







文章目录
- 前言
- 一、东方财富人气top100
- 1.需求说明
- 2.数据爬取
- ①首页数据
- ② 实时趋势(排名)
- ③历史趋势(排名)
- 二、汉服荟小姐姐主页的视频爬取
- 1.需求说明
- 2. 数据爬取
- 总结
前言
最近时间排不过来(在和大佬学习研究JS),所以本次更新内容较为简单,有两个站进行讲解示例。文章写的不好,py写的也不好,请大佬们看到的飘过~见笑了见笑了。本项目仅用于交流学习,若侵犯到贵公司权益请联系邮箱229456906@qq.com第一时间删除。读者请切忌用于一切非法途径,否则后果自行承担!
项目一(东方财富人气top100):https://***/collect/stockranking/pages/ranking/list.html
项目二(汉服荟):https://www.hanfuhui.com/
一、东方财富人气top100
1.需求说明
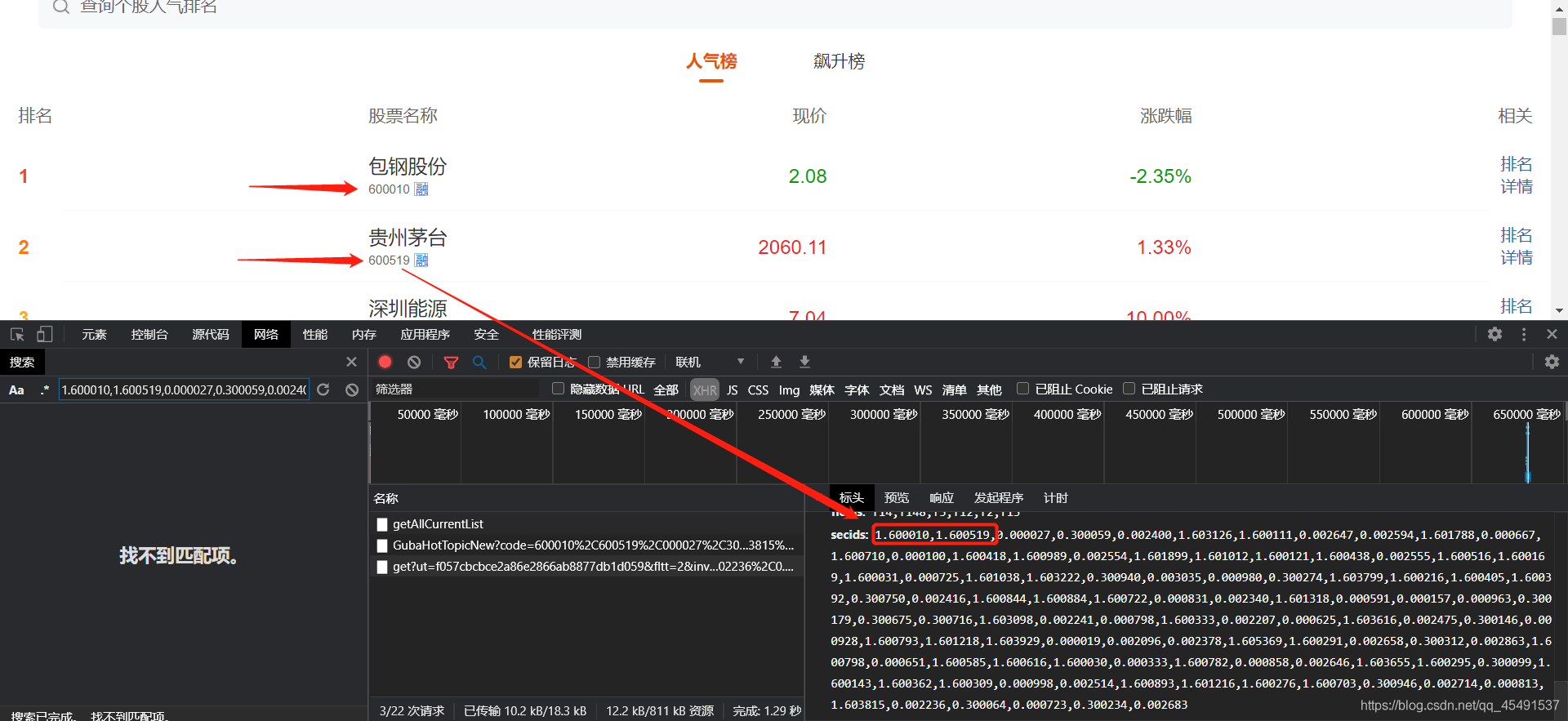
需要爬取的字段为排名、股票名称、现价、涨跌幅、排名详情。
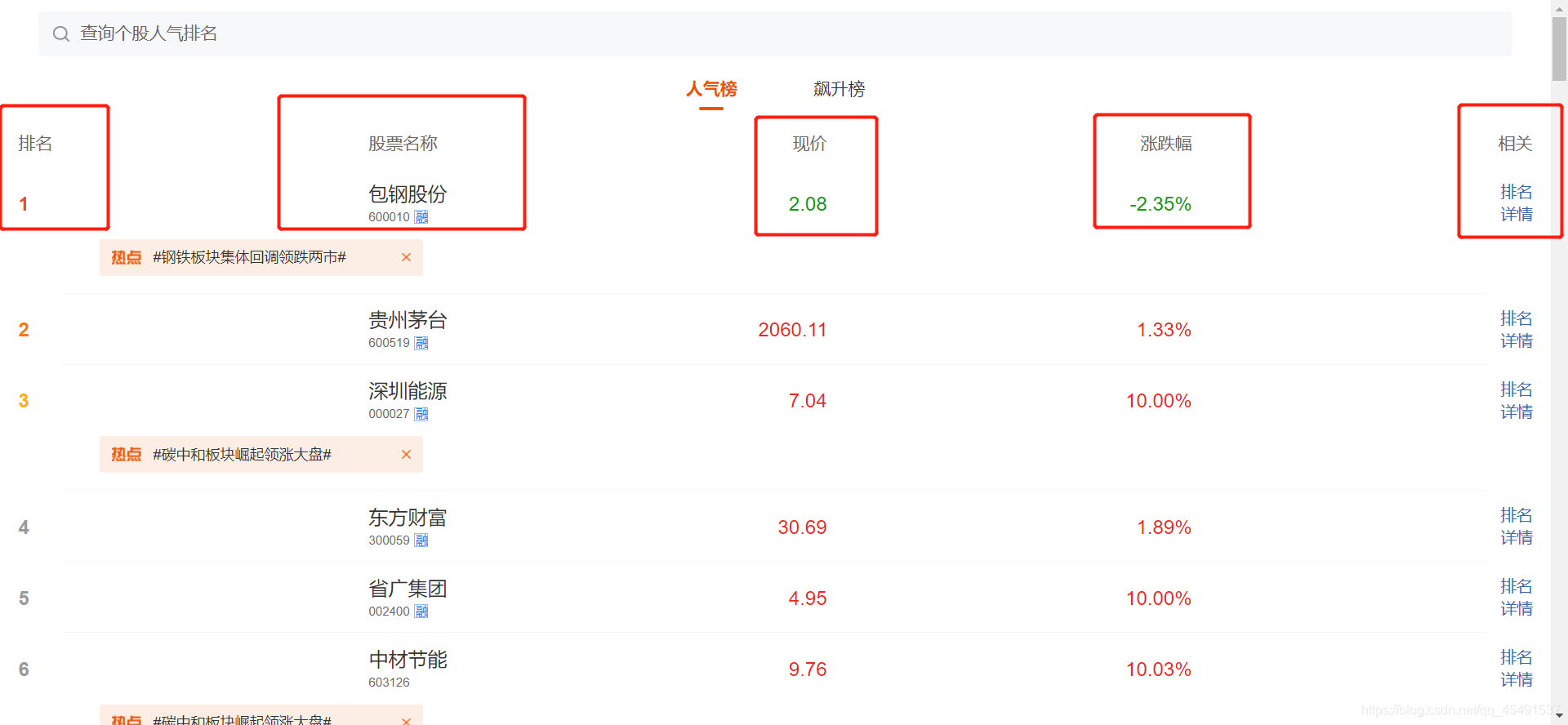
其中排名详情需要进入新的页面进行获取,并且需要实时排名以及历史排名两种数据:
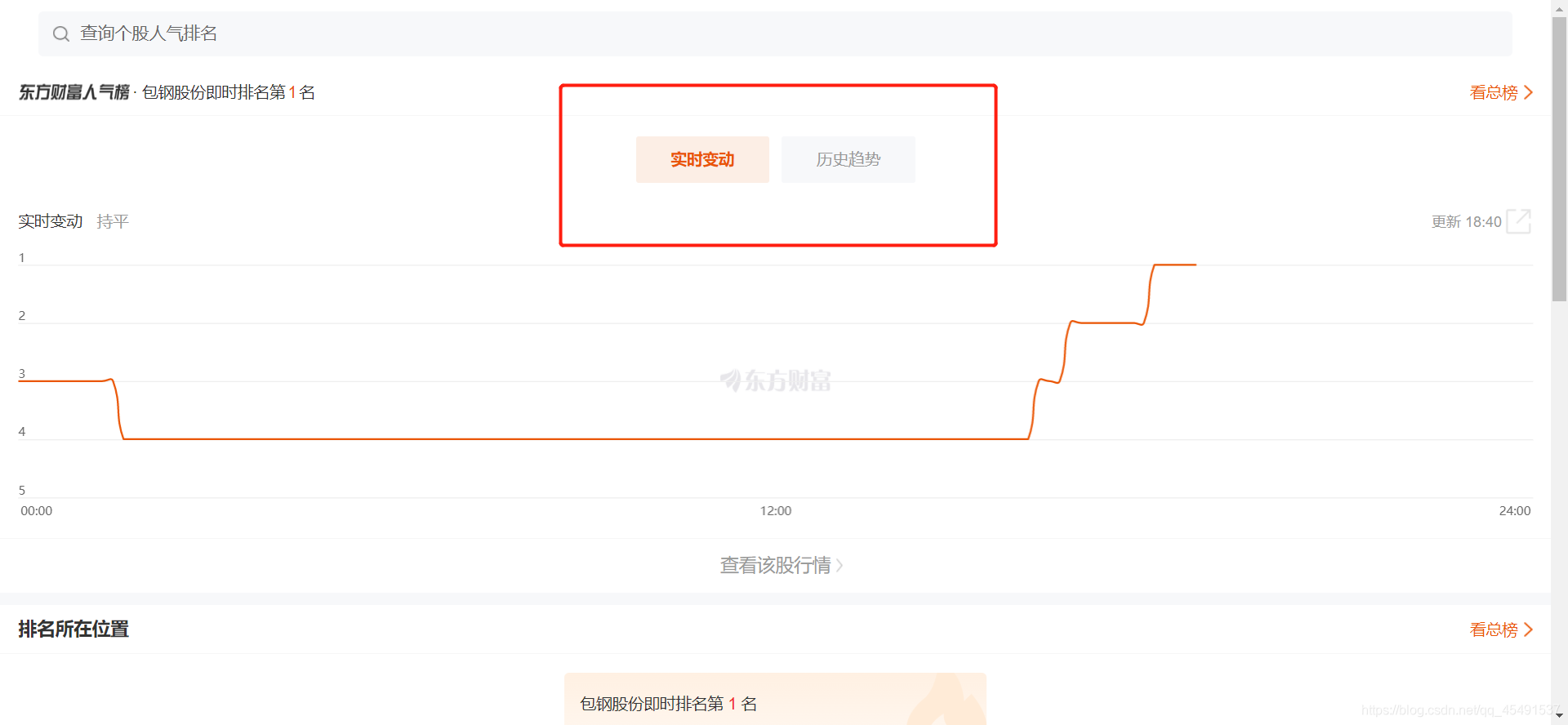
数据均在下面的动态条形图中(上图)。
2.数据爬取
①首页数据
先查看网页源代码中是否存在所需要的数据信息:
结果是无,所以接下来考虑是Ajax加载的数据,进行抓包:
总共三条接口地址,先看第一个的响应,看到响应内容并不是我们想要的,再看第二个。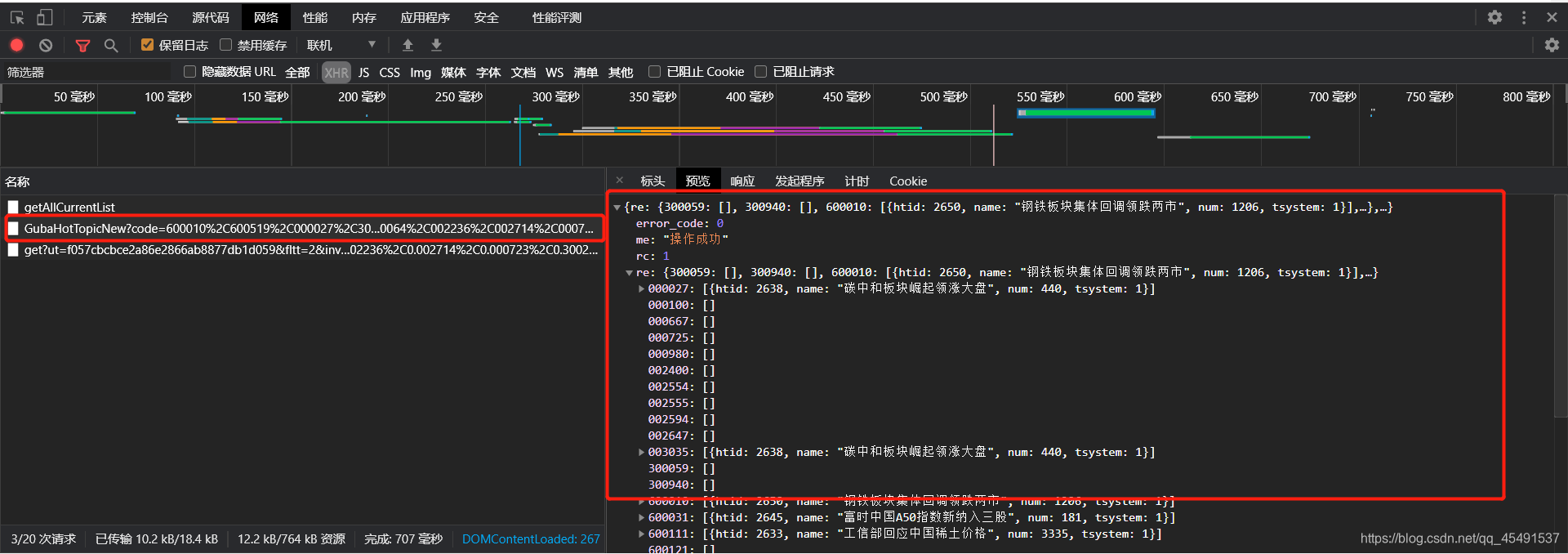
第二个也不是,那大概率就是第三条地址了
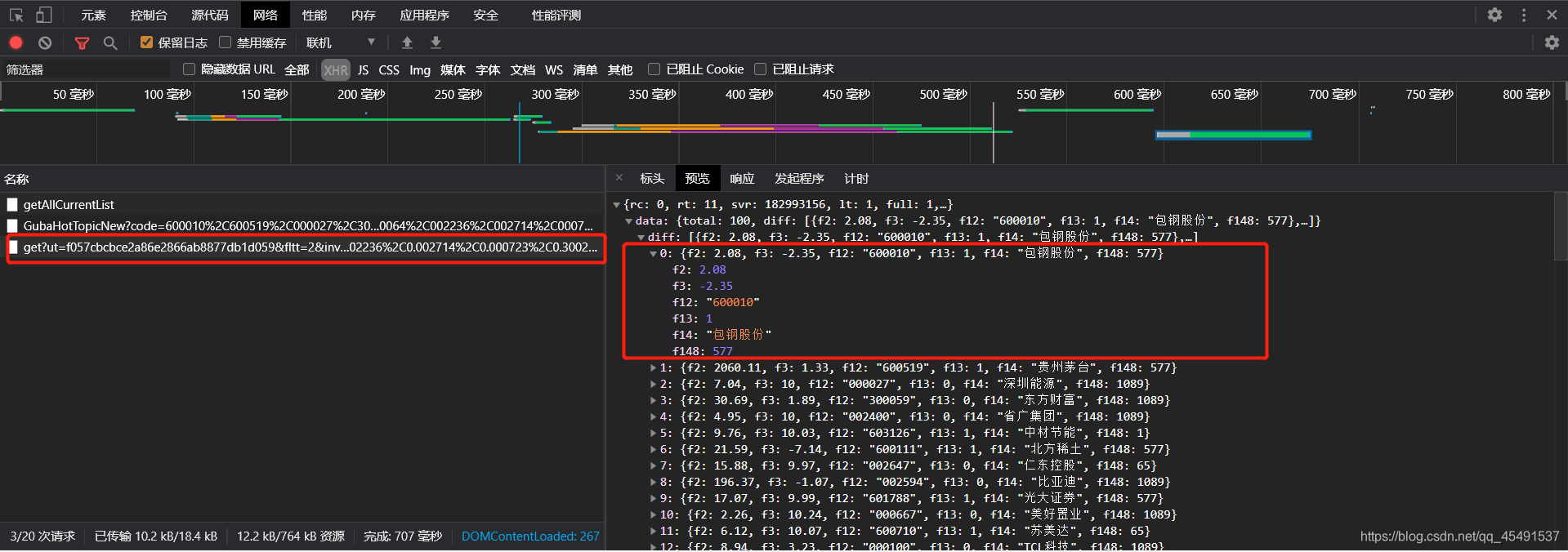
看看参数:
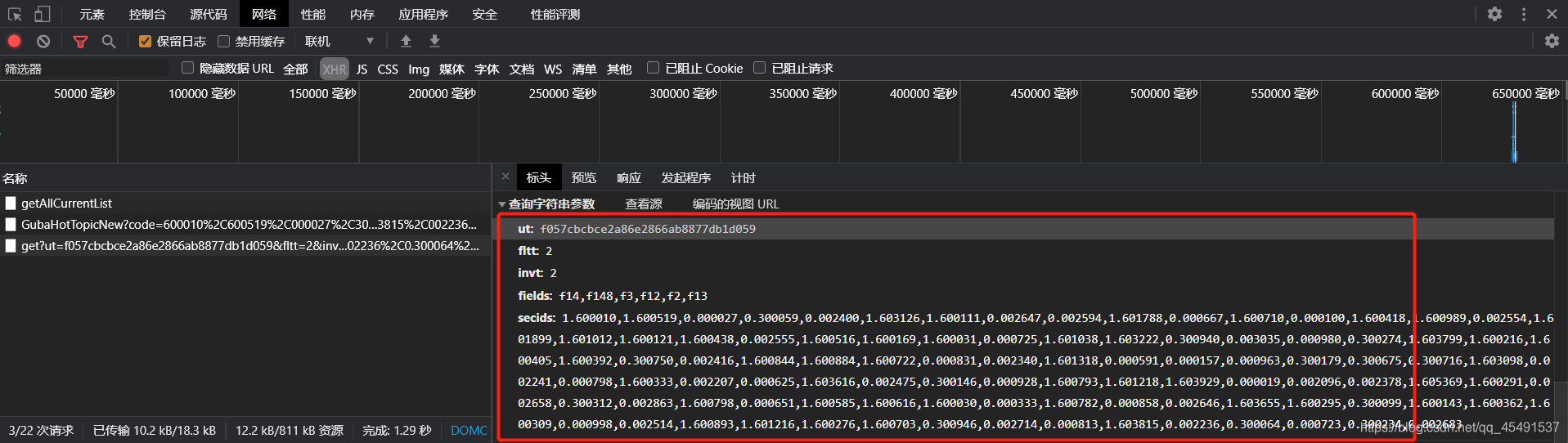
鹅…
就这里说一下,遇到参数先不要方,先看看是否为服务器返回的,如果服务器没有返回则再进行参数逆向。
so,先搜索一波ut的值
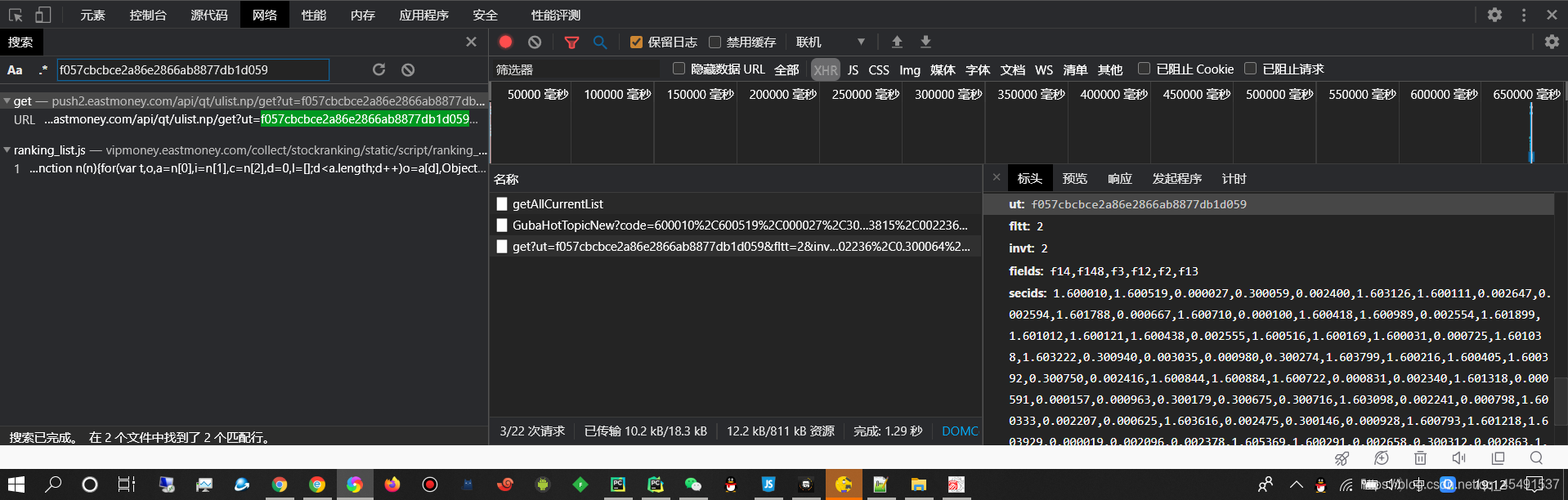
第一条不是,为什么?(他在url地址中所以不是),果断点击第二个
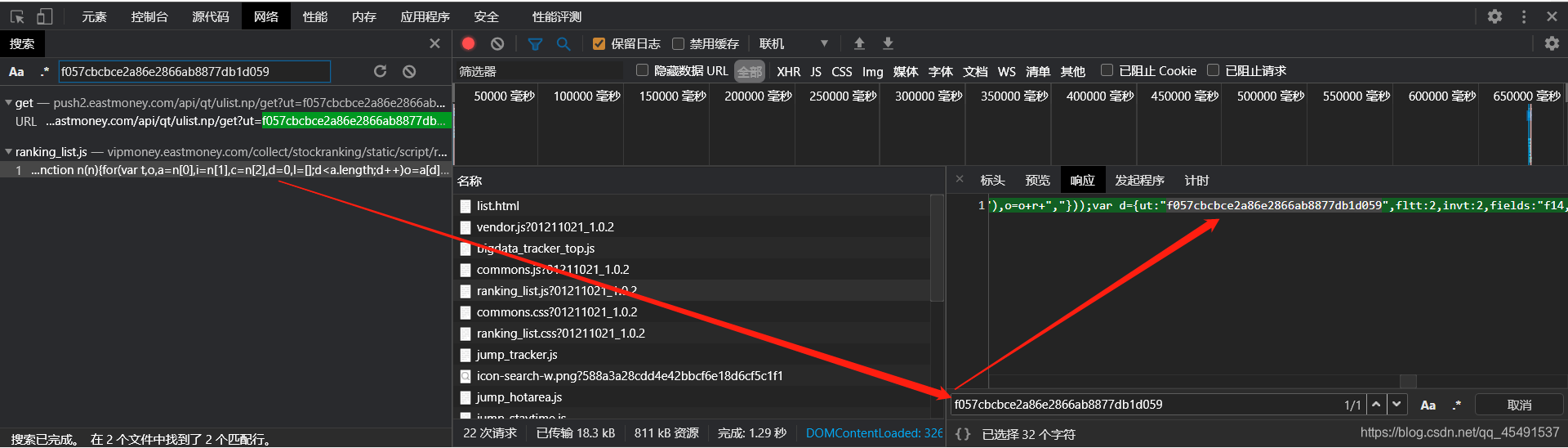
有了,再试着搜一下fields的值
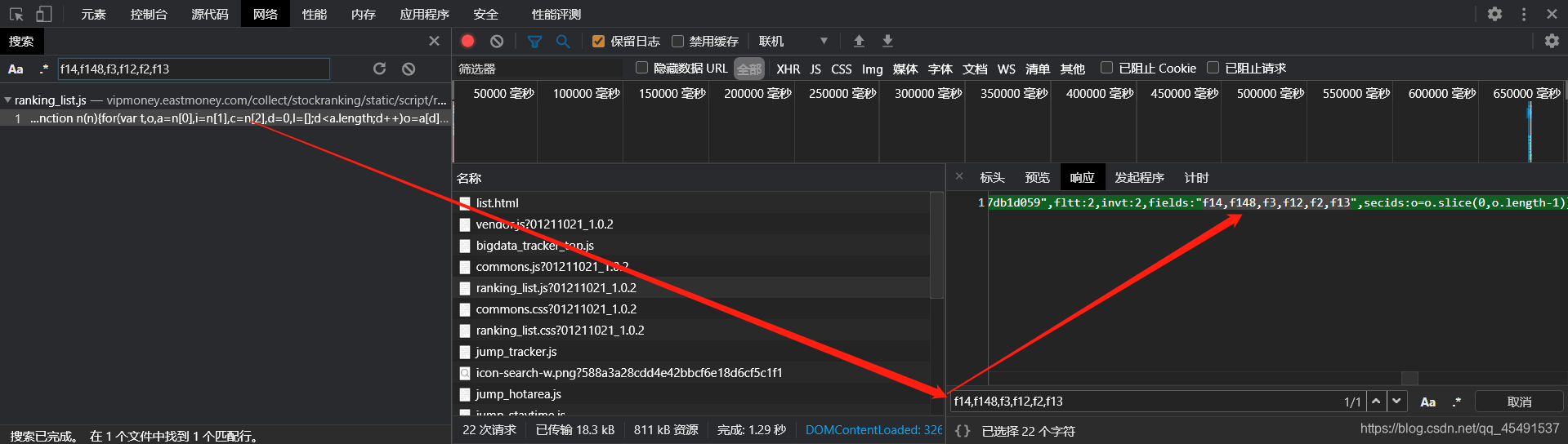
也有了,看看他的Headers也就是标头(我用的是360浏览器所以是标头)
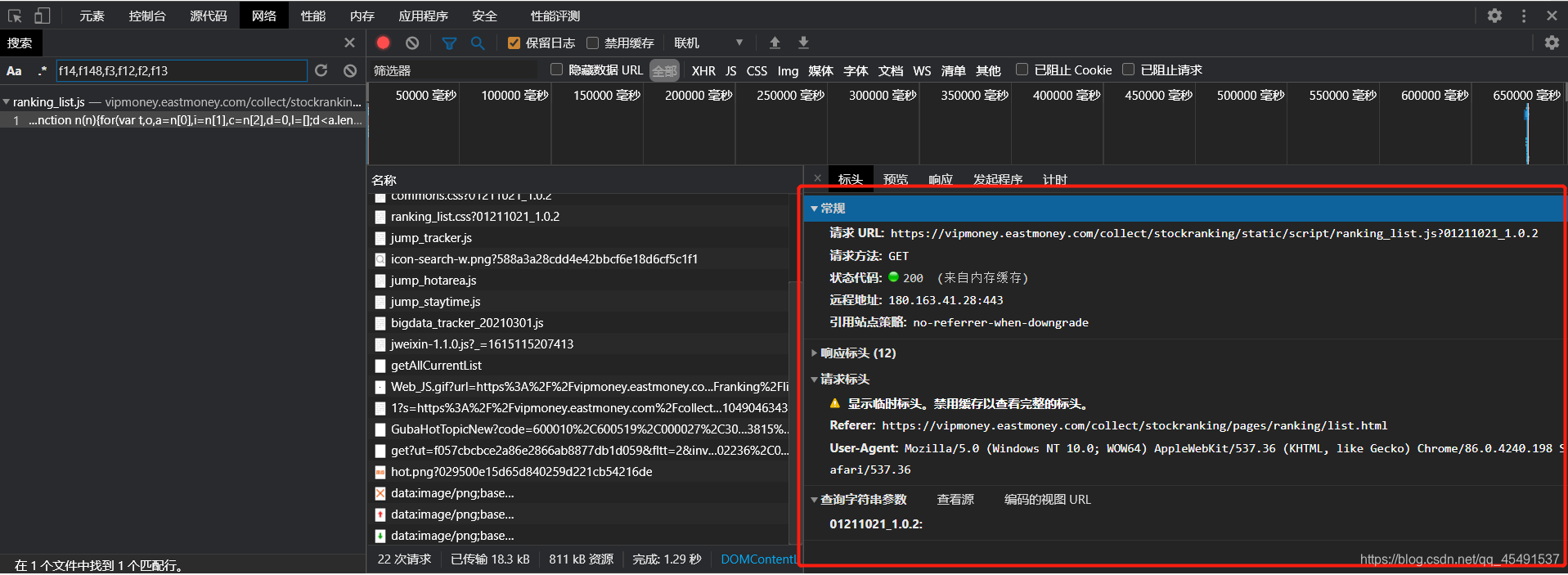
哦豁~GET请求,参数为空,用python模拟请求一下,使用re模块匹配出来ut和fields即可:
import requests
import re
headers = {
'Referer': 'https://vipmoney.eastmoney.com/collect/stockranking/pages/ranking/list.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
}
def getUtandeFields() ->dict:
ut_fields = {}
url = "https://vipmoney.eastmoney.com/collect/stockranking/static/script/ranking_list.js?01211021_1.0.2"
params = {
'01211021_1.0.2': ''
}
response = requests.get(url, headers=headers, params=params).text
ut_fields['ut'] = re.search(r'ut:"(.*?)"', response).group(1)
ut_fields['fields'] = re.search(r'fields:"(.*?)"', response).group(1)
return ut_fields
调用执行结果:

接下来是secids,搜索值发现没求得,所以另想其他办法
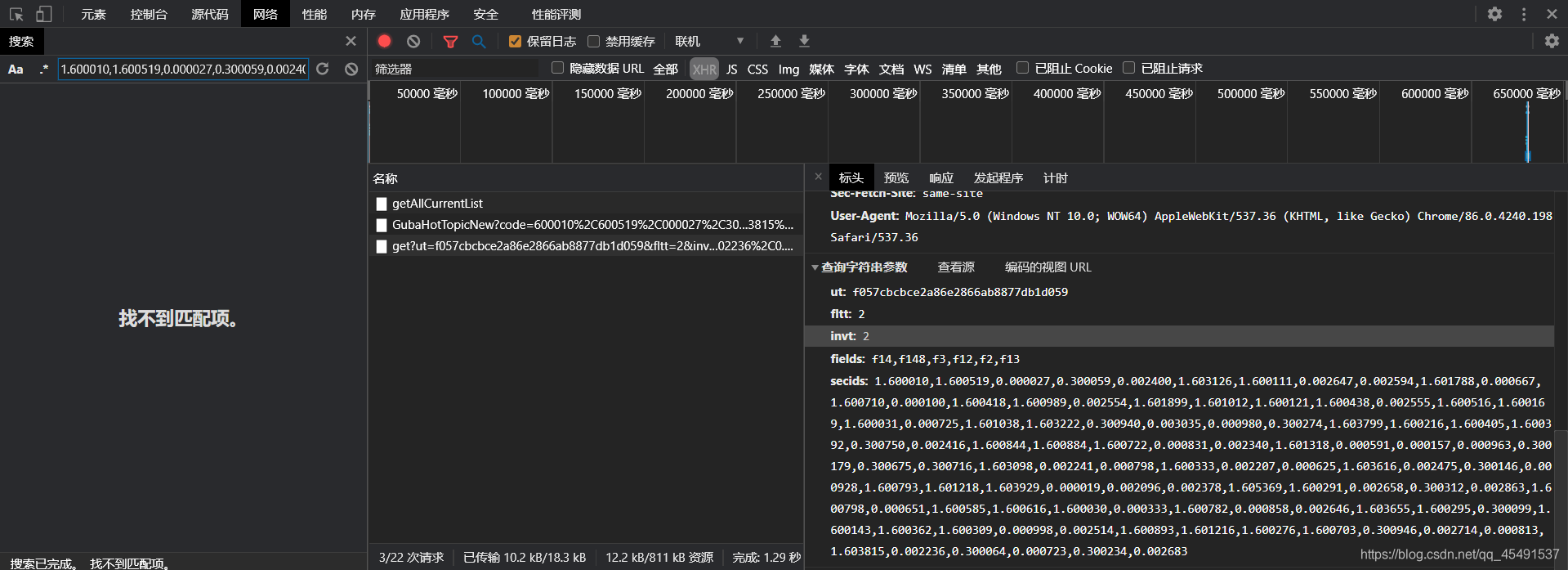
细心一点你就可以发现它像很多个 x. 加上很多个股票的代码xxxxxx
并且,细心的人他已经发现了上面第一条接口返回的数据里有股票代码
so,现在先搞定股票代码从哪里获取,并且 x. 中的 x 是啥玩意,有些童鞋已经在想js逆向了,不不不,要学废多观察
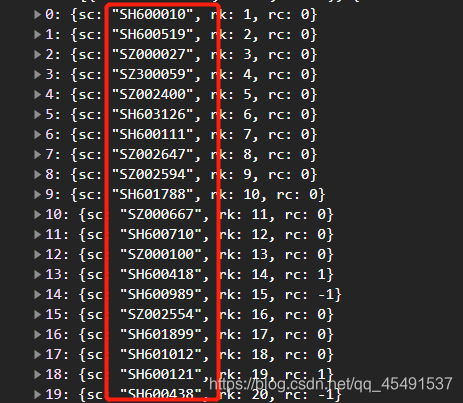
股票代码前面的字母字样SH SZ 并且全部的代码中之后这俩字样,而x. 中的 x不是1就是0,那SH会不会就 == 1,SZ==0 ?没错它就是这个亚子的(我说了多观察,不确定你就撸代码测试哈哈哈哈哈我就是这样做的)
所以我们只需要将第一个接口返回的数据稍作处理即可得到secids,先看看第一个接口的标头: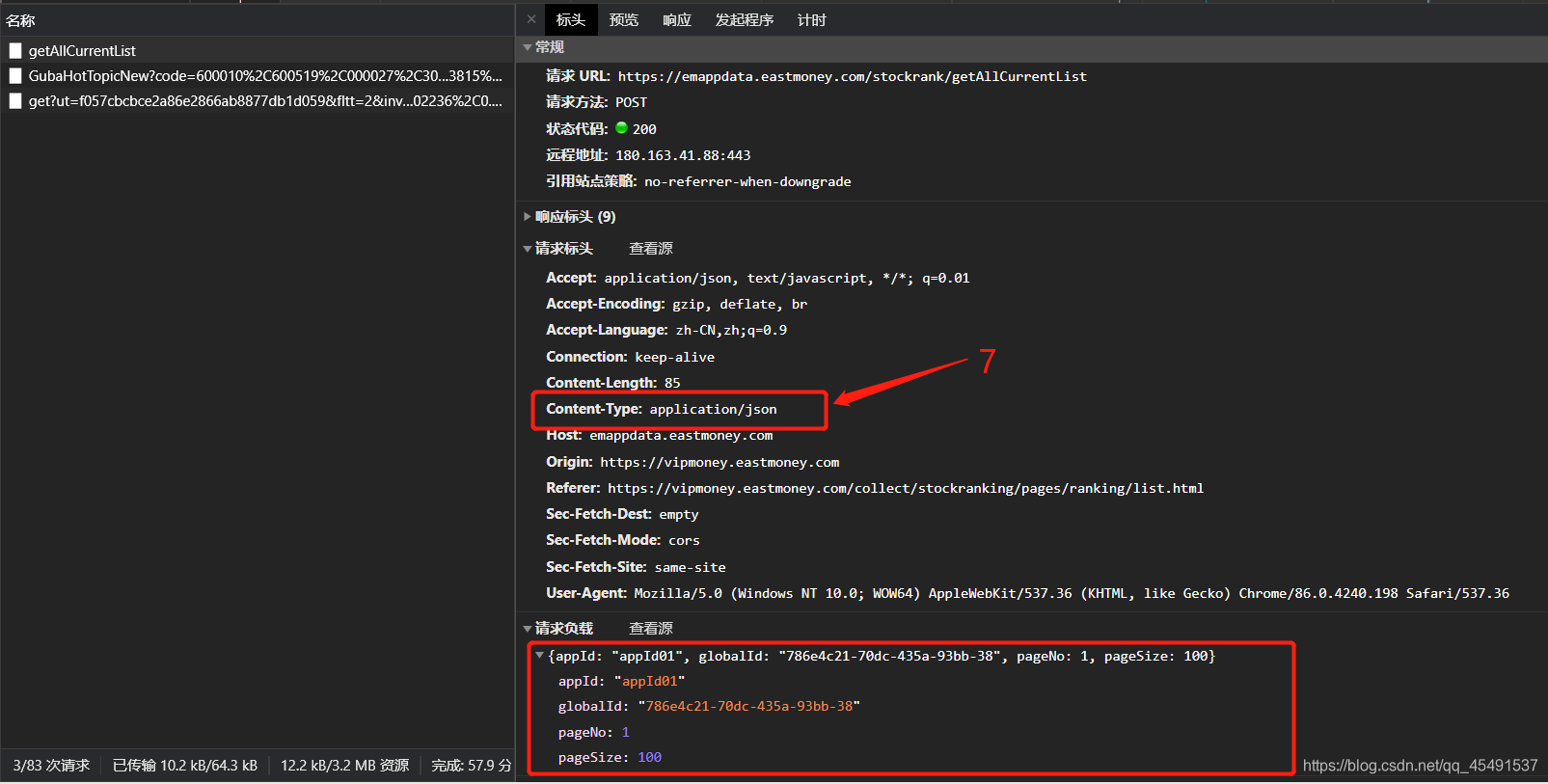
图中标注 7 的地方是一个小细节(Content-Type: application/json)也就是说当你看到Content-Type:application/json 时应该需要知道在提交post参数的时候将他转为json格式的数据,记好了记好了记好了哈
看看他需要提交的参数,其实这里的参数均为固定,所以你可以写死,但是不排除以后会变动,所以说一说globalId参数的获取,没错的,直接先搜索:
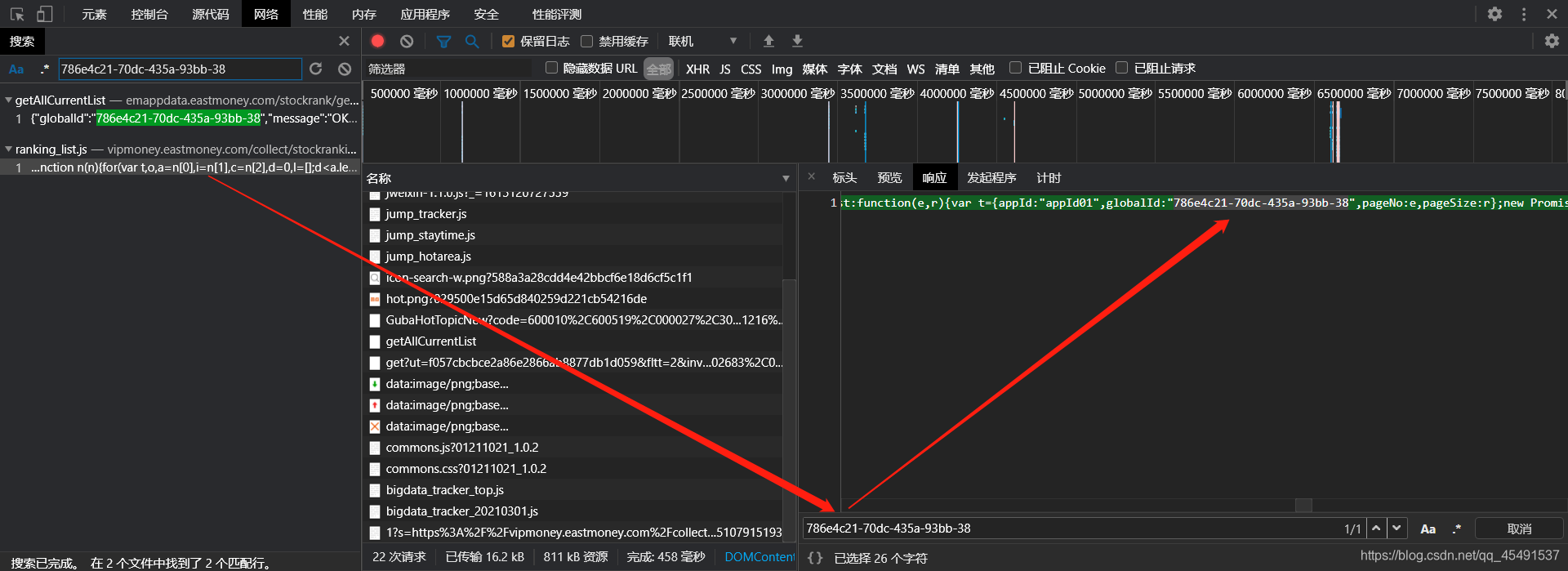
就是第一步获取ut的那个接口返回的,所以只需要在第一步获取ut的代码中添加一行代码即可:
ut_fields['globalId'] = re.search(r'globalId:"(.*?)"', response).group(1)
调用运行结果:

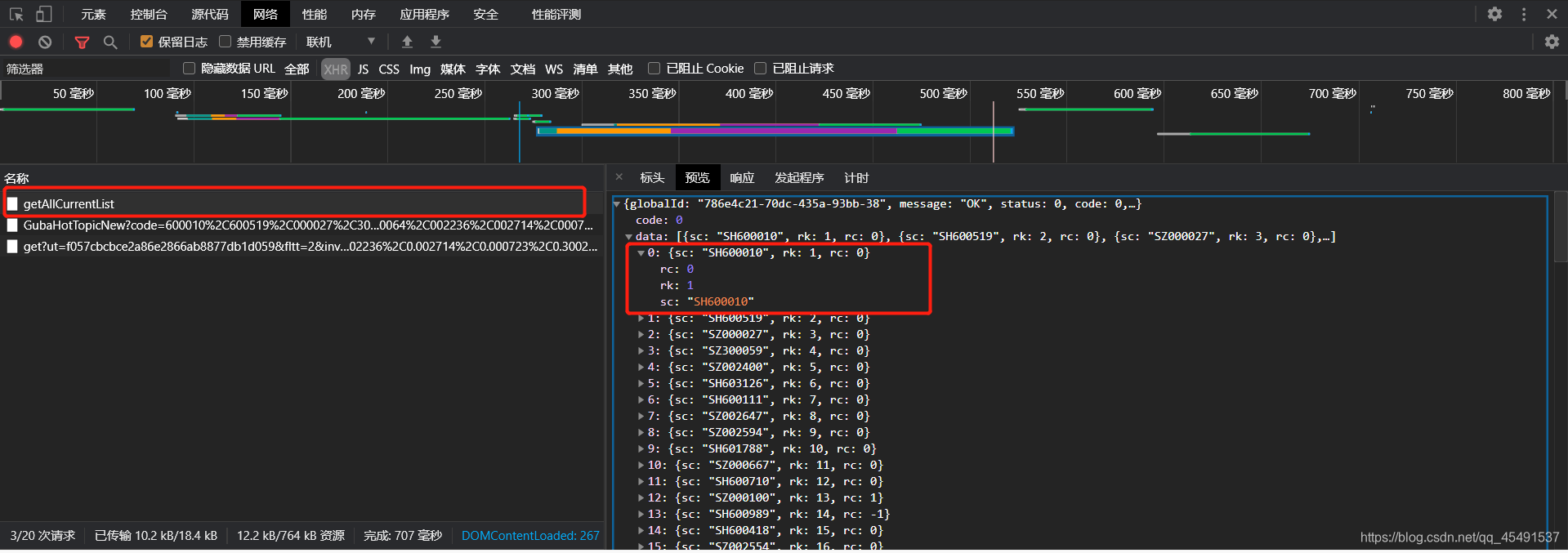
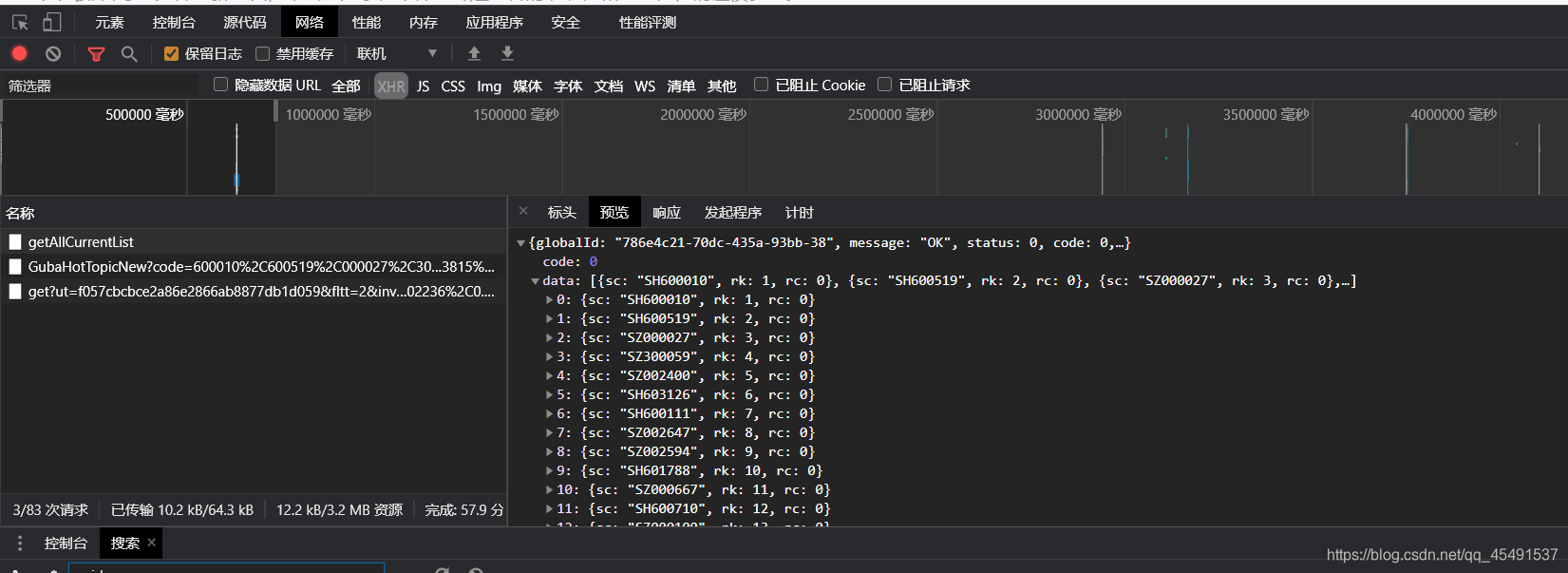
接下来编写getSecids方法获取secids参数:
def getSecids(ut_fields: dict) ->str:
url = "https://emappdata.eastmoney.com/stockrank/getAllCurrentList"
headers['Host'] = "emappdata.eastmoney.com"
headers['Origin'] = "https://vipmoney.eastmoney.com"
data = {
'appId': 'appId01',
'globalId': ut_fields['globalId'],
'pageNo': '1',
'pageSize': '100',
}
response = requests.post(url, json=data, headers=headers).text
jsData = json.loads(response)['data']
secids = ""
gb = 0
for item in jsData:
gb += 1
sc = item['sc']
if "SH" in sc:
secids += sc.replace("SH", "1.") + ","
if gb == len(jsData):
secids += sc.replace("SH", "1.")
else:
secids += sc.replace("SZ", "0.") + ","
if gb == len(jsData):
secids += sc.replace("SZ", "0.")
return secids
调用执行结果:

要得咯,所有参数准备就绪,编写getData方法获取数据并保存至本地
先看看将参数提交后是否有数据:
def getData(ut_fields, secids):
url = "https://push2.eastmoney.com/api/qt/ulist.np/get?"
headers['Host'] = "push2.eastmoney.com"
data = {
'ut': ut_fields['ut'],
'fltt': '2',
'invt': '2',
'fields': ut_fields['fields'],
'secids': secids,
}
response = requests.post(url, data=data, headers=headers).text
print(response)
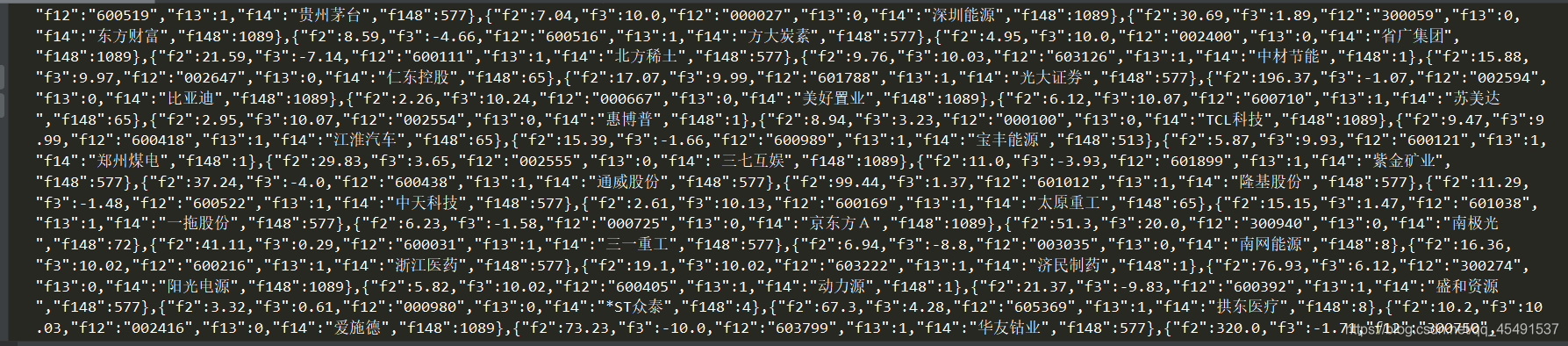
有数据,没问题,接下来继续接着getData函数编写代码清洗数据并保存:
jsData = json.loads(response)['data']['diff']
savepath = os.getcwd() + r'\data'
if not os.path.exists(savepath):
os.mkdir(savepath)
fp = open(savepath + r'\ulist.csv', 'w', encoding='utf-8', newline='')
fw = csv.writer(fp)
fw.writerow(['排名', '股票名称', '股票代码', '现价', '涨跌幅'])
i = 0
for item in jsData:
i += 1
paiming = i # 排名
name = item['f14'] # 股票名称
xianjia = item['f2'] # 现价
daima = item['f12'] # 股票代码
zdf = item['f3'] # 涨跌幅
content = [paiming, name, daima, xianjia, zdf]
print(content)
fw.writerow(content)
最终结果:
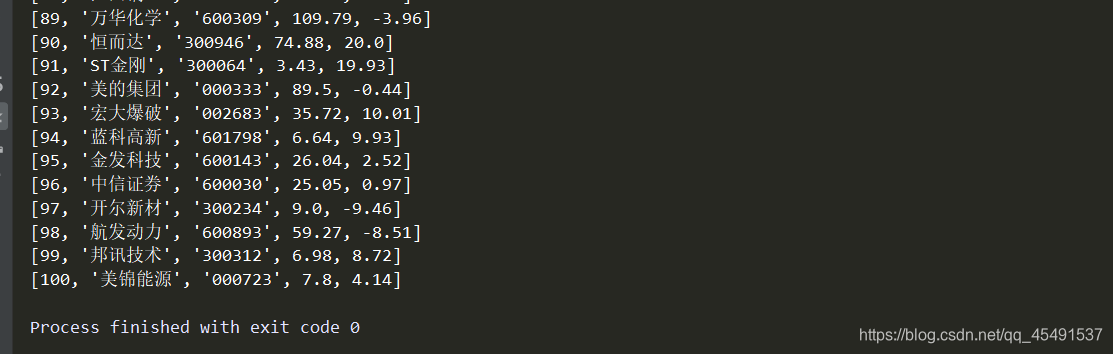
保存的csv文件:
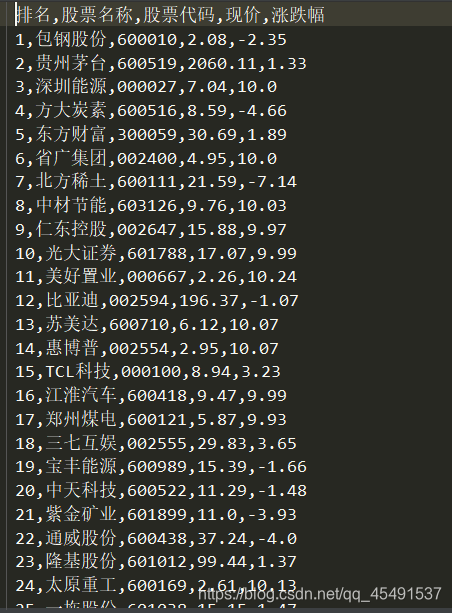
② 实时趋势(排名)
实时排名抓包接口如图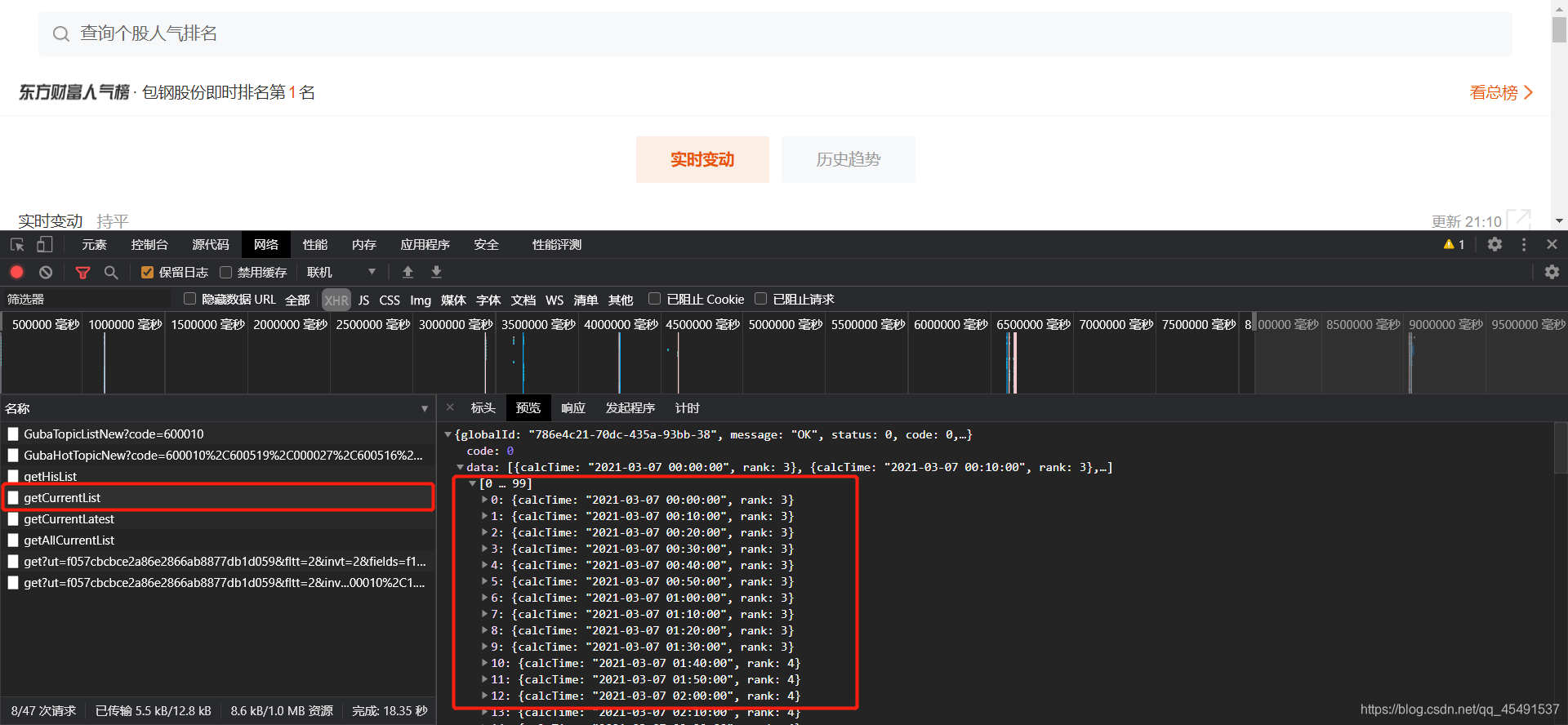
看看标头:

请自行注意蓝色位置~~
然后除了srcSecurityCode参数之外其他的签名已经获取到了,srcSecurityCode就是getSecids方法里我们请求网页可以获取到的,这里也可以在getData方法中稍做处理即可得到:
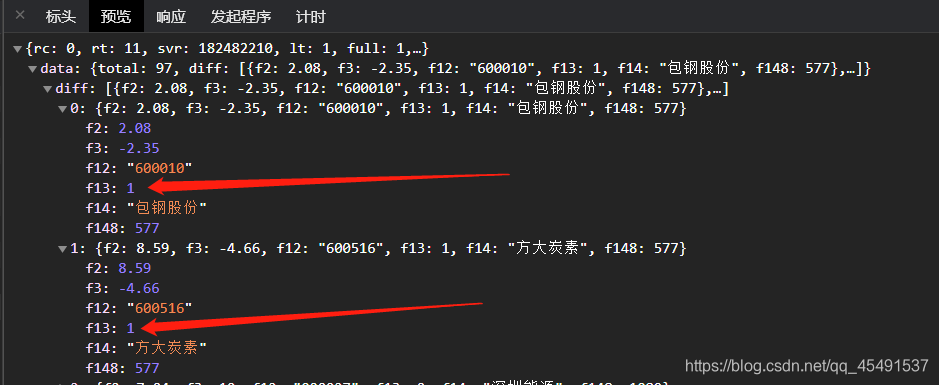
注意这里的f13, 前面我们已经的到对应关系 SH == 1 和 SZ == 0 ,f13的值就是1或0, 所以我们做一个映射关系即可,将getData进行改写:
def getData(ut_fields, secids) ->dict:
url = "https://push2.eastmoney.com/api/qt/ulist.np/get?"
headers['Host'] = "push2.eastmoney.com"
data = {
'ut': ut_fields['ut'],
'fltt': '2',
'invt': '2',
'fields': ut_fields['fields'],
'secids': secids,
}
response = requests.post(url, data=data, headers=headers).text
jsData = json.loads(response)['data']['diff']
savepath = os.getcwd() + r'\data'
if not os.path.exists(savepath):
os.mkdir(savepath)
fp = open(savepath + r'\ulist.csv', 'w', encoding='utf-8', newline='')
fw = csv.writer(fp)
fw.writerow(['排名', '股票名称', '股票代码', '现价', '涨跌幅'])
i = 0
srcSecurityCode_dict = {}
for item in jsData:
i += 1
paiming = i # 排名
name = item['f14'] # 股票名称
xianjia = item['f2'] # 现价
daima = item['f12'] # 股票代码
zdf = item['f3'] # 涨跌幅
content = [paiming, name, daima, xianjia, zdf]
print(content)
fw.writerow(content)
f13 = int(item['f13'])
if f13 == 1:
srcSecurityCode_dict[name] = "SH" + str(daima)
else:
srcSecurityCode_dict[name] = "SZ" + str(daima)
return srcSecurityCode_dict
结果:
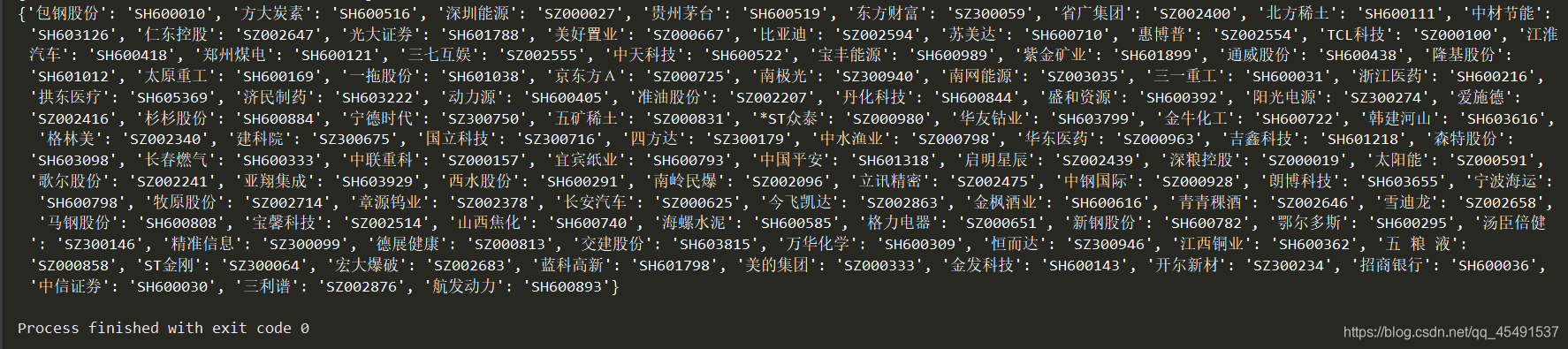
接下来编写getCurrentList方法获取每个股票的实时排名数据:
def getCurrentList(srcSecurityCode_dict, ut_fields):
savepath = os.getcwd() + r'\CurrentListData'
if not os.path.exists(savepath):
os.mkdir(savepath)
url = "https://emappdata.eastmoney.com/stockrank/getCurrentList"
headers['Host'] = 'emappdata.eastmoney.com'
data = {
'appId': 'appId01',
'globalId': ut_fields['globalId'],
'srcSecurityCode': '',
}
for name, srcSecurityCode in srcSecurityCode_dict.items():
if '*' in name:
name = name.replace('*', '')
else:
name = name
fp = open(savepath + r'\【{}】实时排名.csv'.format(name), 'w', encoding='utf-8', newline='')
fw = csv.writer(fp)
fw.writerow(['股票名称', '股票代码', '时间点', '排名'])
data['srcSecurityCode'] = srcSecurityCode
response = requests.post(url, json=data, headers=headers).text
jsData = json.loads(response)['data']
print(jsData)
saveCurrentList(jsData, name, srcSecurityCode, fw)
编写saveCurrentList方法保存数据:
def saveCurrentList(jsData, name, srcSecurityCode, fw):
for item in jsData:
fw.writerow([name, srcSecurityCode, str(item['calcTime']), str(item['rank'])])
结果:
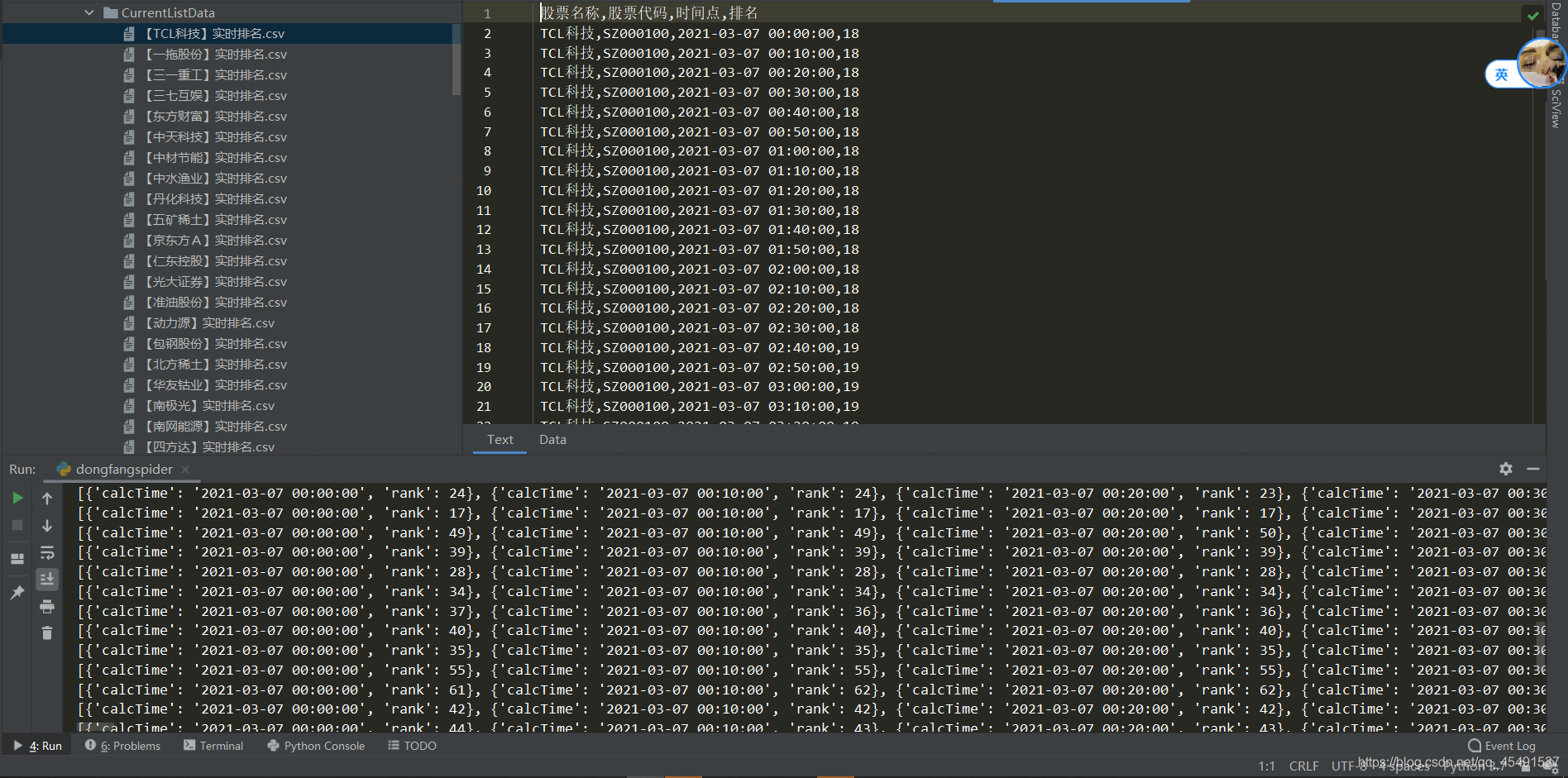
③历史趋势(排名)
抓包如下如:
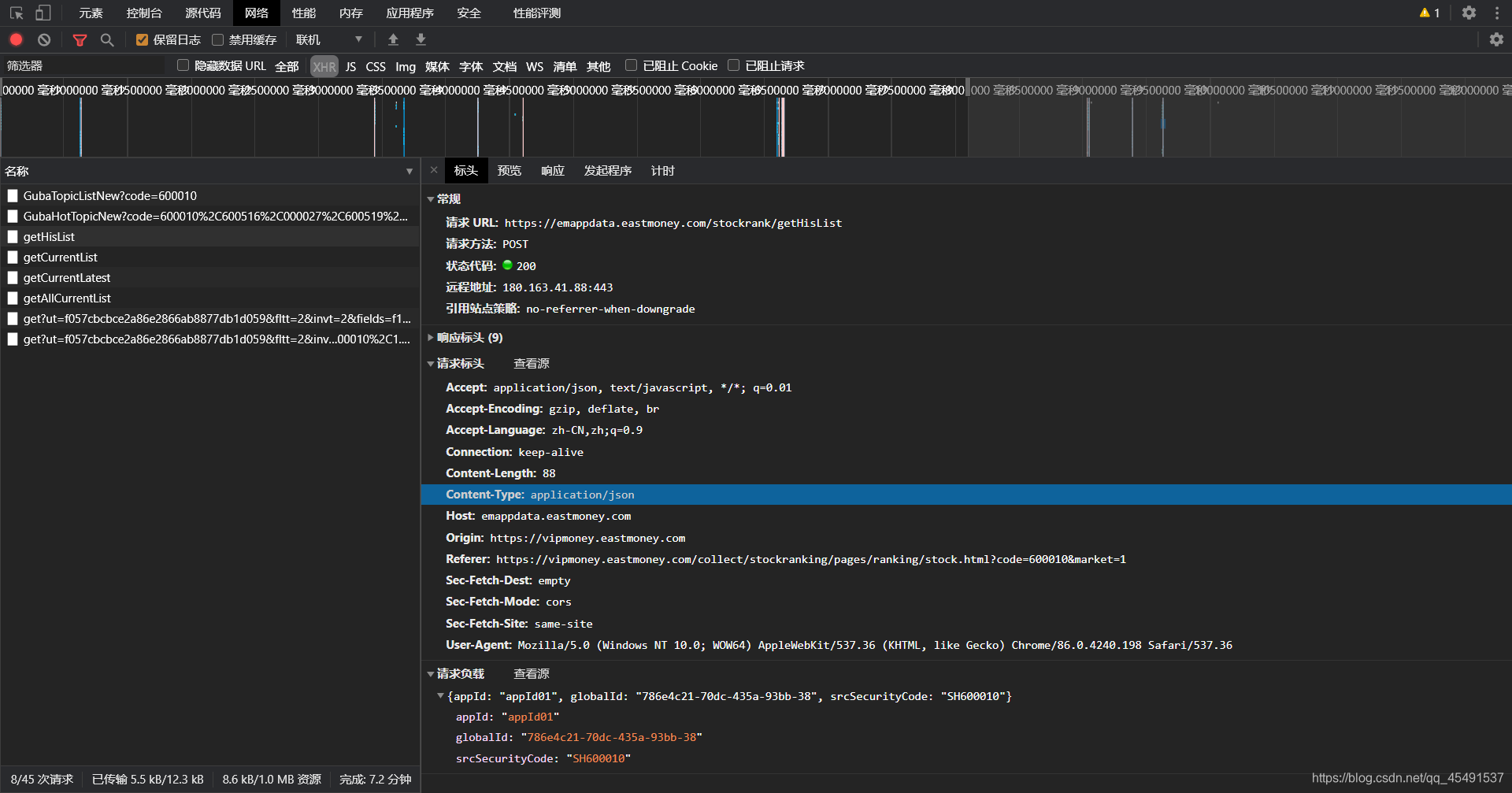
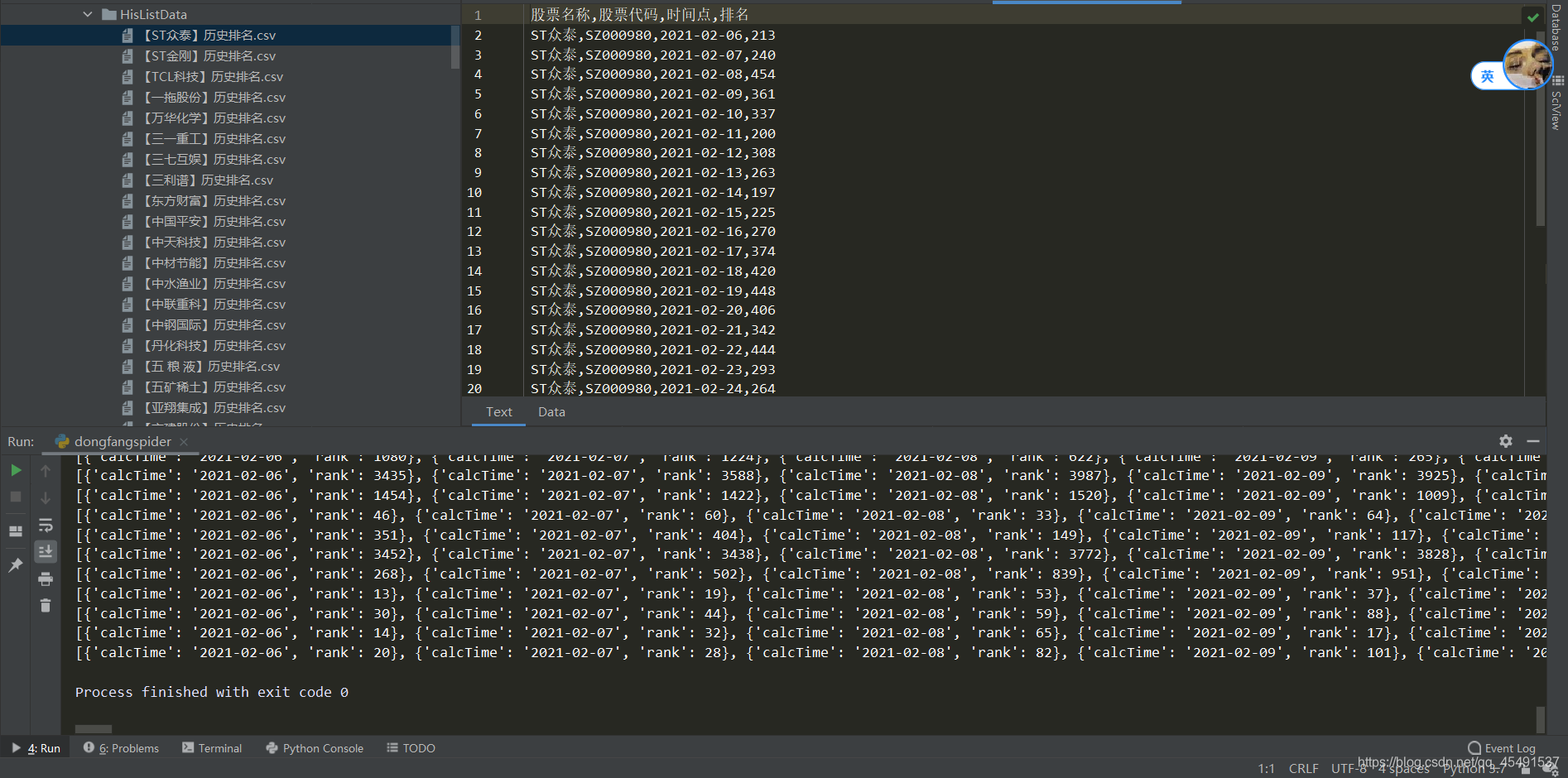
所有参数都有,并且数据返回的格式与实时趋势数据大同小异,编写getHisList方法来获取每个股票的历史趋势(排名)数据即可(这里我就不写了下面还有一个站点,赶时间鸭)贴一下历史趋势最终结果。
二、汉服荟小姐姐主页的视频爬取
1.需求说明
本次爬取为汉服荟首页-视频板块-获取视频板块页面所有视频数据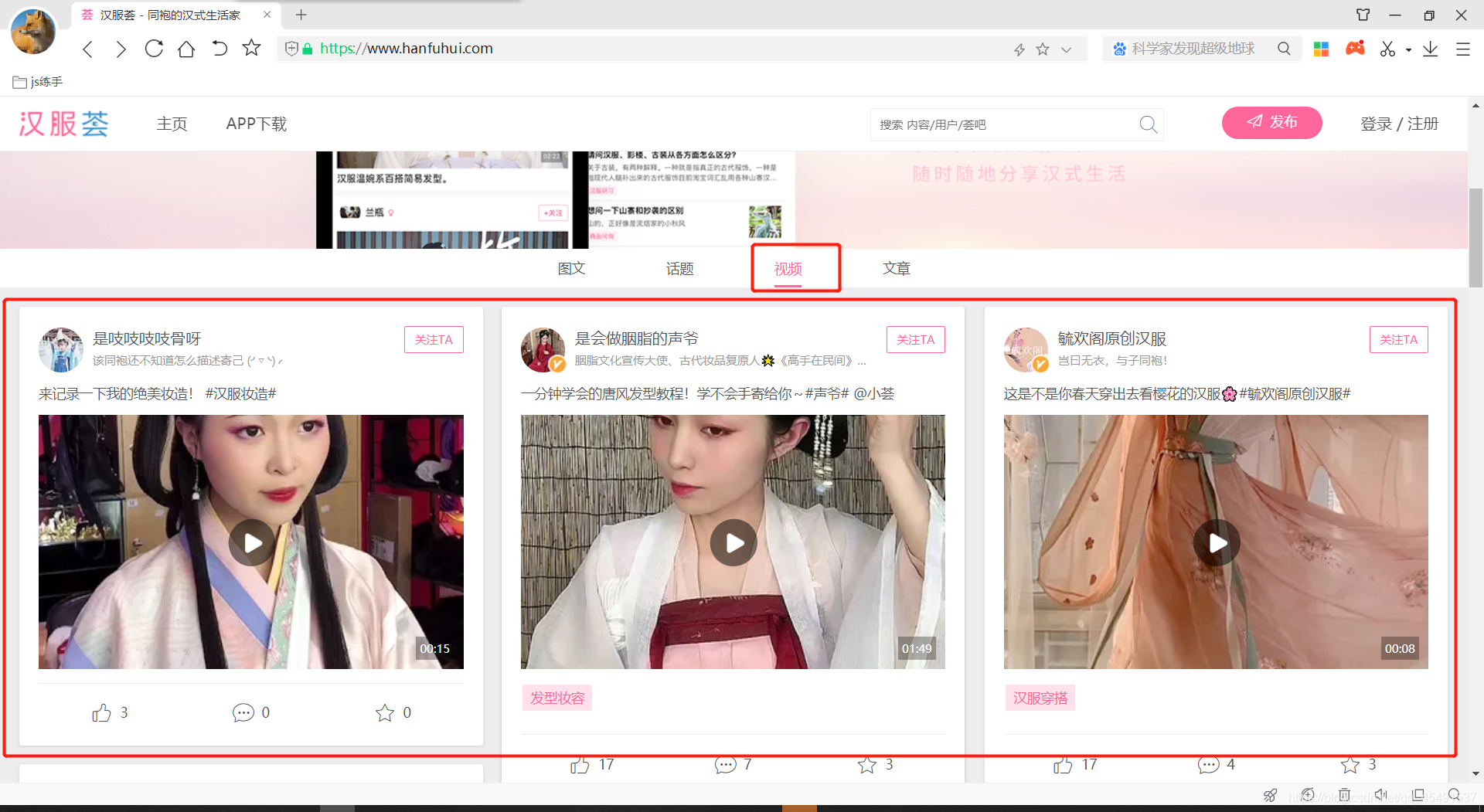
2. 数据爬取
选择视频板块后,随便点击一条视频进入详情页
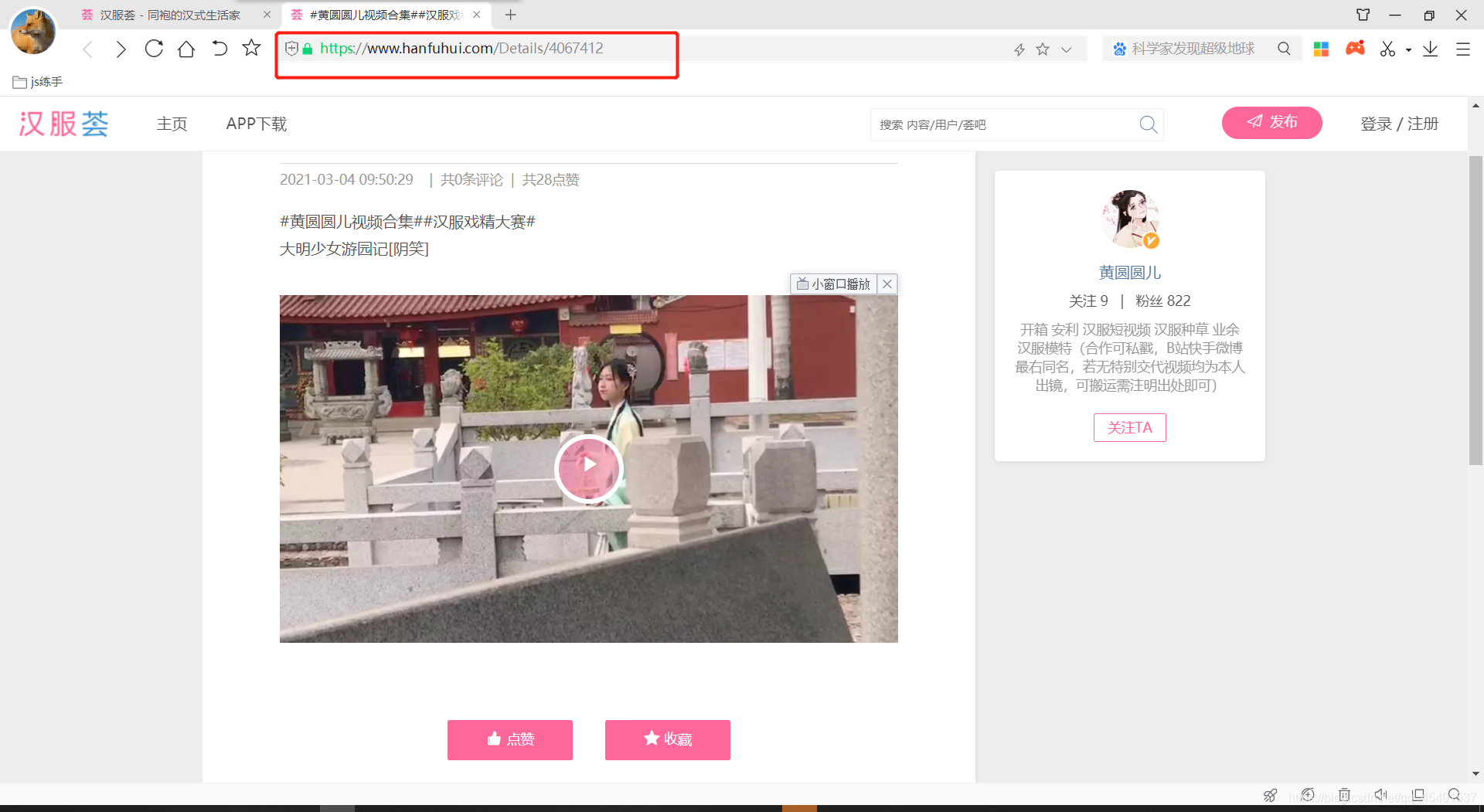
可以看到链接地址为:https://www.hanfuhui.com/Details/4067412
当我再点击其他一条进入详情页观察:
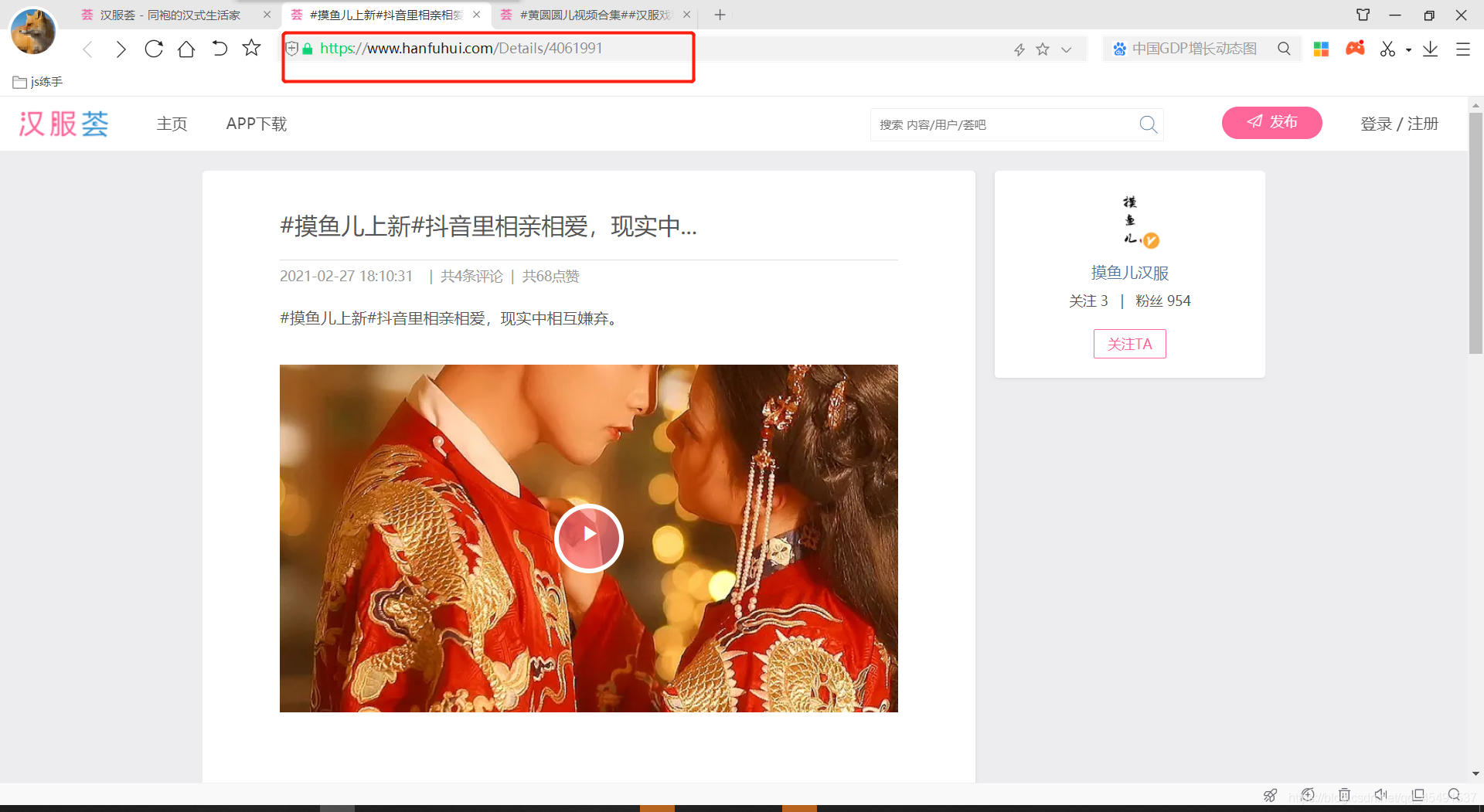
链接地址为:https://www.hanfuhui.com/Details/4061991
也就是说每个视频的地址均为https://www.hanfuhui.com/Details/加上一串数字,这串数字从哪里来?
现在反悔视频首页,往下拉滚动条进行抓包:
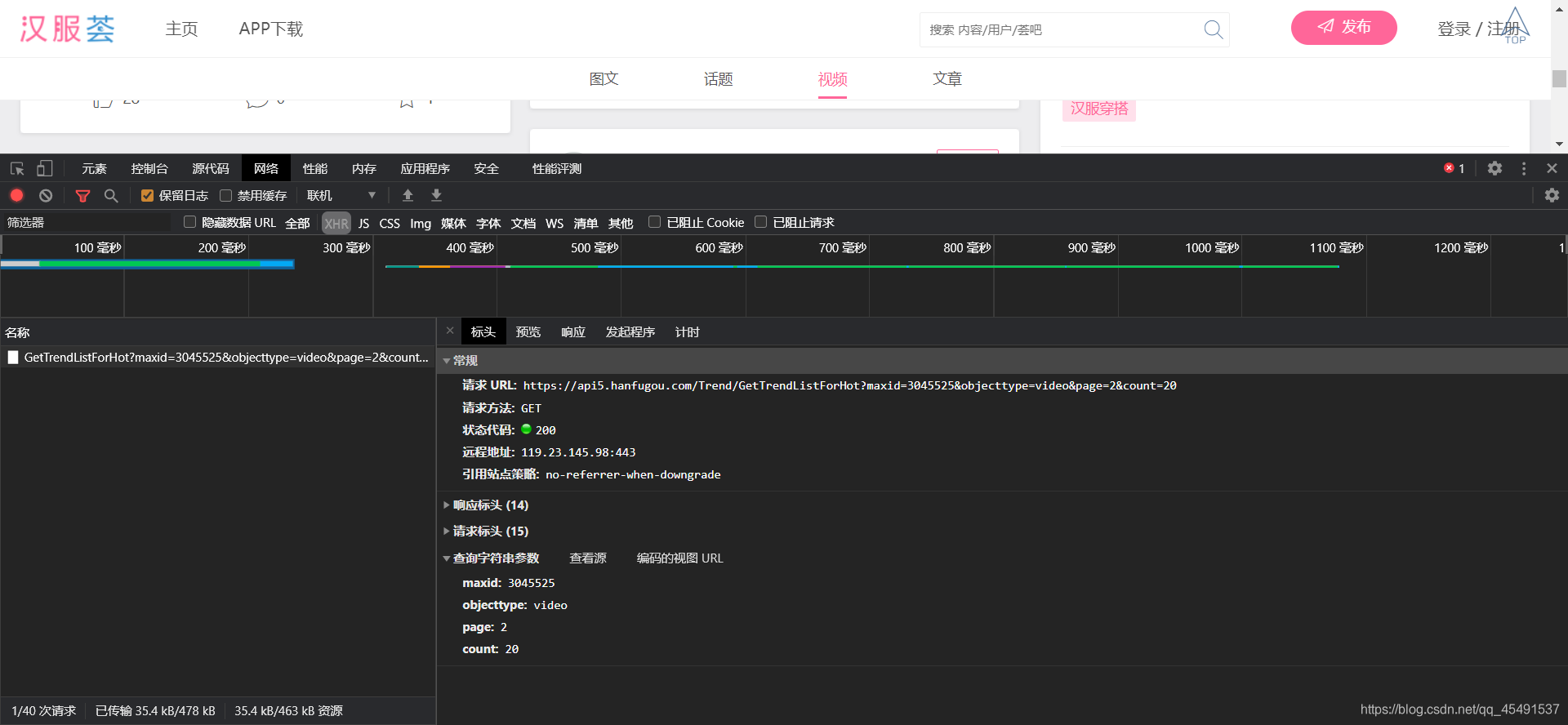
当触发翻页以后,出现这条接口地址,看看他的响应数据:
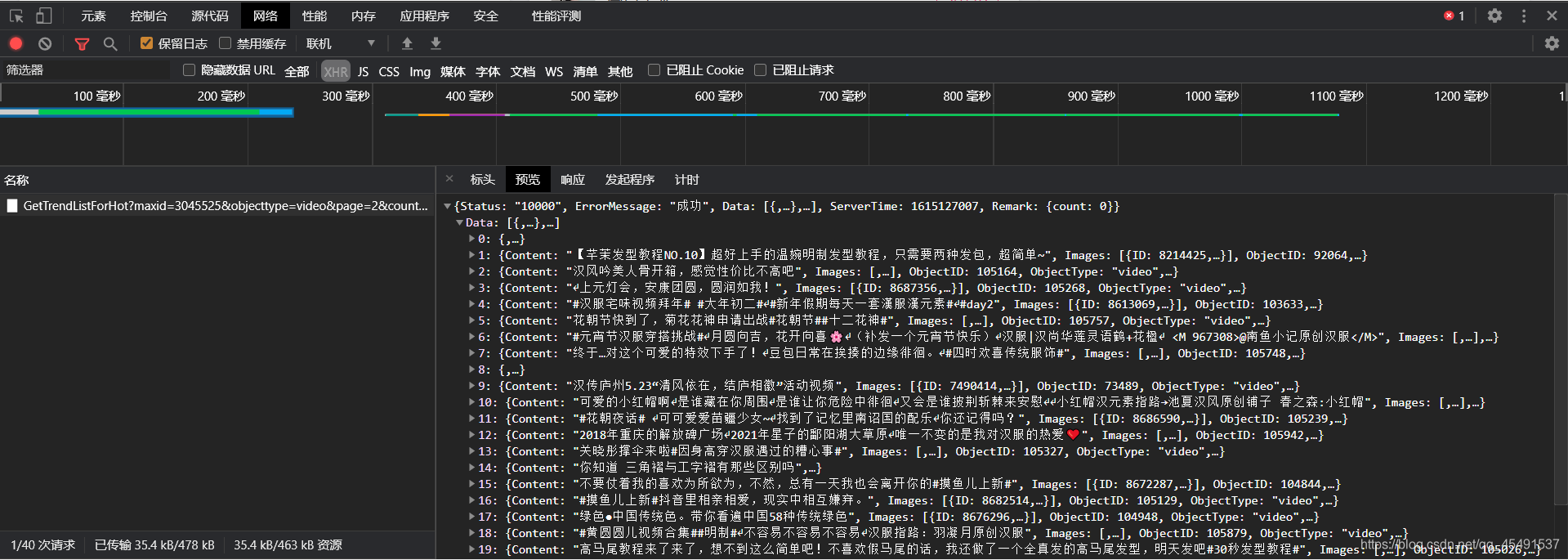
展开其中一条json:
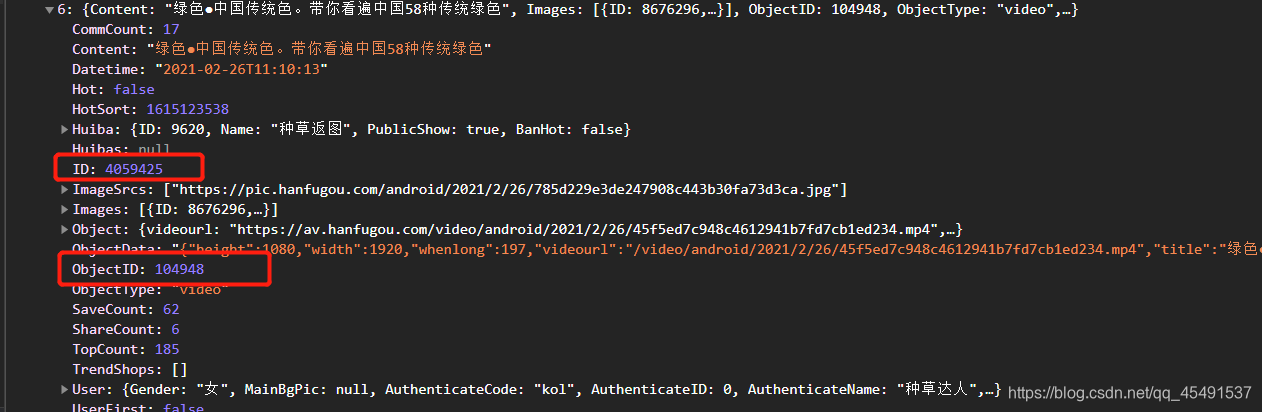
有两个可疑值,将他们与https://www.hanfuhui.com/Details/进行组合并访问看看:
ObjectID:
并没有视频信息,接下来使用ID组合访问:
有了,所以这里的ID就是我们需要的字段,编写get_IDList函数获取ID列表并组合成视频详情页地址:
def get_IDList():
url = 'https://api5.hanfugou.com/Trend/GetTrendListForHot?'
headers = {
'origin': 'https://www.hanfuhui.com',
'referer': 'https://www.hanfuhui.com/',
'sec-ch-ua': '"Google Chrome";v="87", " Not;A Brand";v="99", "Chromium";v="87"',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
}
data = {
'maxid': '0',
'objecttype': 'video',
'page': '1',
'count': '20',
}
i = 0
for page in range(1, 10000000):
if page != 1:
data['maxid'] = str(3045525)
data['page'] = page
response = requests.get(url, params=data, headers=headers).text
jsData = json.loads(response)['Data']
if len(jsData) == 0:
break
for item in jsData:
i += 1
id = item['ID']
indexUrl = 'https://www.hanfuhui.com/Details/' + str(id)
print(indexUrl)
执行结果:
接下来分析视频详情页:
当你想右键进行查看元素的时候会发现点不动
这里使用另一种方法,F12打开开发者工具,操作如图:
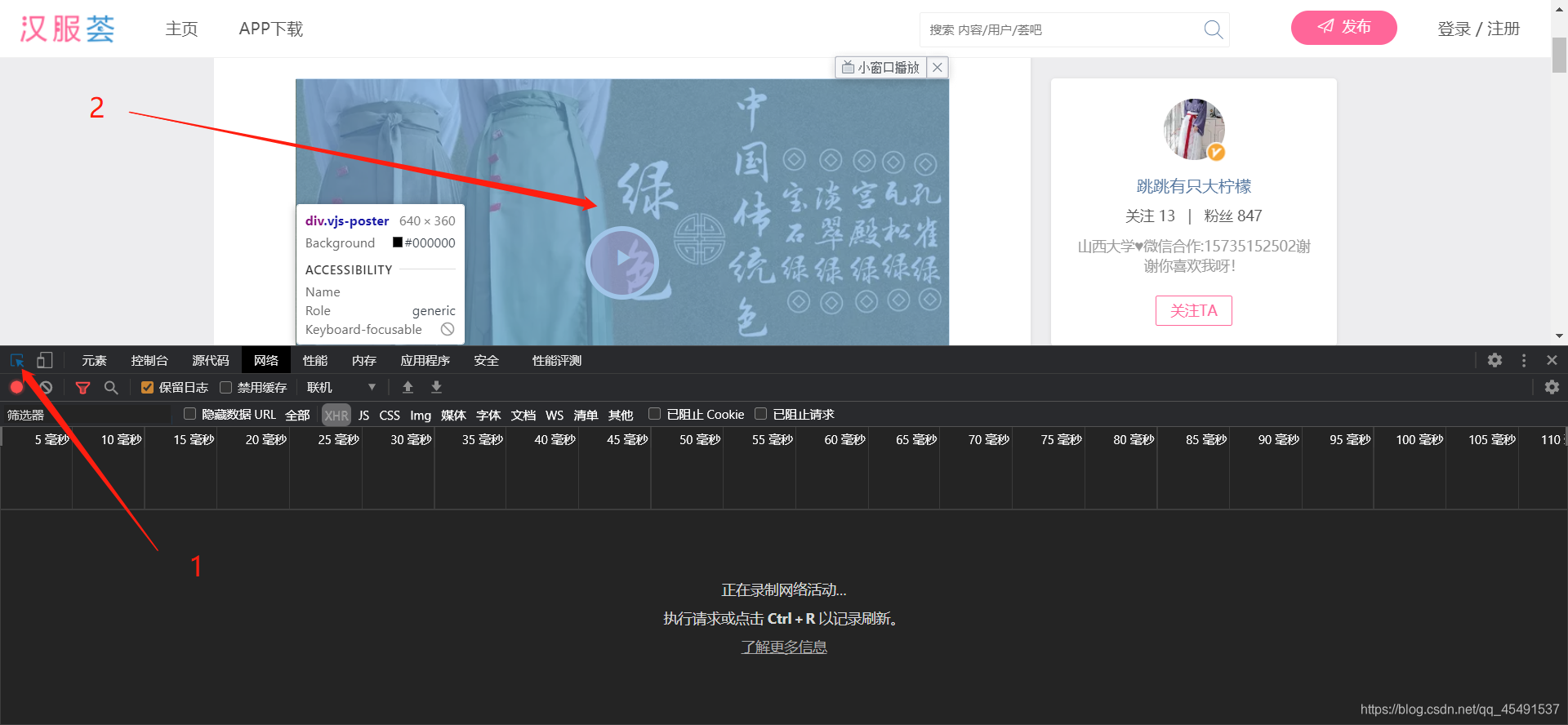
依次点击1,2,即可:
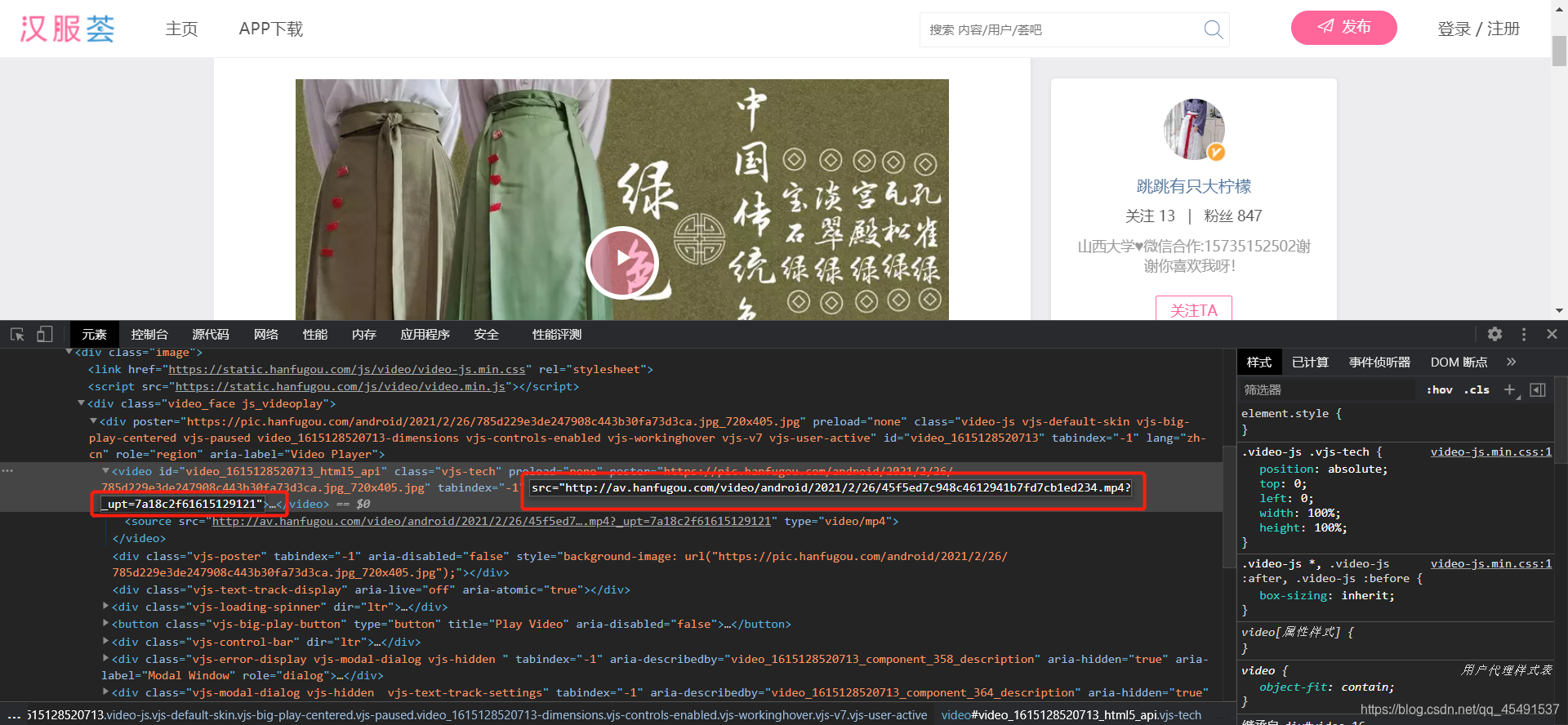
src属性值就是视频的链接地址,复制出来打开新页面进行访问看看:

到这里之后有的童鞋就会扒拉扒拉写代码去了,别急,先看看源代码中有无视频连接:
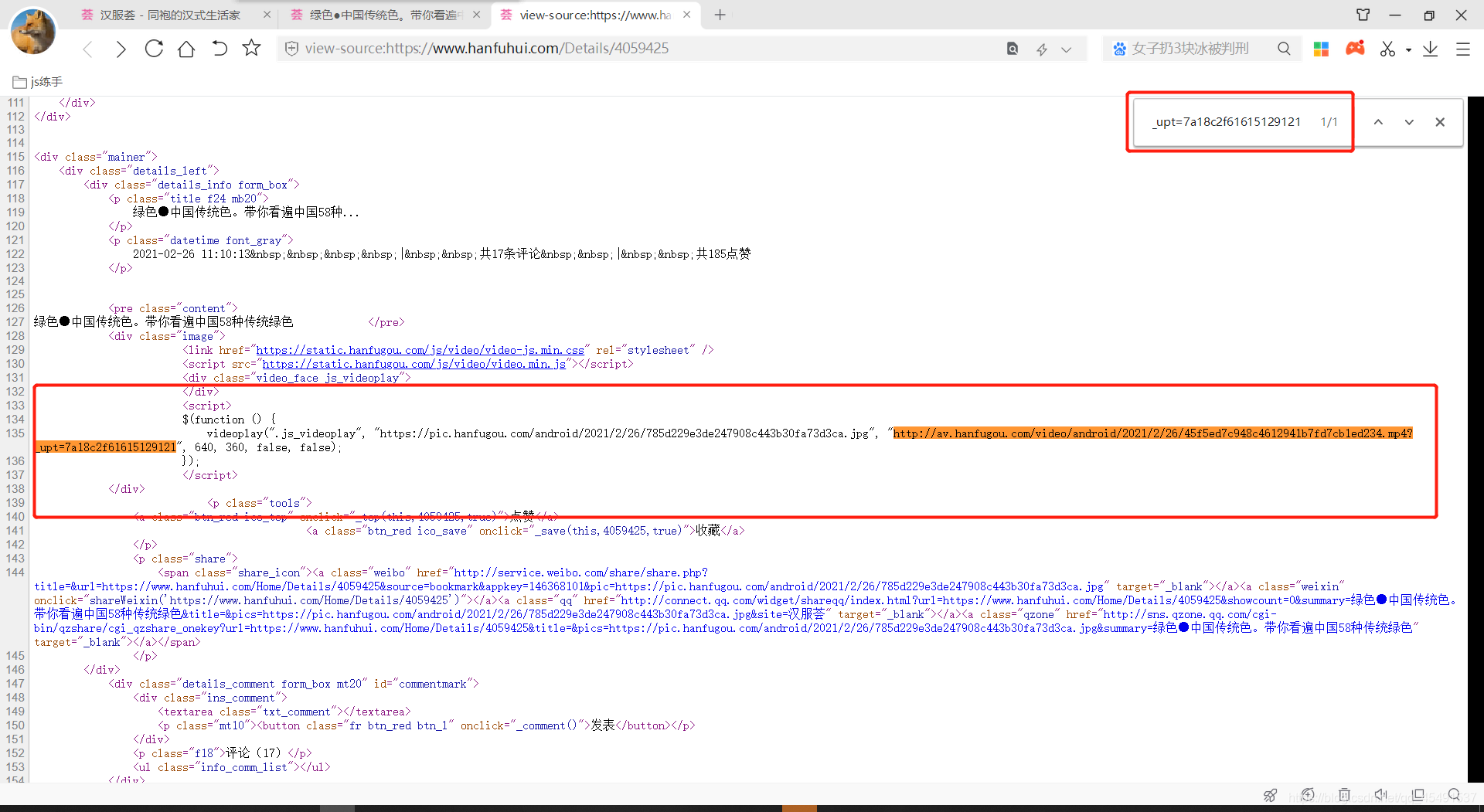
有是有对吧,而且仅有一个,但是你可以看到他的结构与上面我们看到的html结构完全不同,所以使用xpath或者bs4的规则去提取是不可行的。
so~只能上正则表达式了00
没问题,现在编写函数saveVideos来保存视频:
def saveVideos(indexUrl, i):
headers = {
'referer': 'https://www.hanfuhui.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
}
response = requests.get(indexUrl, headers=headers).text
videoUrl = re.search(r'js_videoplay", ".*?", "(.*?)"', response).group(1)
print(videoUrl)
_upt = re.search(r'_upt=(.*?)"', response).group(1)
with open('videoData/{}.mp4'.format(_upt), 'wb') as f:
f.write(requests.get(videoUrl, headers=headers).content)
f.close()
print('第{}个视频保存成功!'.format(i))
写完saveVideos后我们在get_IDList函数中将其调用并传入参数即可,下面是运行结果:
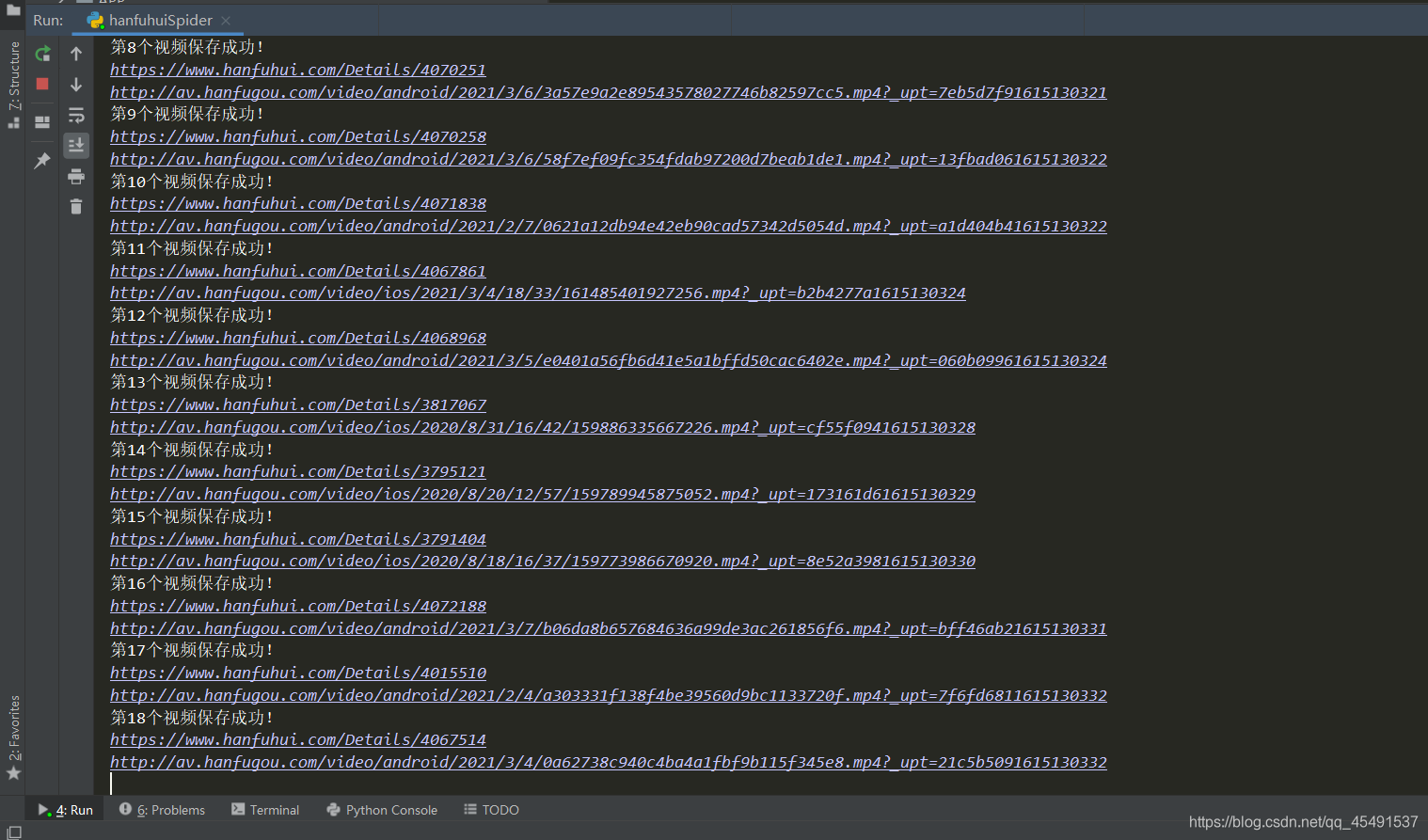
看看文件夹:
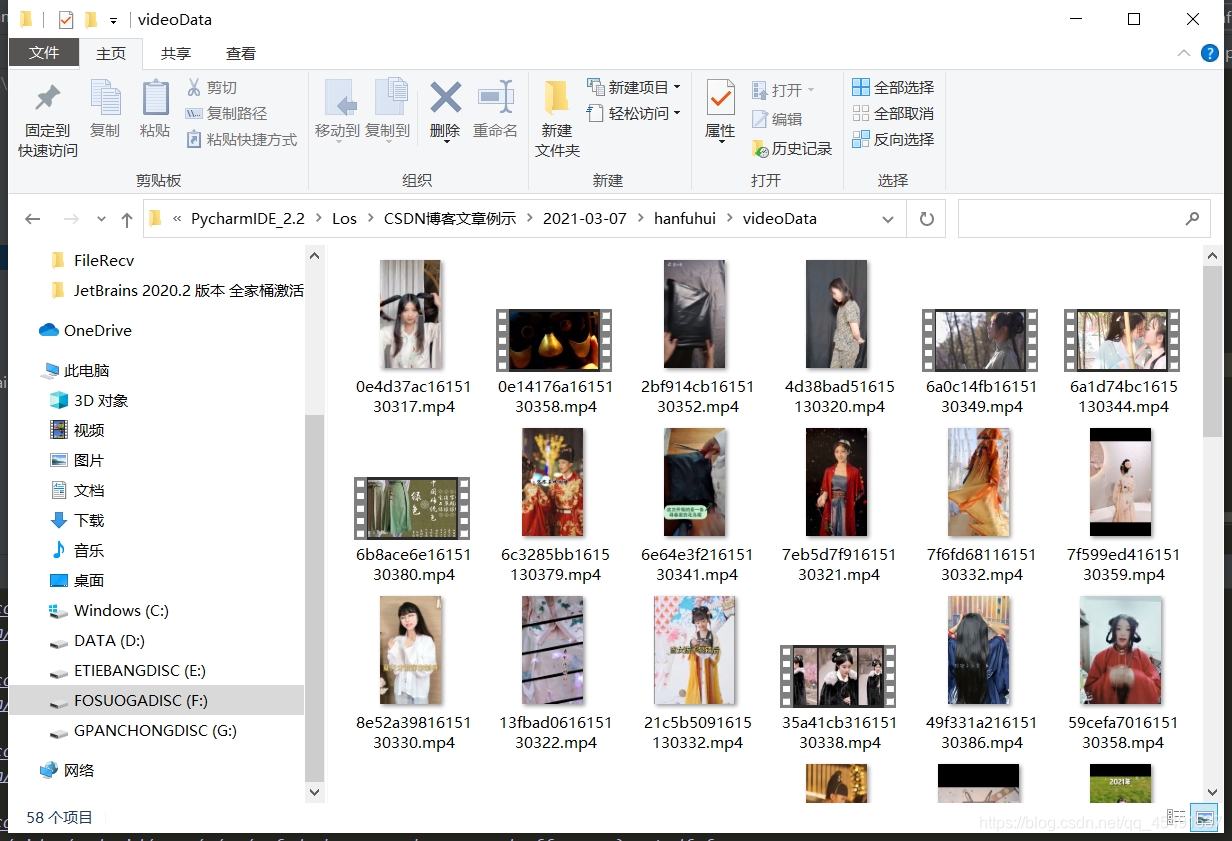
歪哟~成了。本篇文章到此结束。若你遇到了任何问题无法解决可以加我vx,我会抽空进行解答,添加方式见文章结尾。
总结
good good xuexi, day day up, 少掉头发。
码字不易,如果本篇文章对你有帮助请点个赞8,谢谢~
合作及源码获取vx:OneSisxoc 【注明来意】
QQ交流群:735418202
需要源码请关注微信公众号回复【东汉100】获取 :
*注:本文为原创文章,转载文章请附上本文链接!否则将追究相关责任,请自重!谢谢!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









