







小罗碎碎念
推文速览
第一篇文章提出了一种结合半监督学习和知识蒸馏的视觉变换器网络,用于通过分析组织切片图像来预测结直肠癌肝转移患者的生存情况。
第二篇文章介绍了一种名为DeepGEM的深度学习模型,能够从组织学图像中准确预测肺癌患者的基因突变,有助于指导临床治疗。
第三篇文章通过结合自然语言处理和多模态数据集成,提高了癌症预后预测的准确性。
概念补充
【1】半监督视觉变换器(ViT)知识蒸馏网络
【2】DeepGEM模型在内部保留测试集上预测基因突变的性能比较方式
【3】ROS1和KRAS基因突变
【4】泛癌临床数据集MSK-CHORD的构建流程
【5】什么是肿瘤学真实世界数据集?
【6】如何理解肿瘤的多线治疗?
一、结直肠癌肝转移患者生存预测的半监督ViT知识蒸馏网络

一作&通讯
| 姓名 | 角色 | 单位名称(中文) |
|---|---|---|
| Mohamed El Amine Elforaici | 第一作者 | Polytechnique Montréal(蒙特利尔综合理工学院) |
| M.E.A. Elforaici | 通讯作者 | MedICAL Laboratory(医疗实验室) |
文献概述
这篇文章是关于一种半监督的视觉变换器(ViT)知识蒸馏网络,该网络结合了风格迁移归一化,用于预测结直肠癌肝转移(CLM)患者的生存情况。
研究团队提出了一种端到端的方法,使用苏木精-伊红(H&E)和苏木精-磷钨-红(HPS)染色的组织切片来自动预测预后。
这个网络首先使用生成对抗网络(GAN)对切片进行归一化,以减少染色变化并提高图像质量。然后,提出了一个半监督模型来执行组织分类,产生分割和特征图。该模型特别使用基于注意力的方法,对不同区域的重要性进行加权,以产生最终的分类结果。最后,利用提取的特征来训练预后模型。
研究团队在258名CLM患者的内部临床数据集上评估了他们的方法,并在两个公共数据集上进行了测试。他们的方法在预测总体生存率(OS)和复发时间(TTR)方面比其他模型表现更优,c指数分别为0.804和0.735。在预测肿瘤回归分级(TRG)方面,准确率在86.9%到90.3%之间,超过了比较方法。该方法可以为病理学家和肿瘤学家提供自动化的预后预测,促进精准医疗在管理CLM患者方面的进展。
半监督视觉变换器(ViT)知识蒸馏网络
这张图展示了一个半监督视觉变换器(ViT)知识蒸馏网络的概览。
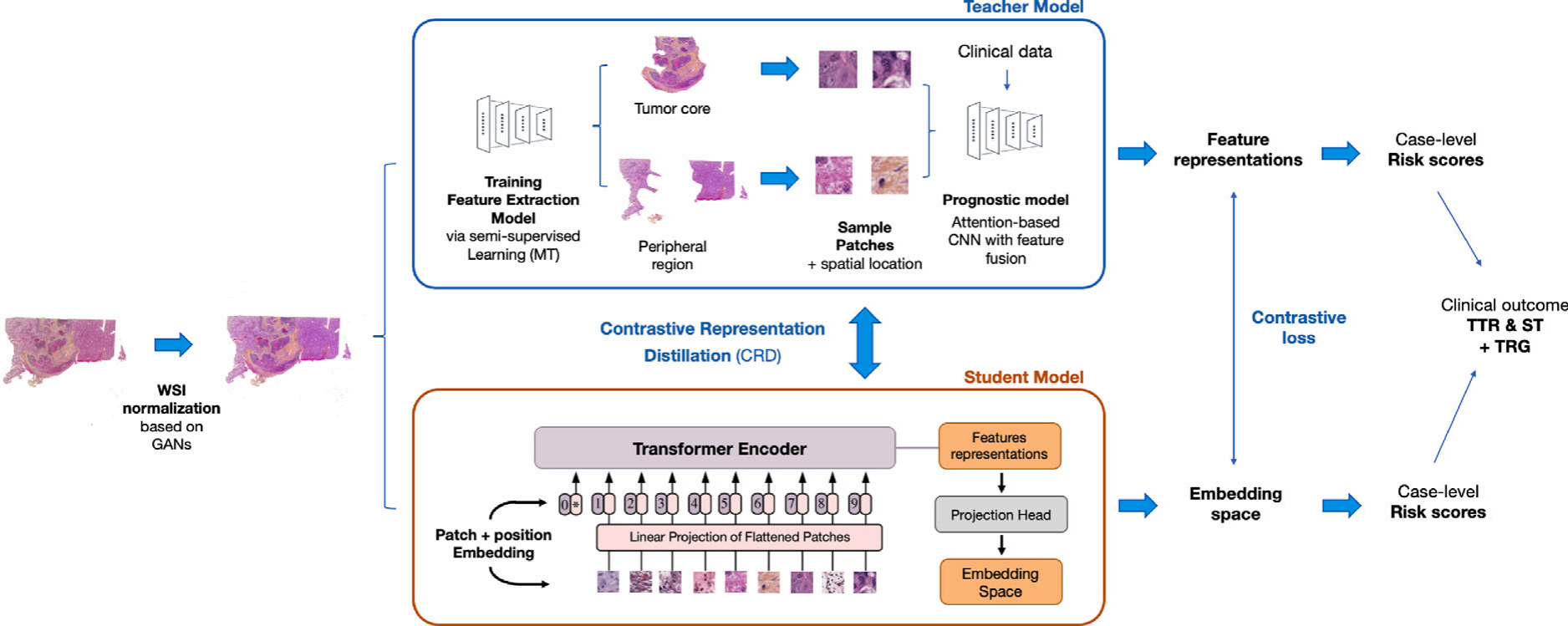
以下是该网络的详细描述:
-
WSI归一化:首先,使用基于生成对抗网络(GAN)的模型对全切片图像(WSI)进行归一化处理,以减少不同染色技术带来的影响。
-
特征提取模型:接着,通过半监督学习中的Mean Teacher(MT)方法训练特征提取模型。这个模型能够从选定的兴趣区域(ROI)——肿瘤核心和周围区域——中提取与预后相关的特征。
-
组织分类和分割:特征提取模型还能够执行组织分类任务,并生成分类图,这些图显示了不同组织类型的分布。
-
预后模型训练:利用从肿瘤核心和周围区域提取的特征,结合临床数据,通过注意力机制训练预后模型。这个模型能够预测患者的生存时间(OS)和复发时间(TTR)。
-
对比表示蒸馏(CRD):同时,使用对比表示蒸馏(CRD)方法,鼓励学生模型(ViT)学习与教师模型相似的表示。这种方法不依赖于直接的特征匹配目标,而是通过对比学习目标来实现。
-
学生模型:学生模型是一个视觉变换器(ViT),它通过Transformer编码器处理图像块,并将它们映射到嵌入空间中。这个过程包括将图像块展平并通过线性投影,然后加上位置嵌入,以保留空间信息。
-
教师模型:教师模型接收临床数据,并结合特征融合的注意力基础卷积神经网络(CNN)来生成特征表示,这些特征表示用于计算病例级别的风险评分。
-
对比损失:学生模型和教师模型之间通过对比损失进行优化,这有助于学生模型学习到与教师模型相似的特征表示。
-
临床结果预测:最终,学生模型能够根据嵌入空间中的特征表示,预测临床结果,包括TTR、ST(可能是生存时间)和TRG(肿瘤回归分级)。
这个网络的设计旨在通过半监督学习和知识蒸馏提高生存预测的准确性,同时减少对大量标注数据的依赖。
二、DeepGEM模型精准预测肺癌基因突变

一作&通讯
| 作者角色 | 作者姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Yu Zhao* | 广州医科大学第一附属医院胸外科、呼吸疾病国家重点实验室、呼吸疾病国家临床研究中心 |
| 第一作者 | Shan Xiong* | 广州医科大学第一附属医院胸外科、呼吸疾病国家重点实验室、呼吸疾病国家临床研究中心 |
| 第一作者 | Qin Ren* | 腾讯AI实验室 |
| 第一作者 | Jun Wang* | 腾讯AI实验室 |
| 第一作者 | Min Li* | 腾讯AI实验室 |
| 第一作者 | Lin Yang* | 腾讯AI实验室 |
| 通讯作者 | Jianxing He† | 广州医科大学第一附属医院胸外科、呼吸疾病国家重点实验室、呼吸疾病国家临床研究中心 |
| 通讯作者 | Jianhua Yao† | 广州医科大学第一附属医院胸外科、呼吸疾病国家重点实验室、呼吸疾病国家临床研究中心 |
| 通讯作者 | Wenhua Liang† | 广州医科大学第一附属医院胸外科、呼吸疾病国家重点实验室、呼吸疾病国家临床研究中心 |
文献概述
研究的核心目标是开发一种基于深度学习的人工智能方法,用于从常规获取的组织学幻灯片中预测肺癌患者的基因突变,这种方法被称为DeepGEM(Deep learning-enabled GEne Mutation predictor)。
背景:
- 肺癌患者中驱动基因突变的准确检测对于治疗规划和预后预测至关重要。
- 传统的基因组测试需要高质量的组织样本,耗时且资源密集,不适用于大多数患者,尤其是在资源有限的地区。
方法:
- 这项多中心回顾性研究收集了中国16家医院的肺癌患者的数据,这些患者接受了活检和多基因下一代测序。
- 研究包括了来自中国广州医科大学第一附属医院的患者数据(内部数据集),以及来自其他15个中心的患者数据(外部数据集)和公开的癌症基因组图谱(TCGA)数据集。
- DeepGEM模型是一个实例级和包级共同监督的多实例学习方法,具有标签消歧设计。
发现:
- 研究共纳入了3697名患者的数据,排除了60名图像质量低的患者,最终包括了3637名连续患者的3767张图像。
- DeepGEM模型在内部数据集上显示出强大的性能,对于切除活检样本,基因突变预测的AUC值从0.90到0.97,准确度值从0.91到0.97;对于抽吸活检样本,AUC值从0.85到0.95,准确度值从0.79到0.99。
- 在多中心外部数据集上,DeepGEM模型也显示出强大的性能。
- 该模型还能够推广到淋巴结转移的活检样本,并显示出预测靶向治疗效果的潜力。
文章强调了DeepGEM模型作为一种辅助工具在肺癌治疗中的潜力,并指出了其在资源有限地区的重要性。研究结果支持了使用深度学习技术从组织学图像中预测基因突变的可行性,并为未来的临床试验和应用奠定了基础。
代码链接和数据集
- 代码链接:
- 链接地址:https://github.com/TencentAILabHealthcare/DeepGEM/blob/main/README.md
- DeepGEM模型:这是一个深度学习模型,用于从常规获取的组织学幻灯片中预测肺癌患者的基因突变情况。模型的开发旨在提供一个准确、及时、经济的基因突变预测工具,以指导临床药物推荐。
- 数据集:
- 这些数据集包括内部数据集(来自广州医科大学第一附属医院的患者),外部数据集(来自其他15个中心的患者),以及TCGA公共数据集。
- 文章中提到了使用来自16家医院及公共数据库(癌症基因组图谱TCGA)的大量肺癌患者数据,形成目前为止数据量最大的配对数据集。这些数据用于训练和验证DeepGEM模型,以展示其在不同患者群体中的性能。
DeepGEM模型在内部保留测试集上预测基因突变的性能
表格展示了DeepGEM模型在不同类型的活检样本(切除活检和抽吸活检)中预测肺癌常见基因突变的性能。
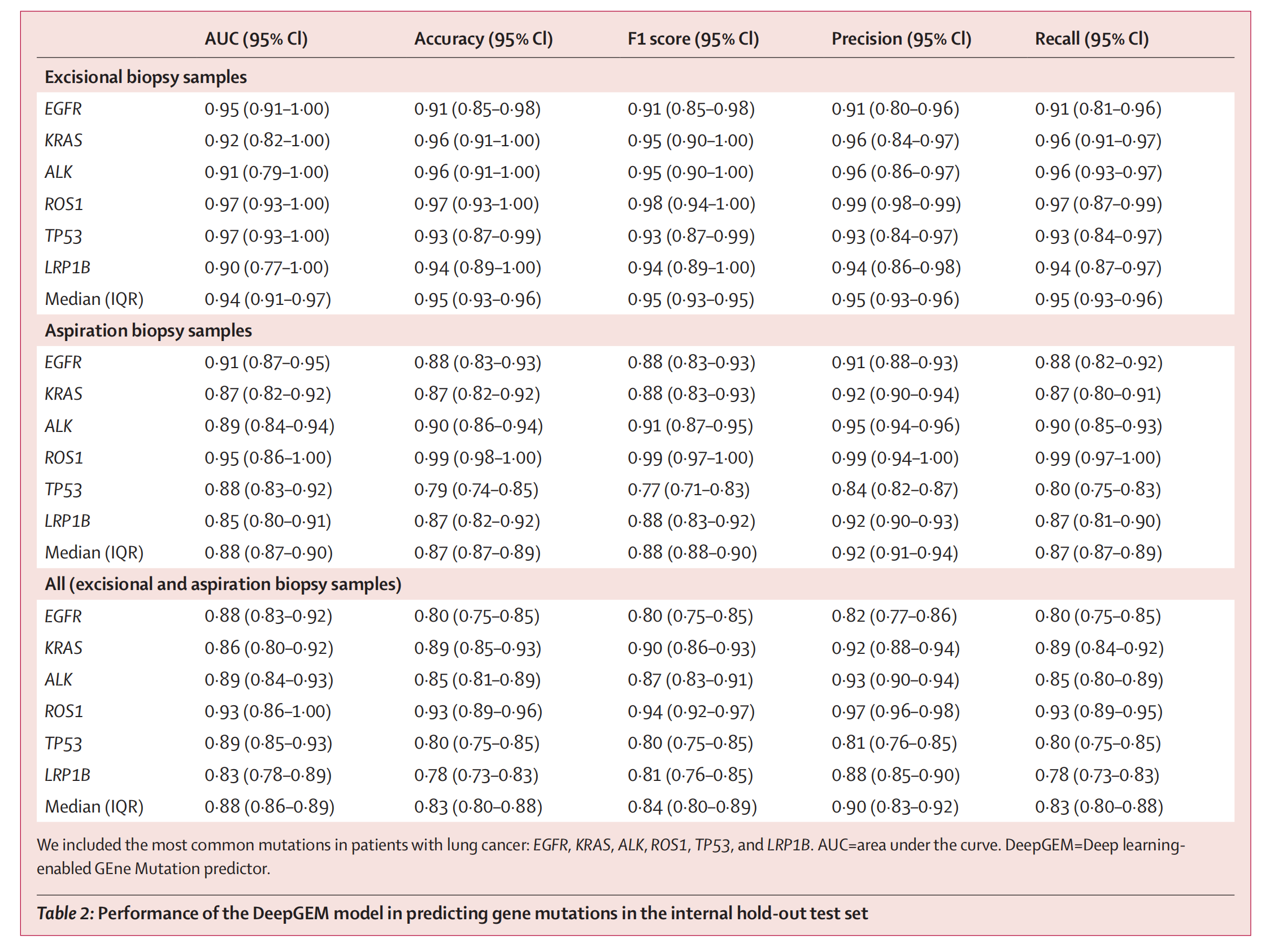
性能指标包括:
- AUC (Area Under the Curve): 反映模型区分正负样本的能力。
- Accuracy (准确率): 正确预测的比例。
- F1 score: 准确率和召回率的调和平均,综合考虑了模型的精确度和召回率。
- Precision (精确度): 正确预测为正的样本占所有预测为正样本的比例。
- Recall (召回率): 正确预测为正的样本占所有实际为正样本的比例。
专业名词
- 切除活检样本 (Excisional biopsy samples)
- 抽吸活检样本 (Aspiration biopsy samples)
- 所有活检样本 (All excisional and aspiration biopsy samples)
结论
DeepGEM模型在预测肺癌基因突变方面表现出色,尤其是在切除活检样本中。模型在预测ROS1和KRAS基因突变时表现最佳,具有高AUC和准确率。这表明DeepGEM模型可以作为肺癌基因突变预测的有力工具,有助于指导临床治疗决策。
ROS1和KRAS基因突变
ROS1和KRAS都是非小细胞肺癌(NSCLC)中重要的驱动基因突变,它们在肿瘤的发生、发展中起着关键作用。
ROS1基因突变
ROS1基因突变通常表现为基因的重组或融合,这种突变会导致ROS1蛋白与其他蛋白发生融合,形成持续激活的酪氨酸激酶,从而激活下游的信号传导通路,如JAK/STAT、PI3K/AKT和RAS/MAPK等,促进细胞的增殖和肿瘤的发生。
在非小细胞肺癌中,ROS1基因突变的发生率约为1%-2%,而且ROS1阳性的肺癌患者通常比较年轻,中位发病年龄在50岁左右。
针对ROS1突变的肺癌患者,可以使用特定的靶向药物,如克唑替尼,这类药物能够显著提高患者的生存期和生活质量。
KRAS基因突变
KRAS基因突变是三种RAS家族成员中最常见的一种,它在多种肿瘤中均有高比例的突变。
KRAS蛋白在细胞生长和分化中起着重要作用,当KRAS基因发生突变时,会导致其功能失常,细胞增殖失控,进而导致癌变。KRAS基因突变在肺癌中的发生率较高,尤其是在西方国家,KRAS G12C是最常见的KRAS变体,占KRAS突变的40%左右。
针对KRAS G12C突变的NSCLC患者,已有靶向药物如索托雷塞(Sotorasib)获得FDA加速批准上市,为患者提供了新的治疗选择。
总的来说,ROS1和KRAS基因突变在肺癌治疗中具有重要的临床意义,针对这些突变的靶向治疗可以显著改善患者预后。
三、跨领域数据融合:优化癌症治疗结果预测

一作&通讯
| 角色 | 姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Justin Jee | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 第一作者 | Christopher Fong | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 第一作者 | Karl Pichotta | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 第一作者 | Thinh Ngoc Tran | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 第一作者 | Anisha Luthra | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
| 通讯作者 | Nikolaus Schultz | 纪念斯隆凯特琳癌症中心(Memorial Sloan Kettering Cancer Center) |
文献概述
通过结合自然语言处理和多模态数据集成,可以提高癌症预后预测的准确性。
-
研究背景:随着健康记录的数字化和肿瘤DNA测序的普及,研究者有机会以前所未有的丰富度研究癌症结果的决定因素。患者数据通常存储在非结构化文本和孤立的数据集中。
-
MSK-CHORD数据集:研究者结合自然语言处理(NLP)注释和结构化的药物、患者报告的人口统计、肿瘤登记和肿瘤基因组数据,从纪念斯隆凯特琳癌症中心的24,950名患者中生成了一个临床基因组、协调的肿瘤真实世界数据集(MSK-CHORD)。这个数据集包括非小细胞肺癌、乳腺癌、结直肠癌、前列腺癌和胰腺癌的数据,并且能够发现在较小数据集中不明显的临床基因组关系。
-
机器学习模型:利用MSK-CHORD训练机器学习模型来预测总体生存率,研究发现包含自然语言处理衍生特征(如疾病部位)的模型比仅基于基因组数据或阶段的模型表现更好。
-
放射学报告注释:通过注释705,241份放射学报告,MSK-CHORD还揭示了特定器官部位转移的预测因子,包括SETD2突变与免疫治疗肺腺癌较低转移潜力之间的关系,这在独立数据集中得到了证实。
-
电子健康记录的普遍性:提供了一个未被充分利用的数据基质,用于转化医学。尽管从自由文本患者访问、放射学、组织病理学和程序笔记中抽象关键元素的传统限制了分析,但自然语言处理(NLP)现在允许自动注释这些特征。
-
研究结果:研究结果表明,结合真实世界数据(RWD)在预测肿瘤轨迹方面具有巨大潜力。通过整合医院、学术和商业实体的数据,研究者能够克服这些数据孤岛,发现基因组修饰响应的修饰因子。
-
自动化注释:研究者开发了算法,自动注释自由文本报告,包括癌症进展、肿瘤部位和放射学报告印象部分的任何癌症存在。
-
MSK-CHORD的组装:MSK-CHORD结合了NLP衍生的特征和机构的人口统计、治疗和肿瘤登记数据,以及使用MSK-IMPACT的肿瘤基因组分析。
-
MSK-CHORD的发现:MSK-CHORD的大小使得足够有力的识别治疗后突变成为可能,并且NLP衍生的先前治疗是此类分析中机构治疗记录的重要补充。
-
综合多模态模型:研究者构建了随机生存森林(RSF)模型,以预测从队列进入时间起的总体生存率(OS),并测试了训练在相关变量子集上的模型的性能。
-
基因组预测转移部位:研究者使用NLP注释了所有705,241份放射学报告中疾病转移部位的存在,并研究了特定基因的致癌改变是否与这些器官部位的未来转移率有关。
-
SETD2和免疫治疗在LUAD中的作用:研究者发现SETD2驱动突变是肺腺癌(LUAD)患者较长OS的预测因子,并且在独立数据集中证实了这些发现。
文章最后讨论了RWD在帮助科学家和临床医生更好地理解疾病如癌症方面的潜力,并强调了多个数据流在预测结果中的重要性。研究者希望MSK-CHORD能够促进进一步的研究,以探索癌症中真实世界基因型-表型关系。
代码链接和数据集,以及它们在文章中的作用
-
MSK-CHORD 数据集
- 链接:MSK-CHORD on cBioPortal
- 作用:文章中提到,MSK-CHORD 是一个临床基因组、协调的肿瘤真实世界数据集,它结合了自然语言处理注释和结构化的药物、患者报告的人口统计、肿瘤登记和肿瘤基因组数据。这个数据集使得研究者能够发现在较小数据集中不明显的临床基因组关系,并用于训练机器学习模型来预测总体生存率。
-
GENIE BPC 数据集
- 链接:GENIE BPC on cBioPortal
- 作用:文章中提到,GENIE BPC 数据集是由美国癌症研究协会的 Project GENIE 生物制药合作项目提供的,包含了来自四个癌症中心的非小细胞肺癌、乳腺癌、结直肠癌、前列腺癌和胰腺癌患者的肿瘤基因组测序和临床注释数据。这个数据集与 MSK-CHORD 数据集部分重叠,用于支持研究和分析。
-
GitHub - 医疗NLP领域相关资源
- 链接:Chinese_medical_NLP on GitHub
- 作用:虽然这个链接并不是直接来自文章,但它提供了医疗NLP领域的测评/比赛、数据集/知识图谱、开源大模型、论文和工具包等资源。
泛癌临床数据集MSK-CHORD的构建流程
这张图片包含了四个部分(a, b, c, d),它们共同概述了关于MSK-CHORD数据集的创建和应用流程。
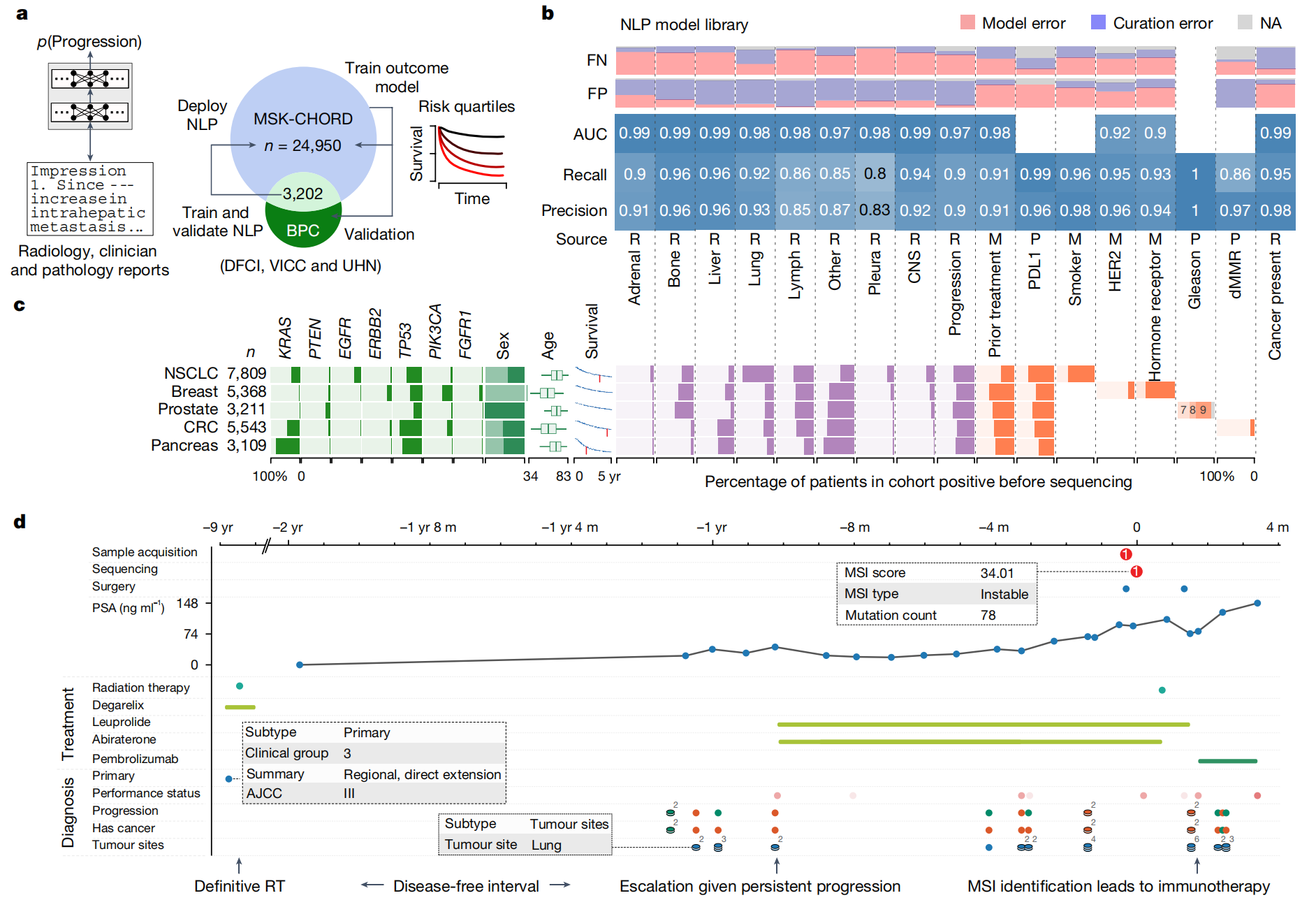
a. 创建MSK-CHORD数据集
- 流程:从24,950名患者的非结构化文本和孤立数据集中,通过自然语言处理(NLP)技术提取信息,创建了一个综合的肿瘤学真实世界数据集(MSK-CHORD)。
- 数据来源:包括放射学印象(R)、医学肿瘤学笔记(M)和组织病理学报告(P)。
- 训练和验证:使用3,202名患者(BPC)的数据来训练和验证NLP模型。
b. NLP模型库性能
- 性能评估:通过交叉验证或在MSK-BPC队列中保留的验证集来评估NLP模型库的性能。
- 错误审计:对随机选择的假阳性(FP)和假阴性(FN)案例进行了独立审查,以审计模型失败的原因。在某些情况下(紫色标记),原始的策划标签是不正确的。
- 精确度、召回率和AUC:展示了不同来源文本的模型性能,包括放射学印象、医学肿瘤学笔记和组织病理学报告。
c. MSK-CHORD特征概览
- 年龄分布:箱线图显示了年龄的中位数、四分位数和±95%百分位数。
- 患者特征比例:条形图显示了具有特定特征的患者比例。
- 基因组改变:仅包括被OncoKB注释为致癌的基因组改变,这些改变来源于MSK-IMPACT的肿瘤活检测序。
- 生存曲线:Kaplan-Meier生存曲线显示了各个队列的中位生存期,用红色标记表示。
d. 在cBioPortal中可视化患者级数据
- 案例研究:展示了一位前列腺腺癌患者(P-0050196)的案例,该患者接受了针对III期疾病的放射治疗,后来在肺部出现了转移性复发,并接受了包括pembrolizumab在内的多线治疗。
- 治疗信息:包括手术、激素治疗(Degarelix、Leuprolide、Abiraterone)、放射治疗和免疫治疗(Pembrolizumab)。
- 生物标志物:MSI(微卫星不稳定性)状态和评分,以及突变计数。
这张图片提供了一个全面的视角,展示了如何通过NLP技术从非结构化数据中提取信息,创建一个综合的数据集,并利用这个数据集来改进癌症治疗和预后预测。
什么是肿瘤学真实世界数据集?
肿瘤学真实世界数据集是指在肿瘤学领域内,从多种来源收集的与患者健康状况、诊疗及保健有关的数据。
这些数据并非都来自传统的临床试验,而是包括了电子健康记录(EHRs)、账单信息、医疗索赔、药房配药记录、产品和疾病相关的登记册、患者生成的数据,以及来自移动设备和可穿戴设备等电子健康解决方案的数据。
真实世界数据(Real World Data, RWD)经过适当的分析,可以形成真实世界证据(Real World Evidence, RWE),用于支持监管决策和临床实践。
肿瘤学真实世界数据集的特点包括:
- 数据来源广泛:包括现有的行政数据来源,如监测、流行病学和结果(SEER)数据库和CancerLinQ数据库等。
- 数据类型多样:涵盖基因组、转录组、蛋白组、表观遗传等多种生物信息学数据。
- 数据量大:由于数据来源于真实世界的广泛收集,因此数据量通常较大。
- 数据的复杂性:可能存在数据不完整、数据标准、数据模型和描述方法不统一等问题,需要通过数据治理和分析来解决这些问题。
- 应用价值:真实世界数据集在补充临床试验、实现有条件的报销和加速药物获取,以及创新试验行为方面可能发挥关键作用。
肿瘤学真实世界数据集的应用包括提供疾病流行病学信息、药物警戒和医疗质量评估,以及支持药物适应症的扩展或细化,并促进新生物标志物的发现和验证。随着技术的发展,这些数据集在肿瘤学研究和治疗中的作用日益重要。
如何理解肿瘤的多线治疗?
肿瘤的多线治疗是指在癌症治疗过程中,患者可能会接受的一系列连续的治疗,这些治疗通常按照效果和副作用的不同,以及患者对治疗的反应,分为不同的“线”。
具体来说:
-
一线治疗:这是诊断后推荐的最初治疗方法,通常包括效果最好、副作用最小的治疗方案,目的是尽可能治愈肿瘤。
-
二线治疗:当一线治疗后患者再次出现肿瘤进展,且对一线治疗方案耐药时,会更换抗癌机理不同的治疗方案。二线治疗的效果通常不如一线治疗,副作用可能更大,成本也可能更高。
-
三线治疗:在二线治疗失败后,患者会接受另一种治疗方案。到了三线治疗阶段,可选择的有效药物和治疗方案通常越来越少。
这种分层的治疗策略允许医生根据患者的病情变化和治疗反应,逐步调整治疗方案。随着治疗线的增加,治疗的挑战性也随之增加,因为患者可能对先前的治疗产生了耐药性,而且可供选择的有效治疗可能减少。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









