






Paper: A Novel Plug-in Module for Fine-Grained Visual Classification
论文链接: https://arxiv.org/pdf/2202.03822.pdf
许多用于细粒度识别任务的定位-分类网络都具有复杂的两层或是多层结构,并且不能够实现端到端的训练。虽然基于视觉Transformer的网络架构能够避免上述缺点,但这种方法不能够推广到卷积神经网络等其他的架构中,因此适用性有限。弱监督目标定位(Weakly supervised object detection)领域的一些研究已经证明了网络提取的feature maps和目标定位之间的关联性。基于此,作者提出了一个适用于许多主干网络的即插即用的模块(plug-in module),包括CNN架构和Transformer架构。该模块能够输出像素级的feature maps,并能够融合经过滤波器后的特征。
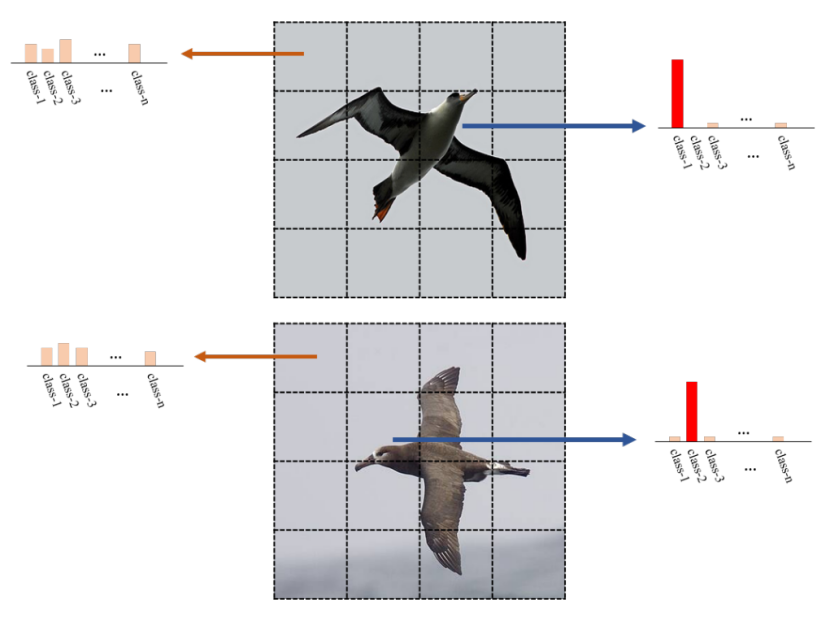
上图是对输入图像的不同patches进行类别预测的概率分布。背景对于分类的结果显然是没有任何帮助的,且概率的分布和包括了部分目标的patches有很明显的不同。因此,作者希望能够借助这种概率分布的区别,来区分前景和背景,以此提高细粒度识别的准确性。
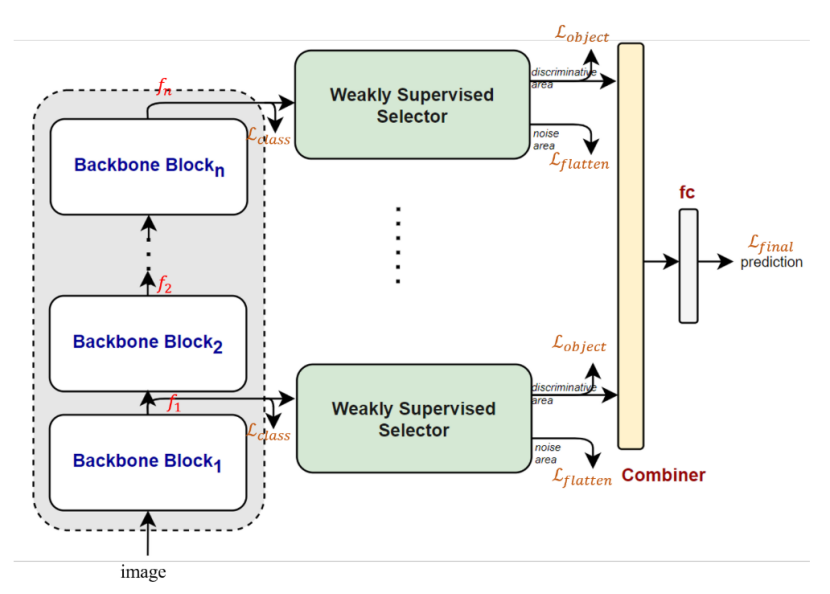
该图展示了PIM的整体架构。对于主干网络每一层输出的feature maps,将其输入到Weakly Supervised Selector模块,根据按像素或按patch的分类结果的概率分布,选中具有辨识度的部分。将确定为无效的特征丢弃后,将每层得到的有效特征结合,输入最终的全连接分类层,并得到分类结果。
Weakly Supervised Selector模块内部的选择逻辑非常简单。该模块将feature map中的每一个point通过一个全连接层,预测其所属类别。当预测结果向量中的最高的概率值大于某个预设的值时,就认为该点是一个有效的特征,参与之后的特征融合。反之,则视为无效特征并丢弃。
对于该模块的实用性,我抱有一定的怀疑。从整个特征提取网络的第一层和最终层提取特征,并且均参与最终的融合,是否会导致从网络深层提取出的高层语义的模糊和失真?并且全连接层作为卷积网络中计算开销占比最大的部分,我认为增加的模块对网络前向推理时的性能影响也会很大。
实验中,该模块在CUB-200-2011数据集上,以Swim-T为主干网络时的top1准确率为92.8%,相较于纯Swim-T提高了0.9%。以ViT为主干网络时的top1准确率为91.0%,相较于纯ViT提高了0.9%。实际在以ViT作为主干网络时,其准确率并未达到SOTA。但同时也证明了Swin-T在细粒度识别任务上具有的优势。















 1466
1466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









