







 文章介绍了Weights&Biases(W&B)这个AI开发者平台,它提供了实验跟踪、模型训练与微调工具,以及超参数调整、数据管理和可视化等功能,帮助机器学习实践者高效组织和优化工作流程。
文章介绍了Weights&Biases(W&B)这个AI开发者平台,它提供了实验跟踪、模型训练与微调工具,以及超参数调整、数据管理和可视化等功能,帮助机器学习实践者高效组织和优化工作流程。
一、W&B 是什么?
Weights & Biases(W&B)是AI开发者平台,提供用于训练模型、微调模型以及利用基础模型的工具。
在5分钟内设置 W&B,然后可以放心地在您的机器学习流程中快速迭代,确保您的模型和数据被跟踪和版本化在一个可靠的记录系统中。
W&B Models
是一组轻量级、可互操作的工具,供机器学习实践者用于**训练和微调模型**。
- Experiments:机器学习实验跟踪
- Model Registry:集中管理生产模型
- Launch:扩展和自动化工作负载
- Sweeps:超参数调整和模型优化
W&B Prompts
用于调试和评估LLMs。
W&B Platform
是一组强大的核心构建模块,用于跟踪和可视化数据和模型,并传达结果。
- Artifacts:版本化资产并跟踪谱系
- Tables:可视化和查询表格数据
- Reports:记录和协作您的发现
- Weave:查询和创建数据可视化。
二、快速入门
在几分钟内安装 W&B 并开始跟踪您的机器学习实验。
2-1:创建账户并安装 W&B
进入官网,创建账户
⚠️建议第一次注册的用户直接与github账号绑定。
进入创建的虚拟环境
打开终端,任选一个你之前已经创建过的虚拟环境,如果不知道怎么创建虚拟环境的,去看我这篇文章。
conda pyt
安装用于与 Weights and Biases API 交互的 CLI 和 Python 库:
pip install wandb
安装成功界面如下。
2-2:登陆wandb
输入下列代码
wandb login

密钥在官网首页即可获取
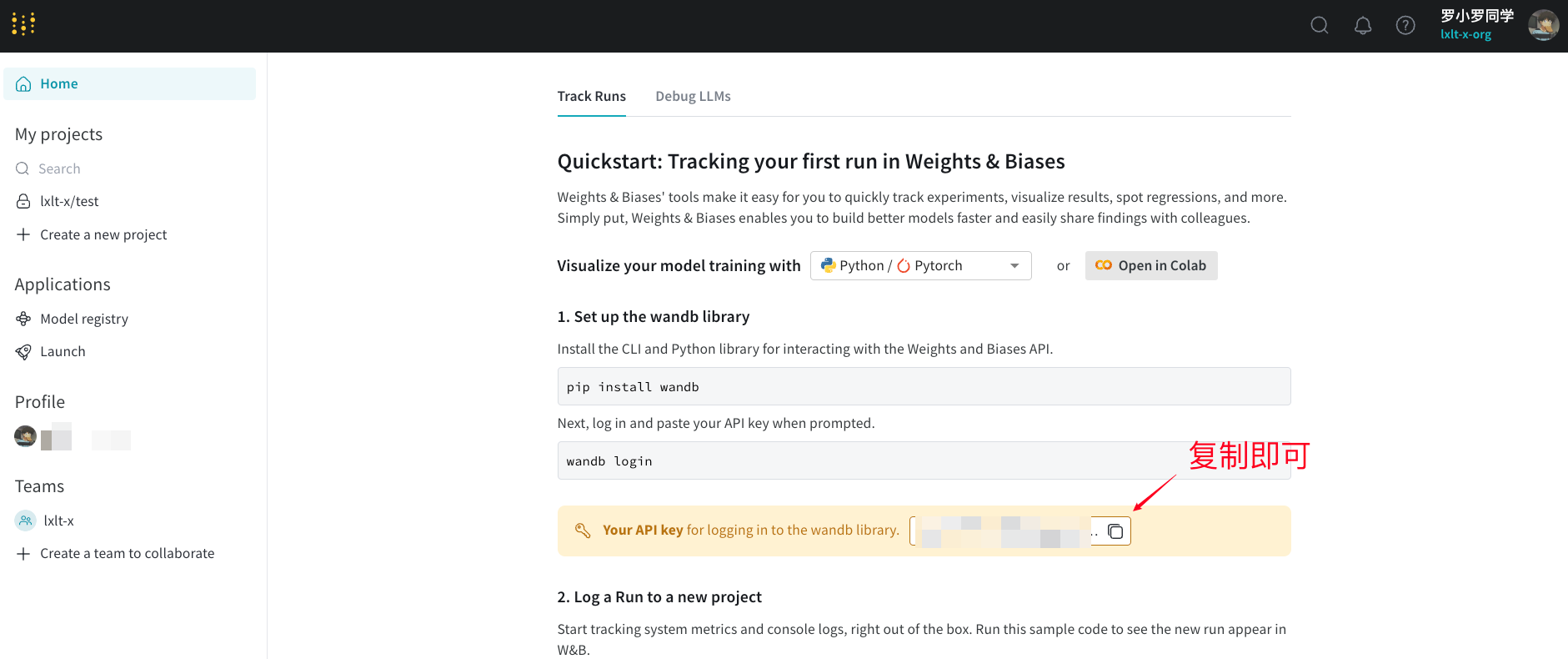
⚠️:你粘贴密钥的时候并不会有显示,粘贴完毕直接回车即可。
2-3:开始一个运行并跟踪超参数
打开jupyter
终端输入
jupyter notebook
检查一下刚刚w&b是否导入成功
pip list
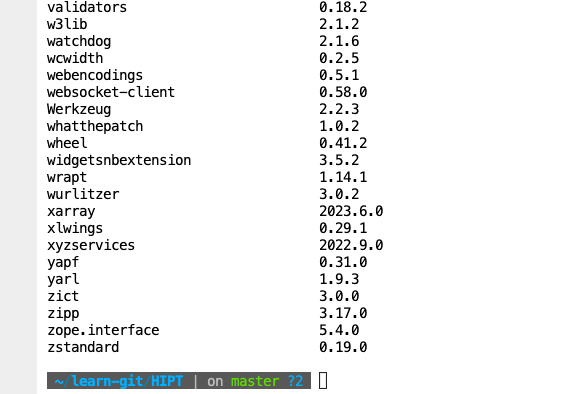
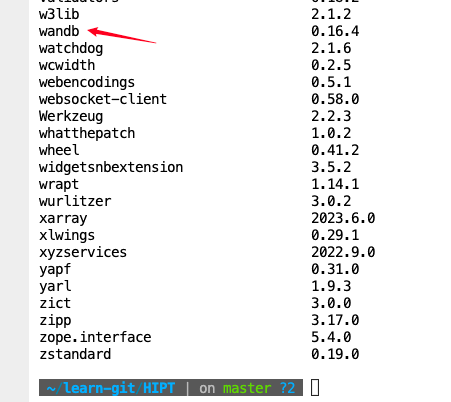
此时如果你和我一样,没有导入成功,那么需要重新导入一次。
pip install wandb
现在导入成功了。
初始化代码如下
⚠️:现在不要输入,只是告诉你这一个模块负责初始化——指定项目名称、学习率以及迭代次数。
run = wandb.init(
# Set the project where this run will be logged
project="my-awesome-project",
# Track hyperparameters and run metadata
config={
"learning_rate": 0.01,
"epochs": 10,
},
)
现在打开一个代码运行界面
# train.py
import wandb
import random # for demo script
wandb.login()
epochs = 10
lr = 0.01
run = wandb.init(
# Set the project where this run will be logged
project="my-awesome-project",
# Track hyperparameters and run metadata
config={
"learning_rate": lr,
"epochs": epochs,
},
)
offset = random.random() / 5
print(f"lr: {lr}")
# simulating a training run
for epoch in range(2, epochs):
acc = 1 - 2**-epoch - random.random() / epoch - offset
loss = 2**-epoch + random.random() / epoch + offset
print(f"epoch={epoch}, accuracy={acc}, loss={loss}")
wandb.log({"accuracy": acc, "loss": loss})
# run.log_code()
完成了!访问 https://wandb.ai/home 上的 W&B 应用程序,查看我们使用 W&B 记录的指标(准确率和损失)在每个训练步骤中的改善情况。
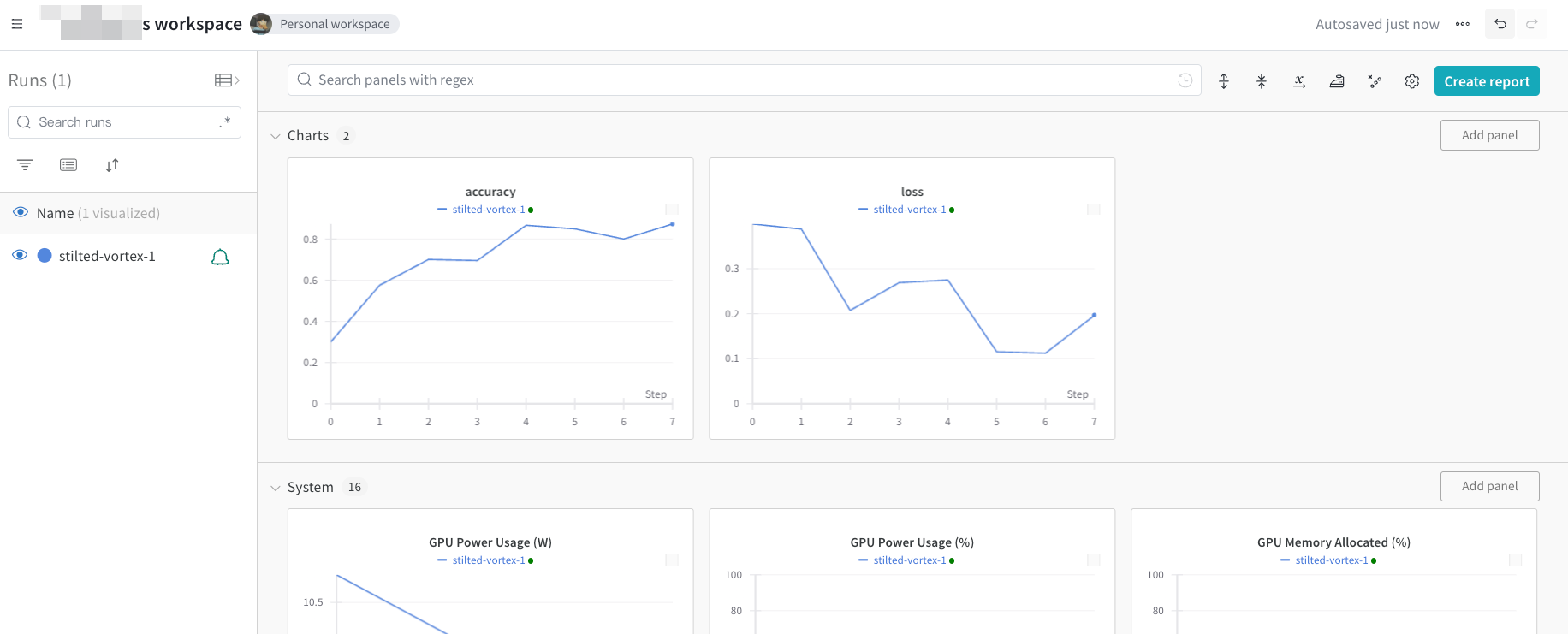
上面的图片(点击扩大)显示了我们从上面运行脚本时跟踪的损失和准确率。在“Runs”列中显示了每个创建的运行对象。每个运行名称都是随机生成的。
三、W&B Models
W&B Models 是机器学习实践者的记录系统,旨在帮助他们组织模型、提升生产力和协作能力,并实现规模化的生产级机器学习。
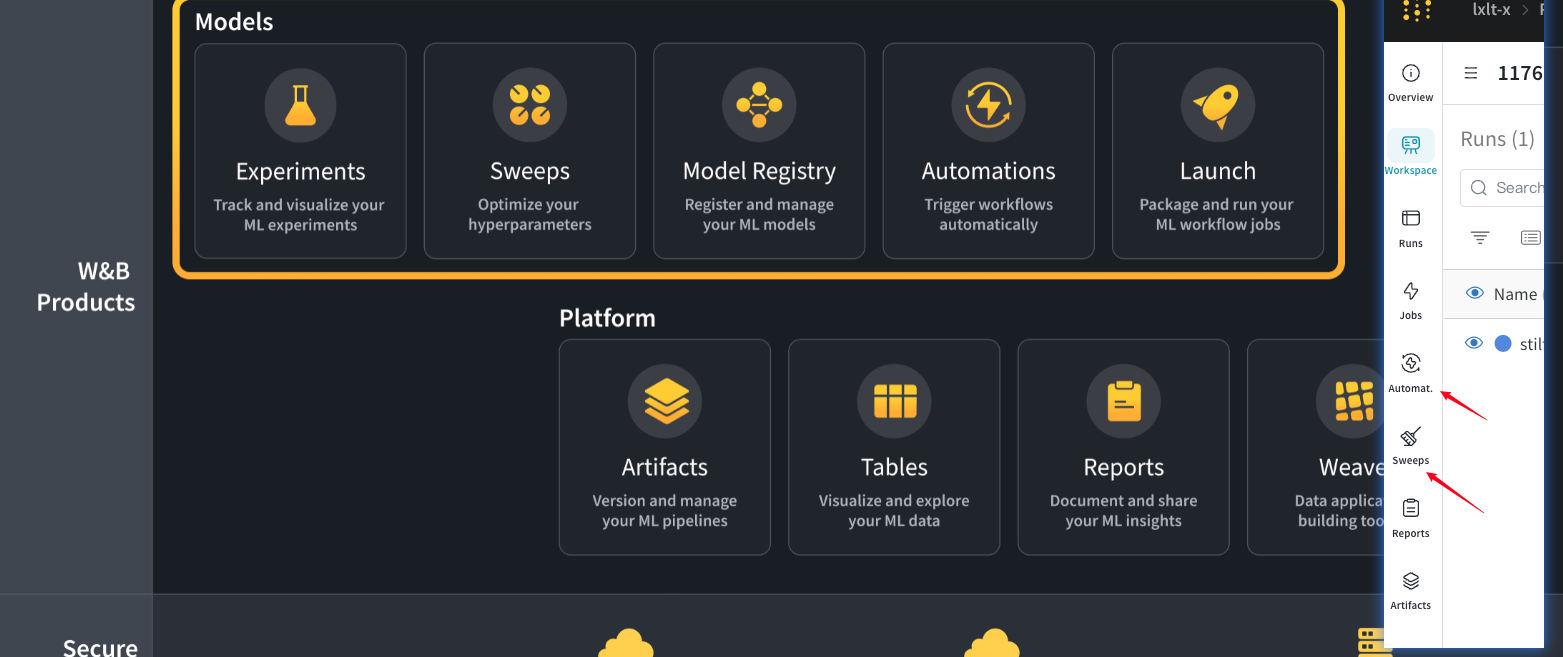
借助 W&B Models,您可以:
- 跟踪和可视化所有机器学习实验。
- 利用超参数搜索在规模上**优化和微调**模型。
- 维护所有模型的集中式中心,实现与开发运维和部署的无缝交接点。
- 配置自定义自动化,触发关键的模型CI/CD工作流程。
- 打包并运行机器学习工作流,以便无缝访问强大的计算资源。
机器学习实践者依赖 W&B Models 作为他们的机器学习记录系统,用于跟踪和可视化实验,管理模型版本和谱系,并优化超参数。
3-1:跟踪实验
使用几行代码跟踪机器学习实验。然后,您可以在交互式仪表板中查看结果,或使用API 将数据导出到 Python 以进行编程访问。
如果您使用流行的框架如 PyTorch、Keras 或 Scikit,可以利用 W&B 集成。请查看集成指南,获取完整的集成列表以及如何将 W&B 添加到代码中。
如何工作
使用几行代码跟踪机器学习实验:
- 创建一个 W&B 运行。
- 将超参数字典(例如学习率或模型类型)存储到您的配置中(
wandb.config)。 - 在训练循环中随时间记录指标(
wandb.log()),例如准确率和损失。 - 保存运行的输出,如模型权重或预测表。
以下伪代码演示了常见的 W&B 实验跟踪工作流程:
# 1. Start a W&B Run
wandb.init(entity="", project="my-project-name")
# 2. Save mode inputs and hyperparameters
wandb.config.learning_rate = 0.01
# Import model and data
model, dataloader = get_model(), get_data()
# Model training code goes here
# 3. Log metrics over time to visualize performance
wandb.log({"loss": loss})
# 4. Log an artifact to W&B
wandb.log_artifact(model)
3-2:创建一个wandb实验
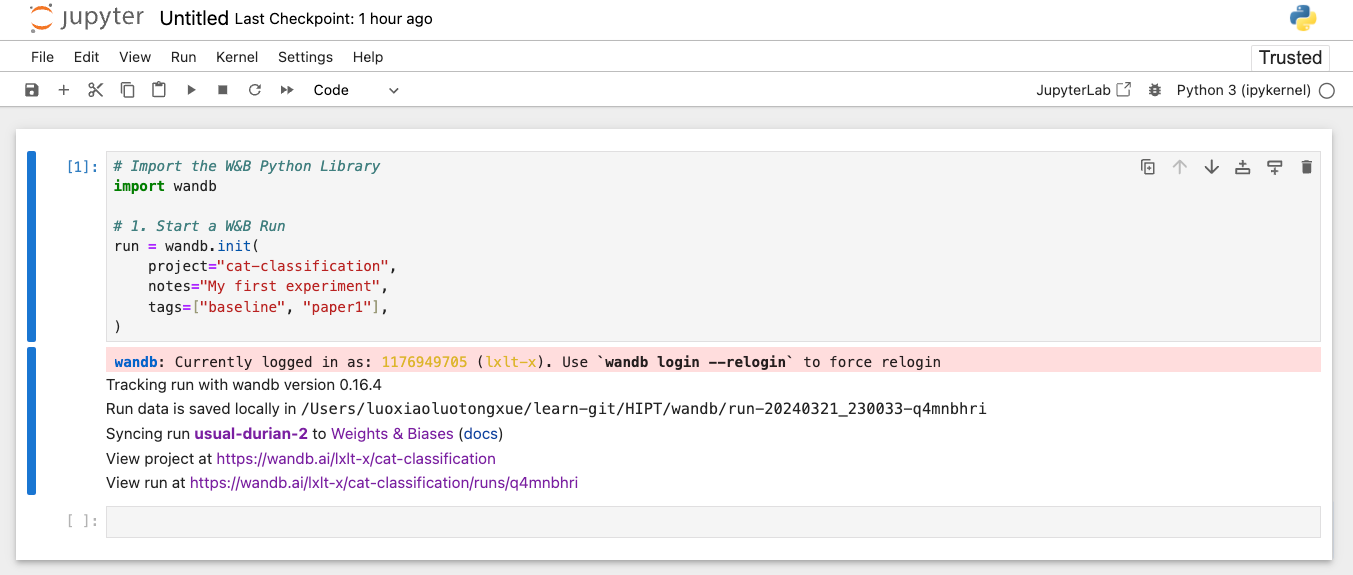
在脚本开头调用 wandb.init() API 来生成一个后台进程,以将数据同步和记录为 W&B 运行。
以下代码片段演示了如何创建一个名为“cat-classification”的新 W&B 项目。添加了一个注释 “My first experiment”以帮助识别此运行。标签baseline和paper1被包含在内,以提醒我们此运行是一个基准实验,旨在用于未来的论文发表。
初始化
# Import the W&B Python Library
import wandb
# 1. Start a W&B Run
run = wandb.init(
project="cat-classification",
notes="My first experiment",
tags=["baseline", "paper1"],
)
使用 wandb.init() 初始化 W&B 时会返回一个 Run 对象。此外,W&B 会创建一个本地目录,其中保存并异步流式传输到 W&B 服务器的所有日志和文件。
记录超参数
保存一个超参数字典,比如学习率或模型类型。在 config 中捕获的模型设置以后对于组织和查询结果非常有用。
# 2. Capture a dictionary of hyperparameters
wandb.config = {"epochs": 100, "learning_rate": 0.001, "batch_size": 128}
在你的训练循环中记录指标
在每个 for 循环(epoch)期间记录指标,准确率和损失值通过 wandb.log() 计算并记录到 W&B。默认情况下,当你调用 wandb.log 时,它会向 history 对象追加一个新步骤,并更新 summary 对象。
以下代码示例展示了如何使用 wandb.log 记录指标。
⚠️:关于如何设置模型和获取数据的详细信息被省略了,所以下面这段代码你运行不了!!只是告诉你这个流程,后续会有相应的教程介绍如何使用。
# Set up model and data
model, dataloader = get_model(), get_data()
for epoch in range(wandb.config.epochs):
for batch in dataloader:
loss, accuracy = model.training_step()
# 3. Log metrics inside your training loop to visualize
# model performance
wandb.log({"accuracy": accuracy, "loss": loss})
记录一个 Artifact 到 W&B
可选择记录一个 W&B Artifact。Artifact 可以方便地对数据集和模型进行版本管理。
wandb.log_artifact(model)
完整的代码记录如下
# Import the W&B Python Library
import wandb
# 1. Start a W&B Run
run = wandb.init(project="cat-classification", notes="", tags=["baseline", "paper1"])
# 2. Capture a dictionary of hyperparameters
wandb.config = {"epochs": 100, "learning_rate": 0.001, "batch_size": 128}
# Set up model and data
model, dataloader = get_model(), get_data()
for epoch in range(wandb.config.epochs):
for batch in dataloader:
loss, accuracy = model.training_step()
# 3. Log metrics inside your training loop to visualize
# model performance
wandb.log({"accuracy": accuracy, "loss": loss})
# 4. Log an artifact to W&B
wandb.log_artifact(model)
# Optional: save model at the end
model.to_onnx()
wandb.save("model.onnx")
最佳实践
以下是创建实验时可以考虑的一些建议指南:
-
配置信息(Config):跟踪超参数、架构、数据集以及其他任何您想要用来复现模型的信息。这些信息会显示在列中,您可以使用配置列在应用程序中动态地对运行进行分组、排序和筛选。
-
项目(Project):项目是一组可以进行比较的实验。每个项目都有一个专用的仪表板页面,您可以轻松地打开和关闭不同组运行以比较不同的模型版本。
-
备注(Notes):给自己的一个快速提交消息。备注可以从您的脚本中设置。您可以在稍后在 W&B 应用程序的项目仪表板概述部分编辑备注。
-
标签(Tags):标识基准运行和喜欢的运行。您可以使用标签筛选运行。您可以在稍后在 W&B 应用程序的项目仪表板概述部分编辑标签。
以下代码片段演示了如何使用上述最佳实践定义一个 W&B 实验:
import wandb
config = dict(
learning_rate=0.01, momentum=0.2, architecture="CNN", dataset_id="cats-0192"
)
wandb.init(
project="detect-cats",
notes="tweak baseline",
tags=["baseline", "paper1"],
config=config,
)
3-3:配置实验
在这里尝试在 Colab Notebook 中配置实验
使用 wandb.config 对象保存您的训练配置,例如:
- 超参数
- 输入设置,如数据集名称或模型类型
- 实验中的任何其他独立变量
wandb.config 属性使得分析您的实验并在将来复现您的工作变得更加容易。您可以在 W&B 应用程序中按配置值分组,比较不同 W&B 运行的设置,并查看不同训练配置如何影响输出。运行的 config 属性是类似字典的对象,可以由许多类似字典的对象构建。
设置实验配置
通常在训练脚本的开头定义配置。然而,机器学习工作流程可能会有所不同,因此您并非必须在训练脚本的开头定义配置。
在初始化时设置配置
在调用 wandb.init() API 时,在脚本开头传递一个字典,以生成一个后台进程来同步和记录数据作为一个 W&B Run。
以下代码片段演示了如何定义一个带有配置值的 Python 字典,以及在初始化 W&B Run 时如何将该字典作为参数传递。
import wandb
# Define a config dictionary object
config = {
"hidden_layer_sizes": [32, 64],
"kernel_sizes": [3],
"activation": "ReLU",
"pool_sizes": [2],
"dropout": 0.5,
"num_classes": 10,
}
# Pass the config dictionary when you initialize W&B
run = wandb.init(project="config_example", config=config)
类似于在 Python 中访问其他字典,您可以访问字典中的值:
# Access values with the key as the index value
hidden_layer_sizes = wandb.config["hidden_layer_sizes"]
kernel_sizes = wandb.config["kernel_sizes"]
activation = wandb.config["activation"]
# Python dictionary get() method
hidden_layer_sizes = wandb.config.get("hidden_layer_sizes")
kernel_sizes = wandb.config.get("kernel_sizes")
activation = wandb.config.get("activation")
使用 argparse 设置配置
您可以使用 argparse 对象设置您的配置。argparse 是 Python 3.2 及以上版本的标准库模块,它使得编写脚本以利用命令行参数的所有灵活性和功能变得容易。
这对于跟踪从命令行启动的脚本的结果非常有用。
以下 Python 脚本演示了如何定义一个解析器对象来定义和设置您的实验配置。为了演示目的,提供了 train_one_epoch 和 evaluate_one_epoch 函数来模拟训练循环:
将下面这段代码保存为test.py文件
⚠️:要保存在当前路径下,不然会报错
# test.py
import wandb
import argparse
import numpy as np
import random
# Training and evaluation demo code
def train_one_epoch(epoch, lr, bs):
acc = 0.25 + ((epoch / 30) + (random.random() / 10))
loss = 0.2 + (1 - ((epoch - 1) / 10 + random.random() / 5))
return acc, loss
def evaluate_one_epoch(epoch):
acc = 0.1 + ((epoch / 20) + (random.random() / 10))
loss = 0.25 + (1 - ((epoch - 1) / 10 + random.random() / 6))
return acc, loss
def main(args):
# Start a W&B Run
run = wandb.init(project="config_example", config=args)
# Access values from config dictionary and store them
# into variables for readability
lr = wandb.config["learning_rate"]
bs = wandb.config["batch_size"]
epochs = wandb.config["epochs"]
# Simulate training and logging values to W&B
for epoch in np.arange(1, epochs):
train_acc, train_loss = train_one_epoch(epoch, lr, bs)
val_acc, val_loss = evaluate_one_epoch(epoch)
wandb.log(
{
"epoch": epoch,
"train_acc": train_acc,
"train_loss": train_loss,
"val_acc": val_acc,
"val_loss": val_loss,
}
)
if __name__ == "__main__":
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("-b", "--batch_size", type=int, default=32, help="Batch size")
parser.add_argument(
"-e", "--epochs", type=int, default=50, help="Number of training epochs"
)
parser.add_argument(
"-lr", "--learning_rate", type=int, default=0.001, help="Learning rate"
)
args = parser.parse_args()
main(args)
终端运行代码
python test.py
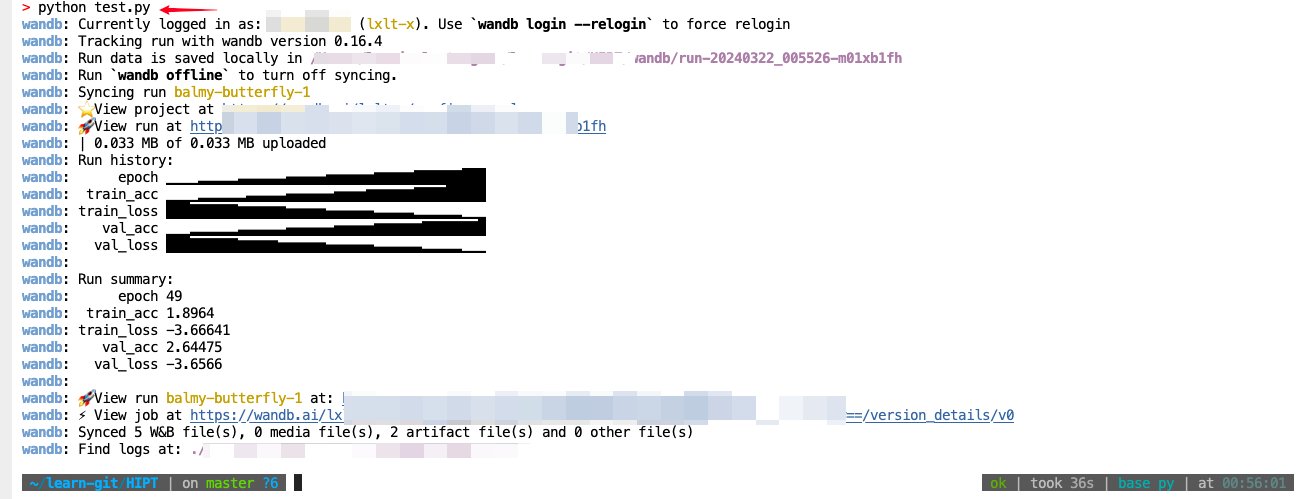
监测结果如下
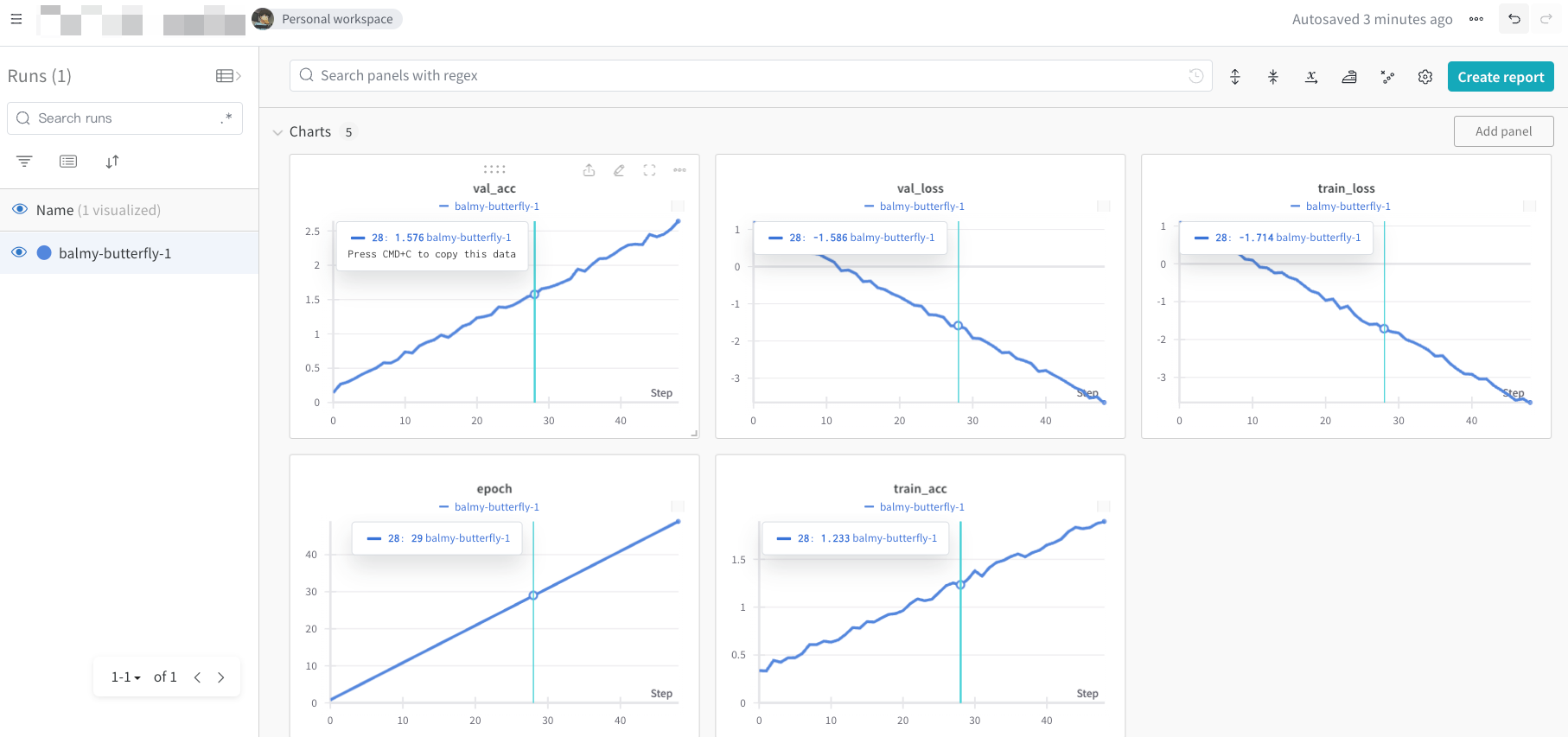
在整个脚本中设置配置
您可以在整个脚本中向您的配置对象添加更多参数。以下代码片段展示了如何向您的配置对象添加新的键值对:
import wandb
# Define a config dictionary object
config = {
"hidden_layer_sizes": [32, 64],
"kernel_sizes": [3],
"activation": "ReLU",
"pool_sizes": [2],
"dropout": 0.5,
"num_classes": 10,
}
# Pass the config dictionary when you initialize W&B
run = wandb.init(project="config_example", config=config)
# Update config after you initialize W&B
wandb.config["dropout"] = 0.2
wandb.config.epochs = 4
wandb.config["batch_size"] = 32
你可以一次更改多个变量。
wandb.init(config={"epochs": 4, "batch_size": 32})
# later
wandb.config.update({"lr": 0.1, "channels": 16})
在运行完成后设置配置
使用W&B公共API在运行完成后更新您的配置(或者除了完整的运行之外的任何其他内容)。如果您在运行期间忘记记录某个值,这将特别有用。
提供您的实体(entity)、project name和Run ID,以便在运行完成后更新您的配置。可以直接从Run对象本身wandb.run或从W&B应用程序UI中找到这些值:
api = wandb.Api()
# Access attributes directly from the run object
# or from the W&B App
username = wandb.run.entity
project = wandb.run.project
run_id = wandb.run.id
run = api.run(f"{username}/{project}/{run_id}")
run.config["bar"] = 32
run.update()
基于文件的配置
如果您创建一个名为config-defaults.yaml的文件,其中的键值对会自动传递给wandb.config。
以下代码片段展示了一个示例config-defaults.yaml YAML文件:
# config-defaults.yaml
# sample config defaults file
epochs:
desc: Number of epochs to train over
value: 100
batch_size:
desc: Size of each mini-batch
value: 32
您可以通过wandb.init的config参数覆盖config-defaults.yaml中自动传递的值。为此,请将值传递给wandb.init的config参数。
您还可以使用命令行参数--configs 加载不同的配置文件。
假设您有一个包含运行的一些元数据的YAML文件,然后在您的Python脚本中有一个超参数字典。您可以将这两者保存在嵌套的config对象中:
hyperparameter_defaults = dict(
dropout=0.5,
batch_size=100,
learning_rate=0.001,
)
config_dictionary = dict(
yaml=my_yaml_file,
params=hyperparameter_defaults,
)
wandb.init(config=config_dictionary)
下期更新
后续我会再更新一部分实际案例,感兴趣的同学可以关注一波!!
















 2201
2201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









