







参考简介
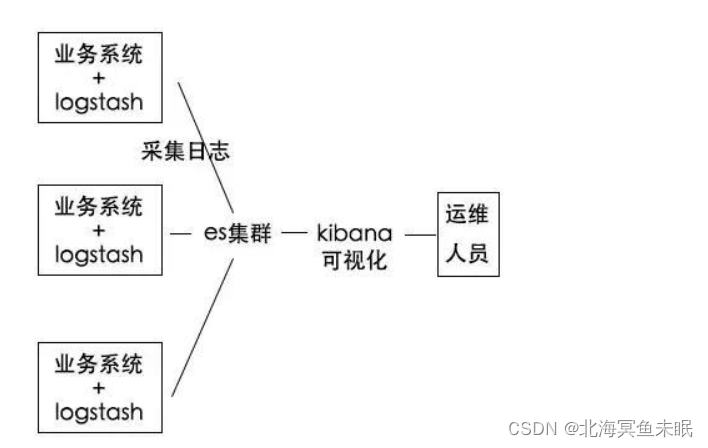
Elasticsearch 是由 Elastic 公司创建的,Elasticsearch 是一个非常强大的搜索引擎。同时,Elastic 公司也拥有 Logstash 及 Kibana 开源项目,这个三个项目组合在一起,就形成了 ELK 软件栈。他们三个共同形成了一个强大的生态圈。简单地说,Logstash 负责数据的采集,处理(丰富数据,数据转换等),Kibana 负责数据展示,分析,管理,监督及应用。Elasticsearch 处于最核心的位置,它可以帮我们对数据进行快速地搜索及分析。
ElasticSearch的下载安装
下载地址
下载完成之后解压即可。
目录结构:
配置文件:
jvm参数设置:默认是1g、1g,由于机器原因,这里我把它改成512M,节省内存。
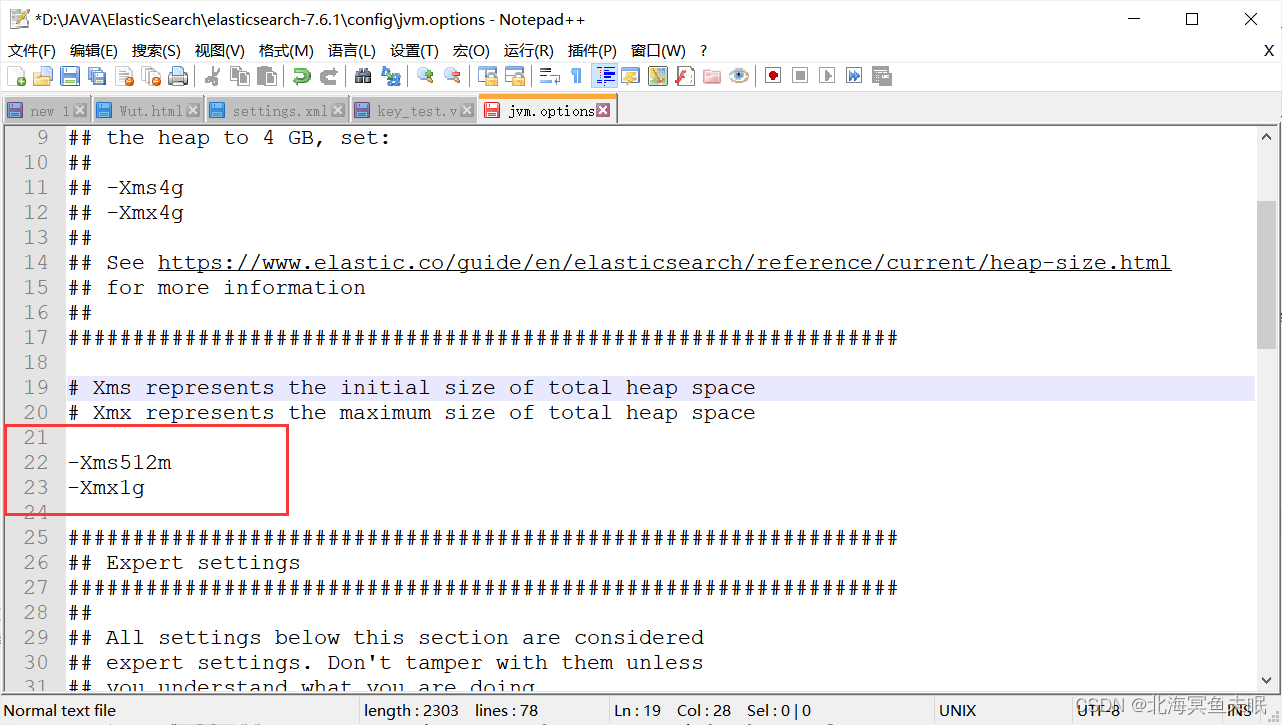
ES的配置文件,默认端口9200

lib目录下都是一些工具包:

启动ElasticSearch
在lib目录下启动
启动成功:
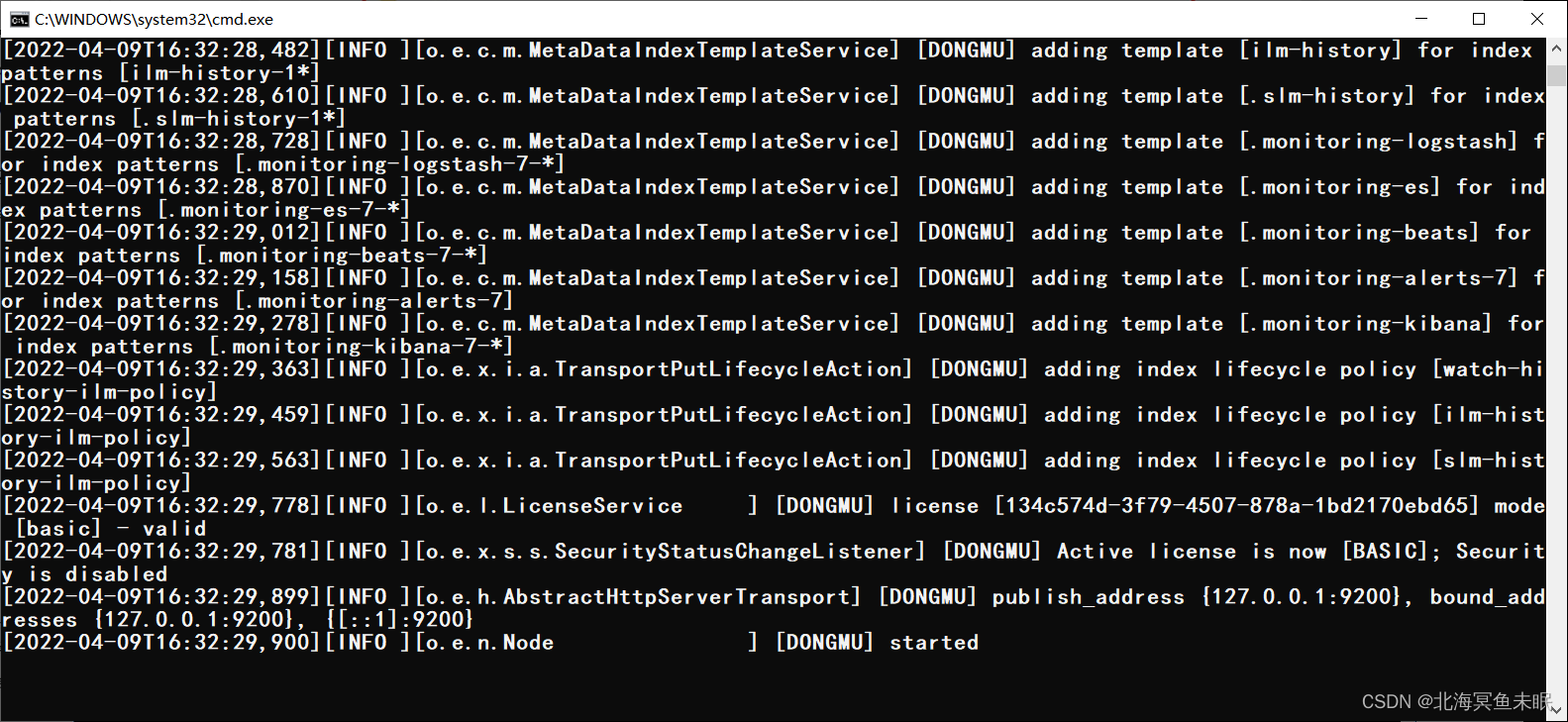
访问测试:
head插件安装
下载地址
下载之后解压
这里要用到nodejs的环境

安装完之后启动即可
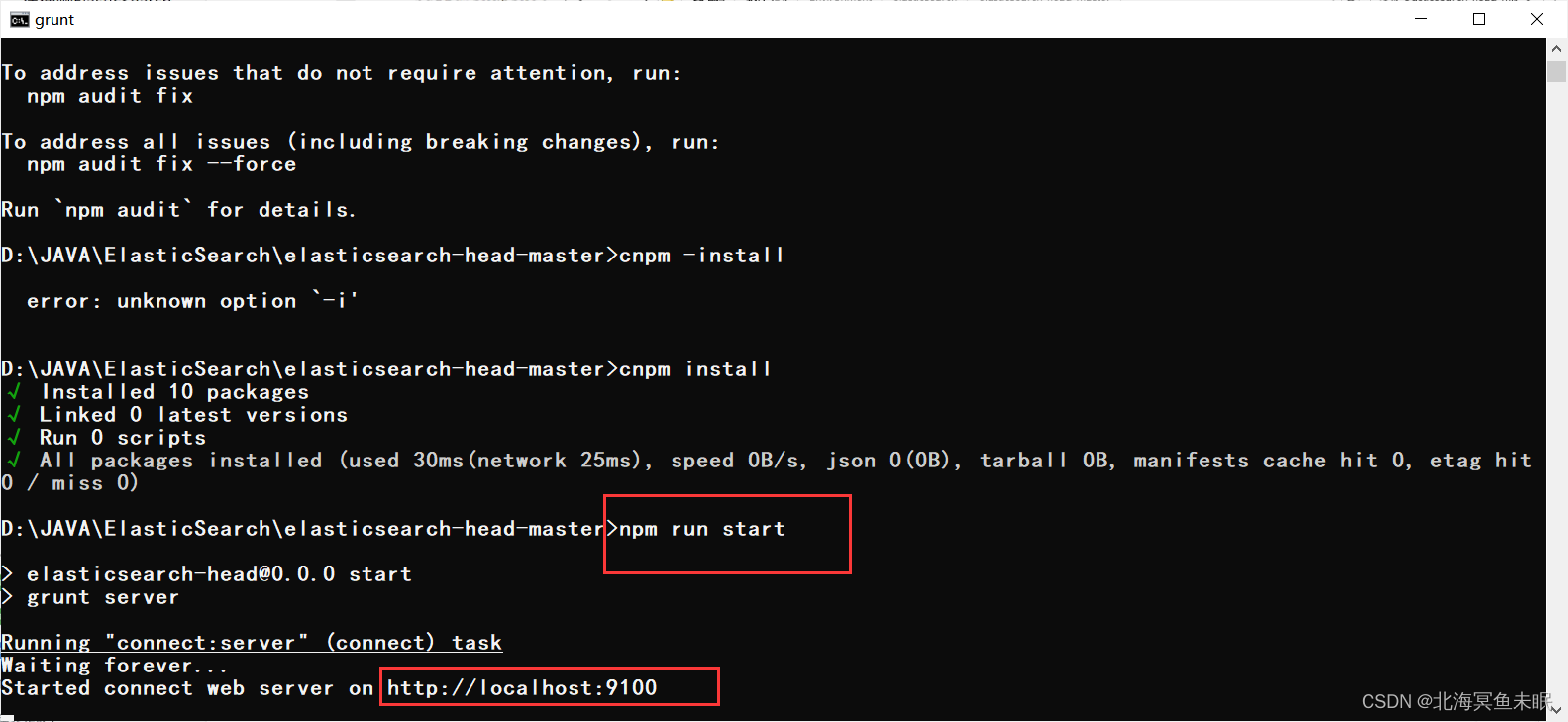
访问测试:
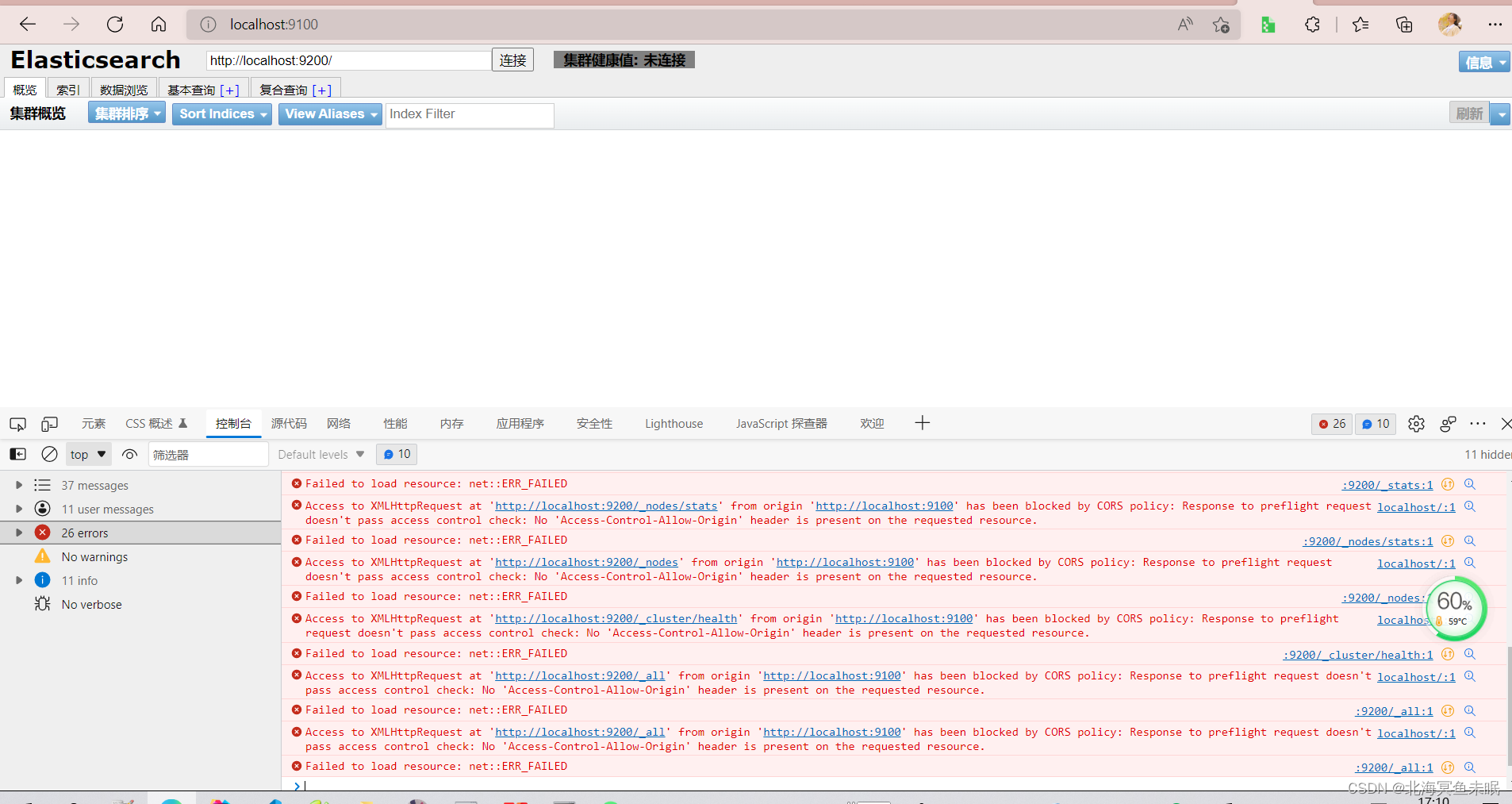
可以发现这里存在一个跨域问题。
解决方式:
在elasticSearch的配置文件中添加两行:
http.cors.enabled: true
http.cors.allow-origin: "*"。
之后重启es。
这时候就可以发现连接成功。
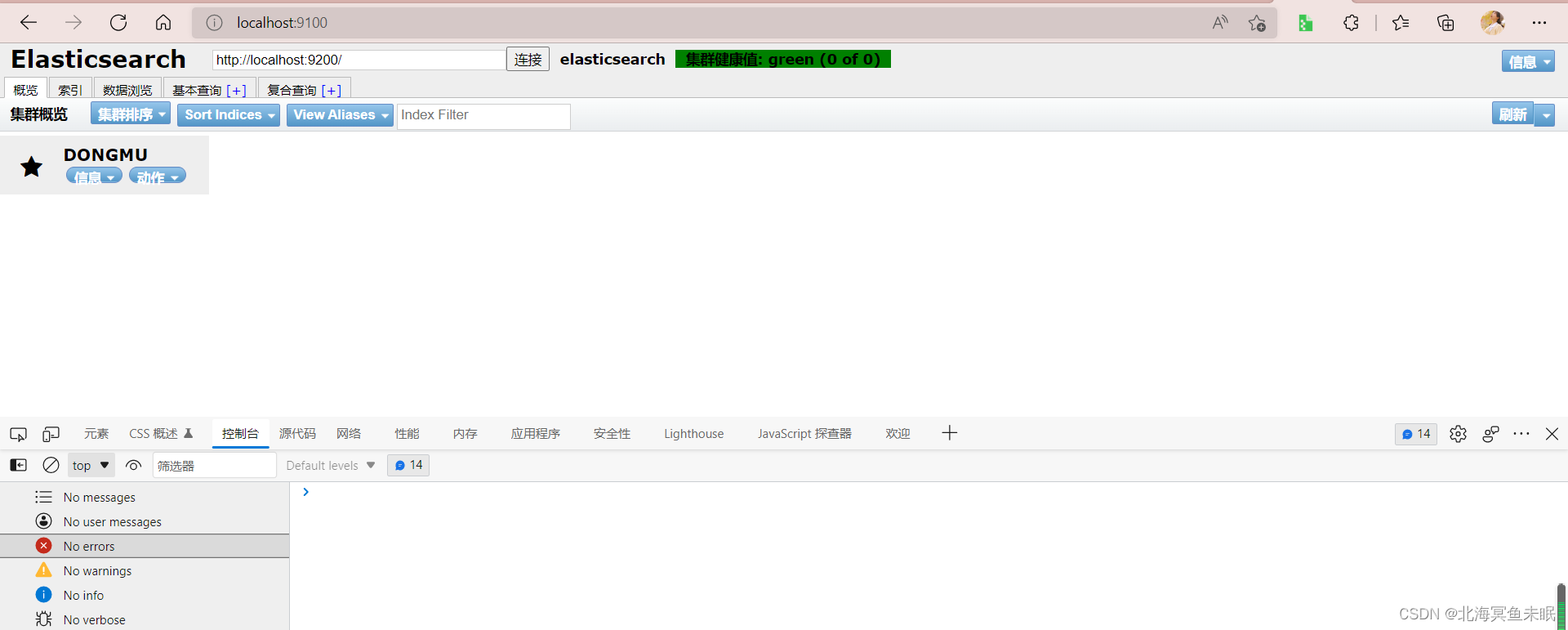
我们可以把head当作一个数据库查询的可视化的工具来用。
安装Kibana
下载地址
要注意版本和es版本一致。
下载完成之后解压,要解压很久
找到bin目录,启动bat文件
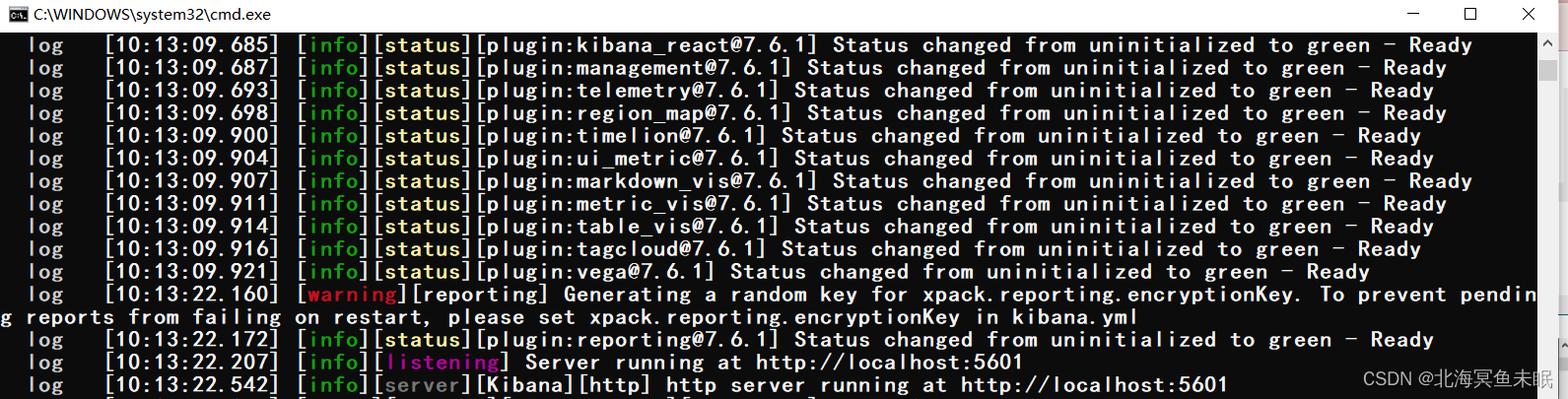
访问端口
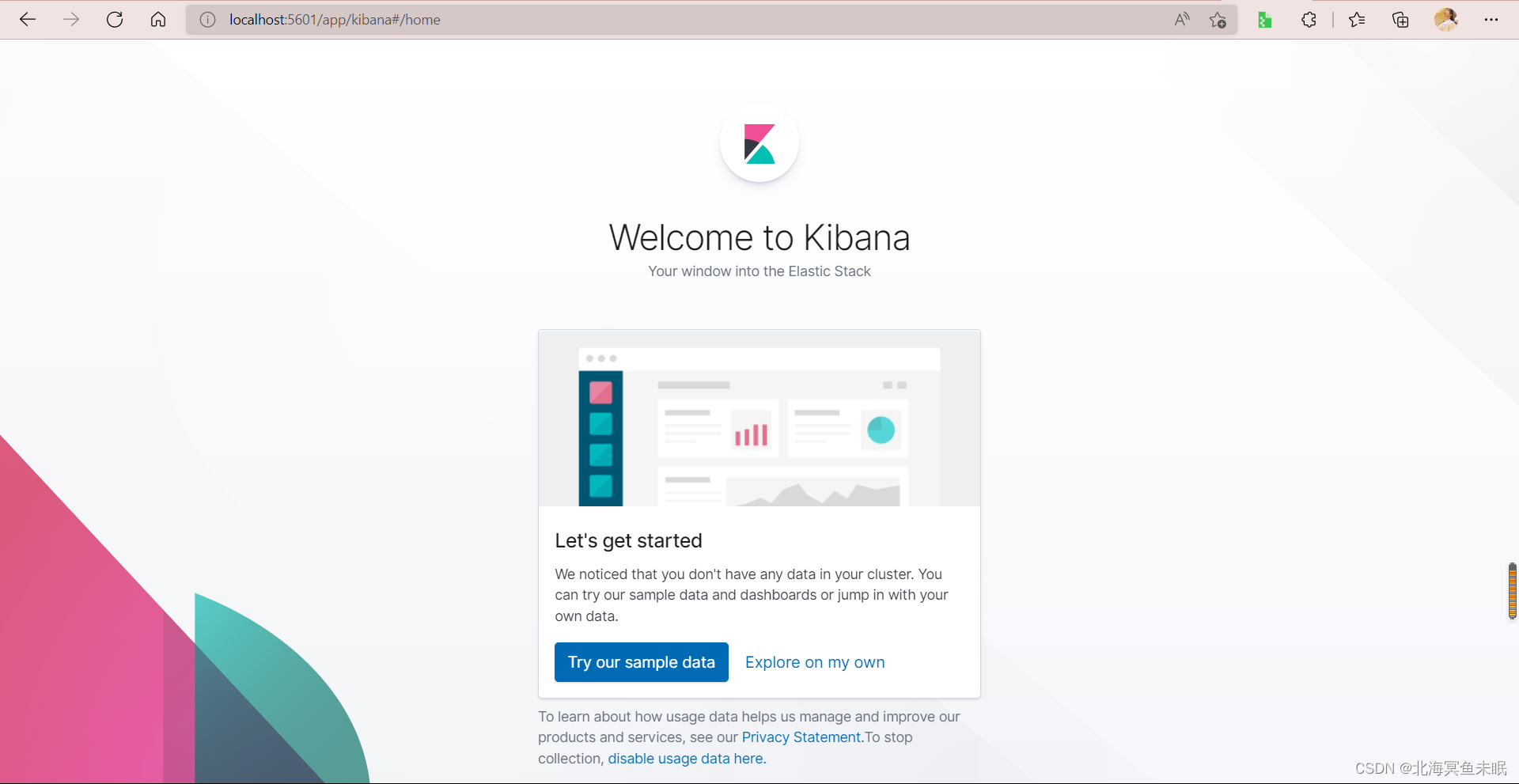
可以发现默认这里是英文的,我们需要把改成中文。

IK分词器
下载完成后解压至下面的目录中

然后重启elasticSearch。注意如果重启闪退说明你的plugins下面还有其他文件,不要有其他无关的文件。
重启之后就可以看到加载插件了;
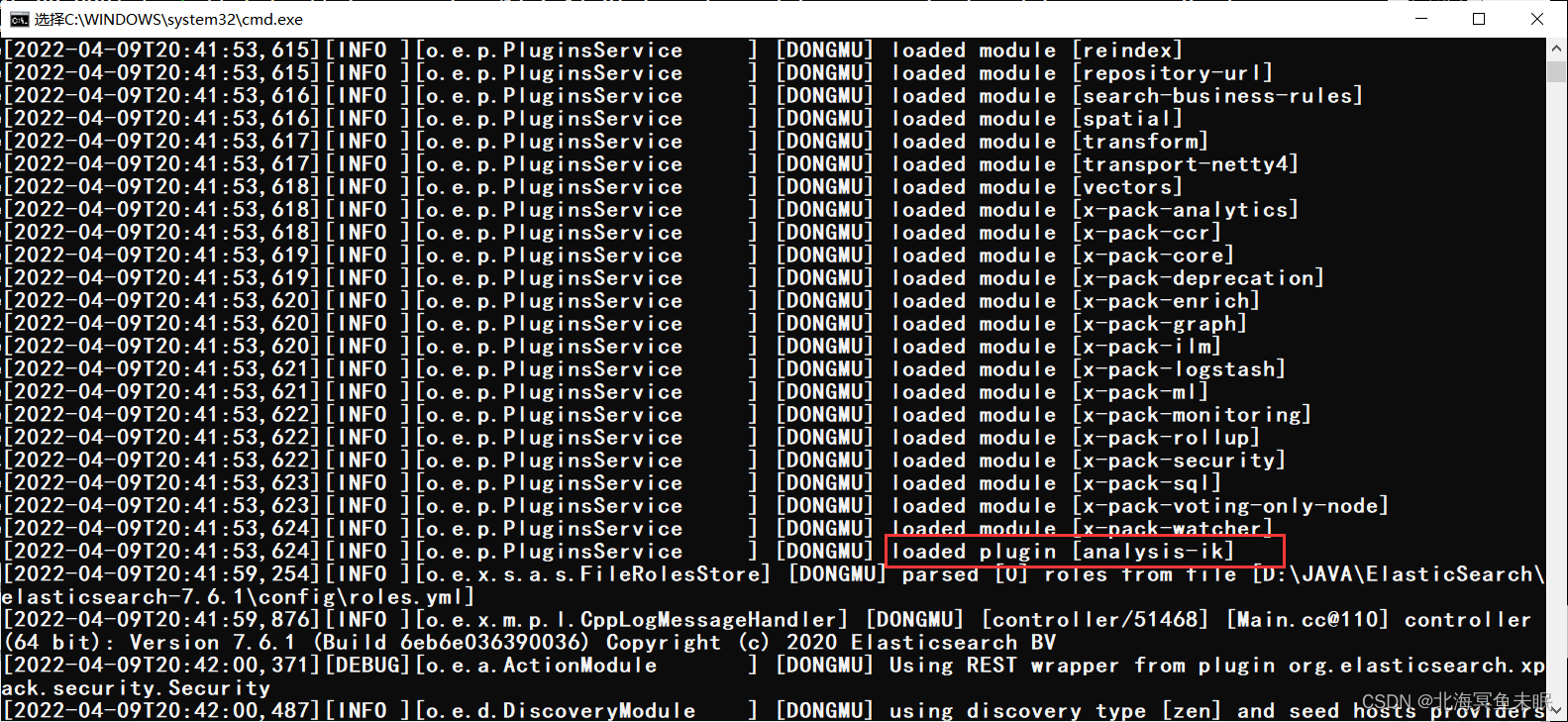
也可以在响应的目录下利用命令来查看我们的插件
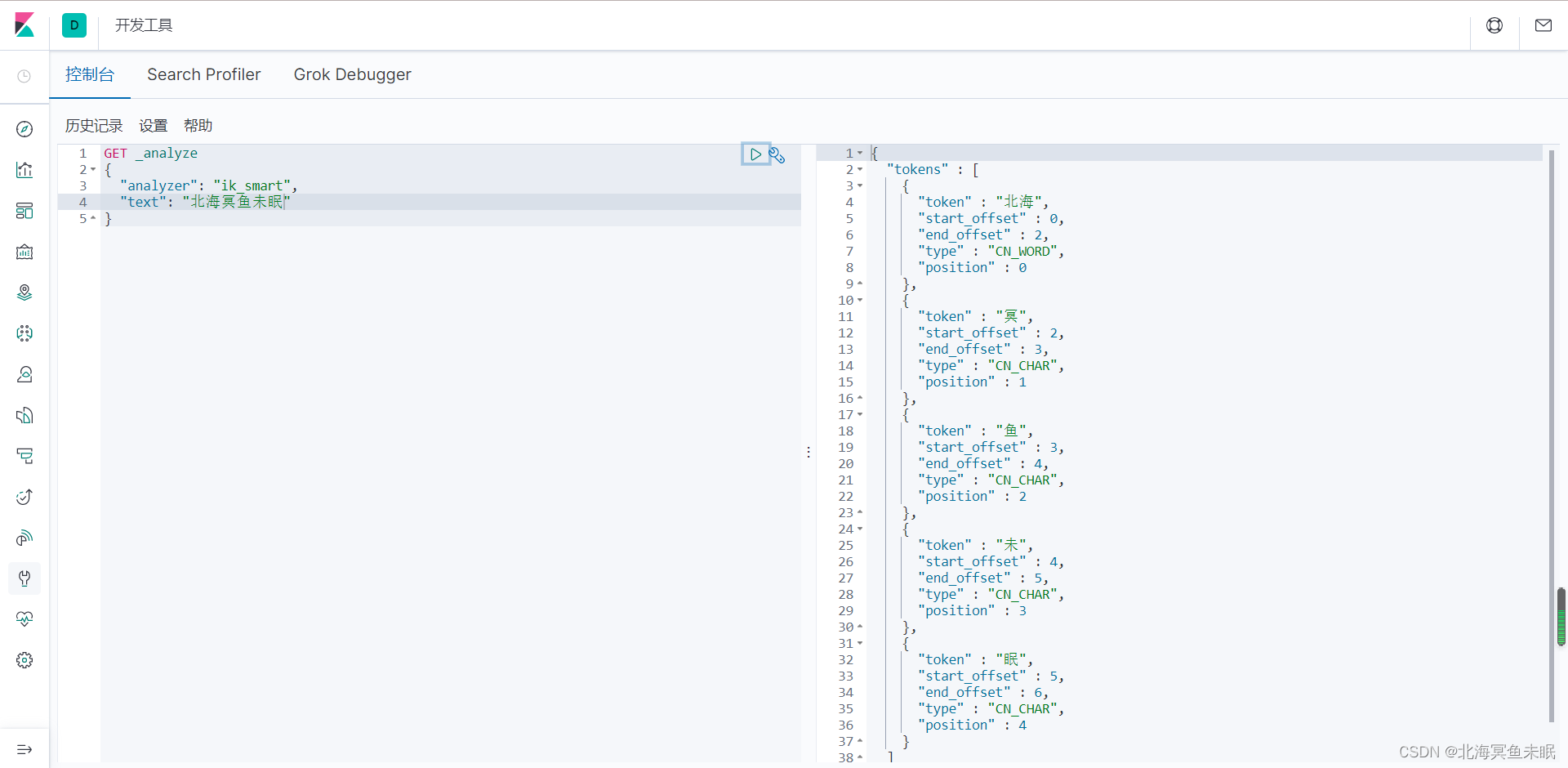
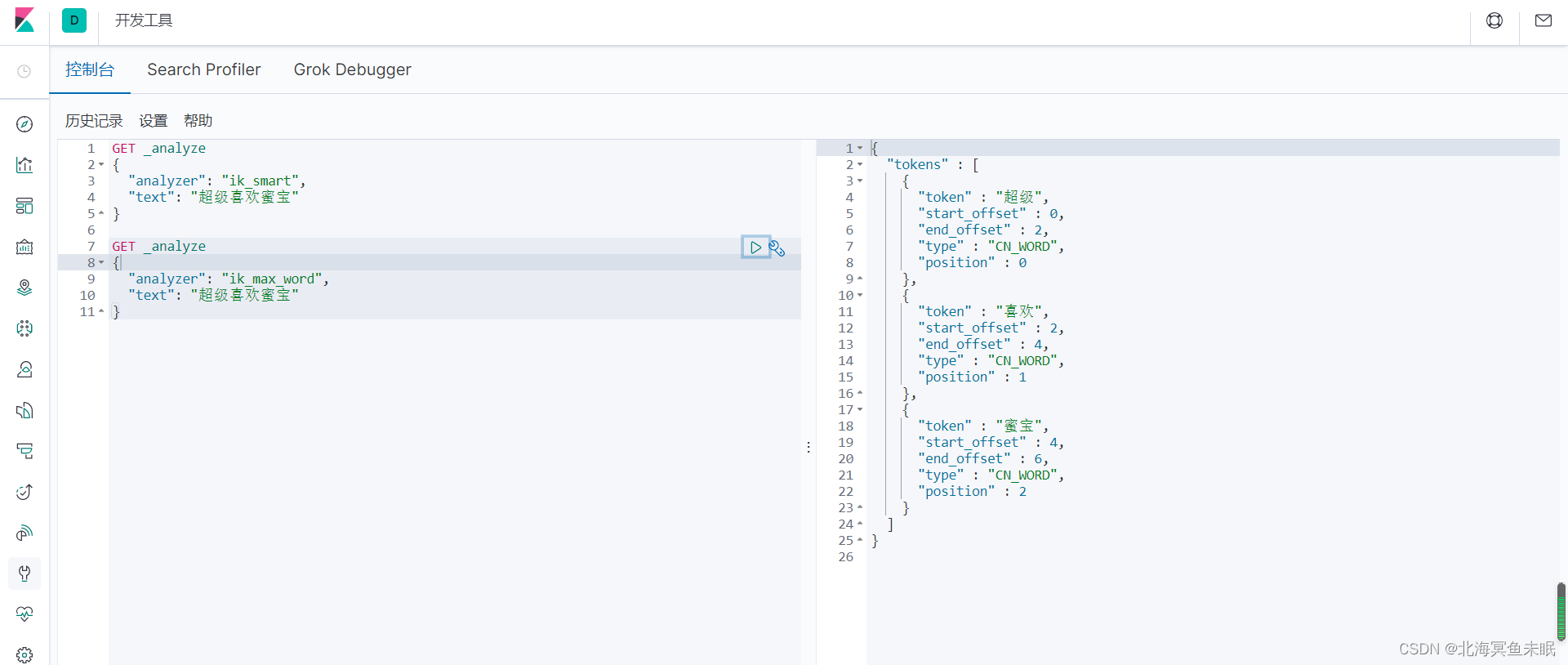
下面我们使用一下IK分词算法。首先介绍一下,我们的IK分词算法有两种ik_smart(最少切分)和ik_max_word(最细粒度划分)。
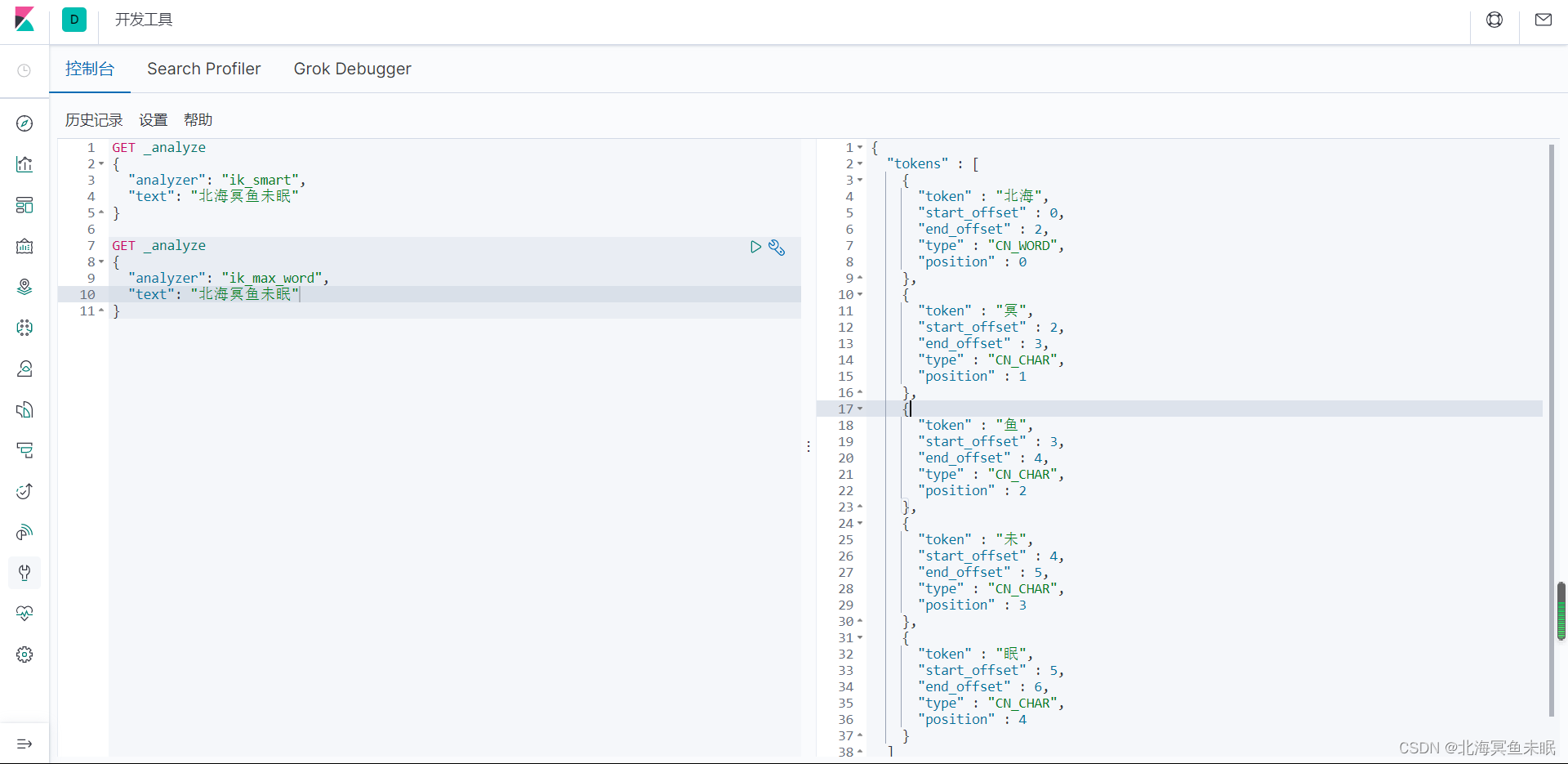
实际上这个两个分词器的结果并不是完全相同的,只是我的这句话恰好完全分词相同了。
再测试一个
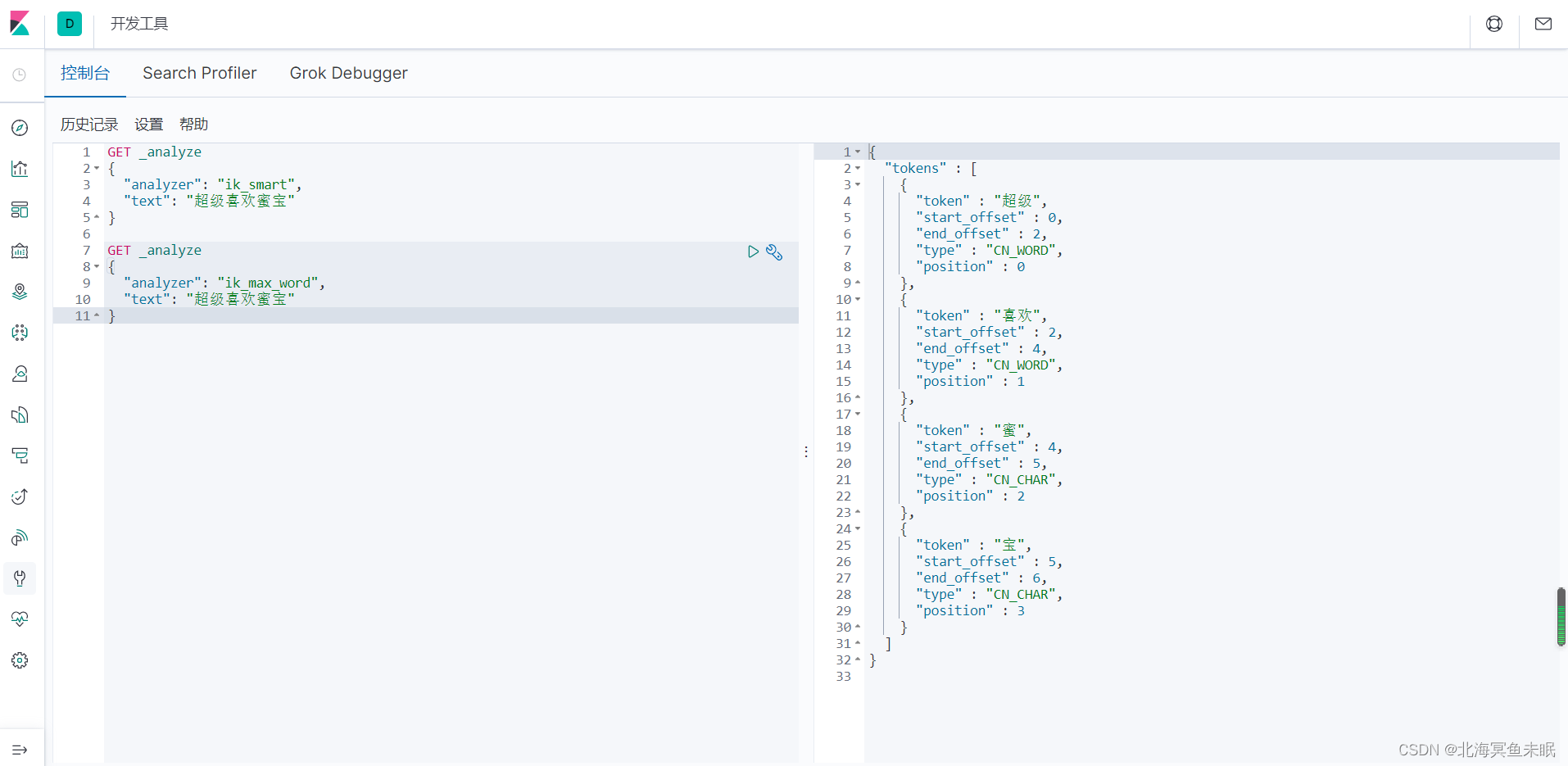
这里蜜宝明明是一个词,却被分开了。我们可以修改分词器的配置。
进入分词器的配置目录
打开之后可以发现
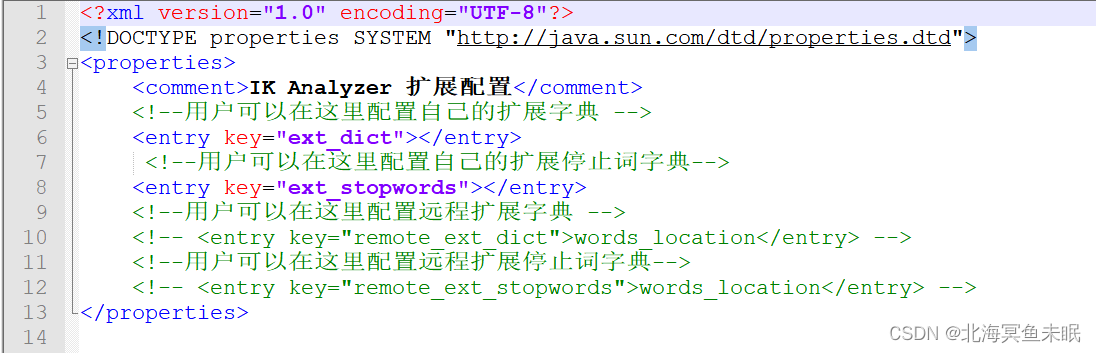
我们可以自己配置写一个字典的文件然后把它配置到配置文件中。(注意这里的编码一定是utf-8,不然后面效果出不来。)

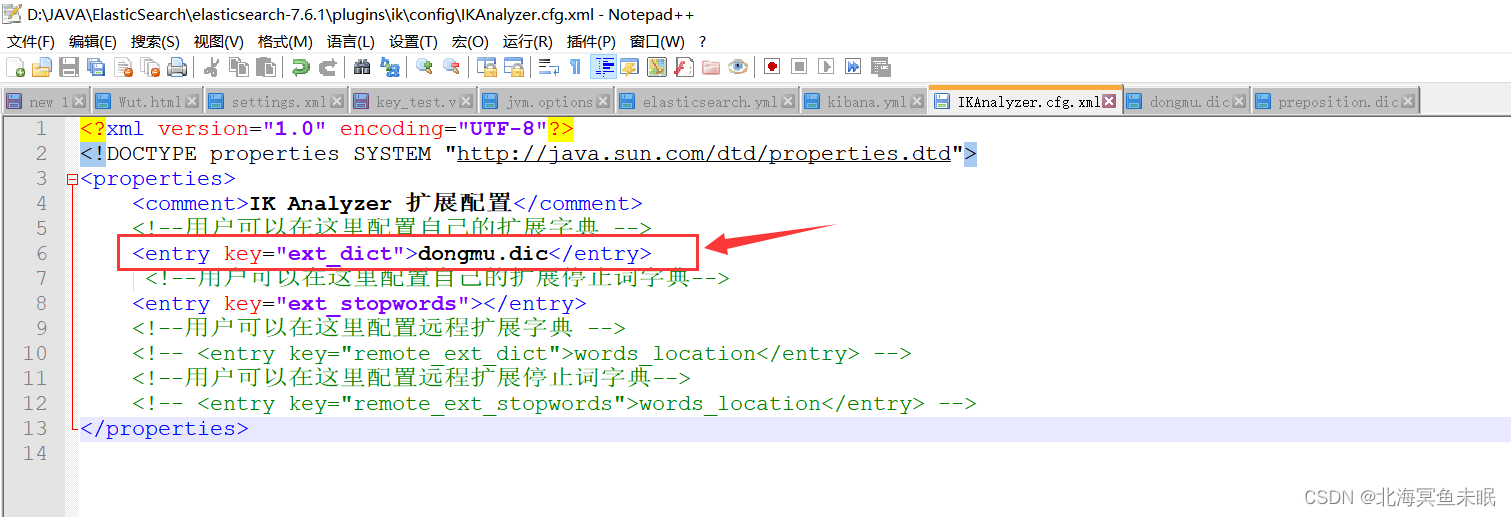
保存之后重启es
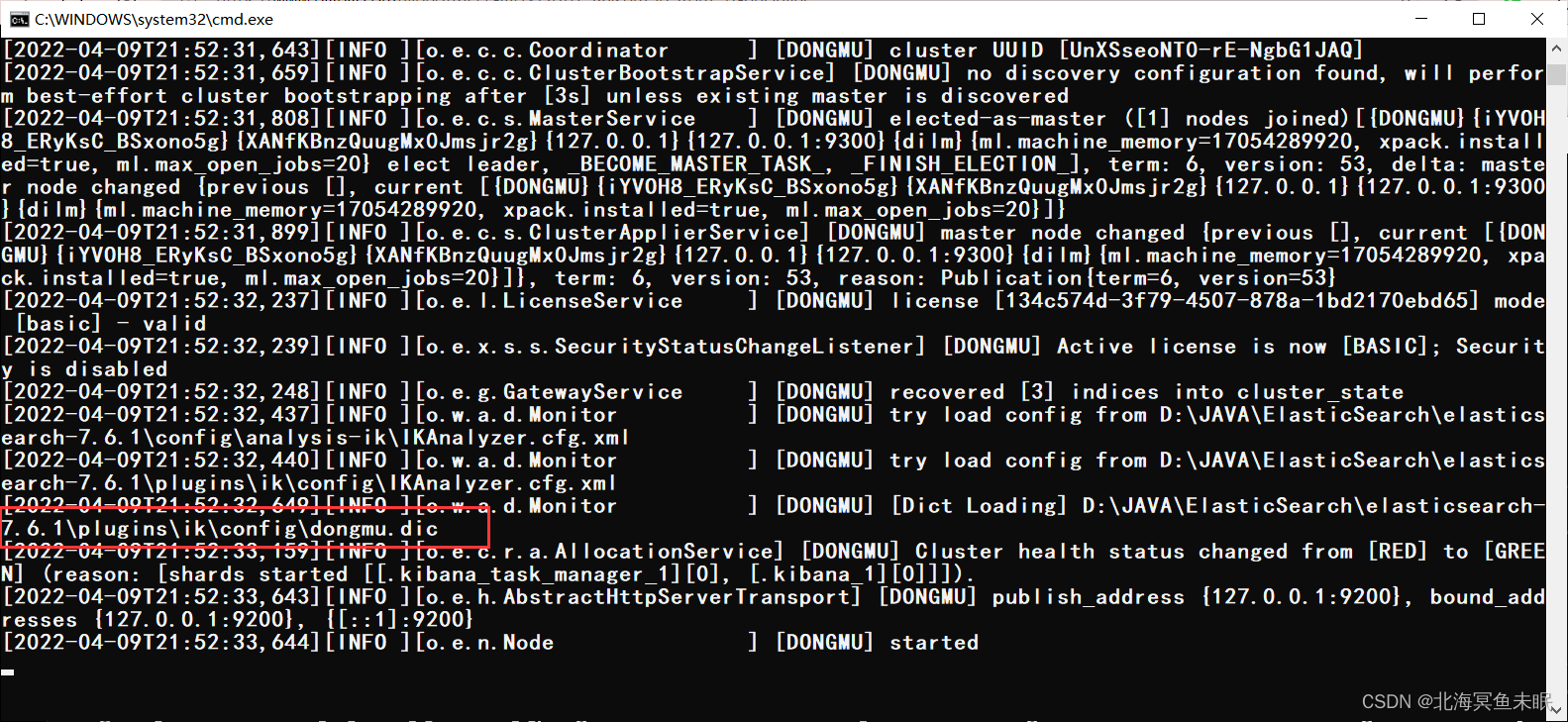
可以看到这里加载了我刚才写的dongmu.dic。
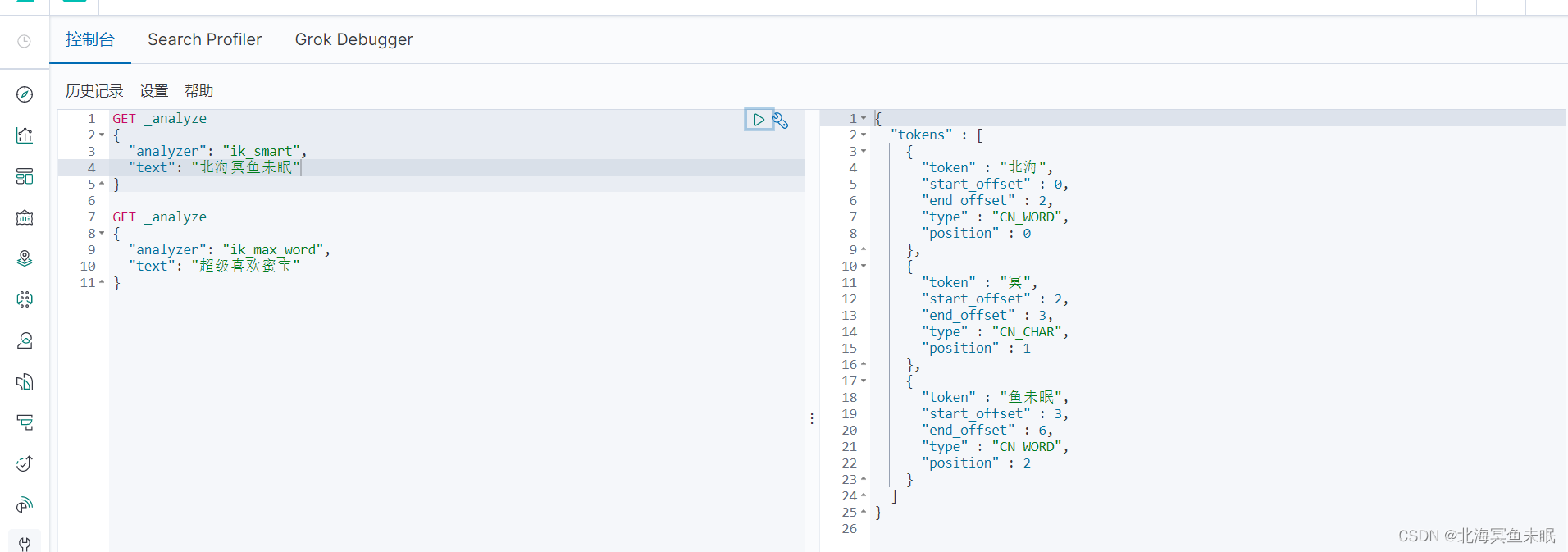
可以看到,这里蜜宝、鱼未眠两个已经变成了一个词。
















 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











