







Chapter6 Graph Neural Networks in Practice
讨论应用、优化问题、损失函数和正则化的使用
6.1 Applications and Loss Functions
GNNs的主要应用:
- node classification 节点分类
- 如预测用户是否为机器人
- graph classification 图分类
- 如基于分子结构的性质预测
- relation prediction 关系预测
- 如线上平台的内容推荐
参数:
- z u z_u zu:最后一层GNN的节点嵌入
- z G z_G zG:通过池化函数产生的graph-level嵌入
6.1.1 GNNs for Node Classification
全监督的形式训练GNNs
- 用softmax classification和negative log-likelihood loss来定义损失函数
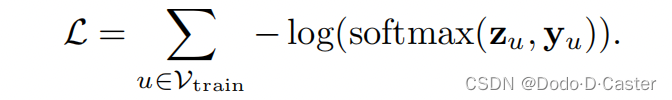
- $Y_u$:one-hot vector
- 指示训练节点u的类别
- softmax($Z_u,Y_u$):节点u属于类别$Y_u$的预测的可能性
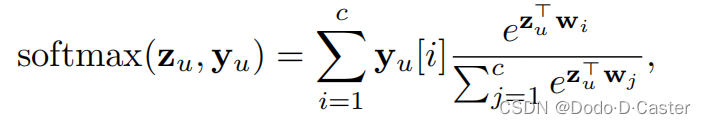
- $w_i$:可训练的参数
训练节点:消息传递中包含的节点同时也被用来计算损失
转换测试节点:一些节点没有标签,虽然会被用于消息传递时生成hidden representation,但输出的最后一层嵌入中这些节点不会用于损失函数的计算
归纳测试节点:既不用于消息传递也不用于损失函数
6.1.2 GNNs for Graph Classification
方法1:softmax classification loss
- 不同点在于该损失是通过标签好的图的graph-level嵌入计算的
方法2:squared-error loss

- MLP:具有单变量输出的密连接神经网络
- y G i yG_i yGi:训练图 G i G_i Gi的目标值
6.1.3 GNNs for Relation Prediction
方法:采用Chapter3&4里面的pairwise node embedding loss functions
6.1.4 Pre-training GNNs
如对节点分类的损失微调之前,预先训练GNN来重建缺失的边
在GNN中,由于消息传递过程以及很好地encode邻居信息,所以pre-training的效果不佳,但是在DGI中表现很好
Pre-training损失函数:让GNN模型可以学习生成能够区分真实的图和它的损坏部分的节点嵌入??
6.2 Efficiency Concerns and Node Sampling
node-level消息传递方程如果直接实现在计算上很低效(因为很多节点会有共同邻居)
6.2.1 Graph-level Implementations
基本思想:基于稀疏矩阵乘法来实现消息传递操作
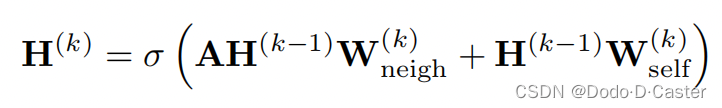
- H ( k ) H^{(k)} H(k):包含了k层图中所有节点的嵌入的矩阵
- 优点:没有冗余计算
- 缺点:
- 需要对整个图和所有节点特征进行操作,会占用很大的内存
- 限制了one to full-batch gradient descent
6.2.2 Subsampling and Mini-Batching
为了限制内存占用和方便mini-batch training,可以采用节点的子集来进行消息传递。
- 在图中每个patch的子集上计算node-level GNN equation
- 挑战:
- 不能只跑每个子集的消息传递而不计算损失
- 每次移除一个节点,需要同时移除对应的边,不能保证选择的随机子集能构成一个连通的图
- 为每个mini-batch选择随机子集不利于模型的性能
- 解决方式:subsampling node neighborhoods
- 基本思想:首先为一个batch选择目标节点集合,然后递归地采样这些集合的邻居来确保图的连通性
6.3 Parameter Sharing and Regularization
GNN正则化方法
- 标准正则化方法
- L2 Regularization
- dropout
- layer normalization
- 针对GNN的正则化方法
- Parameter Sharing Across Layers
- 在GNN的所有AGGREGATE和UPDATE方法上使用相同的参数
- 对于大于6层的GNN最有效
- Edge Dropout
- 在训练过程中随机丢弃邻接矩阵中的边
- 使GNN不容易过拟合
- 增加GNN对于邻接矩阵中的噪音的鲁棒性
- 适合知识图谱和GAT
- 在训练过程中随机丢弃邻接矩阵中的边
- Parameter Sharing Across Layers















 2102
2102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









