







准备数据
电影评论数据下载地址
将文本数据处理成torch,我们希望可以得到的target是他的评论态度是积极还是消极,将数据分为2500训练,2500测试,这里网址下载的数据数量已经分好了,利用pytorch进行文本处理
处理数据
遇到这个问题
RuntimeError: each element in list of batch should be of equal size
这里重写一下Dataloader中的collate_fn方法
import os
import re
from lib import ws,max_len
import torch
from torch.utils.data import Dataset,DataLoader
# 将一个句子分为由单词组成的列表
def tokenize(str):
# 这个是re库里的函数,其原型为re.sub(pattern, repl, string, count)
# 第一个参数为正则表达式需要被替换的参数,第二个参数是替换后的字符串,
# 第三个参数为输入的字符串,第四个参数指替换个数。默认为0,表示每个匹配项都替换。
filter = ['!','"','#','$','%','&','\(','\)','\*','\+',',','-','\.','/',':',';','<','=','>','\?','@'
,'\[','\\','\]','^','_','`','\{','\|','\}','~','\t','\n','\x97','\x96','”','“']
token = re.sub('|'.join(filter),'',str)
token = token.strip()
return token.split(' ')
class Datas(Dataset):
def __init__(self,train=True):
self.train_path = r'data/aclImdb/train'
self.test_path = r'data/aclImdb/test'
temp_path = self.train_path if train else self.test_path
data_path = [temp_path+'/pos', temp_path+'/neg']
# 将含评论的所有文件放在列表中
self.files = []
for i in data_path:
listdirs = os.listdir(i)
data_path2 = [i+'/'+j for j in listdirs]
self.files.extend(data_path2)
def __len__(self):
# 有多少评论数据
return len(self.files)
def __getitem__(self, index):
file_path = self.files[index]
label = file_path.split('/')[-2]
label = 1 if label == 'pos' else 0
# 这里label就是我们想预测的
# 从文件中读到的是真实值
content = open(file_path,encoding='utf-8').read()
# 返回经过分词的句子列表
return label,tokenize(content)
# 需要重写collate_fn方法
def collate_fn(batch):
# batch是一个列表,其中是一个一个的元组,每个元组是dataset中_getitem__的结果
batch = list(zip(*batch))
labels = torch.tensor(batch[0], dtype=torch.int64)
texts = batch[1]
texts = [ws.transform(text,max_len=max_len) for text in texts]
texts = torch.LongTensor(texts)
# labels = torch.LongTensor(labels)
del batch
# 返回真实值,评论(特征值)
return labels, texts
def get_dataloader():
data = Datas(True)
dataloader = DataLoader(dataset=data, batch_size=64, shuffle=True, collate_fn=collate_fn)
# 传入经过分词的64个评论一个batch进入到数据加载器中
return dataloader
if __name__ == '__main__':
# print(tokenize("e D:/test/deep_learing/test/text_test.py data/aclImdb/train/pos/0_9.txt pos1"))
for idx,(input,out) in enumerate(get_dataloader()):
print(idx)
print(input)
print(out)
break
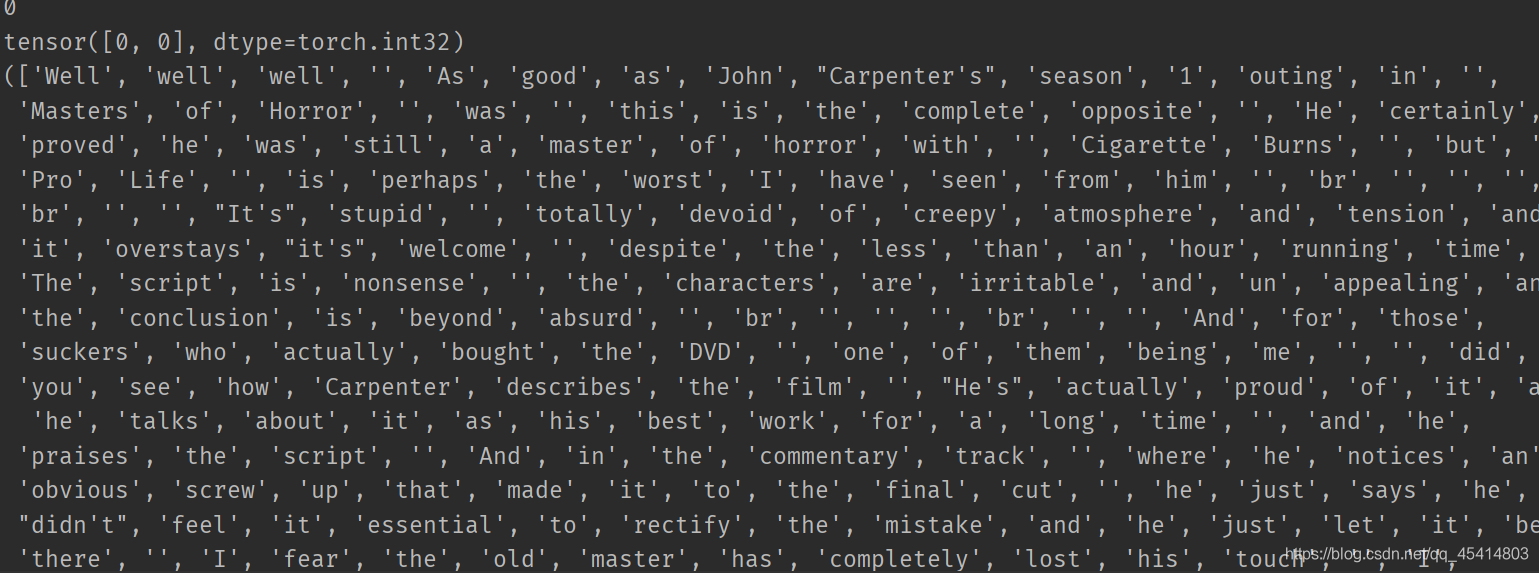
结果是这样,第二行的tensor代表的是两个评论的label都是0因为,第三行是两个评论的文本分词
得到了评论的数据之后,我们需要对词语进行序列化
即把词语转换为数字
序列化
class word2sequense():
# 定义当我们训练出来的词典的两个关键词:UNK就是字典里没有出现的,APP就是由于句子长度不够,填充的符号
unknown_tag = 'UNK'
append_tag = 'APP'
UNK = 0
APP = 1
def __init__(self):
# 定义词典
self.dict = {
self.unknown_tag:self.UNK,
self.append_tag:self.APP
}
# 统计词频
count = {}
def fit(self,sentence):
for word in sentence:
self.count[word] = self.count.get(word,0) + 1
def filter_count(self,min=5,max=None,max_features=None):
"""
:param min:最小词频
:param max: 最大词频
:param max_features:一共保存的词语个数
:return:
"""
# 去掉词频小于min的
self.count = {word:value for word,value in self.count.items() if value > min}
# 去掉大于max的
if max is not None:
self.count = {word: value for word, value in self.count.items() if value < max}
if max_features is not None:
# 把count进行排序,取出前max_features个
temp = sorted(self.count.items(),key=lambda x:x[-1],reverse=True)[:max_features]
# 转回字典
self.count = dict(temp)
# 将单词用数字表示,数字就是第几个加到词典的
for word in self.count:
self.dict[word] = len(self.dict)
# 将数字用单词表示
self.dict2 = dict(zip(self.dict.values(),self.dict.keys()))
def transform(self,sentence,max_len=None):
if max_len is not None:
# 将句子长度统一
if max_len>len(sentence):
# 当长度不够的时候,在句子后面加上对应数量的app符号
sentence += [self.APP]*(max_len-len(sentence))
if max_len<len(sentence):
# 裁剪后面的
sentence = sentence[:max_len]
# 将句子转换成序列
# for word in sentence:
# self.dict.get(word,self.UNK)
return [self.dict.get(word,self.UNK) for word in sentence]
# 从dict里找单词的编号,找不到为0
def inverse_trans(self,indics):
# 将序列转换成句子
return [self.dict2.get(indx) for indx in indics]
def __len__(self):
return len(self.dict)
if __name__ == '__main__':
word2 = word2sequense()
word2.fit(['日','你','妈'])
word2.fit(['退','钱'])
word2.fit(['中','果','足','球','冲','进','世界','杯'])
word2.filter_count(min=0)
print(word2.dict)
print(word2.dict2)
结果是这样

在这里将使用pickle将以上保存起来
import pickle
from tqdm import tqdm
# 显示进度
import os
from text_test import tokenize
from word2 import word2sequense
ws = word2sequense()
# ws就是我们的序列化器
# 传入要训练的句子,从train文件中将所有的评论文件放入
train_path = r'data/aclImdb/train'
data_path = [train_path + '/pos', train_path + '/neg']
files = []
for i in data_path:
listdirs = os.listdir(i)
datas_path = [i + '/' + j for j in listdirs]
for data in tqdm(datas_path):
sentence = tokenize(open(data,encoding='UTF-8').read())
ws.fit(sentence)
ws.filter_count()
# 将训练好的词典保存起来
pickle.dump(ws, open(r'model/ws.okl','wb'))
print(len(ws))
在这里如果出现了open error找不到文件,创建就好了不知道为什么wb模式自动创建没有成功,不过我们手动创建的小效果一样
如果出现了编码的问题,open的时候加入encoding='utf-8’即可,具体情况具体分析.
在这里保存之后,后续使用pickle.load(model/ws.okl)进行载入
去之前的最开始的地方进行检测
对前面的collate_fn进行部分修改
def collate_fn(batch):
# batch是一个列表,其中是一个一个的元组,每个元组是dataset中_getitem__的结果
batch = list(zip(*batch))
labels = torch.tensor(batch[0], dtype=torch.int32)
texts = batch[1]
texts = [ws.transform(text) for text in texts]
del batch
return labels, texts
修改后的运行结果
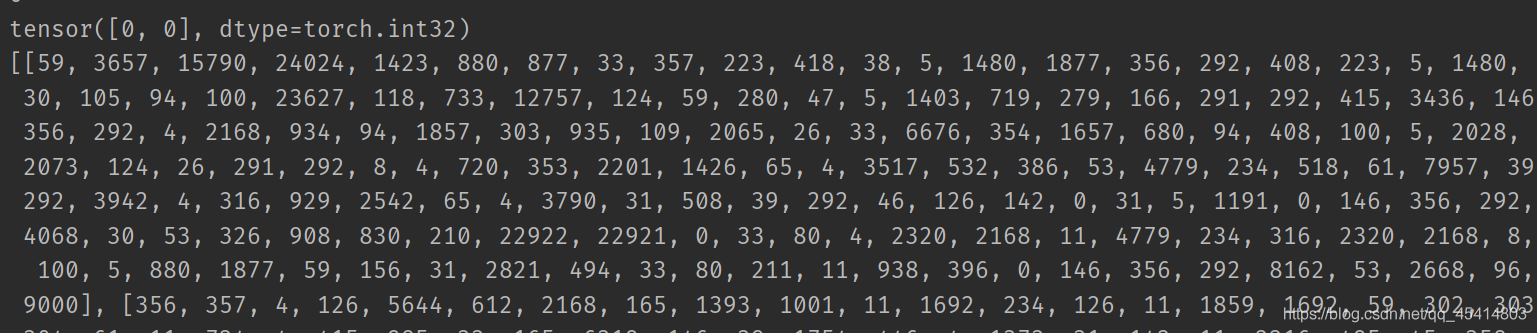
从之前的词语成功的变为数字,达到了目的
,至此数据处理完成
模型建立

模型建立之后遇到了问题,注意以下label和text的顺序,就好了
import torch.nn as nn
from lib import ws,max_len
import torch.nn.functional as f
from torch.optim import Adam
class mymodel(nn.Module):
def __init__(self):
super(mymodel, self).__init__()
self.embedding = nn.Embedding(len(ws),100)
# 传入参数:词的数量,多少个词形成一个向量
self.fc = nn.Linear(max_len*100,2)
def forward(self,input):
"""
:param input:[batch_size,句子长度(max_size)]
:return:
"""
x = self.embedding(input) # x的形状为[batch_size,句子长度(max_size),100]
# 变换形状
x = x.view([-1,max_len*100])
out = self.fc(x)
return f.log_softmax(out)
from text_test import get_dataloader
model = mymodel()
# 优化器,传入参数和学习率
optimizer= Adam(model.parameters(),0.001)
def train():
for idx,(out,input) in enumerate(get_dataloader()):
optimizer.zero_grad()
pre = model(input)
# 计算损失
loss = f.nll_loss(pre,out)
loss.backward()
optimizer.step()
print(loss.item())
if __name__ == '__main__':
train()
运行结果:
RNN循环神经网络的使用进行优化
这里只是将几个单词看成一个向量,训练的效果并不好
循环神经网络的使用,可以让数据具有时序性,即考虑的不仅仅是当前的输入,也考虑之前的输入来调节参数的概率从而使训练效果更好
具有短期记忆–rnn循环神经网络
RNN分类
使用LSTM解决RNN中的长期依赖问题(long-Term Dependencies)
rnn存在间隔长的词语,导致前面的词语对后面的影响小的问题,即长期依赖问题
LSTM的三个输入:
上一次的隐藏状态+上一次的细胞状态(记忆)+本次的输入
三个输出:
隐藏状态+细胞状态+输出,输出和隐藏状态是一样的
输入的形状:
input : [seq_len,batch,embedding size]
输出的形状:
output:[seq_len, batch, num_directions * hidden_size]—>batch_first=False
,/其中hidden_size为一层神经系统里有多少lstm,num_direction是由单向lstm还是双向决定的
单向为1,双向为2
h_n(隐藏状态):(num_layers * num_directions, batch, hidden_size)
c_n(细胞状态): (num_layers * num_directions, batch, hidden_size)
num_layers为有多少层神经系统
实例化LSTM
torch.nn.LSTM(input_size,hidden_size,num_layers,batch_first,dropout,bidirectional)
input_size:输入数据的形状,即embedding_dim
hidden_size:隐藏层神经元的数量,即每一层有多少个LSTM单元
num_layer :即RNN的中LSTM单元的层数
batch_first:默认值为False,输入的数据需要[seq_len,batch,feature],如果为True,则为[batch,seq_len,feature]
dropout:dropout的比例,默认值为0。dropout是一种训练过程中让部分参数随机失活的一种方式,能够提高训练速度,同时能够解决过拟合的问题。这里是在LSTM的最后一层,对每个输出进行dropout
bidirectional:是否使用双向LSTM,默认是False
import os
import torch
import torch.nn as nn
from lib import ws,max_len
import torch.nn.functional as f
from torch.optim import Adam
import lib
class mymodel(nn.Module):
def __init__(self):
super(mymodel, self).__init__()
self.embedding = nn.Embedding(len(ws),100)
# 传入参数:词的数量,多少个词形成一个向量
self.fc = nn.Linear(lib.hidden_size*2,2)
# LSTM优化,实例化
self.LSTM= nn.LSTM(input_size=100,hidden_size=lib.hidden_size,
num_layers=lib.layer_num,bidirectional=lib.biderational,
batch_first=True,dropout=lib.dropout)
def forward(self,input):
"""
:param input:[batch_size,句子长度(max_size)]
:return:
"""
x = self.embedding(input) # x的形状为[batch_size,句子长度(max_size),100]
# 变换形状
# lstm处理
x,(h_n,c_n) = self.LSTM(x)
# x的形状[batch_size,句子长度(max_size),batch_size*2(方向)],h_n的形状[方向*层数(4),batch_size,hidden_size,]
# c_n的形状[方向*层数(4),batch_size,hidden_size]
# 获取两个方向的output进行拼接,第一维是层数,第一层正向的最后一个,即层数-2,第二层就是-1
output_fw = h_n[-2,:,:]
output_bw = h_n[-1,:,:]
output = torch.cat((output_fw,output_bw),dim=-1)
# output形状为[batch_size,hidden_size*2]
# x = x.view([-1,max_len*100])
out = self.fc(output)
return f.log_softmax(out)
from text_test import get_dataloader
model = mymodel()
# 优化器,传入参数和学习率
optimizer= Adam(model.parameters(),0.001)
if os.path.exists('model/model1.okl'):
model.load_state_dict(torch.load('model/model1.kl'))
optimizer.load_state_dict(torch.load('model/opt1.kl'))
def train():
for idx,(out,input) in enumerate(get_dataloader()):
optimizer.zero_grad()
pre = model(input)
# 计算损失
loss = f.nll_loss(pre,out)
loss.backward()
optimizer.step()
print(loss.item())
# 保存模型
if idx % 100 == 0:
torch.save(model.state_dict(),'model/model1.okl')
torch.save(optimizer.state_dict(),'model/opt1.okl')
if __name__ == '__main__':
train()
进行训练的时候.使用cpu训练的时间较长采用gpu计算
校验模型
模型的检验使用训练好的模型,将test数据放入,获取到误差的平均值和准确值作为模型评判















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









