







目录
1.3 SynchronousQueue 与其他单向阻塞队列区别
1.3.2 PriorityBlockingQueue 区别
2.1.1.4 tryCancel() & isCancelled()
2.1.1.5 isOffList() & forgetWaiter() & isFulfilled()
3.3.3 第三种新增:操作发生阻塞,一直阻塞下去,不会中断,直到新增成功为止
3.3.4 第四种新增:操作发生阻塞,阻塞时长超出指定时长,则中断处理或者操作成功也会释放锁
3.4.3 第三种删除:操作发生阻塞,一直阻塞下去,不会中断,直到删除成功为止
3.4.4 第四种删除:操作发生阻塞,阻塞时长超出指定时长,则中断处理!或者操作成功也会释放锁
上一章链接:java-01-基础篇-04 Java集合-03-BlockingQueue-CSDN博客
下一章链接:java-01-基础篇-04 Java集合-03-BlockingQueue(三)-CSDN博客
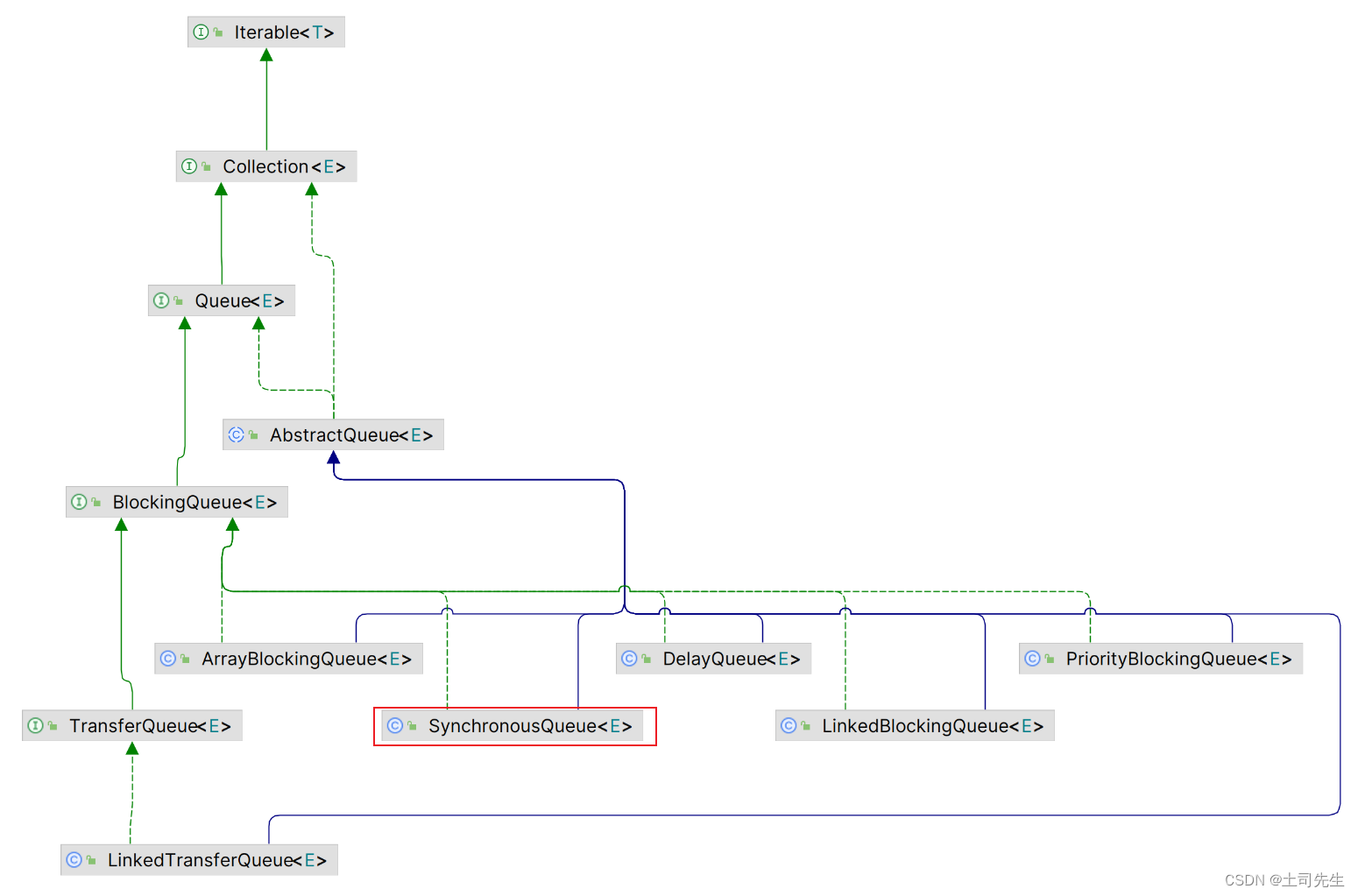
这张沿着上一章继续讲解剩余几个没有讲解完的BlockingQueue 子类阻塞队列。还剩余图中四个红圈圈的实例没有讲解。由于SynchronousQueue 同步队列涉及的内容过多;所以本章只讲解一个SynchronousQueue 同步队列,剩余三个放到下一章。

一,SynchronousQueue
1.1 SynchronousQueue 概念
SynchronousQueue 同步队列,一个比较特殊的队列;该队列是零容量,意味着内部是没有容量,存储的元素并不是在队列中等待。而是存储在内部提供的Transferer(传输队列)里面;生产者和消费者线程必须直接交接元素。
同步队列中的生产者线程必须等待消费者线程来接受元素,反之亦然。这个队列是完全同步的,每一个新增都必须等待相应的删除操作。
换句话说,SynchronousQueue 支持阻塞插入和移除操作,即 put() 和 take() 方法。在没有对应的消费者时,调用 put() 方法的线程将阻塞,直到有消费者调用 take() 方法。反之亦然。
像之前讲解到的阻塞队列实现,比如PriorityBlockingQueue, LinkedBlockingQueue,以及使用数组实现ArrayBlockingQueue, 它们的阻塞基本上都是在生产者添加元素容量满了进行阻塞,并唤醒一条正在等待消费线程进行消费;而消费者线程也是一样,等待消费元素至队列为空,后面的消费线程进行阻塞,并唤醒一条正在等待生产线程进行生产;
这样队列都是在队列容量满了,或者消费完队列容量是空的,对应的操作才会陷入阻塞;但是同步队列 SynchronousQueue 是存储一个就会进行阻塞和限制。那这样子理解的,那这个同步队列应该很简单啊,在设计时将容量直接设置成1不就完了。为什么还要在里面提供传输队列的概念设计,如下图:

得先回到SynchronousQueue同步队列得设计理念上。
首先是零容量和匹配机制;通过零容量和匹配机制来达到一种效果,就是生产者直接将数据传输给消费者;零容量解决元素以非存储而是传输的方式进行着,
匹配机制是一个生产者就直接匹配到一个消费者,并通过直接传输的方式给消费者;这传输方式强制生产者和消费者一对一匹配,消除了队列中的缓冲区。这确保了生产者和消费者的速度严格匹配,但也意味着如果一方速度过快,另一方会被迫等待。
1.2 SynchronousQueue 优点与缺点
1.2.1 SynchronousQueue 队列的优点
优点一:SynchronousQueue 由于是零容量,SynchronousQueue 没有内部缓冲区,任何 put 操作都必须等待一个 take操作。所以优点一,就是强制同步,确保生产者与消费者的操作严格匹配。
优点二:数据在生产者和消费者之间直接传输,不会再队列中积压。具有即使处理的优点;所以适用于需要立即处理数据的高并发实时性场景,比如线程池的任务提交。
1.2.2 SynchronousQueue 队列的优点
无法缓解生产者/消费者能力过剩:如果生产者生成数据的速度快于消费者处理数据的速度,生产者会被迫等待,反之亦然。这意味着生产者和消费者的性能必须大致相同,否则会导致等待和阻塞。
1.3 SynchronousQueue 与其他单向阻塞队列区别
1.3.1 SynchronousQueue 区别
SynchronousQueue 同步队列的设计目标是强制生产者与消费者一对一地直接交换数据,这种匹配机制实现生产者与消费者之间数据即使处理。
- 直接传输:每次
put操作必须等待一个对应的take操作,反之亦然。这意味着数据不会在队 列中积压,从而确保生产者和消费者的速度是严格匹配的 - 缓解速度不匹配:通过直接传输(传输队列 Transfer) 确保生产者与消费者的一一对应地直接交换数据,在一定程度上解决生产者与消费者能力一方过剩不匹配的问题。
- 适用场景:适用于希望立即处理数据并且不需要在队列中积压数据的场景,比如线程池中的任务提交
1.3.2 PriorityBlockingQueue 区别
- 优先级队列:队列中的元素根据优先级进行排序,优先级高的元素被先处理。
- 缓解速度不匹配:通过优先级排序,可以确保关键任务得到及时处理,但不会阻止低优先级任务被处理
- 适用场景:适用于任务具有不同的优先级,并且希望高优先级任务优先处理的场景。
1.3.3 LinkedBlockingQueue 区别
- 链表实现:队列长度可以是固定的或可扩展的,元素按照插入顺序存储。
- 缓解速度不匹配:通过容量限制,可以防止生产者过快生成任务导致内存溢出,同时通过阻塞机制确保消费者能逐步处理任务。
- 适用场景:适用于希望有一个有界或无界缓冲区来存储任务的场景。
1.3.4 ArrayBlockingQueue 区别
- 数组实现:队列长度是固定的,元素按照插入顺序存储。
- 缓解速度不匹配:与
LinkedBlockingQueue类似,通过固定容量和阻塞机制来平衡生产者和消费者的速度。 - 适用场景:适用于需要固定大小的缓冲区以控制内存使用的场景
1.3.5 对比与总结
- 缓冲机制:
PriorityBlockingQueue、LinkedBlockingQueue和ArrayBlockingQueue通过在队列中存储多个元素来缓冲生产者和消费者之间的速度差异。生产者可以在消费者处理速度较慢时继续添加任务,直到队列达到容量上限。 - 直接传输:
SynchronousQueue强制生产者和消费者一对一匹配,消除了队列中的缓冲区。这确保了生产者和消费者的速度严格匹配,但也意味着如果一方速度过快,另一方会被迫等待。 - 应用场景:
SynchronousQueue适用于高实时性要求的场景,而传统阻塞队列适用于需要缓冲和排序机制的场景。
1.4 SynchronousQueue 属性
package java.util.concurrent;
public class SynchronousQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** 用于版本控制,确保序列化和反序列化的兼容性 */
private static final long serialVersionUID = -3223113410248163686L;
/**
* 用于决定是否进行自旋等待,优化短时间等待的性能
* 自旋等待是一种在等待某个条件满足时不立即阻塞线程的方法,而是让线程进行若干次空操作(自旋),以减少上下文切换的开销。
* 如果等待时间(超时)小于这个阈值,线程可能会选择自旋等待而不是立即挂起,从而提高性能。自旋等待适合于预期等待时间非常短的场景
*/
static final long SPIN_FOR_TIMEOUT_THRESHOLD = 1023L;
/** 用于实现元素的直接传输,协调生产者和消费者的匹配。 */
private transient volatile Transferer<E> transferer;
}二 Transferer
Transferer是SynchronousQueue 的传输队列;用于管理元素传递。在SynchronousQueue 同步队列中由于是零容量。不允许存储元素,是没有元素容量的概念的。这一点从源代码的实现也可以得知
public boolean isEmpty() { return true; }
public int size() { return 0; }在SynchronousQueue 同步队列的size()和isEmpty()永远都是0和true;从这里也是可以看出同步队列的设计是没有容量和不存储元素的;SynchronousQueue 同步队列新增元素的时候将元素传入到Transferer 里面;调用就是transfer 传输方法;
/**
* 用于双堆栈和队列的共享内部API
*/
abstract static class Transferer<E> {
/**
*
* @param e 如果 e非空,则表示生产者传递给消费者的元素;
* 如果e为空,则表示消费者正在消费
* @param timed 是否有超时机制;
* true - 有需要在指定时间内完成
* false - 没有,无限等待
* @param nanos 超时机制的超时时间,单位为毫秒
* @return 如果操作成功,则返回传递或接收到的元素。
* 如果操作因超时或中断失败,则返回 null。
* 调用者可以通过检查 Thread.interrupted 来区分是超时还是中断导致的失败
*/
abstract E transfer(E e, boolean timed, long nanos);
}Transferer 是一个抽象类,该类定义管理元素传递的业务标准;具体的实现子类如下有两个。一个是TransferStack,TransferQueue

TransferQueue 使用 ReentrantLock 和 Condition 实现FIFO (先进先出)队列
TransferStack 使用 AtomicReference 和 自旋锁等待实现的LIFO(后进先出)堆栈
2.1 TransferQueue 传输队列
TransferQueue 是一个管理元素传递的FIFO队列。
2.1.1 QNode 节点

QNode 见名知意,是一个节点类,TransferQueue 也是通过链表的方式来实现一条先进先出(FIFO)传输队列。该类还实现ManagedBlocker 阻塞管理器接口,该ManagedBlocker 接口是ForkJoinPool的一个静态内部类,并且提供用于管理阻塞和唤醒标准业务;毕竟这个接口就是一个阻塞管理器;方法如下:
public static interface ManagedBlocker {
/**
* 此方法用于执行阻塞操作
* 返回true表示阻塞操作已完成
*/
boolean block() throws InterruptedException;
/**
* 此方法用于检查阻塞操作是否已经可以解除
* 返回 true 表示可以解除阻塞
*/
boolean isReleasable();
}2.1.1.1 QNode 的属性
QNode 从名称可以看出是一个节点,看一看具体有哪些属性
static final class QNode implements ForkJoinPool.ManagedBlocker {
/*
* 后置节点;Queue 是单向队列所以只有一个方向的节点引用
* 如果是双向的,有会prev前置节点属性
*/
volatile QNode next;
/** 节点对应的元素 */
volatile Object item;
/** 记录当前等待在此节点上的线程 */
volatile Thread waiter;
/**
* 表示节点是数据节点(生产者提供的数据)还是请求节点(消费者请求数据)
* true - 表示数据节点;生产者调用时,传递的数据不为空
* false- 表示请求节点;消费者调用时,传递的数据为空,表示请求数据
*/
final boolean isData;
/* 忽略中间部分代码 */
// VarHandle 是支持CAS操作
/** 获取节点item属性的VarHandle */
private static final VarHandle QITEM;
/** 获取节点next属性的VarHandle */
private static final VarHandle QNEXT;
/** 获取节点waiter属性的VarHandle */
private static final VarHandle QWAITER;
static { // 进行初始化获取值
try {
MethodHandles.Lookup l = MethodHandles.lookup();
QITEM = l.findVarHandle(QNode.class, "item", Object.class);
QNEXT = l.findVarHandle(QNode.class, "next", QNode.class);
QWAITER = l.findVarHandle(QNode.class, "waiter", Thread.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
}从属性上来讲,主要分为两个部分一部分是 next,item,waiter,isData 等业务上需要的属性,毕竟是节点,所以节点的业务是需要后置节点,节点存储的内容 item, 当前节点处理等待的线程 waiter, 当前操作是生产调用还是消费者调用 isData;
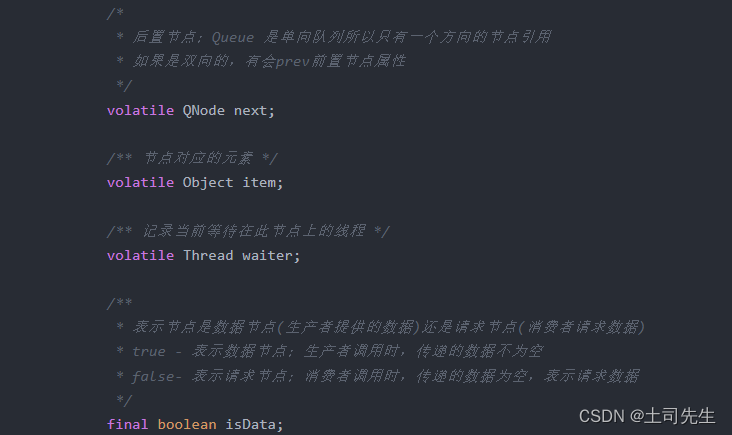
还有一分部就是CAS业务需要的属性,获取对应的VarHandle 属性;用于CAS 等操作设置属性内容。

2.1.1.2 QNode 构造器
QNode(Object item, boolean isData) {
this.item = item;
this.isData = isData;
}2.1.1.3 QNode 的CAS更新业务
【更新后置节点】如果传入的cmp 节点,是当前节点的后置节点,就通过CAS更新后置节点
/**
* 如果传入的cmp 节点,是当前节点的后置节点,就通过CAS更新后置节点
* @param cmp 传入的节点
* @param val 要设置的新后置节点
*/
boolean casNext(QNode cmp, QNode val) {
return next == cmp && QNEXT.compareAndSet(this, cmp, val);
}【更新节点内容】如果传入的cmp 内容,是当前节点的内容,就通过CAS更新节点内容
/**
* 如果传入的cmp 内容,是当前节点的内容,就通过CAS更新节点内容
* @param cmp 传入的内容
* @param val 要设置的内容
*/
boolean casItem(Object cmp, Object val) {
// 只有cmp 传入的值是当前节点的item时,才进行CAS操作赋值
return item == cmp && QITEM.compareAndSet(this, cmp, val);
}2.1.1.4 tryCancel() & isCancelled()
两个方法的作用在于实现节点的取消操作,确保节点能够正确地被移除或者处理。代码如下
/** 节点被移除的方式就是将当前节点设置成item属性的内容 */
boolean tryCancel(Object cmp) {
return QITEM.compareAndSet(this, cmp, this);
}
/** 判断节点是否被移除的依据也是通过item是否等于当前节点 */
boolean isCancelled() {
return item == this;
}2.1.1.5 isOffList() & forgetWaiter() & isFulfilled()
/** 判断后置节点是否被移除 */
boolean isOffList() {
return next == this;
}
/** 移除waiter等待线程,将waiter属性设置为null */
void forgetWaiter() {
QWAITER.setOpaque(this, null);
}
/** 检查当前节点是否已经完成了任务 */
boolean isFulfilled() {
Object x;
return isData == ((x = item) == null) || x == this;
}2.1.2 TransferQueue 属性
static final class TransferQueue<E> extends Transferer<E> {
/** 队列头节点 */
transient volatile QNode head;
/** 队列尾节点 */
transient volatile QNode tail;
/** 用于暂时保存需要清理的节点 */
transient volatile QNode cleanMe;
// VarHandle mechanics 获取对应属性的VarHandle 提供CAS操作
private static final VarHandle QHEAD;
private static final VarHandle QTAIL;
private static final VarHandle QCLEANME;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
QHEAD = l.findVarHandle(TransferQueue.class, "head", QNode.class);
QTAIL = l.findVarHandle(TransferQueue.class, "tail", QNode.class);
QCLEANME = l.findVarHandle(TransferQueue.class, "cleanMe", QNode.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
}TransferQueue 队列的属性和QNode 节点数据分布是一致的,也可以理解成分为两个部分。一个部分是链表业务需要的属性,一个部分是CAS业务需要的部分。
cleanMe 属性表示可能要清除的节点数据,当检测到队列中的某个节点可能出现“垃圾节点”(通常是由于线程被中断或超时导致的未完成传递操作),这个节点会被赋值给 cleanMe。下一次尝试清理时,会有限处理cleanMe 指向的节点。
通过 cleanMe 属性,避免每次清理时都从头遍历队列。它指向上一次清理过程中发现但未能立即处理的节点,在下次清理时可以直接进行处理,从而提高清理效率。
2.1.3 TransferQueue 构造器
/**
* 得到了一个初始状态下只包含头节点的空队列。
* 在队列中添加或移除元素时,会根据具体的逻辑对头节点和尾节点进行相应的操作
*/
TransferQueue() {
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
}2.1.4 TransferQueue 更新业务
【更新头部链表节点】如果传入的h 节点,是当前节点的头部节点,就通过CAS更新头部节点;更新完成之后,移除之前原来的h头部节点;通过GC进行回收
/**
* 如果传入的h 节点,是当前节点的头部节点,就通过CAS更新头部节点
* @param h 原头部节点
* @param nh 要设置的新节点头部
*/
void advanceHead(QNode h, QNode nh) {
if (h == head &&
QHEAD.compareAndSet(this, h, nh))
h.next = h; // 移除原头部的next后置节点,后面通过GC 进行回收
}【更新尾部链表节点】如果传入的t 节点,是当前节点的尾部节点,就通过CAS更新尾部节点;
/**
* 如果传入的t 节点,是当前节点的尾部节点,就通过CAS更新尾部节点;
* @param h 原尾部节点
* @param nh 要设置的新节点尾部
*/
void advanceTail(QNode t, QNode nt) {
if (tail == t)
QTAIL.compareAndSet(this, t, nt);
}【更新CleanMe属性】如果传入的cmp 节点,是当前节点的cleanMe(可能需要被清除节点),通过CAS更新cleanMe(可能需要被清除节点);
/**
* 如果传入的cmp 节点,是当前节点的cleanMe(可能需要被清除节点),通过CAS更新cleanMe(可能需要被清除节点)
* @param cmp cleanMe(可能需要被清除节点)
* @param nh 要设置的新的cleanMe(可能需要被清除节点)
*/
boolean casCleanMe(QNode cmp, QNode val) {
return cleanMe == cmp && QCLEANME.compareAndSet(this, cmp, val);
}2.1.4 TransferQueue 清除业务
clean 方法用于清理传输队列中的节点,这个方法的作用是将指定的节点 s从传输队列中删除。在删除节点 s之前,会先执行一些额外的操作来确保删除操作的正确性。
- 第一步:清除记录当前等待在此节点上的线程;
- 第二步:清除当前节点的head节点;清除方式将头部节点设置成当前节点(this);由GC回收
- 第三步:清除当前节点的tail节点;清除方式将尾部节点设置成当前节点(this);由GC回收
- 第四步:如果要清除的节点不是尾部节点,尝试从传输队列中删除
- 第五步:清除TransferQueue 传输队列的 cleanMe 属性,上面记录着线程中断异常待清除的节点
源代码如下
/**
* 清除节点
* @param pred 要清除节点的前置节点
* @param s 要清除的节点
*/
void clean(QNode pred, QNode s) {
// 【第一步】清除记录当前等待在此节点上的线程
s.forgetWaiter();
/*
* while (pred.next == s)
* 这个条件在多线程环境中用于检查节点 s 是否仍然在待清理的位置。
*/
while (pred.next == s) {
/*
* 【第二步】清除当前节点的head节点;
* 清除方式将头部节点设置成当前节点(this);由GC回收
*/
QNode h = head;
QNode hn = h.next;
if (hn != null && hn.isCancelled()) {
advanceHead(h, hn);
continue;
}
/*
* 【第三步】清除当前节点的tail节点;
* 清除方式将尾部节点设置成当前节点(this);由GC回收
*/
QNode t = tail; // Ensure consistent read for tail
if (t == h)
return;
QNode tn = t.next;
if (t != tail)
continue;
if (tn != null) {
advanceTail(t, tn);
continue;
}
// 【第四步】如果要清除的节点不是尾部节点,尝试从传输队列中删除
if (s != t) { // If not tail, try to unsplice
QNode sn = s.next;
if (sn == s || pred.casNext(s, sn))
return;
}
/*
* 【第五步】清除TransferQueue 传输队列的 cleanMe 属性;
* 上面记录着线程中断异常待清除的节点
*/
QNode dp = cleanMe;
if (dp != null) { // Try unlinking previous cancelled node
QNode d = dp.next;
QNode dn;
if (d == null || // d is gone or
d == dp || // d is off list or
!d.isCancelled() || // d not cancelled or
(d != t && // d not tail and
(dn = d.next) != null && // has successor
dn != d && // that is on list
dp.casNext(d, dn))) // d unspliced
casCleanMe(dp, null);
if (dp == pred)
return; // s is already saved node
} else if (casCleanMe(null, pred))
return; // Postpone cleaning s
}
}
2.1.5 TransferQueue 传输业务
transfer 方法的主要功能是将元素从生产者传递给消费者,或者从消费者获取元素。
/**
*
* @param e 如果 e非空,则表示生产者传递给消费者的元素;
* 如果e为空,则表示消费者正在消费
* @param timed 是否有超时机制;
* true - 有需要在指定时间内完成
* false - 没有,无限等待
* @param nanos 超时机制的超时时间,单位为毫秒
* @return 如果操作成功,则返回传递或接收到的元素。
* 如果操作因超时或中断失败,则返回 null。
* 调用者可以通过检查 Thread.interrupted 来区分是超时还是中断导致的失败
*/
E transfer(E e, boolean timed, long nanos) {
QNode s = null;// 节点引用,用于构造或重用节点
// 标记是否为生产者节点(true 为生产者,false 为消费者)
boolean isData = (e != null);
for (;;) {
/*
* tail 和 head:队列的尾部和头部节点。
* m 和 tn:用于在操作中保存中间节点
*/
QNode t = tail, h = head, m, tn; // m is node to fulfill
if (t == null || h == null)
/* 检查 tail 和 head 是否为 null(不应发生),跳过不一致情况 */;
/** 处理队列为空或包含相同模式节点的情况 */
else if (h == t || t.isData == isData) {
if (t != tail)// 尾部节点不一致,表示有更新
;
else if ((tn = t.next) != null) // tail存在后置节点,尝试更新后置节点
advanceTail(t, tn);
else if (timed && nanos <= 0L) // 超时时间已到
return null;
/* t.casNext 使用 CAS 操作尝试将新节点添加到队列中 */
else if (t.casNext(null, (s != null) ? s :
(s = new QNode(e, isData)))) {
advanceTail(t, s); // 更新尾部节点
// 计算超时时间
long deadline = timed ? System.nanoTime() + nanos : 0L;
// 获取当前等待线程
Thread w = Thread.currentThread();
// 初始化传输变量值stat
int stat = -1; // same idea as TransferStack
Object item;
while ((item = s.item) == e) {
// 检查超时或中断
if ((timed && (nanos = deadline - System.nanoTime()) <= 0) ||
w.isInterrupted()) {
if (s.tryCancel(e)) { // 若满足则尝试取消节点并清理
clean(t, s);
return null;
}
} else if ((item = s.item) != e) { // 如果节点已被满足,跳出循
break;
} else if (stat <= 0) { // 如果状态未初始化,则进行初始化
if (t.next == s) {
if (stat < 0 && t.isFulfilled()) {
stat = 0; // yield once if first
Thread.yield();
}
else {
stat = 1;
s.waiter = w;
}
}
// 如果未设置超时,则使用 ForkJoinPool.managedBlock 进行阻塞等待
} else if (!timed) {
LockSupport.setCurrentBlocker(this);
try {
ForkJoinPool.managedBlock(s);
} catch (InterruptedException cannotHappen) { }
LockSupport.setCurrentBlocker(null);
}
// 否则,使用 LockSupport.parkNanos 进行定时等待
else if (nanos > SPIN_FOR_TIMEOUT_THRESHOLD)
LockSupport.parkNanos(this, nanos);
}
if (stat == 1)
s.forgetWaiter(); // 清理等待状态
if (!s.isOffList()) {//如果节点未被取消,更新 head 并清理节点字段。d
advanceHead(t, s);
if (item != null)
s.item = s;
}
return (item != null) ? (E)item : e;
}
// 如果队列中包含等待节点且 head 和 tail 没有变化,尝试满足等待节点
} else if ((m = h.next) != null && t == tail && h == head) {
Thread waiter;
Object x = m.item;
// 使用 CAS 操作尝试满足等待节点
boolean fulfilled = ((isData == (x == null)) &&
x != m && m.casItem(x, e));
advanceHead(h, m); // 更新head
if (fulfilled) { // 如果成功满足,唤醒等待线程并返回结果
if ((waiter = m.waiter) != null)
LockSupport.unpark(waiter);
return (x != null) ? (E)x : e;
}
}
}
}
2.2 TransferStack 传输队列
TransferStack 使用 AtomicReference 和 自旋锁等待实现的LIFO(后进先出)堆栈。这个传输队列是由Stack 栈结构实现的
2.2.1 SNode
SNode是 TransferStack 内部类;SNode节点是组成TransferStack 栈结构的节点
2.2.1.1 SNode 的属性
static final class SNode implements ForkJoinPool.ManagedBlocker {
volatile SNode next; // 后置节点
volatile SNode match; // 用于指向与当前节点匹配的节点,完成数据交换
volatile Thread waiter; // to control park/unpark
Object item; // 节点元素
int mode; // 数据模式
/* 忽略部分代码 */
// VarHandle mechanics 获取对应字段属性的VarHandle类,该类支持CAS操作
private static final VarHandle SMATCH;
private static final VarHandle SNEXT;
private static final VarHandle SWAITER;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
SMATCH = l.findVarHandle(SNode.class, "match", SNode.class);
SNEXT = l.findVarHandle(SNode.class, "next", SNode.class);
SWAITER = l.findVarHandle(SNode.class, "waiter", Thread.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
}
2.2.1.2 SNode 的构造器
SNode(Object item) {
this.item = item;
}SNode 节点的构造器,只提供一个传入元素的构造器,至于其他的next, waiter等属性都没有提供。
2.2.1.3 SNode CAS 处理业务
设置后置节点
/**
* 通过CAS 将新val 覆盖 cmp 节点;前提是cmp真的是next(后置节点)
* @param cmp 比较节点
* @param val 新节点
*/
boolean casNext(SNode cmp, SNode val) {
return cmp == next &&
SNEXT.compareAndSet(this, cmp, val);
} tryMatch(SNode s) 方法的主要目的是尝试将当前节点与传入的节点 s 进行匹配。如果当前节点尚未匹配过其他节点,则通过 CAS 操作将 s 设置为当前节点的匹配节点,并唤醒等待线程。如果已经匹配过其他节点,则返回当前节点的匹配结果。
boolean tryMatch(SNode s) {
SNode m;
Thread w;
// 检查当前节点的 match 字段是否为 null,即当前节点是否尚未匹配
if ((m = match) == null) {
// 如果当前节点尚未匹配,尝试将 match 字段从 null 设置为传入的节点 s
if (SMATCH.compareAndSet(this, null, s)) {
// 如果设置成功,并且 waiter 字段不为 null,唤醒等待线程
if ((w = waiter) != null)
LockSupport.unpark(w);
return true; // 匹配成功
} else {
// 如果设置失败,说明有其他线程已经设置了 match 字段,重新获取 match 字段
m = match;
}
}
// 返回当前 match 字段是否等于传入的节点 s
return m == s;
}
tryCancel 方法是一个简单但关键的原子操作,用于尝试取消当前节点。通过使用 CAS 操作,将 match 字段从 null 更新为当前节点自身,标记节点为已取消状态,从而确保线程间的正确同步和资源管理。
/**
* Tries to cancel a wait by matching node to itself.
*/
boolean tryCancel() {
return SMATCH.compareAndSet(this, null, this);
}判断是否取消当前节点也是通过是否等于当前节点。
boolean isCancelled() {
return match == this;
}2.2.2 TransferStack 属性
static final class TransferStack<E> extends Transferer<E> {
static final int REQUEST = 0; // 表示节点是一个消费者节点,等待接收数据
static final int DATA = 1; // 表示节点是一个生产者节点,等待提供数据
static final int FULFILLING = 2; // 表示节点处于完成状态
volatile SNode head; // 头部节点
// VarHandle mechanics 获取头部节点的VarHandle ,该类支持CAS操作
private static final VarHandle SHEAD;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
SHEAD = l.findVarHandle(TransferStack.class, "head", SNode.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
/* 忽略部分代码 */
}2.2.3 TransferStack 更新头部节点
boolean casHead(SNode h, SNode nh) {
return h == head &&
SHEAD.compareAndSet(this, h, nh);
}2.2.4 TransferStack 清除节点
void clean(SNode s) {
s.item = null; // forget item
s.forgetWaiter();
/*
* At worst we may need to traverse entire stack to unlink
* s. If there are multiple concurrent calls to clean, we
* might not see s if another thread has already removed
* it. But we can stop when we see any node known to
* follow s. We use s.next unless it too is cancelled, in
* which case we try the node one past. We don't check any
* further because we don't want to doubly traverse just to
* find sentinel.
*/
SNode past = s.next;
if (past != null && past.isCancelled())
past = past.next;
// Absorb cancelled nodes at head
SNode p;
while ((p = head) != null && p != past && p.isCancelled())
casHead(p, p.next);
// Unsplice embedded nodes
while (p != null && p != past) {
SNode n = p.next;
if (n != null && n.isCancelled())
p.casNext(n, n.next);
else
p = n;
}
}2.2.5 TransferStack 创建SNode节点
static SNode snode(SNode s, Object e, SNode next, int mode) {
if (s == null) s = new SNode(e);
s.mode = mode;
s.next = next;
return s;
}2.2.6 TransferStack 传输业务
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
if (h == null || h.mode == mode) { // empty or same-mode
if (timed && nanos <= 0L) { // can't wait
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) {
long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int stat = -1; // -1: may yield, +1: park, else 0
SNode m; // await fulfill or cancel
while ((m = s.match) == null) {
if ((timed &&
(nanos = deadline - System.nanoTime()) <= 0) ||
w.isInterrupted()) {
if (s.tryCancel()) {
clean(s); // wait cancelled
return null;
}
} else if ((m = s.match) != null) {
break; // recheck
} else if (stat <= 0) {
if (stat < 0 && h == null && head == s) {
stat = 0; // yield once if was empty
Thread.yield();
} else {
stat = 1;
s.waiter = w; // enable signal
}
} else if (!timed) {
LockSupport.setCurrentBlocker(this);
try {
ForkJoinPool.managedBlock(s);
} catch (InterruptedException cannotHappen) { }
LockSupport.setCurrentBlocker(null);
} else if (nanos > SPIN_FOR_TIMEOUT_THRESHOLD)
LockSupport.parkNanos(this, nanos);
}
if (stat == 1)
s.forgetWaiter();
Object result = (mode == REQUEST) ? m.item : s.item;
if (h != null && h.next == s)
casHead(h, s.next); // help fulfiller
return (E) result;
}
} else if (!isFulfilling(h.mode)) { // try to fulfill
if (h.isCancelled()) // already cancelled
casHead(h, h.next); // pop and retry
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) { // loop until matched or waiters disappear
SNode m = s.next; // m is s's match
if (m == null) { // all waiters are gone
casHead(s, null); // pop fulfill node
s = null; // use new node next time
break; // restart main loop
}
SNode mn = m.next;
if (m.tryMatch(s)) {
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
s.casNext(m, mn); // help unlink
}
}
} else { // help a fulfiller
SNode m = h.next; // m is h's match
if (m == null) // waiter is gone
casHead(h, null); // pop fulfilling node
else {
SNode mn = m.next;
if (m.tryMatch(h)) // help match
casHead(h, mn); // pop both h and m
else // lost match
h.casNext(m, mn); // help unlink
}
}
}
}三 WaitQueue
同步队列里面的WaitQueue 队列,这个队列是用来维护一个等待线程的队列,当某个线程需要等待某个条件时,会被添加到这个队列中。当条件满足时,从等待队列总移除一个或多个线程,并唤醒它们。
在同步队列里面的这个WaitQueue 有两个具体的实现子类:

从这两个子类名称也可以看出一个是LIFO(后进先出) LifoWaitQueue 等待队列;一个是FIFO(先进先出) FifoWaitQueue 等待队列;这两个队列分别维护不同方向的等待队列。
3.1 SynchronousQueue 属性
SynchronousQueue 同步队列的内部类讲解完毕之后,接下来讲解同步队列的属性。
package java.util.concurrent;
public class SynchronousQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** 序列号,用于序列化 */
private static final long serialVersionUID = -3223113410248163686L;
/** */
static final long SPIN_FOR_TIMEOUT_THRESHOLD = 1023L;
/** 传输队列 */
private transient volatile Transferer<E> transferer;
/** 锁 */
private ReentrantLock qlock;
/** 生产者等待队列 */
private WaitQueue waitingProducers;
/** 消费者等待队列 */
private WaitQueue waitingConsumers;
static {
// Reduce the risk of rare disastrous classloading in first call to
// LockSupport.park: https://bugs.openjdk.java.net/browse/JDK-8074773
Class<?> ensureLoaded = LockSupport.class;
}
}3.2 SynchronousQueue 构造器
/**
* 无参构造,默认使用栈结构的传输队列(LIFO)
*/
public SynchronousQueue() {
this(false);
}
/**
* 指定使用哪种传输队列
* @param fair true - TransferQueue(FIFO) | false - TransferStack(LIFO)
*/
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
3.3 SynchronousQueue 新增业务
3.3.1 第一种新增:操作失败抛异常
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}3.3.2 第二种新增:操作失败返回特殊值
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
return transferer.transfer(e, true, 0) != null;
}3.3.3 第三种新增:操作发生阻塞,一直阻塞下去,不会中断,直到新增成功为止
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}3.3.4 第四种新增:操作发生阻塞,阻塞时长超出指定时长,则中断处理或者操作成功也会释放锁
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, true, unit.toNanos(timeout)) != null)
return true;
if (!Thread.interrupted())
return false;
throw new InterruptedException();
}3.4 SynchronousQueue 删除业务
3.4.1 第一种删除:操作失败抛异常
public E remove() {
E x = poll();
if (x != null)
return x;
else
throw new NoSuchElementException();
}3.4.2 第二种删除:操作失败返回特殊值
public E poll() {
return transferer.transfer(null, true, 0);
}3.4.3 第三种删除:操作发生阻塞,一直阻塞下去,不会中断,直到删除成功为止
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}3.4.4 第四种删除:操作发生阻塞,阻塞时长超出指定时长,则中断处理!或者操作成功也会释放锁
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E e = transferer.transfer(null, true, unit.toNanos(timeout));
if (e != null || !Thread.interrupted())
return e;
throw new InterruptedException();
}四 【面试题】
4.1 生产者或者消费者一方能力过剩或者能力不足怎么处理?
首先Java阻塞队列只能保持生产者与消费者之间正常工作,解决了重复消费或者重复生产的问题。对于生产者还是消费者能力过剩问题,不属于Java 阻塞队列里面的业务问题。因为这是属于队列资源分配问题。跟队列本身的业务并无关,Java 阻塞队列本身的业务只需要做到生产的数据能被正确的消费掉。不会出现重复生产或者重复消费等问题。保证数据生产与消费之间正确业务流程即可。
所以,对于生产者或者消费者一方能力过剩或者太弱怎么处理这个问题是属于一些资源分配业务的问题,像这种问题,最直接的就是生产者能力过剩就追加消费者,生产者能力不足,就减少消费者;或者引入一些池化概念进行复用与扩充队列资源。也可以通过引入一些权重的概念进行分配队列。专业俗语描述如下:
-
增加或减少消费者或生产者线程
增加消费者线程
如果生产者的能力过剩,导致队列中积压了大量的数据,可以考虑增加消费者线程的数量,以加快数据的处理速度。
增加生产者线程
如果消费者的能力过剩,导致队列中数据耗尽,可以考虑增加生产者线程的数量,以增加数据的生产速度。
- 调整队列的容量
扩大队列容量
如果队列容量过小,导致生产者频繁阻塞,可以增加队列的容量,使其能够容纳更多的数据。
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(100); // 调整容量
- 使用自适应的负载均衡策略
根据系统的负载情况动态调整生产者和消费者的数量。例如,可以使用线程池来管理生产者和消费者线程,并根据负载情况动态调整线程池的大小
ExecutorService producerPool = Executors.newFixedThreadPool(producerCount);
ExecutorService consumerPool = Executors.newFixedThreadPool(consumerCount);
-
实现优先级队列
如果有些任务比其他任务更重要,可以使用 PriorityBlockingQueue 来确保重要任务优先处理
-
使用流控机制
在生产者和消费者之间实现流控机制。例如,可以通过某种协议让消费者通知生产者当前的负载情况,生产者根据反馈调整生产速度。
- 增加中间层缓冲区
可以增加一个中间层缓冲区,用来暂时存储生产者的数据,当消费者忙不过来时,这个缓冲区可以起到缓冲的作用。
- 分批处理
如果消费者的处理能力有限,可以考虑将生产者的数据分批处理,以减少消费者的负担。















 647
647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









