






需要知道:
正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本
许多程序设计语言都支持利用正则表达式进行字符串操作,例如,在Perl中就内建了一个功能强大的正则表达式引擎
正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的
正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”
这个“规则字符串”用来表达对字符串的一种过滤逻辑
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式
就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串
一、grep文本过滤命令
==有关grep:==全面搜索研究正则表达式并显示出来
grep 命令是一种强大的文本搜索工具 , 根据用户指定的“模式”对目标文本进行匹配检查 , 打印匹配到的行
由正则表达式或者字符及基本文本字符所编写的过滤条件
首先准备实验筛选文件:
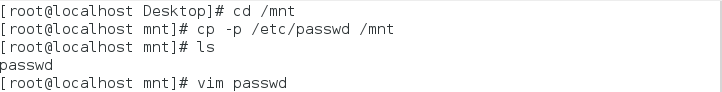

常用命令:1.grep 匹配条件 处理文件
| grep root passwd | 筛选passwd中有root字符的 |
|---|---|
| grep ^root passwd | 筛选passwd中以root字符开头的 |
| grep root$ passwd | 筛选passwd中以root字符结尾的 |
| grep -i root passwd | 筛选passwd中有root字符的且不区分大小写 |
| grep -E "root | ROOT" passwd |
如图:
/1.grep "root" passwd 筛选passwd中有root字符的

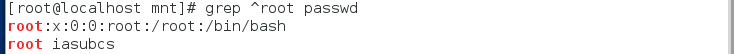


grep "root" passwd -in
筛选passwd中有root字符的且不区分大小写,显示行号

grep "root" passwd -i 筛选passwd中有root字符的且不区分大小写

grep -in "^root" passwd
筛选passwd中以root字符开头的并显示行号


grep -Ein "^root|root$" passwd
筛选passwd中以root字符开头或结尾的并显示行号

grep ROOT passwd -2 筛选passwd中有root字符,并且的上下两行也显示

grep root passwd -v
显示除了所筛选的字符

grep root passwd -2
所筛选字符的上下两行也显示

查看passwd文件并且显示行号

查看并且过滤包括lp的行

打印匹配以及匹配行的上下2行

打印匹配行的后两行

打印匹配行的前两行

2.正则表达式; grep "w....s" file 打印w和s中间包括四个字符的行

grep "w...." file 打印w开头,后面四个字符的行

grep "....s" file 打印s结尾,前面四个字符的行

3.grep中字符的匹配次数设定
| * | 字符出现[0-任意次] |
|---|---|
| ? | 字符出现[0-1次] |
| + | 字符出现[1-任意次] |
| {n} | 字符出现[n次] |
| {m,n} | 字符出现[至少m次,最多出现n次] |
| {0,n} | 字符出现[0-n次] |
| {m,} | 字符出现[至少m次] |
| (xy){n}xy | 关键字出现[n次] |
| .* | 关键字之间匹配任意字符 |
首先编辑实验筛选文件


打印含有ab的行

打印含有ab或者a和b之间有0-任意多字符的行

打印b前面出现0-1次a的行

打印b前面至少出现一次a的行

打印b前面出现两次a的行

打印b前面a最少出现两次,最多出现三次的行

打印b前面a至少出现2次的行

打印b前面a出现0-2次的行

打印a和b之间出现0-多个字符的行

打印b前面有0-多个a的行


(2)grep中字符的匹配位置设定
| ^关键字 | 以xx开头 |
|---|---|
| 关键字& | 以xx结尾 |
| <关键字 | 以xx开头 |
| 关键字> | 以xx结尾 |
| <关键字> | 含xx |





注意
grep 正则表达式与扩展正则表达式
正规的 grep 不支持扩展的正则表达式子 , 竖线是用于表示”或”的扩展正则表达式元字符 , 正规的 grep 无法识别
加上反斜杠 , 这个字符就被翻译成扩展正则表达式 , 就像 egrp,和grep -E 一样
二、sed行编辑器
sed命令的概念
SED是一项Linux指令,功能同awk类似,差别在于,sed简单,对列处理的功能要差一些,awk的功能复杂,对列处理的功能比较强大
sed用来操作纯 ASCII 码的文本
处理时 , 把当前处理的行存储在临时缓冲区中 , 称为“模式空间” (pattern space) ,可以指定仅仅处理哪些行
sed 符合模式条件的处理,不符合条件的不予处理,处理完成之后把缓冲区的内容送往屏幕
接着处理下一行 , 这样不断重复 , 直到文件末尾
原来的内容是在磁盘当中放着,现在用sed命令处理的时候将内容掉入内存的一个地方用户处理,这个处理空间也叫模式空间
1)sed对字符的处理`
| p | 显示 |
|---|---|
| d | 删除 |
| a | 添加 |
| c | 替换 |
| w | 写入 |
| i | 插入 |
准备文件筛选文件
p模式(按照要求显示行)

cat的相关命令:
查看fstab文件不显示行号
查看fstab不显示空行

查看文件显示空行

显示第5行并且原来文件也显示(所以两行)

-n只显示模式空间的内容,不显示原来的,所以只显示第五行

显示第三到五行

显示第三行和第五行

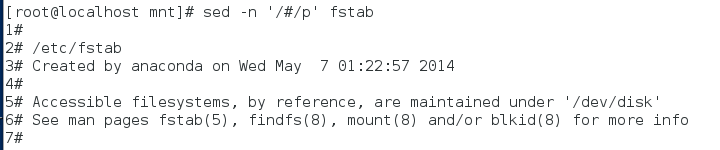
sed -n '/\:/p' fstab 显示含有":"的行
sed -n '/UUID$/p' fstab 显示以UUID结尾的行
sed -n '/^UUID/p' fstab 显示以UUID开头的行
sed -n '2,6p' fstab 显示第二到六行
sed -n '2,6!p' fstab 显示除过第二到六行的信息
显示包括#的行
显示不包括#的行

显示空行和不显示空行

两者结合

注意
-n参数的区别:不加内容显示两次,加了显示一次


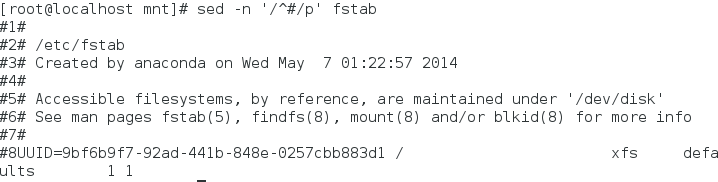
d模式(按照要求删除行)
sed '/^#/d' fstab 除了以“#”开头的都显示

sed '/4$/d' fstab 除了以“4”结尾的都显示

sed '1,4d' fstab 除了1至4行都显示

sed '/^$/d' fstab 不显示空行
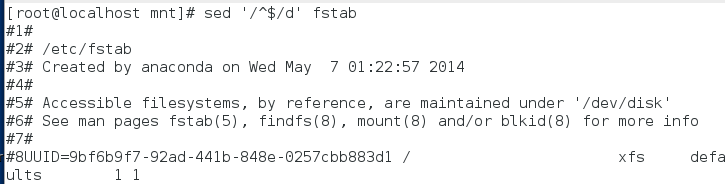
sed '1d;4d' fstab 除了第1行和第4行都显示

sed '/^UUID/!d' fstab 除了不是以“UUID”开头的都显示(显示以UUID开头的)

sed行编辑器的其他命令
sed '/^UUID/a'\hello' sed fstab 在以“UUID”开头的行的后面一行添加"hello"

sed '/^UUID/a\hello sed\nwestos' fstab 在以“UUID”开头的行的后面一行添加"hello",然后在下一行添加"westos"(\n为换行符)

sed '/^UUID/i'\hello' sed fstab 在以“UUID”开头的行的前面一行添加"hello"
sed '/^UUID/a\hello sed\nwestos' fstab 在以“UUID”开头的行的前面一行添加"hello",然后再添加一行"westos"


sed '/^UUID/i'\hello' sed fstab 在以“UUID”开头的行的前面一行添加"hello"
sed '/^UUID/w hahaha' fstab 将fstab以“UUID”开头的行添加到文件hahaha中


sed -n '/^UUID/w haha' fstab 将fstab以“UUID”开头的行添加到文件haha中,并且不显示

sed '6r /mnt/lee' fstab 将fstab第6行添加到文件lee中
sed '/^UUID/c\hello sed\nwestos' fstab 将fstab以“UUID”开头的行替换为"hell sed",并且在下一行添加"westos"

sed '/^UUID/=' fstab 在以“UUID”开头的行前面一行添加行号

sed -n -e '/^UUID/p' -e '/^UUID/=' fstab 显示以“UUID”开头的行并在后面面一行添加行号

sed -e 's/sbin/lee/g;s/nologin/#####/' passwd 将passwd中的"sbin"替换为"lee",并且把"nologin"替换为"#####"

sed 's/^\//#/' fstab 将fstab中以“\”开头的“\”替换为“#”

sed 's@^/@#@g' fstab 将fstab中以“\”开头的“\”替换为“#”

sed 's/\//#/g' fstab 将fstab中“/”替换为#

三、报告生成器(awk)
awk处理机制:awk会逐行处理文本,支持在处理第一行之前做一些准备工作,以及在处理完最后一行做一些总结性质的工作,然后将结果展现给用户
在命令格式上分别体现如下 :
BEGIN{}:读入第一行文本之前执行,一般用来初始化操作
{}:逐行处理,逐行读入文本执行相应的处理,是最常见的编辑指令
END{}:处理完最后一行文本之后执行 , 一般用来输出处理
AWK是一个优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一
这种编程及数据操作语言(其名称得自于它的创始人阿尔佛雷德·艾侯、彼得·温伯格和布莱恩·柯林汉姓氏的首个字母)的最大功能取决于一个人所拥有的知识
awk经过改进生成的新的版本nawk,gawk,现在默认linux系统下日常使用的是gawk,用命令可以查看正在应用的awk的来源(ls -l /bin/awk
基本用法一
准备筛选文件/etc/passwd
打印passwd文件中以:分隔符的第一列

打印第一列和第二列不出现分隔符

打印第二lie

打印第二列并且在最前面加上linux

awk '{print FILENAME}' passwd 文件passwd中信息全部显示为文件名

awk '{print NR}' passwd 显示文件passwd中的行号,但不显示内容

awk -F : '{print NF}' passwd 显示文件passwd中的以":"为分隔符的每行的列数

awk 'BEGIN{n=0}/bash$/{n++}END{print n}' /etc/passwd 显示文件passwd中的以bash结尾的信息个数

awk -F : 'BEGIN{print "NAME"}{print $1}END{print "END"}' passwd 显示文件passwd中的第一列并且在第一行显示"NAME"在第最后一行显示"END"

awk '/bash$/{print}' /etc/passwd 显示文件passwd中的以"bash"结尾的信息

awk '/^r/{print}' passwd 显示文件passwd中的以“r”结尾的

awk -F : '$6~/\<bin/{print}' passwd 显示文件passwd中的第六列是以“bin”开头的信息

awk -F : '$6!~/\<bin/{print}' passwd 显示文件passwd中的除过第六列是以“bin”开头的信息的其他信息

设置编号在前:打印第一列

并打印行数

打印列数

打印第三行第一列

打印4-6行

打印4和6行
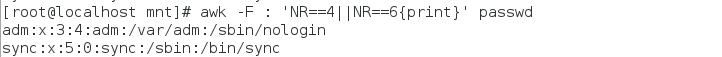
打印以R开头和bash结尾的

awk的应用
抓取主机ip
步骤如下:
抓取如下:

















 1221
1221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









