说到区别;我们完全可以从上一章讲解到的SynchronousQueue 同步队列与其他队列有什么区别开始入手讲:
上一章链接:

总结就是 SynchronousQueue 同步队列采用直接传输(传输队列)的方式,使得生产者和消费者一对一匹配,消除了队列中的缓冲区。这确保了生产者和消费者的速度严格匹配。而其他传统阻塞队列是通过缓冲的方式来进行存储元素,其生产者与消费者之间的数据处理较慢。
package java.util.concurrent;
/**
* @since 1.7
* @author Doug Lea
* @param <E> the type of elements held in this queue
*/
public interface TransferQueue<E> extends BlockingQueue<E> {
/**
* 尝试将元素 e 直接传输给消费者(如果有的话)。
* 如果当前有消费者在等待,则立即将元素传输给消费者并返回 true。
* 如果没有消费者在等待,则返回 false,并且不会将元素加入队列。
* @param e 传入给消费者使用的接口
*/
boolean tryTransfer(E e);
/**
* 将元素 e 直接传输给消费者
* 如果当前没有消费者在等待,则生产者将被阻塞,直到有消费者接收该元素
* 这种方法确保传输的元素一定会被消费
*/
void transfer(E e) throws InterruptedException;
/**
* 尝试将元素 e 在指定的超时时间内传输给消费者。
* 如果在超时时间内有消费者接收该元素,则返回 true。
* 如果在超时时间内没有消费者接收该元素,则返回 false。
* 如果超时时间为零,则该方法的行为与 tryTransfer(E e) 类似
*
*/
boolean tryTransfer(E e, long timeout, TimeUnit unit) throws InterruptedException;
/**
* 检查是否有消费者在等待元素
* 如果至少有一个消费者在等待元素,则返回 true
* 如果没有消费者在等待元素,则返回 false
*/
boolean hasWaitingConsumer();
/**
* 返回当前等待元素的消费者数量。
* 这个方法对于监控和调试非常有用,可以帮助了解当前系统中消费者的状态。
*/
int getWaitingConsumerCount();
}
3.1 LinkedTransferQueue 子类
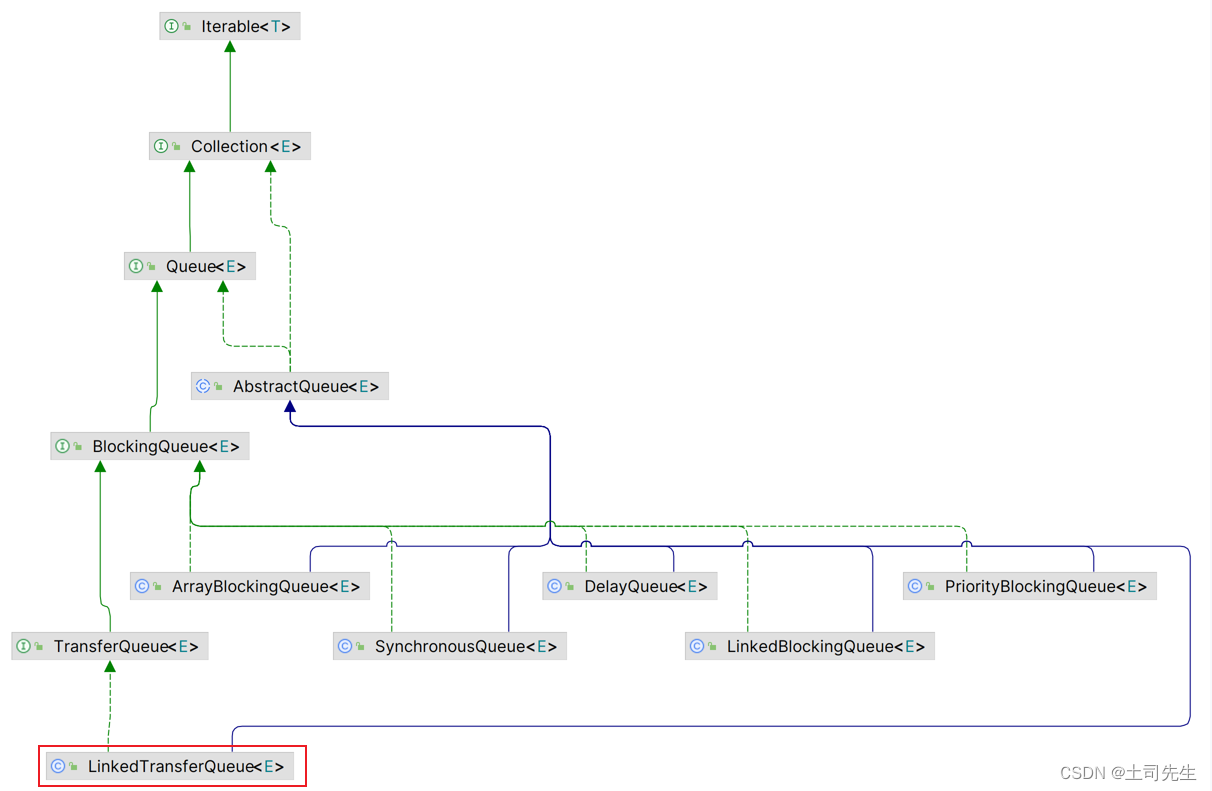
3.2 LinkedTransferQueue 内部类
3.2.1 Node 类
static final class Node implements ForkJoinPool.ManagedBlocker {/*忽略代码*/}从Node的继承结构来看,和 SynchronousQueue同步队列的QNode/SNode 内部类的作用是一样的,都是在节点里面提供用于管理阻塞等待相关业务的实现。这样也是为LinkedTransferQueue 队列提供直接输入功能做准备。实现方式和SynchronousQueue 同步队列是一样的。只不过这个TransferQueue 接口,不仅实现了直接传输还实现阻塞队列的基本操作!
也就是该队列不仅支持传入和支持存储的方式。这样主要是为了应对生产者在没有消费者时阻塞,确保每个传输的元素都能被及时消费。这些方法在高度同步的生产者-消费者场景中非常有用。特别是 LinkedTransferQueue 实现了这些方法,提供了一种灵活且高效的方式来进行并发编程。
3.2.1.1 Node 构造器
Node() {
isData = true;
}Node(Object item) {
ITEM.set(this, item);
isData = (item != null);
}3.2.1.2 Node的属性
static final class Node implements ForkJoinPool.ManagedBlocker {
final boolean isData; // true - 生产者数据 | false - 消费者数据
volatile Object item; // 节点内容
volatile Node next; // 后置节点
volatile Thread waiter; // 处理节点的线程(陷入等待状态的线程)
private static final long serialVersionUID = -3375979862319811754L;
}3.2.1.3 Node的业务
通过CAS设置后置节点
/**
* 通过CAS设置后置节点
* @param cmp 比较节点(旧的后置节点)
* @param val 要设置新的后置节点
*/
final boolean casNext(Node cmp, Node val) {
return NEXT.compareAndSet(this, cmp, val);
}通过CAS设置节点内容
/**
* 通过CAS设置节点内容
* @param cmp 比较节点内容(旧内容)
* @param val 要设置新的节点内容
*/
final boolean casItem(Object cmp, Object val) {
return ITEM.compareAndSet(this, cmp, val);
}删除Node的后置节点;删除的方式是自我连接,之后通过GC垃圾回收处理
/** 通过CAS将后置节点进行自我连接,给GC垃圾回收进行处理 */
final void selfLink() {
NEXT.setRelease(this, this);
}将当前节点推进为后置节点
final void appendRelaxed(LinkedTransferQueue.Node next) {
NEXT.setOpaque(this, next);
}尝试匹配节点内容
/**
* 尝试匹配节点内容,如果节点内容匹配成功,则返回true;
* @param cmp 比较内容
* @param val 新内容
*/
final boolean tryMatch(Object cmp, Object val) {
if (casItem(cmp, val)) {
LockSupport.unpark(waiter);
return true;
}
return false;
}如果无法将具有给定模式的节点附加到此节点,因为此节点不匹配并且具有相反的数据模式,则返回true
final boolean cannotPrecede(boolean haveData) {
boolean d = isData;
return d != haveData && d != (item == null);
} /**
* 此方法用于执行阻塞操作
* 返回true表示阻塞操作已完成
*/
public final boolean block() {
while (!isReleasable()) LockSupport.park();
return true;
}
/**
* 此方法用于检查阻塞操作是否已经可以解除
* 返回 true 表示可以解除阻塞
*/
public final boolean isReleasable() {
return (isData == (item == null)) ||
Thread.currentThread().isInterrupted();
}3.3 LinkedTransferQueue 属性
package java.util.concurrent;
public class LinkedTransferQueue<E> extends AbstractQueue<E>
implements TransferQueue<E>, java.io.Serializable {
private static final long serialVersionUID = -3223113410248163686L;
/*
* 这个常量定义了自旋等待的阈值,用于控制在某些情况下是否进行忙等待(自旋)。
* 当等待超时时间低于这个阈值时,线程会通过自旋等待而不是挂起,
* 以减少上下文切换的开销,从而提高性能。
*/
static final long SPIN_FOR_TIMEOUT_THRESHOLD = 1023L;
/*
* 这个常量定义了清理操作的阈值。
* 当队列中未处理的节点数量超过这个阈值时,
* 会触发清理操作,以移除无效或取消的节点,防止队列膨胀。
*/
static final int SWEEP_THRESHOLD = 32;
/*
* 这是一个指向队列头节点的指针。
* 使用 volatile 修饰,确保对 head 的修改对于所有线程可见。
* transient 修饰符表明在序列化过程中不包含这个字段
*/
transient volatile Node head;
/*
* 这是一个指向队列尾节点的指针。
* 使用 volatile 修饰,确保对 tail 的修改对于所有线程可见
*/
private transient volatile Node tail;
/*
* 这个布尔变量指示是否需要进行队列清理操作。
* 当队列中存在过多的无效节点时,这个标志位会被设置为 true,以提示进行清理。
*/
private transient volatile boolean needSweep;
/* 忽略代码 */
// 表示立即执行的操作,如无超时的 poll 和 tryTransfer
private static final int NOW = 0;
// 表示异步操作,如 offer、put 和 add
private static final int ASYNC = 1;
// 表示同步操作,如 transfer 和 take。 这些操作会阻塞,直到成功完成
private static final int SYNC = 2;
// 表示带有超时的操作,如带超时的 poll 和 tryTransfer
private static final int TIMED = 3;
} LinkedTransferQueue 利用这些属性和常量来实现高效的并发数据传输和管理。SPIN_FOR_TIMEOUT_THRESHOLD 用于优化短时等待的性能,SWEEP_THRESHOLD 用于维护队列的清洁和效率。
head 和 tail 指针用于维护队列的结构,支持并发访问。
needSweep 标志位用于指示何时需要清理无效节点,防止队列过度膨胀。
这些操作类型常量(NOW、ASYNC、SYNC、TIMED)简化了内部方法的调用逻辑,有助于明确不同操作模式下的行为。
3.4 LinkedTransferQueue 新增业务
3.4.1 第一种新增:操作失败抛异常
public boolean add(E e) {
xfer(e, true, ASYNC, 0L);
return true;
}3.4.2 第二种新增:操作失败返回特殊值
public boolean offer(E e) {
xfer(e, true, ASYNC, 0L);
return true;
}3.4.3 第三种新增:操作发生阻塞,一直阻塞下去,不会中断,直到新增成功为止
public void put(E e) {
xfer(e, true, ASYNC, 0L);
}3.4.4 第四种新增:操作发生阻塞,阻塞时长超出指定时长,则中断处理或者操作成功也会释放锁
public boolean offer(E e, long timeout, TimeUnit unit) {
xfer(e, true, ASYNC, 0L);
return true;
}
总结:所有队列新增的接口方式都是调用 xfer()方法,该方法就是传输队列里面的传输方法业务。
3.5 LinkedTransferQueue 删除业务
3.5.1 第一种删除:操作失败抛异常
public E remove() {
E x = poll();
if (x != null)
return x;
else
throw new NoSuchElementException();
}3.5.2 第二种删除:操作失败返回特殊值
public E poll() {
return xfer(null, false, NOW, 0L);
}3.5.3 第三种删除:操作发生阻塞,一直阻塞下去,不会中断,直到删除成功为止
public E take() throws InterruptedException {
E e = xfer(null, false, SYNC, 0L);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}3.5.4 第四种删除:操作发生阻塞,阻塞时长超出指定时长,则中断处理!或者操作成功也会释放锁
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E e = xfer(null, false, TIMED, unit.toNanos(timeout));
if (e != null || !Thread.interrupted())
return e;
throw new InterruptedException();
}
总结:删除业务方法也是调用xfer()方法进行传输,在删除业务里面是属于消费者的类型;而新增是属于生产者的类型。
3.7 LinkedTransferQueue 传输业务
xfer 方法是 LinkedTransferQueue 中的核心方法之一,用于处理元素的传输。它既可以用于将数据放入队列(传输),也可以用于从队列中获取数据。此方法支持同步和异步传输,并且可以处理带有超时的操作。
/**
* xfer 方法是 LinkedTransferQueue 中的核心方法之一,用于在生产者和消费者之间传递元素。
* 它实现了同步队列的核心逻辑,确保只有当消费者准备好接收数据时,生产者才能成功放入数据,反之亦然。
* 这个方法处理了多种场景,包括立即返回、异步操作和带超时的操作。
* @param e 要传输的元素
* @param haveData true - 生产者 | false - 消费者
* @param how 操作类型(NOW(立即返回)、ASYNC(异步操作)、SYNC(同步操作)或 TIMED(带超时的操作)。)
* @param nanos 超时时间(纳秒)
*/
private E xfer(E e, boolean haveData, int how, long nanos) {
if (haveData && (e == null)) // true 表示生产者,却没有元素传入,抛空指针异常
throw new NullPointerException();
/*
* 使用 restart 标签标记外层循环的起点。
* 这个循环在成功传输数据或发生特定条件(如超时)前一直运行。
*/
restart: for (Node s = null, t = null, h = null;;) {
// 根据节点的类型(生产者或消费者)选择起始节点。
/*
* p 节点的初始值根据当前尾节点(tail)或头节点(head)确定。
*
*/
for (Node p = ( t != (t = tail) && t.isData == haveData ) ? t : (h = head);;) {
final Node q; final Object item;
/*
* p.isData - p 节点的数据类型(生产者数据节点或消费者请求节点)
* haveData - 当前操作类型(生产者或消费者)
* 如果 p 节点的类型与当前操作(生产者或消费者)不匹配,
* 并且 haveData 的值与 p.item 是否为空相匹配,
则尝试通过tryMatch匹配该节点。如果匹配成功唤醒一条线程
*
*/
if (p.isData != haveData &&
haveData == ((item = p.item) == null)) {
if (h == null) h = head;
if (p.tryMatch(item, e)) {
if (h != p) skipDeadNodesNearHead(h, p);
return (E) item;
}
}
// 如果 p 节点的下一个节点 q 为 null,表示到达了队列的末尾
if ((q = p.next) == null) {
// 如果操作类型为 NOW,立即返回元素 e
if (how == NOW) return e;
if (s == null) s = new Node(e);
// 尝试将新节点 s 作为当前节点 p 的下一个节点(使用 casNext 方法)
if (!p.casNext(null, s)) continue;
// 如果当前节点 p 不是尾节点 t,更新尾节点为新节点 s。
if (p != t) casTail(t, s);
// 如果操作类型为 ASYNC,立即返回元素 e。
if (how == ASYNC) return e;
// 否则,调用 awaitMatch 方法等待匹配,传入新节点 s、当前节点 p、元素 e、是否带超时的标志 TIMED 和超时时间 nanos。
return awaitMatch(s, p, e, (how == TIMED), nanos);
}
if (p == (p = q)) continue restart;
}
}
} 通过这样设计,xfer 方法实现了生产者和消费者之间的同步传输机制,确保数据只有在消费者准备好接收时才能被生产者传输。
尝试在指定时间内进行匹配
/**
* awaitMatch 方法是 LinkedTransferQueue 中用于等待节点匹配的方法。该方法实现了线程在节点匹配过程中等待的逻辑,并处理超时和中断等情况。
* @param s 当前接待你
* @param pred 当前节点的前置节点
* @param e 当前元素
* @param timed 是否有超时
* @param nanos 超时时间
*/
private E awaitMatch(Node s, Node pred, E e, boolean timed, long nanos) {
final boolean isData = s.isData;
final long deadline = timed ? System.nanoTime() + nanos : 0L;
final Thread w = Thread.currentThread();
int stat = -1; // -1: may yield, +1: park, else 0
Object item;
/*
* 循环如果当前节点的元素仍然是 e,
* 继续循环匹配处理机制;
* 通过一个复杂的等待逻辑,用于在生产者和消费者之间进行匹配。它处理了如下情况:
* 【超时和中断】确保在这些情况下正确取消节点并将其从队列中移除
* 【让步和挂起】根据当前状态和上下文决定是否让步或挂起当前线程
* 【匹配成功】如果匹配成功,返回匹配的元素
*/
while ((item = s.item) == e) {
// 如果需要清理,调用 sweep 方法进行清理
if (needSweep) sweep();
// 如果超时或线程被中断,尝试取消当前节点。
else if ((timed && nanos <= 0L) || w.isInterrupted()) {
if (s.casItem(e, (e == null) ? s : null)) {
unsplice(pred, s); // cancelled
return e;
}
}
// 如果状态为 -1 或 0,尝试让步或挂起当前线程
else if (stat <= 0) {
if (pred != null && pred.next == s) {
if (stat < 0 &&
(pred.isData != isData || pred.isMatched())) {
stat = 0; // yield once if first
Thread.yield();
}
else {
stat = 1;
s.waiter = w; // enable unpark
}
} // else signal in progress
}
// 如果当前节点的元素不再是 e,退出循环。说明已经匹配到了
else if ((item = s.item) != e) break;
// 如果此时还没有超时
else if (!timed) {
LockSupport.setCurrentBlocker(this); // 设置当前线程的阻塞对象
try {
// 调用 ForkJoinPool 的 managedBlock 方法阻塞当前线程,等待匹配。
ForkJoinPool.managedBlock(s);
} catch (InterruptedException cannotHappen) { }
// 清除当前线程的阻塞对象
LockSupport.setCurrentBlocker(null);
}
// 如果有超时
else {
nanos = deadline - System.nanoTime(); // 计算剩余的超时时间。
// 如果剩余时间超过阈值,挂起当前线程指定的时间
if (nanos > SPIN_FOR_TIMEOUT_THRESHOLD)
LockSupport.parkNanos(this, nanos);
}
}
// 如果状态为 1,清除当前节点的等待者
if (stat == 1) WAITER.set(s, null);
// 如果当前节点不是数据节点,将其元素设置为自身,避免垃圾回收。
if (!isData) ITEM.set(s, s); // self-link to avoid garbage
return (E) item;
}3.8 LinkedTransferQueue 其他业务
3.8.1 获取第一个节点
final Node firstDataNode() {
Node first = null;
restartFromHead: for (;;) {
Node h = head, p = h;
while (p != null) {
if (p.item != null) {
if (p.isData) {
first = p;
break;
}
}
else if (!p.isData)
break;
final Node q;
if ((q = p.next) == null)
break;
if (p == (p = q))
continue restartFromHead;
}
if (p != h && casHead(h, p))
h.selfLink();
return first;
}
}3.8.2 统计模型中不匹配的节点
遍历给定模式中不匹配的节点并对其计数。 由方法size和getWaitingConsumerCount使用
private int countOfMode(boolean data) {
restartFromHead: for (;;) {
int count = 0;
for (Node p = head; p != null;) {
if (!p.isMatched()) {
if (p.isData != data)
return 0;
if (++count == Integer.MAX_VALUE)
break; // @see Collection.size()
}
if (p == (p = p.next))
continue restartFromHead;
}
return count;
}
}3.8.3 CAS更新业务
【更新尾部节点】如果传入的cmp 节点,是当前节点的尾部节点,就通过CAS更新尾部节点
private boolean casTail(Node cmp, Node val) {
return TAIL.compareAndSet(this, cmp, val);
}【更新头部节点】如果传入的cmp 节点,是当前节点的头部节点,就通过CAS更新头部节点
private boolean casHead(Node cmp, Node val) {
return HEAD.compareAndSet(this, cmp, val);
}【更新前置节点】如果传入的cmp 节点,是当前节点的前置节点,就通过CAS更新前置节点
private boolean tryCasSuccessor(Node pred, Node c, Node p) {
if (pred != null)
return pred.casNext(c, p);
if (casHead(c, p)) {
c.selfLink();
return true;
}
return false;
}3.8.4 跳过已匹配的节点(即“死节点”)来保持队列的连贯性和高效性
这两个方法 skipDeadNodes 和 skipDeadNodesNearHead 用于 LinkedTransferQueue 中清理已匹配的(也称为“死”)节点,以维护队列的效率和防止内存泄漏。它们通过在队列中跳过这些无效节点(已死的节点)来保持队列的连贯性和流畅性
/**
* @param pred 最后一个已知的有效节点,或者如果没有则为 null
* @param c 第一个死节点
* @param p 最后一个死节点
* @param q 下一个有效节点,或者如果在末尾则为null
*/
private Node skipDeadNodes(Node pred, Node c, Node p, Node q) {
/*
* 下面四种断言案例就是节点已死的状态
* 确保 pred 不等于 c,p 不等于 q,并且 c 和 p 都已经匹配(即是死节点)
*/
// assert pred != c;
// assert p != q;
// assert c.isMatched();
// assert p.isMatched();
// 处理 q 为空的情况
if (q == null) { // 如果 q 为 null,表示 p 是队列的末尾节点
// 如果 c 等于 p,返回 pred。否则,将 q 设置为 p
if (c == p) return pred;
q = p;
}
// 尝试 CAS 操作调用 tryCasSuccessor(pred, c, q) 尝试将 c 的后继节点从 c 更改为 q。
return (tryCasSuccessor(pred, c, q) && (pred == null || !pred.isMatched()))
? pred : p;
}
/**
* 这个方法用于从队列头部删除连续的死节点
* h 曾经是头节点的节点
* p 死节点链的最后一个节点
*/
private void skipDeadNodesNearHead(Node h, Node p) {
/*确保 h 和 p 不为 null,并且 h 不等于 p,并且 p 已经匹配(即是死节点)*/
// assert h != null;
// assert h != p;
// assert p.isMatched();
// 跳过连续的死节点
for (;;) { //使用一个无限循环来遍历从 h 到 p 的节点
final Node q;
if ((q = p.next) == null) break;
else if (!q.isMatched()) { p = q; break; }
else if (p == (p = q)) return;
}
// CAS 操作设置新的头节点;如果成功,将旧头节点 h 设置为自引用,以避免垃圾回收。
if (casHead(h, p)) h.selfLink();
}BlockingQueue 单向队列下图的所有继承结构类都大概分析了一遍;BlockingQueue 阻塞队列分别写了三篇,讲一下的子类都讲解了一遍。

各位读者大佬发现小编有错误的地方和理解不对的地方,欢迎提出!如下是单向队列的全部文章链接:
java-01-基础篇-04 Java集合-03-Queue-CSDN博客















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









