







HashMap以自定义的类作为键
import java.util.HashMap;
import java.util.Map;
class Key {
String title;
public Key(String title) {
this.title = title;
}
}
public class HashMapLeakDemo {
public static void main(String[] args) {
Map<Key, Integer> map = new HashMap<>();
map.put(new Key("1"), 1);
map.put(new Key("2"), 2);
map.put(new Key("3"), 3);
Integer integer = map.get(new Key("2"));
System.out.println(integer);
}
}
运行结果
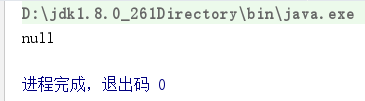
只重写equals方法或者只重写hashCode方法(结果都为null)
import java.util.HashMap;
import java.util.Map;
class Key {//同时重写两个方法才能正确得到结果输出2
String title;
public Key(String title) {
this.title = title;
}
// @Override
// public boolean equals(Object obj) {
// if (obj == null)
// return false;
// if (obj == this)
// return true;
// if (obj instanceof Key) {
// Key sd = (Key) obj;
// return sd.title.equals(title);
// }
// return false;
// }
@Override
public int hashCode() {
return title.hashCode();
}
}
public class HashMapLeakDemo {
public static void main(String[] args) {
Map<Key, Integer> map = new HashMap<>();
map.put(new Key("1"), 1);
map.put(new Key("2"), 2);
map.put(new Key("3"), 2);
Integer integer = map.get(new Key("2"));
System.out.println(integer);
}
}
原理和后果
hashmap是根据对象的哈希值作为键去寻找值的,如果在某一个对象的哈希值与hashmap里其中一个对象的哈希值相同的前提下就会去使用equals方法比较这两个对象是否“相等”,在没重写equals方法前,equals方法的内部实现是使用“==”比较两个对象地址是否相等的,但是每个独立的对象地址肯定是不相等的(new Key(“2”)这样的对象就是地址不相同的两个独立对象),但是我们值都是为2的对象啊,我们人类就会觉得他们就是相等的,所以我们要重新写一下equals方法的规则,不比较地址而是比较值是否一样。
不同时重写这两个方法会导致什么?首先就如上面所示,我们存进hashmap里的数据就拿不出来了。其次,放进hashmap里的野对象可能会越来越多而且垃圾回收又奈何不了这一部分的野对象,可能就会导致内存泄漏,最终导致OOM。














 3431
3431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









