







一、引入
本文总结一个数据倾斜的问题,该问题由 SQL 函数row_number()对手机号分组时引发,做数仓开发的同学在在业务实战过程中,或许会遇到过。
先简单介绍一下什么是数据倾斜和为什么会造成数据倾斜。
数据倾斜是在分布式计算系统中经常遇到的一种现象,特别是在大数据处理和分析领域。它指的是数据在被分割并分配到多个计算节点上进行并行处理时,数据分布不均匀,导致某些节点处理的数据量远远大于其他节点的现象。
在 MapReduce 中,数据倾斜也是比较常见的一个问题,稍不留意可能就会出现数据倾斜的问题。数据倾斜的根本原因大抵只有一个,数据值分布不均,或者叫出现热点值。
这也符合实际业务或实际生活中的情况,比如说令打工人感到痛苦的通勤早晚高峰,一天24小时中,高峰的时间段就是这两个时间段,白天其他时间段则相对稳定,然后在凌晨则是低谷期。表现在数据上,如果按小时来看,就会明显看到一个尖峰和一个低谷,数据分布明显不均匀。
同样的,像微博这种平台,大热的话题会有上亿的阅读和千万的讨论,而小话题,只有零星几人阅读,所以针对话题的数据分布极度不均匀。
这些现实问题映射到了一些大数据的处理上,就容易出现数据倾斜。
二、问题来源
本次的数据倾斜问题,来自使用row_number()函数对有大量空值的手机号字段进行分组,导致 Shuffle 阶段分布不均匀。
以下是一个简化之后的 SQL 结构,大致意思就是使用另外一个表 t1 的手机号,对用户表 t0 中的手机号字段的值进行补充,并对手机号进行标记,以便取最后关联的手机号。t0 是一个大表,有 2000 多万数据,t1 是小表,只有 30 多万数据。
INSERT OVERWRITE TABLE t2 PARTITION(cre_year,cre_month)
select /*+ mapjoin(t1)*/
t0.user_id
,coalesce(t1.mobile,t0.mobile) mobile
,if(row_number()over(partition by coalesce(t1.mobile,t0.mobile) order by t1.created_at desc,t0.created_at desc)=1,1,0) "mobile_label"
,year(t0.created_at) AS "cre_year"
,lpad(month(t0.created_at),2,'0') AS "cre_month"
from t0
left join t1 on t1.user_id=t0.user_id;
注:通过/*+ mapjoin(t1)*/指定在 Map 阶段进行 JOIN,避免 Shuffle 和减少 Reduce 阶段,降低网络负载,提高执行效率。
t0 表中的 mobile 字段有 80% 是空的,即使 t1 表进行补充,最多也就补充 1.5%,所以在进行row_number()过程中引发了数据倾斜。
该任务是跑在阿里云的 MaxCompute 上,可以通过 LogView 查看每个作业的具体任务,如下图,就是对应上面 SQL 中的 SELECT 任务,可以看到在 SELECT 中出现了数据倾斜,第一个任务跑了百分之七八十的数据,剩下的数据拆分为几十个任务给其他线程跑,发生了严重的数据倾斜,造成了一个长尾现象:第一个任务跑了 3分钟,其他任务五六秒就跑完了。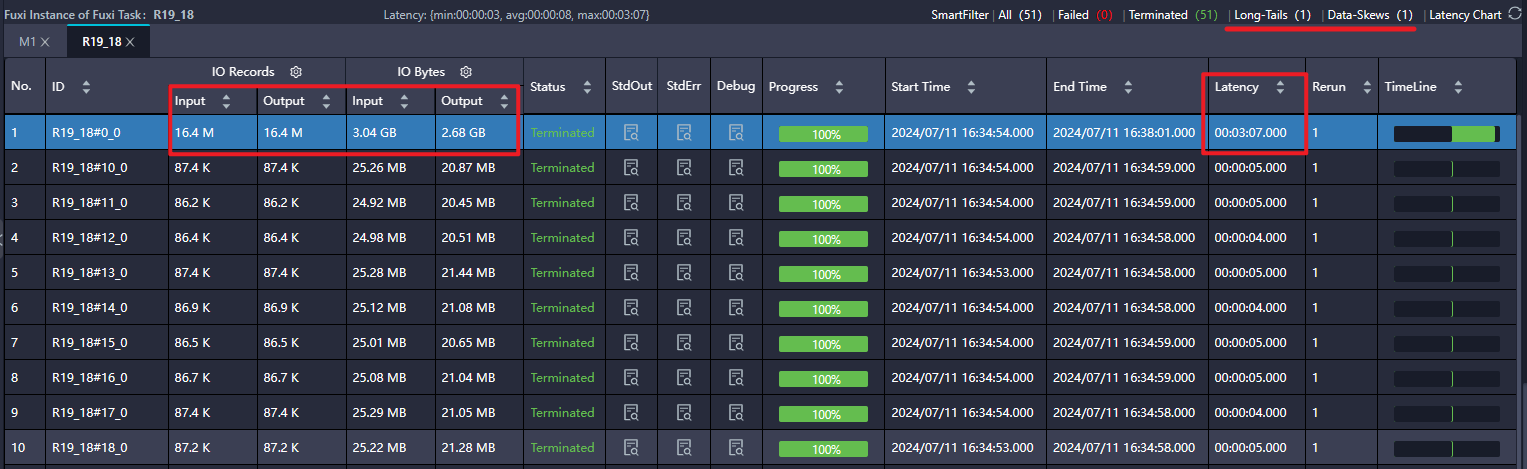
2.1 如何定位到是哪一个 SQL 节点出了问题?
在阿里云的 LogView 中的 Job Details 界面,可以看到有很多节点作业(Job),每一个作业对应一个或一类任务(Task)。
如下图,展示了 2 个作业,可以抽象地认为是上面 SQL 的作业图,作业 J18_3_4_8_11_12_15_16_17 把关联的表进行 JOIN 操作,而作业 R19_8 则是对 JOIN 结果进行处理(R19_8 对应的任务就是上文的截图,第一个任务跑了百分之七八十的数据,出现明显的长尾现象)。
双击 R19_18 查看详细的算子,可以看到读取数据之后就进行一个窗口函数计算,然后做数据分流。所以基本确认了,数据倾斜的问题就是在 SELECT 中的row_number()函数上。
三、如何解决该数据倾斜问题
该问题主要是空值太多导致 Shuffle 的时候分配到了同一个任务导致的,那么就手动给空值填充一个随机值即可。使用CONCAT(ROUND(RAND(),8)*100000000)手动给空值补充一个随机值(注意:该填充值并不是唯一的,仅做一种参考),这样便可以规避数据倾斜问题。
if(row_number()over(partition by coalesce(t1.mobile,t0.mobile,CONCAT(ROUND(RAND(),8)*100000000)) order by t1.created_at desc,t0.created_at desc)=1,1,0) "mobile_label"
但是该处理方式会使得标记手机号的数据,即标识为 1 的记录翻了 5 倍,我又想实现原来的效果,即对有手机号记录且为最后一个绑定的用户记录标记为1,方便后续筛选出相关记录,该怎么操作呢?
在if()条件上下功夫,加一个条件coalesce(t1.mobile,t0.mobile) is not null,参考如下。
if(row_number()over(partition by coalesce(t1.mobile,t0.mobile,CONCAT(ROUND(RAND(),8)*100000000)) order by t1.created_at desc,t0.created_at desc)=1 and coalesce(t1.mobile,t0.mobile) is not null,1,0) "mobile_label"
修改完跑一下任务,查看那 LogView,可以看到数据都均匀了,每个任务差不多分配 86 万条数据,174 MB,基本在 16 秒左右跑完。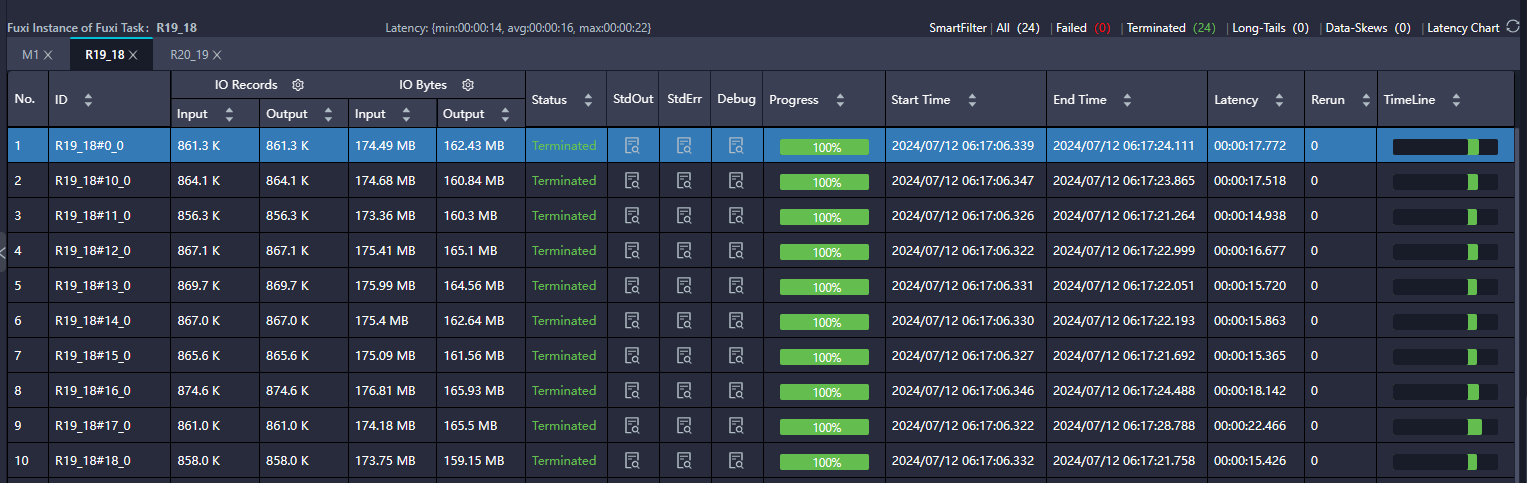
时间从 3 分钟下降到 16 秒,下降 90%,速度提高了 10 倍。另外,阿里云有一个资源占用指标:CoreMin(核数分钟数),CPU 占用由 47.51 下降到 38.90,降幅 18%;内存从 86.24 降到 66.58,降幅 23%。
四、小结
本文介绍了使用随机数填充字段值,规避数据倾斜的一个实战案例。使用CONCAT(ROUND(RAND(),8)*100000000)作为空值的填充值,保证数据在 Shuffle 阶段不发生倾斜,从而提高执行效率(注意:该填充值并不是唯一的,仅做一种参考)。
实战过程中可能会遇到不同的数据倾斜问题,需要根据实际的情况“对症下药”,另外,阿里云官方提供了一份数据倾斜调优文档,感兴趣的同学可以看看。

















 2246
2246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











