










系列文章目录
前言
一、效果展示:
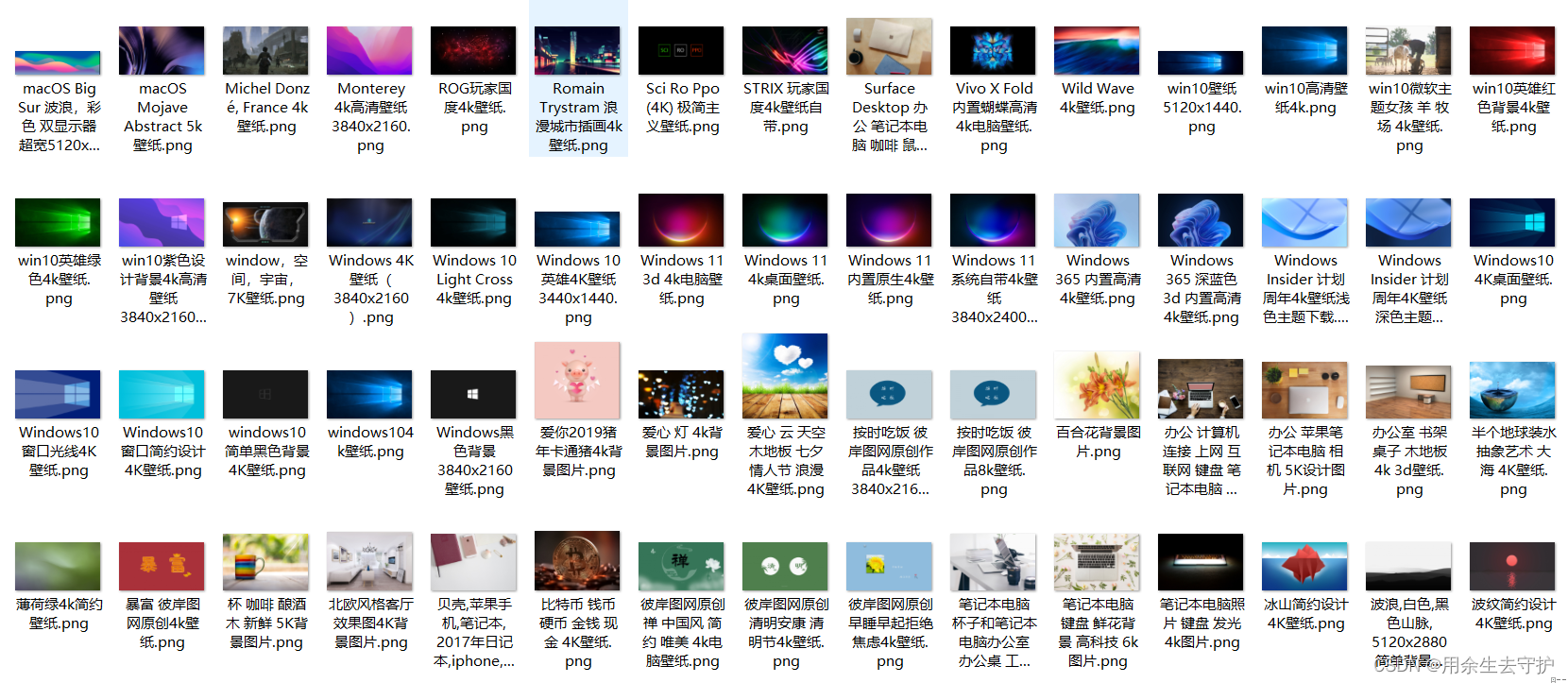
二、使用步骤
1.复制源码并修改路径
代码如下(示例):
from lxml.html import etree
import requests
from PIL import Image
import os
import sys
path = './tutu4'
if not os.path.exists(path):
os.makedirs(path)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url_list = []
area = input('请输入类别:')
if area.find('美女')>=0:
area = '4kmeinv'
elif area.find('风景')>=0:
area = '4kfengjing'
elif area.find('游戏')>=0:
area = '4kyouxi'
elif area.find('动漫')>=0:
area = '4kdongman'
elif area.find('影视')>=0:
area = '4kyingshi'
elif area.find('明星')>=0:
area = '4kmingxing'
elif area.find('汽车')>=0:
area = '4kqiche'
elif area.find('动物')>=0:
area = '4kdongwu'
elif area.find('人物')>=0:
area = '4krenwu'
elif area.find('美食')>=0:
area = '4kmeishi'
elif area.find('宗教')>=0:
area = '4kzongjiao'
elif area.find('背景')>=0:
area = '4kbeijing'
else:
print('输入关键词格式不正确')
sys.exit(0)
page = int(input('请输入页数:'))
for i in range(0,page+1):
i = int(i)
if i==1:
url = 'http://pic.netbian.com/'+ area +'/index.html'
res = requests.get(url=url,headers=headers)
res.encoding = res.apparent_encoding # 修改编码
response = etree.HTML(res.text)
response = etree.tostring(response)
response = etree.fromstring(response) # 以上搭建xpath对象
content = response.xpath('//ul[@class="clearfix"]/li')
for i in content:
tu_url = i.xpath('./a/@href')
tupian_url = 'http://pic.netbian.com'+ ''.join(tu_url)
url_list.append(tupian_url)
elif i>=1:
i = str(i)
url = 'http://pic.netbian.com/' + area + '/index_' + i + '.html'
res = requests.get(url=url,headers=headers)
res.encoding = res.apparent_encoding # 修改编码
response = etree.HTML(res.text)
response = etree.tostring(response)
response = etree.fromstring(response) # 以上搭建xpath对象
content = response.xpath('//ul[@class="clearfix"]/li')
for i in content:
tu_url = i.xpath('./a/@href')
tupian_url = 'http://pic.netbian.com'+ ''.join(tu_url)
url_list.append(tupian_url)
for i in url_list:
r = requests.get(url=i, headers=headers)
r.encoding = r.apparent_encoding # 修改编码
html = etree.HTML(r.text)
html = etree.tostring(html)
html = etree.fromstring(html) # 以上搭建xpath对象
url = html.xpath(r'//a[@id="img"]/img/@src')
rr = requests.get('http://pic.netbian.com' + ''.join(url), headers=headers)
name = html.xpath(r'//a[@id="img"]/img/@title')
rr.encoding = rr.apparent_encoding # 修改编码
with open(f"./tutu4/{''.join(name)}" + '.png', 'wb') as fw:
fw.write(rr.content)
img = Image.open(f"./tutu4/{''.join(name)}" + '.png')
img = img.resize((4000, 2000), Image.ANTIALIAS) # 改变大小 抗锯齿
# print(img.size)
img.save(f"./tutu4/{''.join(name)}" + '.png', quality=95)
print(str(name) + " 保存完成!")
print("保存完成!")
2. python运行即可!
总结
分享:
写作是心灵的自我对话一—它有着诸多的约束条件,因此并不是所有的人在任何时段、任何环境下都适合写作。没有思想骨架作为支撑,任何文字都只是一种软体的堆积。对于一个作者而言,什么时候都可以写,问题在于想不想写。

















 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











