









李宏毅机器学习03:误差Error

文章目录
ML Lecture 2 Where does the error come from
一、Bias & Variance 偏差和方差
1.误差的来源
从上节课测试集数据来看,Average Error 随着模型复杂增加呈指数上升趋势。更复杂的模型并不能给测试集带来更好的效果,而这些Error 的主要有两个来源,分别是 bias(偏差) 和 variance(方差) 。

2.偏差和方差的理解
以打靶为例理解偏差和误差:
假设真实的模型为 f ^ \hat f f^,通过 step1~step3 训练得到的模型是 f ∗ f^* f∗, f ∗ f^* f∗是 f ^ \hat f f^ 的预估。
将此过程类比打靶, f ^ \hat f f^ 是目标靶心, f ∗ f^* f∗是我们射击的结果。
如下图所示, f ^ \hat f f^ 和 f ∗ f^* f∗之间蓝色部分的差距就是偏差和方差导致的。
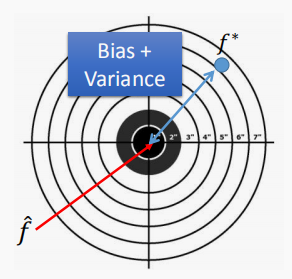
射击点距离靶心近则偏差小,射击点偏离靶心远则偏差大;
射击点集中则方差小,射击点分散则方差大。
如下图所示:

3.偏差和方差出现的原因
Training data 是所有数据的一个子集,通过Training data 训练模型去预测Testing data 相当于统计学中通过样本预测总体。
设总体的期望为
μ
\mu
μ,方差为
σ
2
\sigma^2
σ2, 样本的统计量:样本均值为
ξ
ˉ
\bar \xi
ξˉ 和样本方差
S
2
S^2
S2。
通常情况:
ξ ˉ = 1 n ∑ i = 1 n ξ i ≠ μ \bar\xi=\frac{1}{n}\displaystyle\sum_{i=1}^n\xi_i\not =\mu ξˉ=n1i=1∑nξi=μ
S 2 = = 1 n ∑ i = 1 n ( ξ i − ξ ˉ ) 2 ≠ σ 2 S^2==\frac{1}{n}\displaystyle\sum_{i=1}^n(\xi_i-\bar\xi)^2\not =\sigma^2 S2==n1i=1∑n(ξi−ξˉ)2=σ2
-
Bias of Estimator 偏差的估算:
通过多个样本估计,样本均值是无偏估计量
E ( ξ ˉ ) = μ E(\bar\xi)=\mu E(ξˉ)=μ

-
Variance of Estimator 方差的估算:
通过多个样本估计,样本方差是有偏估计量,修正样本方差是无偏估计量
E ( S 2 ) = n − 1 n σ 2 E(S^2)=\frac{n-1}{n}\sigma^2 E(S2)=nn−1σ2

4.模型的偏差和方差
对100个样本采取不同模型:
-
y = b + w ⋅ x c p y=b+w\cdot x_{cp} y=b+w⋅xcp

-
y = b + w 1 ⋅ x c p + w 2 ⋅ x c p 2 + w 3 ⋅ x c p 3 y=b+w_1\cdot x_{cp}+w_2\cdot x_{cp}^2+w_3\cdot x_{cp}^3 y=b+w1⋅xcp+w2⋅xcp2+w3⋅xcp3

-
y = b + w 1 ⋅ x c p + w 2 ⋅ x c p 2 + w 3 ⋅ x c p 3 + w 4 ⋅ x c p 4 + w 5 ⋅ x c p 5 y=b+w_1\cdot x_{cp}+w_2\cdot x_{cp}^2+w_3\cdot x_{cp}^3+w_4\cdot x_{cp}^4+w_5\cdot x_{cp}^5 y=b+w1⋅xcp+w2⋅xcp2+w3⋅xcp3+w4⋅xcp4+w5⋅xcp5

(1)Bias偏差
一次模型的偏差较大,而复杂的五次模型,偏差较小。

(2)Variance方差
一次模型的方差较小,分布比较集中,离散程度较小。而五次模型的方差较大,散布比较广,离散程度较大。
模型简单,方差较小;模型复杂,方差较大
原因:简单模型受到不同训练集的影响比较小。

二、What to do with error 误差的处理
Bias v.s. Variance 偏差和方差对比
将误差拆分为偏差和方差。简单模型(左边)是偏差比较大造成的误差,这种情况叫做欠拟合,而复杂模型(右边)是方差过大造成的误差,这种情况叫做过拟合。
因此,理想的模型应该是介于欠拟合和过拟合之间的,误差最小的模型。

1.Large bias - underfitting偏差大 - 欠拟合
- Diagnosis判断方法:
训练集在模型上没有得到好的结果。 - What to do with large bias 解决方法:
redesign your model 重新设计模型:- Add more features as input
将更多的特征作为输入加入模型 - A more complex model
设计一个更复杂的模型
- Add more features as input

2.Large variance - Overfitting 方差大 - 过拟合
- What to do with large variance 解决方法:
- More data更多的数据
但是很多时候不一定能做到收集更多的数据。可以针对对问题的理解对数据集做调整。 - Regularization正则化
y = ∑ i = 1 n ( y i ^ − ( b + w ⋅ x c p i ) ) 2 + λ ∑ ( w i ) 2 y=\displaystyle\sum_{i=1}^n\big(\hat{y^i}-(b+w\cdot x_{cp}^i)\big)^2+\color{blue}\lambda\sum(w_i)^2 y=i=1∑n(yi^−(b+w⋅xcpi))2+λ∑(wi)2
- More data更多的数据

三、Model Selection模型的选择
因为现有测试集并不是完整的测试集,所以通过现有测试集选择的模型可能在实际数据集上的表现并不理想。因此在模型的选择上可以采取交叉验证、k-折交叉验证等方法。

1.Cross Validation 交叉验证
将训练集分成两份:
Training Set 训练集,Validation Set验证集

2.K-fold Cross Validation k折交叉验证
将训练集分成N份,比如分成3份,选取一份作为验证集

















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











