







 本文探讨了处理存储中的计算(PIM)技术,旨在解决内存墙问题,通过在内存中执行计算来减少数据移动。文章提出了选择在内存中执行哪些操作的策略,以及编程PIM架构的关键问题,如卸载粒度、数据共享、虚拟内存管理和自动识别PIM目标。案例研究表明,PIM对于数据密集型任务如机器学习的打包过程特别有效。此外,还讨论了PIM内核的优化和一致性机制,以提高能效和性能。
本文探讨了处理存储中的计算(PIM)技术,旨在解决内存墙问题,通过在内存中执行计算来减少数据移动。文章提出了选择在内存中执行哪些操作的策略,以及编程PIM架构的关键问题,如卸载粒度、数据共享、虚拟内存管理和自动识别PIM目标。案例研究表明,PIM对于数据密集型任务如机器学习的打包过程特别有效。此外,还讨论了PIM内核的优化和一致性机制,以提高能效和性能。
Processing-in-memory: A workload-driven perspective
NOTE:本文并不是论文的通篇翻译,只讲个大概意思(但是全面),然后说一下总结和自己的看法。
Introduction
PIM的出现是解决传统数据跨内存通道移动时带来的巨大的数据移动瓶颈,俗称“内存墙”,实际是指代数据移动在时间和能耗方面的损失。在上个世纪之前,类似于PIM的思想就出现过,然而受制于当时的制作工艺、内存容量、应用场景等限制,这种思想并未被广泛采用。然而,当3D堆叠技术出现之后,PIM便成为了一门比较热门的方向。
在本文中,作者主要研究了两个挑战:
- 程序员需要能够识别出可以用PIM改进其性能的地方,具体指代什么部分应该在PIM中执行
- 有效的接口和机制,使得程序嫩巩固轻松利用PIM的优势,比如Cache一致性、地址转换等。
Overview of PIM
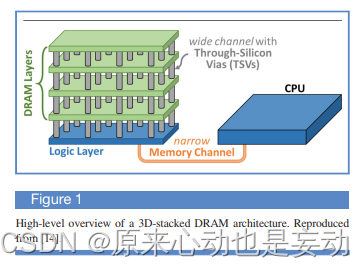
首先,许多著名的3D堆叠DRAM架构,包括HBM,HMC,在芯片内部都包含一个逻辑层。架构师可以在其中实现与处理器和DRAM交互的功能单元。其次,现在NVM(e.g., ReRAM, MRAM, PCM等)技术的发展也为架构师提供了一个机会从而重新设计内存子系统的运作方式。
受此影响,PIM又被分为两种类型:processing-near-memory(pnm) & processing-using-memory(pum)。
- pnm:在靠近内存或者内存内部添加PIM逻辑,一般PIM逻辑位于逻辑层或者存储器控制器中。
- pum:利用内存单元和单元阵列本身的内在属性和操作原理,通过单元之间的相互作用,使得可以执行计算。
Challenges
- 程序员需要能够确定应用程序的哪部分适合PIM
- 程序员需要一种方法来提取PIM的好处,而不必求助于复杂的编程模型。
Choosing what to execute in memory
PIM并不可以代替CPU,相反,由于其面积、能量和成本的原因,其无法承受与CPU一样复杂的大型多级缓存层次结构或执行逻辑,另外,PIM往往没有缓存或者缓存很小,灭有复杂的侵占性乱序或超标量执行逻辑,这限制了PIM内核提取指令集并行性的能力。因此,常规来讲,程序中计算密集型或者缓存友好的部分应该保留在CPU中。
为了确定程序中的哪一部分适合放在PIM上,作者开发了一个系统的工具流来做这个工作。那么,什么时候一个函数应该放在PIM中而不是CPU中呢?作者给出了四个条件(为表述清楚,此处用原文):
- It consumes the most energy out of all functions in the workload since energy reduction is a primary objective in consummer workloads.
- Its data movement consumes a significant fraction (e.g., more than 20%) of the total workload energy to maximize the potential energy benefits of offloading to PIM.
- It is memory-intensive (i.e., its last-level cache misses per kilo instruction, or MPKI, is greater than
10 [122–125]), as the energy savings of PIM is higher when more data movement is eliminated. - Data movement is the single largest component of the function’s energy consumption.
Case study
PIM之所以是一个比较热门的研究方向,并不在于其打破了传统的冯架构所以夺目,现在应用中的许多工作负载(e.g., 机器学习、数据分析负载、基因组分析)都非常适合PIM也是一个重要的点。这些工作负载通常被划分为计算密集型和内存密集型,当把内存密集型的PIM目标卸载到PIM逻辑时,收益巨大。
作者接着使用TensorFlow Lite做了一个case study,如下图所示,可以看出能量的花费。可以看出:打包、解包、量化消耗了不少的能量。这是因为这部分主要对矩阵的元素进行重新排序,以最大限度地减少矩阵乘之间的缓存未命中,这会导致大量的数据移动。同时,图3也证明很大一部分执行时间花在了打包和量化过程。作者认为:这个打包、量化过程,正是PIM逻辑的发挥之处!
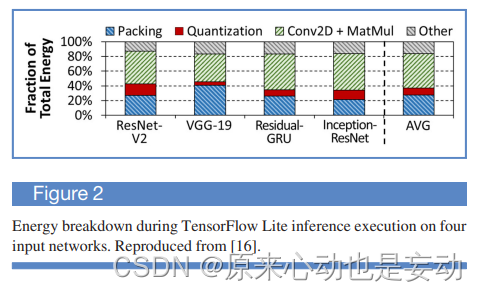
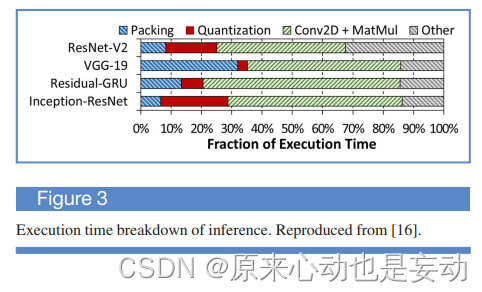
PIM effectiveness for packing
广义矩阵乘法(GEMM)是神经网络的核心构建块,被卷积层和全连接层使用。每个GEMM操作设计三个步骤:根据内核的内存访问模式对矩阵块进行重新排序;GEMM计算;使用gemmlowp进行解包,它将结果矩阵转换回原始顺序。作者根据这个工作流程,将部分任务卸载到了PIM中,具体如下:
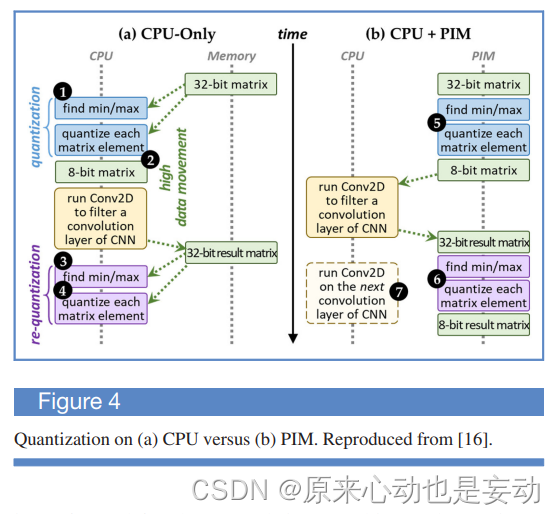
根据评估,无论时消耗的能量,还是延迟,本文提出的识别PIM目标的方法可以显著提高TensorFlow Lite机器学习的框架的性能并降低能耗。
Programming PIM architectures: Key issues
虽然许多应用程序具有从PIM中收益的巨大潜力,但需要对如何卸载应用程序的某些部分以及如何在不给应用程序造成过度负担的情况下完成卸载。因此,本部分考虑PIM架构可编程性的四个关键问题(我们继续使用原文来表述):
- the different granularities of an offloaded PIM kernel;
- how to handle data sharing between PIM kernels and CPU threads;
- how to efficiently provide PIM kernel with access to essential virtual memory address translation mechanisms;
- how to automate the identification and offloading of PIM targets
Offloading Granularity
- 在极端情况下,从CPU的角度来讲,一个PIM内核可以由一条指令组成。因此,单个PRI执行工作。
- 另一种方法是将批量操作卸载到内存(可以想象那些NVM:简单的算术运算,批量按位操作),缺点是单个批量操作处理的数据量存在限制(不能少于一行等)。
- 第二种比单个PEI执行更多工作的方法是在应用程序功能或应用程序中的指令块的粒度上卸载。
- 另一种极端的情况,一个PIM内核可以包含一个完整的应用程序(不需要与CPU通信,不需要CPU和PIM之间执行缓存一致性)。
Sharing data between PIM logic and CPUs
PIM逻辑上应该与CPU共同执行,类似于多线程。因此,需要共享内存,即,需要考虑缓存一致性。问题在于,对PIM使用传统的细粒度缓存一致性会迫使大量的一致性数据穿过狭窄的内存通道,这与PIM技术最初的减少数据移动的初衷相反。为解决这个问题,本文提出了成为CoNDA的PIM一致性机制。
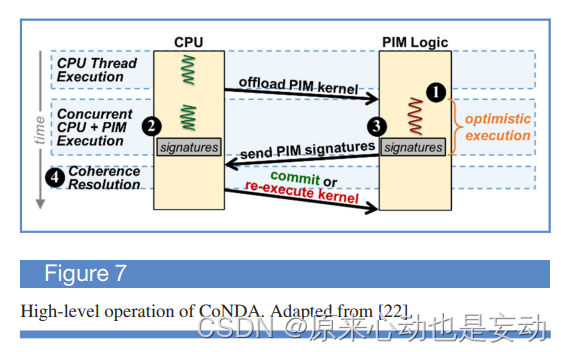
PIM logic:
- 在给定的一段时间内,投机性地获得多个内存操作的一致性权限(opyimistic execution)
- 将来自多个内存操作的一致性请求批处理成一组压缩的一致性签名( ② ③ )
- 将签名发送到CPU以确定推理是否违反了任何连贯语义
而当CPU收到签名时,CPU就会执行一致性解析,检查是否有冲突,如果有,刷新脏行,然后PIM内核会回滚并重新执行乐观执行的代码。实验证明,CoNDA将平均性能提高了66.0%。
Virtual memory
应用程序在虚拟地址空间中运行,当应用程序需要访问其在主存中的数据时,CPU内核必须首先进行地址转换,将数据的虚拟地址转换为主存中的物理地址。相应地,PIM内核通常需要执行地址转换,例如当卸载到内存的代码需要遍历指针时。指针存储为虚拟地址,并且必须在PIM逻辑可以访问内存中的物理位置之前进行转换。如果把这个工作交给CPU,那么PIM的好处会被削弱,因此,作者做了一系列研究,以IMPICA为名已发表。作者将CPU中的页表与PIM中的页表完全解耦,如此,PIM中的页表逻辑不再依赖于单一架构,并且允许具有PIM逻辑的内存芯片与任何CPU配对。其次,这提供了一种机会去开发新的页表设计。
Enabling programmers and compilers to find PIM targets
最直接的方式就时开发可以执行工具流并自动执行的PIM编译器。
注:
最后的最后,感觉国内关于PIM的工作才刚刚起步,国外已经走了好几年了。望我辈迎头赶上,不要在博士期间
研究人家丢的破烂,共勉。

















 3116
3116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









