









项目前言
自学python差不多有一年半载了,这两天利用在甲方公司搬砖空闲之余写了个小项目——【12306-tiebanggg-master】。注:本项目仅供学习研究,如若侵犯到贵公司权益请联系我第一时间进行删除;切忌用于一切非法用途,否则后果自行承担!
下一章节 【python爬取12306列车信息自动抢票并自动识别验证码(二)selenium登录验证篇】 已完结
第三章节【2021最新 python爬取12306列车信息自动抢票并自动识别验证码(三)购票篇】已完结
项目描述
通过分析123O6,车次列表信息无需登录即可获取,但是如果我们想要使用代码代替手动为自己进行购票时,则需要进行登录网站;为了不给对方服务器造成压力,本项目并未开启多线程。项目为全自动进行车票的购买,包括(登录、验证码识别、刷票、判断是否有票、预购、下单、邮箱通知)本项目思路——使用selenium登录网站获取到cookie(供后续购票使用),定时检查cookie是否有效,获取列车列表信息及购票流程均使用requests的方式进行,流程如下:
1. 获取车次列表信息并对获取到的信息进行清洗处理;
2. selenium登录;
3. 超级鹰验证码处理(图片点选/滑块);
4. 获取cookie并保存至本地;
5. 判断是否有所选择的车次车票;
6. requests购票;
7. 完成抢票;
8. 将购票信息发送至邮箱;
9. 付款。
本项目结构如图:

项目效果:



最后抢到票的时候耗时总共用了1800秒并且邮件发送到了我的邮箱中(也可以通过微信进行通知,由于忙着写博客暂时不加入微信通知), 差不多半个小时。。。也就是说我在没有开多线程的情况下每秒的并发量可以达到2.3次。
技术手段及第三方打码平台的使用
本项目思路、过程过于复杂,共分为【列车数据获取篇】【selenium登录验证篇】【购票篇】【项目结束】,本篇文章只讲第一点【列车数据获取篇】
涉及到的第三方包:
① selenium
② requests
③ lxml
④ PIL
⑤ smtplib
⑥ email
打码平台:超级鹰
为什么使用第三方打码:
① 可以采用tensorflow等训练模型的方式进行验证码识别,但由于需要时间成本太大,果断放弃(其实是学艺不精,菜鸟,搞不定此处省略一万个#¥#¥%@#@¥)。
②由于12303采用图片点选和滑块的登陆验证方式,超级鹰可以识别并返回正确图片的坐标(供我们使用selenium进行点选操作)很方便,且10块大洋10000积分很实惠(声明:没有被超级鹰充值)。至于滑块验证的话本项目使用纯手工打造的代码进行实现验证通过率为99+%。
邮件发送:
当我们购票成功后,程序会自动将信息发送至设置邮箱通知付款。
好了,正片开始~
一. 获取列车列表信息并处理数据
本次“幸运”对象地址:aHR0cHM6Ly93d3cuMTIzMDYuY24vaW5kZXgvaW5kZXguaHRtbA==
1. 抓包
①搜先进入车票搜索页面进行车票检索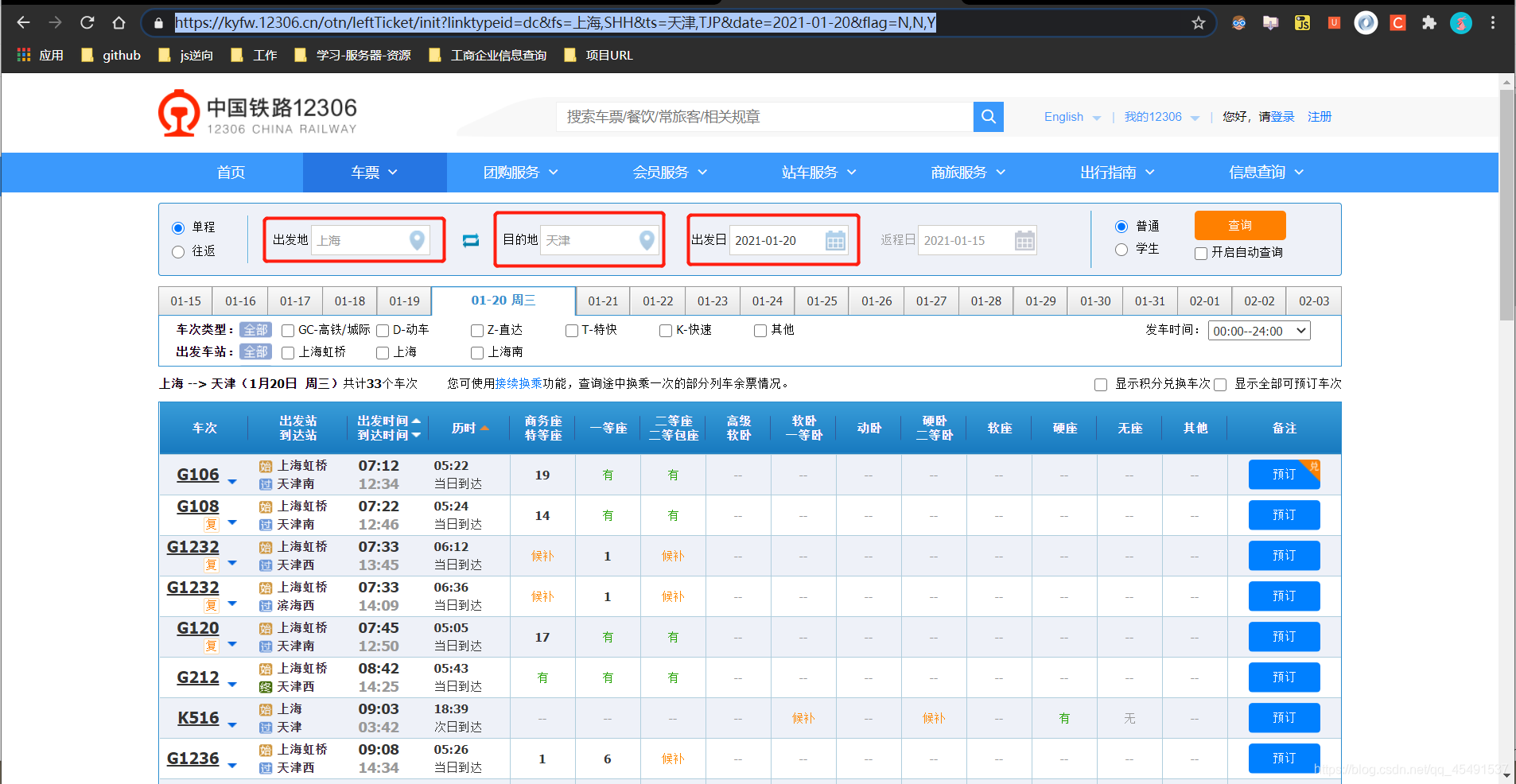
可以看到我们输入【上海—天津】时间为【2021-01-20】点击查询后便可以看到所有的车次列表信息地址栏URL变化为https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs=上海,SHH&ts=天津,TJP&date=2021-01-20&flag=N,N,Y
URL中带上了我们在输入框中输入的信息并返回数据,接下来通过代码请求网页:
import requests
fs = '上海'
ts = '天津'
date = '2021-01-20'
url = "https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs={},SHH&ts={},TJP&date={}&flag=N,N,Y"
headers = {
'Host': 'kyfw.12306.cn',
'Origin': 'https://kyfw.12306.cn',
'Referer': 'https://kyfw.12306.cn/otn/confirmPassenger/initDc',
'sec-ch-ua': '"Google Chrome";v="87", " Not;A Brand";v="99", "Chromium";v="87"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
# 打印网页文本
print(response.text)
请求到网页文本数据之后通过run窗口进行查询数据是否存在:
瓦特???没数据,于是我将headers中信息全部添加完整、带上cookie之后再进行请求,然鹅并没有什么暖用,数据依然不见踪影…
接下来我心存幻想:网页是不是异步加载?
于是乎:

当按下F12,并选择XHR(异步加载请求抓包)重新点击查询后出来了这么个玩意,接下来点击Preview看看返回值:

这是个啥玩意?这时候不慌,先点击Response查询数据看看,以 G106这列车来进行搜索:

真香大白了hhh~列车数据是通过异步加载地址:https://kyfw.12306.cn/otn/leftTicket/queryT?leftTicketDTO.train_date=2021-01-20&leftTicketDTO.from_station=SHH&leftTicketDTO.to_station=TJP&purpose_codes=ADULT请求而得到,看看请求方式及提交的表单信息:

可以看到请求方式为get,提交的表单有leftTicketDTO.train_date、leftTicketDTO.from_station、leftTicketDTO.to_station、purpose_codes 经过多次抓包purpose_codes参数为固定值,leftTicketDTO.train_date为我们填入的购票日期,另外两个跟着我们填入的出发点和目的地一直在改变,我猜想这应该是出发地和目的地的对应代码,接下来我们清空之前的抓包数据再进行一次抓包,并以我们输入的出发地【上海】进行全局搜索:

发现了什么~[/手动滑稽],接着点击这条连接看看返回数据:

通过返回数据可以看到【上海】后面跟的是一个【SHH】,没错,到这里我们找到了之前我们的leftTicketDTO.from_station=SHH变量,再进一步搜索【天津】:

没错,leftTicketDTO.to_station=TJP, 也就是说这里找到了出发地和目的地对应的代码,接下来可以请求这个地址进行出发地和目的地代码提取了,但是这里有细节需要注意一下:
当我搜索出发地或者目的地关键字时可以看到返回的地址并不是唯一一个
楼主之前使用第一条地址进行请求时,虽然能够返回出发地和目的地对应的代码,但是数据并不全。so,经过我多次观察,出发点和目的地返回最全的地址为截图中第五条地址, 如何操作:
左边点击地址,右边再点击Headers即可查看到对应的URL并且请求方式为get

接下来写代码获取全国出发站台的对应id,代码实现:
"""
获取城市站台对应代号并保存到本地
:return: dict
"""
# 通过抓包可知城市代码信息为请求如下地址
url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9181"
response = requests.get(url=url).text
# print(response)
# 通过正则表达式获取需要数据
find_city = re.findall(r'@.*?\|(.*?)\|', response)
find_city_id = re.findall(r'@.*?\|.*?\|(.*?)\|', response)
city_id_dict = {}
for c, i in zip(find_city, find_city_id):
city_id_dict[c] = i
print(city_id_dict)
# 保存数据至本地
with open('_utils/citytilss/city.txt', 'w', encoding='utf-8') as f:
f.write(str(city_id_dict))
打印日志:

将保存为字典格式,以便后续获取列车信息使用,代码实现获取列车信息:
# -- coding: utf-8 --
# @Time : 2021/1/15 21:45
# @Author : Los Angeles Clippers
import requests
import json
import re
def city_id():
"""
获取城市站台对应代号并保存到本地
:return: dict
"""
# 通过抓包可知城市代码信息为请求如下地址
url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9181"
response = requests.get(url=url).text
# print(response)
# 通过正则表达式获取需要数据
find_city = re.findall(r'@.*?\|(.*?)\|', response)
find_city_id = re.findall(r'@.*?\|.*?\|(.*?)\|', response)
city_id_dict = {}
for c, i in zip(find_city, find_city_id):
city_id_dict[c] = i
print(city_id_dict)
# 保存数据至本地
with open('_utils/citytilss/city.txt', 'w', encoding='utf-8') as f:
f.write(str(city_id_dict))
return city_id_dict
def decrypt(string):
"""
处理字符串
:param string:
:return:
"""
# 定义正则表达式提取规则
reg1 = re.compile('.*?\|预订\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*')
reg2 = re.compile('.*?\|.*?起售\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*')
reg3 = re.compile('.*?\|.*?停运\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*')
reg4 = re.compile('.*?\|.*?暂停发售\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*')
# 因网站存在三种状态的列车信息,所以使用try语句进行处理。
try:
result = re.findall(reg1,string)[0]
except IndexError as e:
try:
result = re.findall(reg2, string)[0]
except:
try:
result = re.findall(reg3, string)[0]
except:
result = re.findall(reg4, string)[0]
return result
def getchepiaoinfo(city_id_dict):
"""
获取列车信息并保存至本地。
:param city_id_dict:
:return:
"""
# 通过抓包可知车次信息为请求如下地址得到
fs = '上海'
ts = '天津'
date = '2021-01-20'
url = "https://kyfw.12306.cn/otn/leftTicket/queryT?"
# 构造form表单
params = {
'leftTicketDTO.train_date': date,
'leftTicketDTO.from_station': city_id_dict[fs],
'leftTicketDTO.to_station': city_id_dict[ts],
'purpose_codes': 'ADULT',
}
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Host': 'kyfw.12306.cn',
'If-Modified-Since': '0',
'Pragma': 'no-cache',
'sec-ch-ua': '"Google Chrome";v="87", " Not;A Brand";v="99", "Chromium";v="87"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': '', # 自行添加
}
response = requests.get(url=url, params=params, headers=headers)
print(response.status_code)
# 请求到的数据使用json来进行处理
jsdata = json.loads(response.text)['data']['result']
read_id = {}
for k, v in city_id_dict.items():
read_id[v] = k
# 获取车次详情信息,并保存至本地
for item in jsdata:
# break
result = list(decrypt(item))
result[1] = fs
result[2] = ts
# 构建content列表,用于存放列车信息
content = [result[0], read_id[item.split('|')[6]], read_id[item.split('|')[7]], result[3], result[4], result[5], result[-1], result[-2], result[-3],
result[6], result[-10], result[8], result[-5], result[9], result[-4], result[-7], result[-6]]
print(content)
def spider_main():
# 主函数,程序运行入口
city_id_dict = city_id()
secretStr = getchepiaoinfo(city_id_dict=city_id_dict)
return secretStr
if __name__ == '__main__':
spider_main()
运行结果:

可以看到,我们到此为止获取到了上海到天津的所有车次列表信息。本篇文章只对过程进行叙述,具体代码实现如有不明白的请v我解答。
接下来购票需要登录,所以下一章节我们将会讲解如何进行12306登录并处理验证码。
下一章节【python爬取12306列车信息自动抢票并自动识别验证码(二)selenium登录验证篇】 已更新
码字不容易,如果本篇文章对你有帮助请点个赞8,谢谢~
合作及源码获取vx:tiebanggg 【注明来意】
QQ交流群:735418202
需项目【12306-tiebanggg-master】源码请关注微信公众号 :
*注:本文为原创文章,转载文章请附上本文链接,谢谢!















 3231
3231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









