







Basic Concept
在进行预测时会产生error,但是error是怎么产生的呢?
(1)bias:有可能是偏置导致的 。(距离靶心有多远)
(2)variance:方差,有可能是Loss Function导致的(在靶心的分散程度)
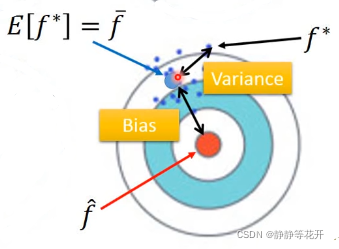
蓝点:在训练集中抽取N个数据,训练出一个函数f*,既一个点代表某一分采样数据训练后的的function。
对每个训练出来的f*取平均值,得到“平均函数”。f*距离“平均函数”的距离代表了variance,距离靶心(最佳函数)的距离就是bias。
我们对数据集进行100次采样训练出了100个函数。
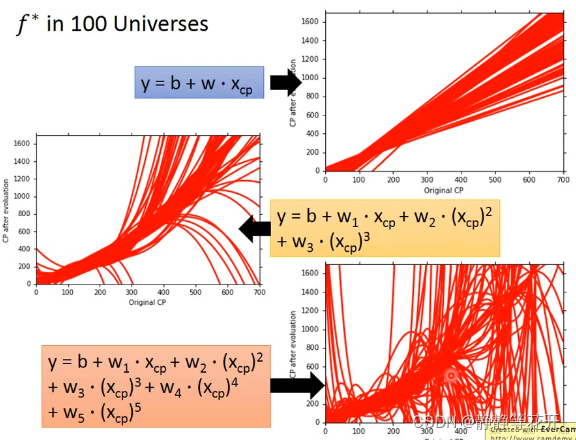
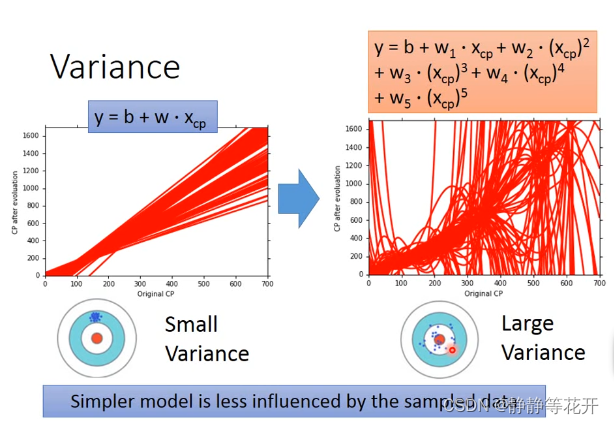
可以看出当model较为简单时,Bias会比较大,Variance会比较小。当model比较复杂时,Bias会比较小,Variance会比较大。
(1)因为当model教为简单时,最佳function可能不在选取得model中,所以Bias会比较大;而因为model比较简单,所以每次找出来的function都是差不多的,所以variance比较小。
(2)当model较为复杂时,最佳function在model中,虽不能确定哪一个是最佳model,会在最佳function周围靠近,所以BIasi会比较小。而因为model比较复杂,所以每次找出来的function相差较大,所以variance比较大。
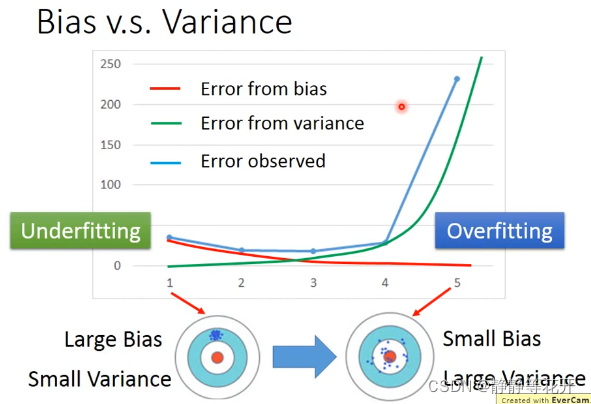
纵坐标表示Erro,横坐标表示function复杂程度。
当复杂程度越高,bias会减小,但是variance会增大;
当error来自于variance过高,来自于bias过低时,称为Overfitting(过拟合)。
当error来自于variance过低,来自于bias过高时,称为Underfitting(欠拟合)。
What to do with large bias?
应该重新设计Model:
(1)添加更多的特征值feature作为输入
(2)换成一个更复杂的Model
What to do with large variance?
(1)More data,应该扩大训练集数据
(2)Regularization,正则化,让function更加平滑。【我的理解,当函数平滑之后,对输入数据敏感度下降,所以对于不同采样结果函数之间会更加紧凑】
Model Selection
存在问题:
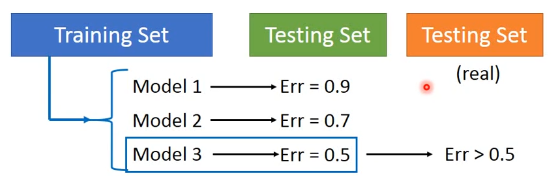 当我在Training Set 上训练出了三个Model,在测试自己的Testing Set,选取了erro最小的Model 3,但在用于外界没见过的Testing Set时,erro往往大于0.5.
当我在Training Set 上训练出了三个Model,在测试自己的Testing Set,选取了erro最小的Model 3,但在用于外界没见过的Testing Set时,erro往往大于0.5.
解决:
(1)Cross Validation 交叉验证

将Training Set分为两个部分:训练集和验证集
用训练集去训练Model,再用验证集去评判Model,选出Model3,可以在将整个Training Set用来训练Model 3;在用自己的Testing Set测试时的结果会更接近外界Testing Set的测试结果。
(2)N-fold Cross Validation N次交叉验证
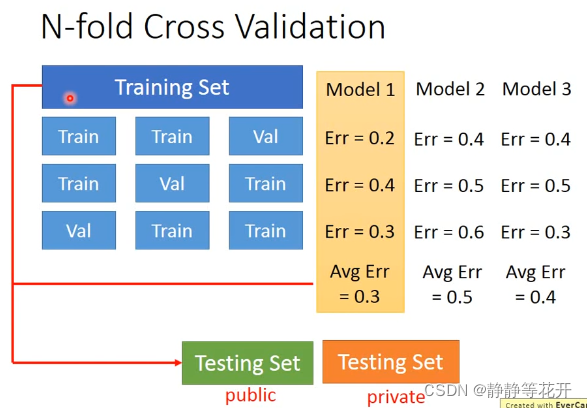
将Training Set分成不同的Train1、Train2和Val,用不同的Train1、Train2训练,用val去验证,选取较好的Model1。再将Model 1放入到整个Training Set里去训练。在用自己的Testing Set测试时的结果会更接近外界Testing Set的测试结果。















 2025
2025











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









