






1.Golang介绍与环境搭建
1.1Golang介绍
golang又称go language简称golang, go语言是谷歌推出的一种编程语言,可以在不损失应用程序性能的情况下降低代码的复杂性。谷歌首席软件工程师罗勃派克说:‘’我们之所以开发go,是因为过去十年间软件开发的难度令人沮丧‘’。派克表示,和今天C和C++一样,go是一种系统语言。使用它可以快速开发,同时它还是一个真正的编译语言,我们之所以将它开源,原因是我们认为它已经非常有用和强大。
1)计算机硬件更新频繁,性能提高很快。目前主流的编程语言发展明显落后于硬件,不能合理的利用多核多CPU的优势来提升软件系统的性能。
2)软件系统的复杂度越来越高,维护成本越来越高,目前需要一个足够简洁高效的编程语言。
3)企业运行维护很多C/C++的项目,C/C++运行速度快但是编译速度却很慢。同时还存在内存泄漏等一系列困扰需要解决。
1.2Golang安装
1.官网下载SDK(运行go的前提)
2.一直下一步
1.3Windows下常用的命令
1)dir:查看当前目录下的文件列表
2) D: 进入D盘
3) MD/md/mkdir fileName :创建文件名目录
RD fileName :删除目录
4) cls :清空DOS命令窗口内容
5) copy file1 file2 :将file1的内容复制到file2中
6) cd .. :返回上级目录
7) ./ :当前目录
8) del fileName :删除文件
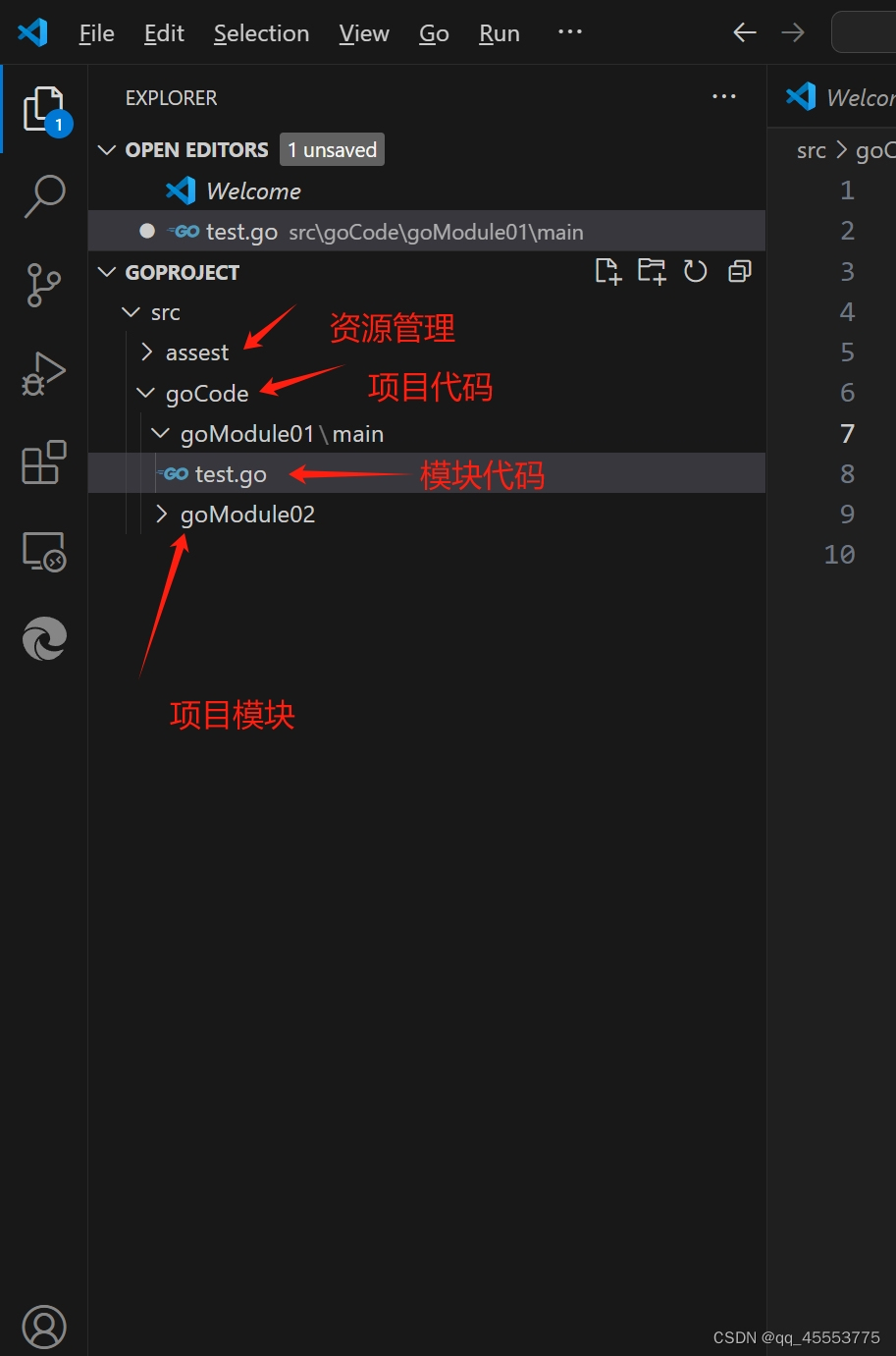
1.4Golang项目的大致目录结构
文件手动创建
1.5Golang的hello world
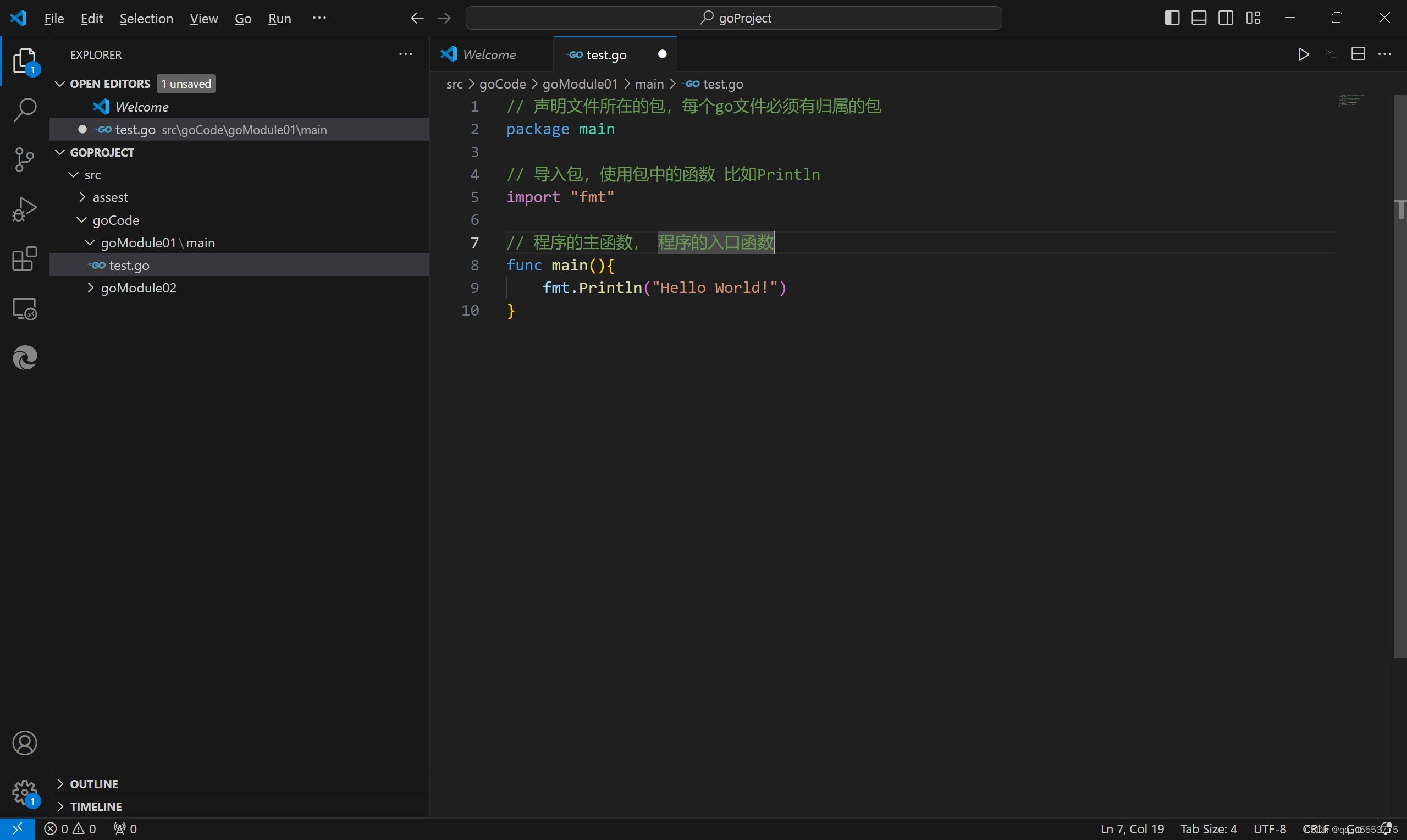
注意:
1) 在go语言里命名为main的包具有特殊的含义,Go语言的编译程序会试图把这种命名的包编译成二进制的可执行程序文件
2)所有用Go语言编译的可执行程序都必须要有一个名叫main的包
3)一个可执行程序有且只有一个main包
4)当编译器发现某一个包为main时,它一定会发现main() 函数 ,否则不会创建可执行文件
5)程序编译时,会使用声明main包代码所在目录的目录名为二进制可执行程序的文件名
6)源文件以go为拓展名
7)源文件字母严格区分大小
8)方法由语句构成,每条语句末尾不需要“;”结尾
9)go的编译器是一行一行进行编译,因此每行只能写一条语句,否则报错,或者使用';'进行隔开,但是失去代码简洁性
10)定义的变量或者import包没有使用到则编译不能通过,体验简洁性
1.6Golang的文件编译
使用命令窗口 进入主程序目录下
-
使用命令: go build test.go 在当前目录下生成test.exe二进制可执行文件
-
使用.\test.exe可运行该编译文件,或者使用go run test.go直接编译执行源文件
-
说明:编译之后生成的二进制可执行文件变大是因为是编译程序把程序所依赖的库文件打包编译。
-
直接go run 运行文件不可迁移至非go环境上运行,而go build之后的文件能够运行在其他环境上
-
编译时可以额外指定名字,默认使用main函数文件名,使用go build -o name.exe test.go 可指定编译后生成的二进制可执行文件的文件名
1.7前置知识
1) 缩进:
Tab键向后缩进
Shift + Tab键向后缩进
格式化命令:格式效果展示 gofmt test.go 效果写入源文件 gofmt -w test.go
Ctrl + s 保存。在vscode中会附带格式化
2)格式统一。声明函数同一行中必须要由{,以下代码是错误示范:
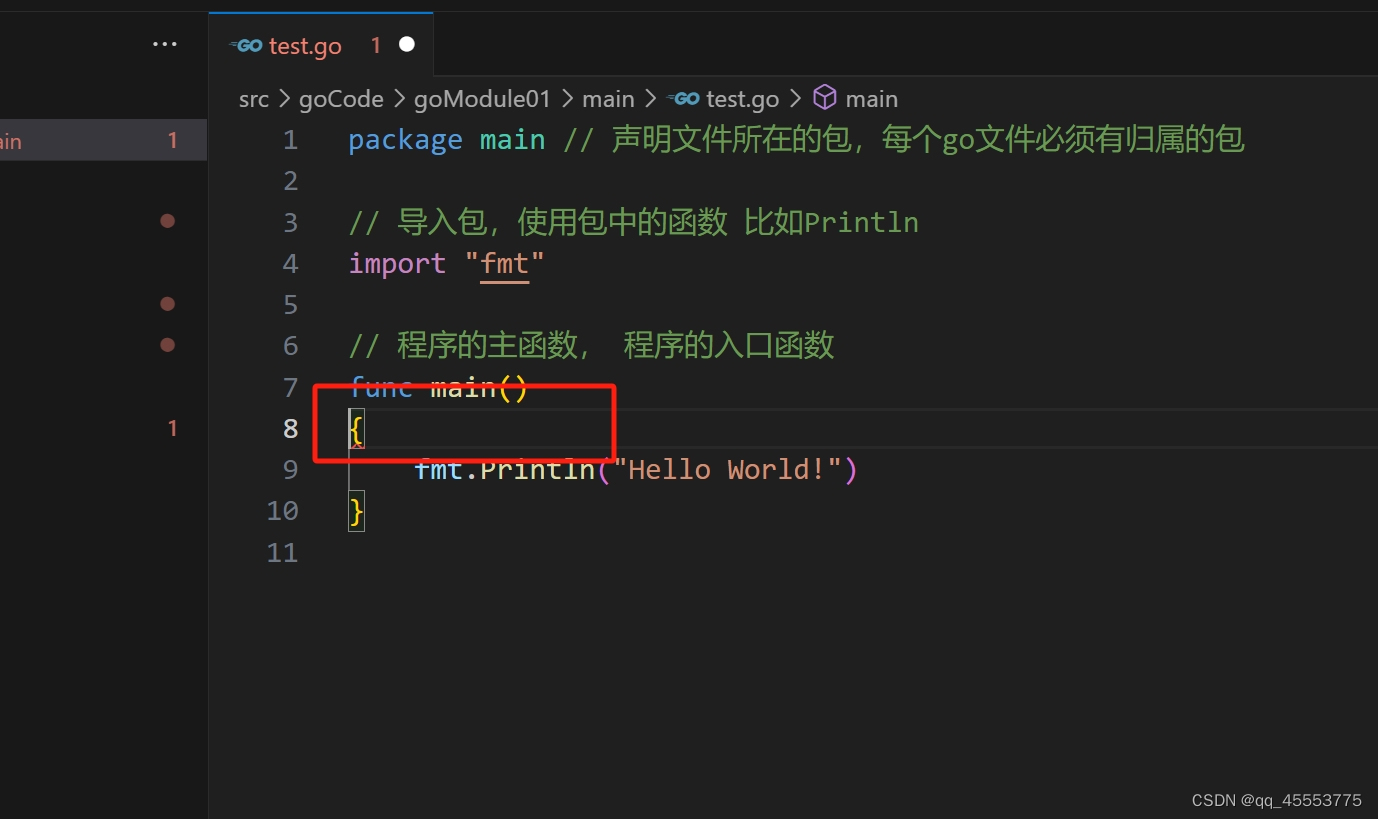
一行尽量不要超过80个字符,Println函数可以输出多个,使用‘,’进行隔开。
3)Go语言的API文档Go语言标准库文档中文版 | Go语言中文网 | Golang中文社区 | Golang中国
源码查看方式:
对应官方文档:
2.Golang的变量与运算
2.1Golang的变量
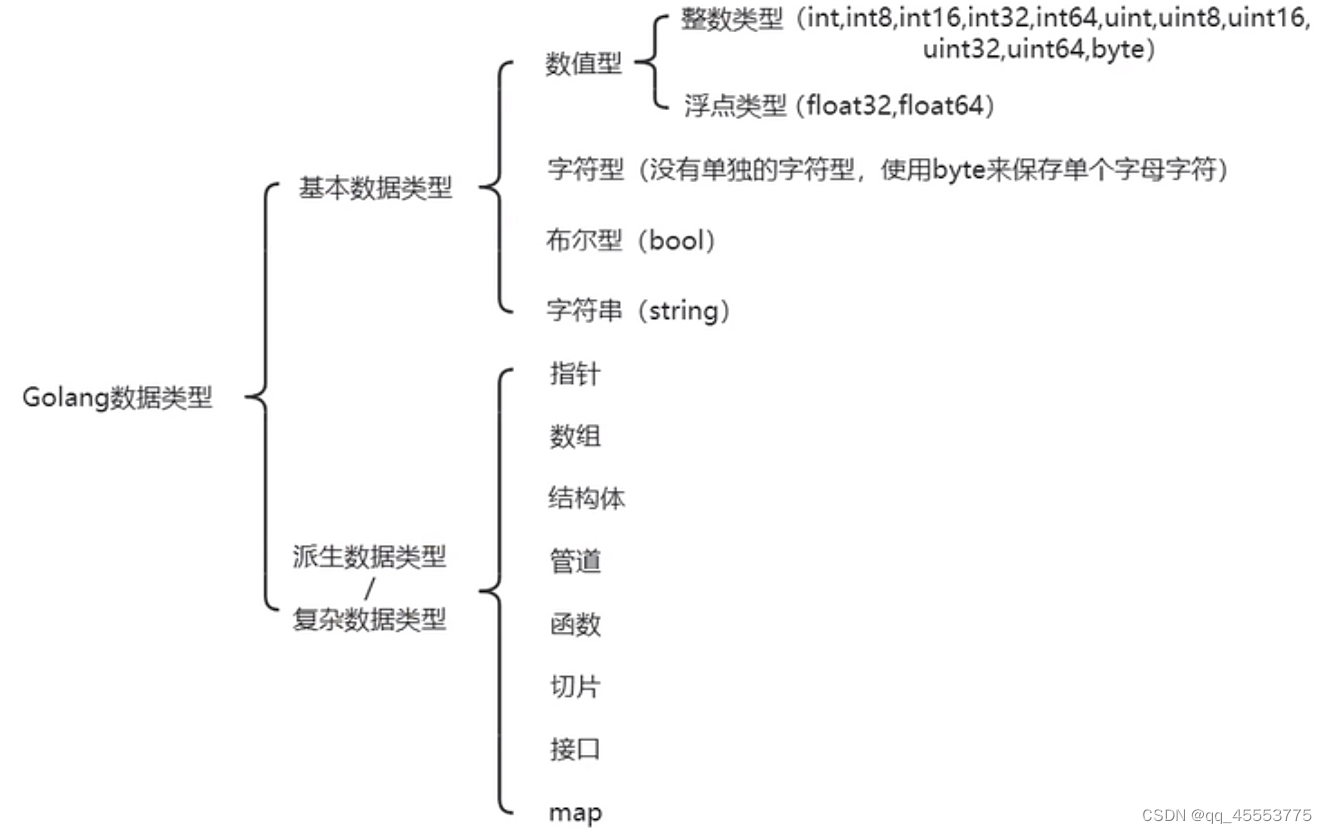
Golang是一种强制类型定义的语言。其变量类型如下:
(1) 整型
| 类型 | 有无符号 | 占用存储空间 | 表示范围 |
|---|---|---|---|
| int | 有 | 32位操作系统4字节/64位操作系统8字节 | -2**31~-2**31-1/-2**63~2**63-1 |
| int8 | 有 | 1字节8位 | -2**7~2**7-1 |
| int16 | 有 | 2字节16位 | -2**15~2**15-1 |
| int32 | 有 | 4字节32位 | -2**31~2**31-1 |
| int64 | 有 | 8字节64位 | -2**63~2**63-1 |
| uint | 无 | 32位操作系统4字节/64位操作系统8字节 | 0~-2**32-1/0~2**64-1 |
| uint8 | 无 | 1字节8位 | 0~2**8-1 |
| uint16 | 无 | 2字节16位 | 0~2**16-1 |
| uint32 | 无 | 4字节32位 | 0~2**32-1 |
| uint64 | 无 | 8字节64位 | 0~2**64-1 |
注意:使用适当的变量类型能够节约内存空间
package main
import (
"fmt"
"math"
)
func main() {
// 声明int类型
var num1 int
// << 左移运算符,1表示0000 0000 · 0000 0000 · 0000 0000 · 0000 0000 · 0000 0000 · 0000 0000 · 0000 0000 · 0000 0001
num1 = 1 << 62 // num1 = 1 << 63将会报错,因为int类型在64位操作系统中只有64位,其中一位为符号位,左移63位超出表示范围
num1 = int(math.Pow(2, 63)) //使用math库中的Pow函数进行幂运算
fmt.Println("num1 = ", num1)
num1 = -1 * int(math.Pow(2, 64)) //使用math库中的Pow函数进行幂运算
fmt.Println("num1 = ", num1)
// 声明uint类型
var num2 uint8
num2 = 128
fmt.Println("num2 = ", num2)
// num2 = 263
// fmt.Println("num2 = ", num2)
/* 超出范围报错
# command-line-arguments
.\main.go:22:9: cannot use 263 (untyped int constant) as uint8 value in assignment (overflows)
*/
}(2) 浮点型
浮点型常用来存放小数使用
| 类型 | 存储空间 | 表示范围 |
|---|---|---|
| 单精度float32 | 4字节32位 | -3.403E38~3.403E38 |
| 双精度float64 | 8字节64位 | -1.798E308~1.798E308 |
注意:底层存储空间和操作系统无关,浮点数在计算机中的存储方式导致其存在精度损失,建议使用float64
package main
import "fmt"
func main() {
// 定义一个浮点数
var num1 float32 = 3.1415926
fmt.Println("num1 = ", num1) // num1 = 3.1415925
num1 = 3.141592697989293849
fmt.Println("num1 = ", num1) // 存在精度损失 num1 = 3.1415927
// 扩大精度
var num2 float64 = 3.1415926
fmt.Println("num2 = ", num2) //num2 = 3.1415926
num2 = 3.141592697989293849
fmt.Println("num2 = ", num2) // 更精确时仍然存在精度损失num2 = 3.1415926979892936
// 系统默认使用float64位
num3 := 3.1293
fmt.Printf("num3的数据类型:%T", num3)
}
(3) 字符类型
Golang没有单独的字符型,使用Byte来保存单个字母字符,byte:uint8的别名,ASCII码字符用此表示,1个字节
package main
import (
"fmt"
"unsafe"
)
func main() {
// 汉字使用unicode的utf-8编码 不能使用byte接收需要更大的接收如uint16
var c int = '中'
fmt.Println("c :", c) //c1 : 20013
fmt.Printf("c 类型 :%T\n", c) //c1 类型 :int
fmt.Println("c占用字节数 :", unsafe.Sizeof(c)) //c1占用字节数 : 8
// 想现实对应的字符必须采用格式化输出
fmt.Printf("c所表示的字符:%c\n", c) // c所表示的字符:中
// 定义字符类型的数据,通常使用ASCII码
var c1 byte = 'a'
fmt.Println("c1 :", c1) //c1 : 97
fmt.Printf("c1 类型 :%T\n", c1) //c1 类型 :uint8
fmt.Println("c1占用字节数 :", unsafe.Sizeof(c1)) //c1占用字节数 : 1
// 想现实对应的字符必须采用格式化输出
fmt.Printf("c1所表示的字符:%c\n", c1) // c1所表示的字符:a
}(4) 转义字符
\转移字符: 将后面的字母表示成特殊的含义
| 转义字符 | 含义 | unicode值 |
|---|---|---|
| \b | 退格(backspace) | \u0008 |
| \n | 换行 | \u000a |
| \r | 回车 | \u000d |
| \t | 制表符(tab) | \u0009 |
| \" | 双引号 | \u0022 |
| \' | 单引号 | \u0027 |
| \\ | 反斜杠 | \u005c |
(5) 布尔类型
布尔类型又称bool类型,只允许取true和false,布尔类型占用一个字节,适用于逻辑判断流程控制中
package main
import (
"fmt"
"unsafe"
)
func main() {
//布尔类型声明和使用
var b1 bool = true
fmt.Println("b1的数据值:", b1) //b1的数据值: true
fmt.Printf("b1的类型:%T\n", b1) //b1的类型:bool
fmt.Printf("b1的真实表示:%t\n", b1) //b1的真实表示:true
fmt.Println("b1的数据值大小:", unsafe.Sizeof(b1)) //b1的数据值大小: 1
}
(6) 字符串类型
字符连起来的字符序列
package main
import "fmt"
func main() {
// 字符串的使用
var s1 string = "全面拥抱golang"
fmt.Println(s1)
// 字符串不可变,字符串一旦定义好其中字符值就不能改变,除非重新创建新的字符串
s2 := "abc"
// s2[0] = 'n' //.\main.go:11:2: cannot assign to s2[0] (neither addressable nor a map index expression)
s2 = "zhan"
fmt.Println(s2)
// 字符串的表示形式,遇到多个特殊字符时可使用反引号``进行完整输出表示
s3 := "askjdhjk\"asd"
s3 = `
func main() {
//布尔类型声明和使用
var b1 bool = true
fmt.Println("b1的数据值:", b1) //b1的数据值: true
fmt.Printf("b1的类型:%T\n", b1) //b1的类型:bool
fmt.Printf("b1的真实表示:%t\n", b1) //b1的真实表示:true
fmt.Println("b1的数据值大小:", unsafe.Sizeof(b1)) //b1的数据值大小: 1
}
`
fmt.Println(s3)
// 字符串还能进行拼接
s4 := s1 + "\t" + s2
fmt.Println(s4)
// 注意字符串拼接时,➕应该保存在每行的最后,不能使用s6 := "abc"*8
s5 := "abc" + "abc" + "abc" + "abc" + "abc" + "abc" + "abc" + "abc" + "abc" + "abc" +
"abc" + "abc" +
"abc" + "abc"
fmt.Println(s5)
}(7) 数据默认值
| 数据类型 | 默认值 |
| 整数类型 | 0 |
| 浮点类型 | 0 |
| 布尔类型 | false |
| 字符类型 | '' |
| 字符串类型 | "" |
package main
import "fmt"
func main() {
// 整数的默认值
var i int
fmt.Println("整数的默认值:", i) //整数的默认值: 0
// 浮点数的默认值
var f float32
fmt.Println("浮点数的默认值:", f) // 浮点数的默认值: 0
// 布尔类型的默认值
var b bool
fmt.Println("布尔类型的默认值:", b) // 布尔类型的默认值: false
// 字符类型默认值
var c byte
fmt.Println("字符类型的默认值:", c) //字符类型的默认值: 0
// 字符串类型的默认值
var s string
fmt.Println("字符串类型的默认值:", s) //字符串类型的默认值:
}(8) 基本数据类型之间转换
不同类型之间赋值时需要显示转换,并且只有显示转换(强制转换)
语法:
1.表达式 T(v)将v强制转换成T类型
2.使用SPrintf()按照基本类型的格式进行转换返回字符串
3.使用strconv库中的函数进行转换
package main
import (
"fmt"
"strconv"
)
func main() {
//浮点型转整型
b := 3.14
a := int(b)
fmt.Println(a) // 3
//整型转浮点型
c := 8
d := float64(c)
fmt.Println(d) //8
//字符型转整形
e := 'e'
f := int(e)
fmt.Println(f) //101
//字符型转浮点型
g := 'g'
h := float64(g)
fmt.Println(h) //103
//大整型转小整型
var num1 int32 = 2999
num2 := int8(num1)
fmt.Println(num2) //-73
// 整型转字符型
num3 := 99
num4 := byte(num3)
fmt.Printf("%c\n", num4) // c
// 基本类型转换成字符串类型
n1 := 90
f1 := 3.14
b1 := false
s1 := fmt.Sprintf("%d", n1) // 90
fmt.Print(s1)
fmt.Printf("%T\n", s1) // string
s2 := fmt.Sprintf("%3.3f", f1) // 3.140
fmt.Print(s2)
fmt.Printf("%T\n", s2) // string
s3 := fmt.Sprintf("%t", b1) // 3.140
fmt.Print(s3)
fmt.Printf("%T\n", s3) // string
// 使用strconv库函数进行转换
fmt.Println(strconv.FormatFloat(f1, 'E', 3, 64))
}(9) string类型转成基本类型
使用strconv包下的Parse开头的函数
当不满足转换条件时,比如PrarseInt("dasd",10,32)时“dasd无法转换,函数返回Int默认值和报错(err)
package main
import (
"fmt"
"strconv"
)
func main() {
// 字符串转成其他类型
s1 := string('t')
s2 := "-10203"
s3 := "0921"
s4 := "0.293"
fmt.Println(strconv.ParseBool(s1))
fmt.Println(strconv.ParseInt(string(s2), 10, 32))
fmt.Println(strconv.ParseUint(s3, 10, 16))
fmt.Println(strconv.ParseFloat(s4, 32))
}(10) 指针
表示内存地址
package main
import "fmt"
func main() {
// 指针使用
var a int = 10
// &变量名 就能获取变量的内存地址
fmt.Println(&a) //0xc000096068 表示a变量的地址,程序每次运行时分配的地址可能不同
//指针类型就是 在基本类型前加*
f := 3.1001
var b *float64 = &f
fmt.Println(b) // 0xc00000a0f0表示b值,也就是f的地址
fmt.Println(*b) // 3.1001代表b指向的内存地址所存储的值
*b = 3.01
fmt.Println(f) // 通过指针改变地址的值 3.01
fmt.Println(&b) // 0xc000068030表示存储地址b的地址
}(11) 标识符
1.中文也能作为标识符,但是不建议使用
2.下划线"_"在Go语言里十个特殊的标识符,称为空标识符,可以作为占位符忽略某些值(某些返回值或者其后的值)
3. go文件中首字母大小是对变量或者函数的安全限制,当首字母大写时,该包被导入后该标识符能够被访问,当首字母小写时,该包即使被导入近也不能被访问
4.进行导包时需要用双引号扩起来,推荐使用go mod init方式构建的项目进行导包
1) 创建项目目录,进入项目目录下,构建一个main.go文件,和一个utils文件,进入项目 根目录下命令行执行:go mod init myProject,生成go.mod文件
2)在utils目录下编辑可以创建多个go文件,但是go文件的包名原则上需要与utils目录名同名,且一个目录下不允许有多个不同的包名
3)在main中就能直接导入包,导入该目录下的所有的标识符首字母大写的变量或者函数
2.2 运算符
(1) 算数运算符
算数运算符包括:+ 、- 、* 、/ 、%、 ++ 、--,同java类似,但是这里的++只能单独使用,在变量的前面,不能运算赋值
package main
import "fmt"
func main() {
var num1 int = 10
var num2 int = 3
num3 := num1 + num2 // num3 : 13
num4 := num1 - num2 // num4 : 7
num5 := num1 * num2 // num5 : 30
num6 := num1 / num2 //num6 : 3
num7 := num1 % num2 //num7 : 1
num1++ //num1 : 11
num2-- //num2 : 2
fmt.Println("num3 :", num3)
fmt.Println("num4 :", num4)
fmt.Println("num5 :", num5)
fmt.Println("num6 :", num6)
fmt.Println("num7 :", num7)
fmt.Println("num1 :", num1)
fmt.Println("num2 :", num2)
}(2) 赋值运算符
赋值运算符包括:= 、 += 、-= 、*= 、/= 、%=
package main
import "fmt"
func main() {
// 赋值运算符
a := 10
fmt.Println("a=", a) // 10
a += 2
fmt.Println("a=", a) // 12
a -= 3
fmt.Println("a=", a) // 9
a *= 6
fmt.Println("a=", a) // 54
a /= 3
fmt.Println("a=", a) // 18
a %= 5
fmt.Println("a=", a) // 3
}(3) 关系运算符
关系运算符包含:== 、 != 、 > 、< 、 >= 、 <=,常用于流程控制
package main
import "fmt"
func main() {
// 关系运算符
fmt.Println("2>3 : ", 2 > 3)
fmt.Println("2<3 : ", 2 < 3)
fmt.Println("2==3 : ", 2 == 3)
fmt.Println("2!=3 : ", 2 != 3)
fmt.Println("2>=3 : ", 2 >= 3)
fmt.Println("2<=3 : ", 2 <= 3)
}
(4) 逻辑运算符
逻辑运算符包含: && (短路与、且)、||(或)、!(非)
短路与:只要有一个是false就都是false后续不需要再判断了
或:只要有一个是true后续不需要判断表达式为true
package main
import "fmt"
func main() {
fmt.Println("true && true :", true && true) // true
fmt.Println("true && false :", true && false) //false
fmt.Println("false && false :", false && false) //false
fmt.Println("true || true :", true || true) //true
fmt.Println("false || true :", false || true) //true
fmt.Println("false || false :", false || false) //false
fmt.Println("!false :", !false) //true
fmt.Println("!true :", !true) //false
}(5) 位运算符
位运算符:& 、| 、 ^ 、 << 、 >>
&:按位与:两位都为1,结果为1,否则为0
|:按位或:只要有一位为1,结果就为1
^:按位异或:两对应的二进位相异时,结果为1
<<:左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。
>>:右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数
a = 60 # 二进制位 0011 1100
b = 13 # 二进制位 0000 1101
'''
a&b 按位与:两位都为1,结果为1,否则为0
a 0011 1100
b 0000 1101
二进制结果 0000 1100
十进制结果 12
'''
fmt.Println(a & b)
'''
a|b 按位或:只要有一位为1,结果就为1
a 0011 1100
b 0000 1101
二进制结果 0011 1101
十进制结果 61
'''
fmt.Println(a | b)
'''
a^b 按位异或:两对应的二进位相异时,结果为1
a 0011 1100
b 0000 1101
二进制结果 0011 0001
十进制结果 49
'''
fmt.Println(a ^ b)
'''
<< 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0
a 0011 1100
a << 2 1111 0000
十进制结果 240
'''
fmt.Println(a << 2)
'''
>> 右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数
a 0011 1100
a >> 2 0000 1111
十进制结果 15
'''
fmt.Println(a >> 2)(6) 键盘录入Scanf
可查看fmt包下的相关介绍。
package main
import "fmt"
func main() {
// 键盘录入值
var age int
var name string
fmt.Println("请录入学生的年龄:")
// 将age的地址传递给该函数,函数扫描输入传递给该地址
num1, _ := fmt.Scanln(&age) // 录入数据式类型应该匹配,底层会自动判别
fmt.Println("获取到的输入:", num1)
fmt.Printf("输入的类型:%T\n", age)
fmt.Println("输入的值:", age)
fmt.Println("请录入学生的姓名:")
// 将age的地址传递给该函数,函数扫描输入传递给该地址
num2, _ := fmt.Scanln(&name)
fmt.Println("获取到的输入:", num2)
fmt.Printf("输入的类型:%T\n", name)
fmt.Println("输入的值:", name)
// 方式2:
var age2 int
var name2 string
var score float32
var isVip bool
fmt.Println("请按照 “年龄-姓名-成绩-是否是VIP” 输入学生 年龄、姓名、成绩以及是否是VIP!")
fmt.Scanf("%d %s %f %t", &age2, &name2, &score, &isVip)
fmt.Println("输入学生信息为:年龄-", age2, ";姓名-", name2, ";成绩-", score, ";是否是VIP-", isVip)
}3.流程控制与函数
3.1流程控制
(1) 分支结构
package main
import "fmt"
func main() {
// 单分支结构
// if (3 > 2) { go语言建议不写括号,简洁
// fmt.Println("3>2")
// }
if 3 > 2 {
fmt.Println("3大于2")
}
//双分支
if 5 == 6 {
fmt.Println("5等于6")
} else {
fmt.Println("5不等于6")
}
//多分支
if 10 < 5 {
fmt.Println("10小于5")
} else if 10 < 7 {
fmt.Println("10小于7")
} else if 10 < 10 {
fmt.Println("10小于10")
} else if 10 < 11 {
fmt.Println("10小于11")
} else {
fmt.Println("10很大")
}
//switch 多分支
a := 0001
switch a { // 这里a可以是表达式比如 a++,或者有返回值的函数
case 0001: // case后值得类型必须和表达式得值类型一样,也可以是表达式,而且可以包含多个表达式
fmt.Println("第一位为零")
// break case后不再需要带break
case 0010:
fmt.Println("第二位为零")
case 0100:
fmt.Println("第三位为零")
fallthrough //表示穿透,需要继续进行下一个case
case 1000:
fmt.Println("第四位为零")
default:
fmt.Println("全为零")
break
}
}(2) 循环结构
package main
import (
"fmt"
)
func main() {
// 循环结构
for i := 0; i < 10; i++ {
fmt.Print("\t", i)
}
fmt.Print("\n")
// for循环的初始语句和迭代语句可以都不写,变成类似while结构
j := 100
for j > 0 {
j -= 10
fmt.Print("\t", j)
}
fmt.Print("\n")
/*
for true {
死循环
}
*/
// 键值循环
lists := []int{1, 2, 3, 4}
for index, value := range lists {
fmt.Printf("下标%d的元素为:%d\n", index, value)
}
s := "我是中国人"
// 使用普通for循环
// for i := 0; i < len(s); i++ {
// fmt.Printf("%c\t", s[i])
// }
// 上述进行遍历时是按照字节一个字节一个字节进行遍历,
// 当出现中文时,unicode编码占用四个字节就会出现乱码
for _, c := range s {
fmt.Printf("%c\t", c)
// fmt.Print(unsafe.Sizeof(c))
}
// for range lists { //可以直接进行循环
// fmt.Print("元素\t")
// }
/*
0 1 2 3 4 5 6 7 8 9
90 80 70 60 50 40 30 20 10 0
下标0的元素为:1
下标1的元素为:2
下标2的元素为:3
下标3的元素为:4
我 是 中 国 人
*/
}(3) 控制流程 关键字
-
break: 跳出本层循环,
-
continue : 本轮循环碰到continue结束本次循环,直接跳到下次循环
-
goto:直接跳到指定行执行,不建议使用
-
return: 直接跳出当前函数
3.2函数
函数的定义语法,函数不支持重载
func functionName(parameter1 type1,parameter2 type2...) returnType{
// 函数逻辑
return returnType
}-
参数:可以是值传递也可以是引用传递。另外go语言也支持可变参数传递
-
返回值:返回值可以是单个的,也可以是多返回值
-
一等公民:go语言中的函数作为一等公民可以被当作变量一样被传递,被赋值、被当作参数传递给函数、被当作返回值返回
-
函数名:函数名首字母不能是数字,若是大写字母可以被外部包引用,若是小写则是私有的不能被外部引用
函数作用:提高代码的复用性
package main
import "fmt"
func main() {
// 求和函数
a := 10
b := 19
fmt.Println(sum(a, b))
fmt.Println("===========")
//交换两数需要传递引用类型
n1 := 10
n2 := 80
fmt.Printf("调用函数前 a:%d \t b:%d \n", n1, n2)
exchange(&n1, &n2)
fmt.Printf("调用函数后 a:%d \t b:%d \n", n1, n2)
fmt.Println("===========")
l, s := multSum(1, 2, 4, 5, 6)
fmt.Println("共有:", l, "个数;\t 总和:", s)
myfunc("占山", "为王", 12, 22, "李四")
fmt.Println("===========")
fun := myfunc
fmt.Printf("fun对应的类型%T,以及函数对应的类型:%T\n", fun, myfunc)
reFunc := feedBack(100, callFunc)
reFunc()
fmt.Println("===========")
// 起别名
type myInt int
var x1 myInt = 10
var x2 int = 10
// fmt.Println("x1==x2?",x1==x2)
fmt.Println("x1==x2?", x1 == myInt(x2))
type myfunction func(string, ...interface{})
var myfunct myfunction = callFunc
feedBack(100, myfunct)()
}
// 对返回值直接命名
func sum(x int, y int) (sum int) {
sum = x + y
return
}
func exchange(num1 *int, num2 *int) {
temp := *num1
*num1 = *num2
*num2 = temp
}
func multSum(Samples ...int) (int, int) {
sum := 0
l := 0
for k, value := range Samples {
l++
sum += value
fmt.Printf("第%d个元素值:%d\n", k, value)
}
return l, sum
}
// 任意参数的传递
func myfunc(args ...interface{}) {
for key, value := range args {
fmt.Println("======", key, "\t", value, "=====")
}
}
// 一等公民
func feedBack(inNum int, call func(string, ...interface{})) func() {
// 返回一个匿名函数
return func() {
outNum := float32(inNum + 10)
call("传递输入值:%f,类型:%T", outNum, outNum)
}
}
func callFunc(formatS string, li ...interface{}) {
fmt.Printf(formatS, li[0], li[1])
}封装函数集合时,导包注意事项:
-
go文件的package声明原则上需要和go文件所在目录同名
-
引入包的过程:
1.先创建项目 go mod init moduleName
2.import “包所在的目录/包”
-
一个目录下不能有重复的函数名
-
一个目录下的go文件归属一个包
-
包的底层:
1.在程序层面,所有报名相同的源文件组成的代码块
2.在源文件层面 指的是文件夹
-
导入的包在使用时可通过别名进行使用
-
init函数:程序执行前的初始化函数,执行顺序:
初始化导入的包(包括初始化包里面的变量函数)-----》初始化包作用域变量-----》init函数------》main函数
package main
import (
u "demo02/utils"
f "fmt"
)
var T1 func() = myFunc
var T2 int = myFunc2()
func myFunc() {
f.Println("函数执行了")
}
func myFunc2() int {
f.Println("函数执行了,返回10")
return 10
}
// 该函数会在所有包执行开始前被调用,通常用于注册程序所需要的依赖。如mysql注册和配置文件加载
func init() {
f.Println("init函数被执行了!")
}
func main() {
f.Println("main函数被执行了!")
u.GetInfo()
// 匿名函数,被定义时就被调用
sum := func(a int, b int) int {
return a * b
}
f.Println(sum(99, 9))
func() { // 形参是空的,返回值也是空
f.Println("匿名函数执行===")
}() //实参也是空
}闭包:匿名函数+外部数据
package main
import "fmt"
/*
闭包产生的条件:
1.在函数A直接或者间接返回一个函数B
2.B函数内部使用着A函数的私有变量
3.A函数要被调用且由变量接收着B形成闭包
闭包的优点:
1.延长了变量的声明周期,闭包允许函数捕获外部作用域的变量,形成一个封闭的环境,函数执行
空间不销毁,变量也不会销毁
2.保护私有变量,通过闭包我们可以访问函数的私有变量,同时保证函数的私有变量不会被外界访问
3.延迟执行,闭包可以用于延迟执行一些操作,使其在某一个特定时刻执行。需要函数执行后再执
行某些操作时非常有用
4.闭包可以用作回调函数,将特定的行为传递给其他函数。
闭包的缺点:
1.资源泄露,闭包捕获大量外部资源时,或者长时间不释放,会造成内存泄漏等问题
2.性能损耗,闭包的外部资源可能需要在内存堆上进行分配,因此会导致内存分配和垃圾回收等性能消耗
3.代码可读性,使用复杂的闭包可能降低代码的可读性
*/
func getMethod() func(int) int {
// 闭包所需的外部资源或者称作环境
sum := 0
// 闭包所需要的函数
return func(i int) int {
// 对外部资源进行处理管理
sum += i
fmt.Println("sum:", sum)
return sum
}
}
func main() {
// 调用getMethod函数,将返回值赋值给f,随后结束getMethod()方法
// 但是返回值中包含sum局部变量,而被封装至匿名函数中
f := getMethod()
f(1) // 1
f(2) // 3
// 重新返回一个匿名函数并附带所需要的外部资源
f1 := getMethod()
f1(1) //1
f1(2) //3
}defer关键字:
声明延迟函数,能够在创建资源之后及时释放资源,会将defer声明的语句或者函数放到当前函数的栈中。
当程序执行一个函数时,会将函数的上下文(输入参数、输出参数、返回值等)作为栈帧放在程序内存的栈中,当函数执行完之后,设置返回值,然后返回调用方,此时栈帧已经退出栈,函数才算真正的执行完成。或者异常中断之后。而defer声明过的语句或者代码片段会在return 语句之后或者函数结束处执行,遵循先声明后执行的原则。另外带有return语句的函数,defer需要声明在return语句之前。
package main
import "fmt"
func test1() {
fmt.Println("执行6==")
defer fmt.Println("执行4==")
return
}
// defer函数的传递参数在被定义时就已经明确,无论传入的时变量还是语句还是函数,在声明时就被计算确定,
// 随后头插法将该_defer结构体(函数栈帧)插入链表,在最后结束时再从链表头取出延迟结构体执行。
func test2() (i int) {
i = 0
defer fmt.Println("i:", i) // 被计入defer表时是0,取出表时仍然是0
i++
return
}
func main() {
//defer 关键字
defer fmt.Println("执行1==")
defer fmt.Println("执行2==")
test1()
defer fmt.Println("执行3==")
defer fmt.Println(test2())
}
常用的系统函数:
统计字符串的长度:len(str)
字符串的遍历函数:r := []rune(str) rune是int32的别名
字符串转整数:num,err := strconv.Atoi("1234")
整数转字符串:str := strconv.Itoa(1234)
查找子串是否在字符串中: b := strings.contains("golang","go")
统计字符串有几个子串:n = strings.Count("golang","g")
不区分大小写的字符串比较: b := strings.EqualFold("g","G")
返回子串在字符串第一次出现的索引值,没有返回-1:strings.Index("golang","an")
替换字符串的某些子串:strings.Replace("golanggood","go","do",n)
切割字符串:strings.Split("go-go-goo","-") 返回切割数组
字符串大小写切换:strings.ToLower() strings.ToUpper()
字符串去除左右两边的空格:strings.TrimSpace()
获取当前时间:time.Now() 返回Time结构体,Time结构体包含一些方法可以用于获取具体的成员变量
builtin包下有很多内置的函数 :
package main
import (
"fmt"
"strconv"
"strings"
"time"
"unsafe"
)
func main() {
// 常用的字符串命令
s1 := "zhangsan"
s2 := "中国二年"
s3 := []byte{}
fmt.Println(len(s1)) //8 英文采用ASCLL编码 每个字母占用一个字节
fmt.Println(len(s2)) //12 中文每个字符占用三字节
fmt.Println(unsafe.Sizeof(s2)) //16 这里由两个值决定了16,8字节的地址和8字节的长度
fmt.Println(unsafe.Sizeof(s3)) //24 这里由于切片的数据结构决定,首元素地址、切片长度、切片容量
fmt.Println([]rune(s1)) // 对字符串进行遍历返回切片
fmt.Println(strconv.Atoi("123")) // 将字符串装成整数
fmt.Println(strconv.Itoa(123)) // 将数字转成字符串
fmt.Println(strings.Contains("golang", "go")) // 查找字符串是否包含子串
fmt.Println(strings.Count("anbdhskjdfhj", "j")) // 查找字符串包含几个子串
fmt.Println(strings.EqualFold("Go", "gO")) //不区分大小比较字符串是否相等
fmt.Println(strings.Index("asdfghjkl", "df")) //返回子串第一次出现的下标
fmt.Println(strings.Replace("golanggood", "go", "do", -1)) //替换字符串中的某些字串
fmt.Println(strings.Split("go-go-do-good", "-")) //切割某字符串返回数组
fmt.Println(strings.ToLower("HJjkk")) // 字符串转小写
fmt.Println(strings.ToUpper("HJjkk")) //字符串转大写
fmt.Println(strings.TrimSpace(" hdghkd ")) //去除左右两边的字符空格
fmt.Println(time.Now()) //获取当前时间,返回Time结构体
fmt.Println("======================")
// 特别注意rune,作为int32的别名使用。常用统计包含中文字符的字符串长度和字符串的截取
s4 := "hhhh中国"
fmt.Println(len(s4)) //10 占用10个字节
fmt.Println(len([]rune(s4))) //6 总共6个字符
fmt.Println(string([]rune(s4)[2:5])) //hh中 截取下标2、3、4的字符
fmt.Println("======================")
// builtin包的内置函数
// new用于分配内存使用,主要用于分配值类型(int系列、float系列、bool、string、数组和结构体)
ptr := new(int)
*ptr = 10
fmt.Println(*ptr)
fmt.Printf("ptr类型:%T,ptr的值:%v,关联的值是:%d\n", ptr, ptr, *ptr)
// make用于分配内存使用,常用于切片、map和管道的分配
ptr1 := make([]int, 9, 10)
ptr1[0] = 100
fmt.Println(ptr1)
}错误处理:不会轻易的结束程序运行
错误处理/错误捕获机制:使用defer+recover处理
// 使用panic抛出一个异常
func triggerPanic() {
panic("a problem occurred")
}
// 使用recover捕获并处理异常
func recoverFromPanic() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered from a panic", r)
}
}()
triggerPanic()
}自定义错误:使用errors报下的new函数自定义错误
// 函数可能会返回错误
func mightFail() error {
// 如果发生错误,返回一个错误信息
if someCondition {
return errors.New("some error message")
}
return nil // 表示没有错误发生
}
// 在函数调用中检查错误
if err := mightFail(); err != nil {
fmt.Println("Error:", err)
}4.数组、切片和Map
4.1数组
package main
import (
"fmt"
)
func main() {
// 数组定义
/*
var 数组名 [数组大小]数据类型
数据名 := [数组大小]数据类型{num1,num1……}
var 数组名 = [数组大小]数组类型{num1,num2,num3,……}
*/
var n1 = [3]int{1, 2, 3}
var n2 = [...]int{1, 2, 3, 4, 5}
var n3 = [...]int{2: 4, 3: 9} // 下标2的值为4,下标3的值为9,未定义的值默认0
fmt.Println(n1)
fmt.Println(n2)
fmt.Println(n3)
nums1 := [5]int8{1, 2, 3, 4, 5}
for i := 0; i < len(nums1); i++ {
fmt.Print(nums1[i], "\t")
}
fmt.Print("\n")
test(nums1) //nums1的值并未改变,说明调用传递给函数的的参数是值 不是引用
for _, value := range nums1 {
fmt.Print(value, "\t")
}
fmt.Print("\n")
test2(&nums1) //nums1的值并改变,说明调用传递给函数的的参数是引用
for _, value := range nums1 {
fmt.Print(value, "\t")
}
fmt.Print("\n")
fmt.Println(nums1)
fmt.Printf("数组的类型:%T\n", nums1) //长度也属于数组的类型的一部分
fmt.Printf("数组的地址:%p\n", &nums1)
fmt.Printf("数组首元素的地址:%p\n", &nums1[0])
fmt.Printf("数组首元素的地址:%p\n", &nums1[1])
// 二维数组
var nums2 [5][6]int
for i := 0; i < len(nums2); i++ {
nums2[i] = [6]int{1, 2, 3, 4, 5, 6}
}
fmt.Println(nums2)
//二维数组的遍历
su := 0
for _, v := range nums2 {
for _, t := range v {
su++
fmt.Print(t, "\t")
}
}
fmt.Print("\n")
fmt.Print(su, "\n")
}
func test(arr [5]int8) {
arr[0] = 10
}
func test2(arr *[5]int8) {
arr[0] = 10
}
4.2切片
对数组连续片段的引用
package main
import "fmt"
func main() {
// 定义一个数组
nums1 := [5]int{1, 2, 3, 4, 5}
// 切片
sp1 := nums1[2:4]
var sp2 []int = []int{1, 2, 3}
fmt.Printf("sp1的数据类型:%T\n", sp1)
fmt.Printf("sp2的数据类型:%T\n", sp2)
fmt.Printf("sp1的数据:%d\n", sp1)
fmt.Printf("sp1的数据长度:%d\n", len(sp1))
fmt.Printf("sp1的数据容量:%d\n", cap(sp1))
/*
切片结构体:
1.切片首元素地址
2.切片长度
3.切片容量
*/
fmt.Printf("sp1的数据地址:%p\n", sp1) //切片属于引用类型 可以直接使用%p进行取地址
fmt.Printf("nums1的数据地址:%p\n", &nums1) // 数组属于值类型,需要使用&去取地址
// 改变切片sp1的值,nums1的值也改变
sp1[1] = 10
fmt.Printf("nums1的数据:%d\n", nums1)
// 使用make()进行切片创建,使用append()函数对切片末尾添加元素
sp3 := make([]int8, 0, 10)
sp3 = append(sp3, 8, 9)
sp3[1] = 10
fmt.Printf("切片sp3的类型:%T\n", sp3)
fmt.Printf("切片sp3数据:%v\n", sp3)
// 切片遍历同数组遍历一样
for i := 0; i < len(sp1); i++ {
fmt.Printf("第 %d 个元素值:%d\n", i+1, sp1[i])
}
for index, value := range sp1 {
fmt.Printf("第 %d 个元素值:%d\n", index+1, value)
}
}注意:使用for range进行遍历时,其value值只是对元素的复制,因此不能修改值。
4.3映射(Map)
包含key-value键值对的集合,且key-value是无须的
key通常为int、string等基本类型,指针也可以作为key,另外接口、数组也可以作为key,只要是可比较的且不能改变的都能作为key
注意:只声明了map,但是内存中没有分配实际地址,因此不能使用
package main
import "fmt"
func main() {
// 映射(map)
// var map1 map[int]string // 这里只声明了map,但是内存中没有分配实际地址,因此不能使用
var map1 map[int]string = map[int]string{} // 需要进行申请
map2 := map[int]int{1: 2} //方式1
map3 := make(map[string]int) //方式2
map4 := map[[2]int]string{ //方式3
{1, 2}: "张三",
{2, 3}: "李四",
}
fmt.Println("map4值:", map4)
fmt.Println("map3值:", map3)
fmt.Println("map2值:", map2)
// 新增键值对
map1[1] = "张三" // 新增键值对1:"张三"
// 删除键值对
delete(map2, 1)
// 清空
map3 = make(map[string]int) // 直接清空
// 访问键值对
value, ok := map1[1]
if ok {
fmt.Println("map1[2]的值:", value)
} else {
fmt.Println("不存在map1[2]的值")
}
fmt.Println("map1[2]的值:", map1[2]) // 当不存在时使用0作为默认值
fmt.Println("map4长度:", len(map4))
// 对数组进行遍历
s := "kjasdghkiqwe"
fmt.Println(getCounts(s))
}
func getCounts(s string) map[string]int {
res := make(map[string]int, 0)
for _, char := range s {
res[string(char)]++
}
return res
}5.Golang的“面向对象”
go语言使用结构体(struct)和接口(interface)作为对象,因此go语言基于结构体和接口实现面向对象,go语言不是面向对象语言,也不是面向过程语言,只是支持面向对象。
目的:易于数据的管理和维护,代码简洁性。
5.1结构体
结构体定义与使用:
package main
import (
"demo01/model"
"fmt"
)
// 定义一个结构体
type Address struct {
city string
}
type Student struct {
name string
age int
addr Address
}
// 带有引用类型的声明都是传递地址,不带引用类型都是值传递
func (s Student) test1() {
fmt.Println("学生测试一===")
}
func (s Student) test2() {
s.name = s.name + "学生"
}
func (s *Student) test3() {
s.addr.city = s.addr.city + "城市"
}
func test4(s Student) {
s.addr.city = s.addr.city + "城市"
s.age += 5
}
func main() {
// 实例化一个结构体
t1 := Student{"张三", 18, Address{"安徽合肥"}}
fmt.Println("0t1: ", t1)
t1.test1()
fmt.Println("1t1: ", t1)
t1.test2()
fmt.Println("2t1: ", t1)
t1.test3() //底层实现 (*t1).test3()
fmt.Println("3t1: ", t1)
test4(t1)
fmt.Println("4t1: ", t1)
t1.name = "李四"
fmt.Println("5t1: ", t1)
var t2 *Student = new(Student)
(*t2).name = "王五"
// go语言提供了简化的复制方式,底层自动把t2转换成(*t2)
t2.age = 26
t2.addr.city = "太原市"
fmt.Println("0t2: ", t2)
fmt.Println("0t2: ", *t2)
// 使用外部包导入
teacher1 := model.NewTeacher("张三", 68)
teacher1.Show()
// fmt.Println(&teacher1)
}model下的包:
package model
import "fmt"
/*
封装的实现:某些变量采用首字母采用小写(private),某些变量首字母采用大写(public)
*/
/*
使用方法实现 工厂模式,类似构造函数
*/
type teacher struct {
name string
age int
}
// 注意这里返回的是引用,teacher的引用而不是值类型,只有返回引用类型才能算是工厂模式
func NewTeacher(name string, age int) *teacher {
// return &teacher{
// name,
// age,
// }c 这里会有赋值顺序的限制
return &teacher{
age: age,
name: name,
}
}
// 这里的Show首字母必须大写,否则外界无法使用
func (t *teacher) Show() {
fmt.Println("当前实列数据:", t)
}
// 当结构体实现String()方法时,Println时会自动调用String方法
func (t teacher) String() string {
return fmt.Sprintf("老师的信息包括 姓名:%v; 年龄:%v", t.name, t.age)
}继承注意事项:
显示嵌入:外部实列dog需要通过dog.A来访问结构体animal的变量,如果animal结构体内的变量首字母是大写,则在由于外部dog实列能访问到A,也就是能访问到A的对外可见变量(首字母大写),如果A改成a则,外部dog实列不管animal中的变量首字母是否大写都不能访问到animal内嵌结构体,这里与声明animal的大小写无关。
type dog struct {
A animal
}
匿名嵌入:这种嵌入方式更像继承,animal所有的变量都将是Cat的一部分,外部Cat实例可以直接访问animal的可见变量
type Cat struct {
animal
}
另外。go语言支持多继承,但是可能导致代码混乱,当出现不同父类的包含相同命名的变量时,可使用 ‘父类.相同变量’ 区分。匿名嵌入的结构体还支持基本数据类型
type A struct{
a int
b string
int32
}
type B struct{
c int
b string
int32
}
type C struct{
B
A
string
}
c := C{B{1,"b",64},A{12,"张",32},"张三"}
fmt.Println(c.string, c.B.b, c.A.int32)5.2接口
目的:为了定义规范、定义规则或者定义某种能力
1.一个结构体可以实现多个接口
2.接口本身不能实例化,但是可以指向实现了接口的结构体实列
3.只要是自定义数据类型都可以实现接口
4.接口之间也可以继承,一个接口可以继承多个接口
5.接口是一个引用数据类型
举个列子:
A接口: a,b方法
B接口:a,b方法
C结构体实现了a,b方法,则可以说C结构体实现了A接口和实现了B结构,所有需要A,B接口能力规范或者 规则的函数,C都能够作为参数传入,执行A,B所具备的方法。
package main
import (
"demo02/model"
"fmt"
)
type A interface {
a()
}
type B interface {
a()
}
type Ainterface interface {
A
B
Ainter()
}
type s struct{}
func (s s) a() {
fmt.Println("实现了a接口的a函数")
}
func (s s) Ainter() {
fmt.Println("实现了Ainter接口的Ainter函数")
}
func main() {
// 使用工厂创建类
Af := model.AnimalFactory{}
A1 := Af.CreateObject("王五", 29)
A1.AnimalRun()
D1 := model.DogFactory{}.CreateObject("李四", 10)
D1.A.AnimalRun() // 由于dog结构体采用显示嵌入,需要通过A来访问animal的实现接口。
// fmt.Println(D1)
Cf := model.CatFactory{}
C1 := Cf.CreateObject("张三", 10)
// 接口可以指向实现了接口的结构体实列,但是自身不能实列化
var r model.Run = C1
r.AnimalRun()
sport(C1)
fmt.Printf("c1的类型:%T", *C1)
// 接口的继承
var i Ainterface = new(s)
i.a()
i.Ainter()
var b B = new(s)
b.a()
var a A = new(s)
a.a()
// 多态数组,可以定义一个空接口,通过空接口可以实现多种数据类型的融合数组
rs := [3]model.Run{}
rs[0] = *model.AnimalFactory{}.CreateObject("动物", 0)
rs[1] = *model.CatFactory{}.CreateObject("狗", 1)
fmt.Println(rs)
var mult []interface{} = []interface{}{"zhangsan", 10, 'c'}
fmt.Println(mult)
}
// 函数用于接收具备特定能力(实现了接口的结构体)的变量r参数,传入的参数是实现了接口的结构体(体现出多态)
// 多态参数
func sport(r model.Run) {
r.AnimalRun()
}
model包:
package model
import "fmt"
type Run interface {
AnimalRun()
}
type Factory interface {
CreateObject(name string, age int) *animal
}
type animal struct {
name string
age int
}
/*
以下是给结构体起别名 不同于继承
type dog animal
type cat animal
*/
type dog struct {
A animal
}
type cat struct {
animal
}
// 实现接口所有的方法
func (a animal) AnimalRun() {
fmt.Printf("动物%v在跑:\n", a.name)
}
// 定义一个狗的实现接口工厂
type DogFactory struct{}
func (d DogFactory) CreateObject(name string, age int) *dog {
return &dog{animal{
name,
age,
},
}
}
type CatFactory struct{}
func (c CatFactory) CreateObject(name string, age int) *cat {
return &cat{
animal{
name,
age,
},
}
}
type AnimalFactory struct{}
func (a AnimalFactory) CreateObject(name string, age int) *animal {
return &animal{
name,
age,
}
}
5.3断言
目的:用于判断某个接口实列是否是是它的某一个类型 value,ok := element.(T)
语法含义:当element(变量)是T(实现了element接口的结构体)类型时,将转换成T类型并赋值给value,并把ok赋值成true
package main
import (
"fmt"
)
type i interface {
iF()
}
type c struct {
name string
}
func (c c) l() {
fmt.Println("结构体c独有的函数")
}
type d struct {
name string
}
func (d d) p() {
fmt.Println("结构体d独有的函数")
}
func (d d) iF() {
fmt.Println("d结构体实现了i接口")
}
func (c c) iF() {
fmt.Println("c结构体实现了i接口")
}
func doIt(i i) {
i.iF()
v, ok := i.(c)
if ok {
v.l()
}
}
func main() {
// 判断接口实列是否是某一个类型
c1 := c{"展示噶"}
var r i = c1 // 将c1向上转型为接口实列
v, ok := r.(c) //判断接口实列是否是d类型,如果是的化就将接口实列转换成d的实列
if ok {
fmt.Printf("r是c类型,值为:%v\n", v)
fmt.Printf("v的类型:%T\n", v)
} else {
fmt.Print("r并不是c结构体的实列")
}
var s interface{} = "结婚三大件哈桑"
_, isString := s.(string)
fmt.Println("是否是字符串:", isString)
// 使用switch进行判别
// type是go语言的关键字,switch type固定用法
switch r.(type) {
case c:
c1 := r.(c)
c1.l()
case d:
d1 := r.(d)
d1.p()
}
}注意:数组和结构体都是值类型,而切片、管道、指针、映射、接口和函数都是引用类型
package main
import "fmt"
func Qie(a []int) {
a[0] = 10
}
func St(s test) {
s.x = 10
}
type test struct {
x int
y int
}
func main() {
b := []int{1, 2, 3}
fmt.Println(b)
Qie(b)
fmt.Println(b)
t := test{1, 2}
fmt.Println(t)
St(t)
fmt.Println(t)
}6.文件操作
文件操作,os包下的type File结构体,
一般使用os包下的Open函数打开只读文件,当要写入文件时可采用os包下的OpenFile函数,os报下的File结构体,实现了io包下的一些函数接口,file结构体本身也具有一些函数,Read函数和Write函数,另外bufio包下还有一些关于利用缓存进行读写的操作。
package main
import (
"bufio"
"fmt"
"io"
"os"
"syscall"
)
func main() {
//os
// 使用os包进行读写
// 使用Open打开的文件一般只用于读取,需要写入时还需要OpenFile
f, err := os.Open("./test.txt")
if err != nil {
fmt.Print("打开文件失败:", err)
}
readData := make([]byte, 24, 24)
n, reErr := f.Read(readData)
if reErr != nil {
fmt.Print("读取文件失败:", err)
}
fmt.Printf("总共读取%d个字节数据:%q\n", n, readData)
f.Close()
// io/ioutil
// 使用os包ReadFile进行读写,不需要Open再Close
// re, err := ioutil.ReadFile("./test.txt") //ioutil已经被弃用
re, _ := os.ReadFile("./test.txt")
fmt.Printf("总共读取%d个字节数据:%q\n", len(re), re)
fmt.Printf("总共读取%d个字节数据:%q\n", len(re), string(re))
// bufio
// 当文件较大时,可以采用带缓冲的,使用bufio,带缓冲的io留进行读写
bufOut := []string{}
readerIn, _ := os.Open("./test2.txt")
defer readerIn.Close()
bfRead := bufio.NewReader(readerIn)
// 当系统无法读入更多内容时候,会返回io.EOF
for line, _, errBuf := bfRead.ReadLine(); errBuf != io.EOF; line, _, errBuf = bfRead.ReadLine() {
fmt.Printf("line的类型是%T,内容是:%s\n", line, string(line))
bufOut = append(bufOut, string(line))
}
// os包
//使用os包下的OpenFile打开一个用于写入的文件,再使用io流进行写入,这里的后面参数可以参考指导文献
wF, errF := os.OpenFile("./test3.txt", syscall.O_WRONLY|os.O_APPEND|os.O_CREATE, 0666)
if errF != nil {
fmt.Println(errF)
}
defer wF.Close()
// 直接写入
// fmt.Println(bufOut)
// for _, value := range bufOut {
// wF.WriteString("\n")
// wF.WriteString(value)
// }
wbF := bufio.NewWriter(wF)
fmt.Println(bufOut)
for _, value := range bufOut {
wbF.WriteString("\n")
wbF.WriteString(value)
// wbF.Flush() // 将缓冲区的内容写入到底层的io.Writer,刷新缓冲流之后才算写成功
}
wbF.Flush() // 将缓冲区的内容写入到底层的io.Writer,刷新缓冲流之后才算写成功
}7.协程和管道
7.1前置概念
-
CPU核心:计算机中央处理的一个单元,能够执行计算机程序指令,CPU核心包括: 算数逻辑单元(负责执行所有的算数逻辑运算)、寄存器(数据在CPU的临时中转站)、控制单元(负责协调控制指令执行过程)、缓存(提供寄存器和内存之间临时存储,减少内存访问次数)
-
单核CPU:单个核心的中央处理器,只能进行并发。
-
多核CPU:多个核心的CPU,并行处理的关键。
-
并发:同一时间段内,多个任务在轮流使用单个计算资源(通常指单核CPU),宏观上同时执行,微观上顺序执行
-
并行:一组程序或者任务按照独立异步的速度执行,多个任务有多个计算资源承担(多核CPU或者多CPU),宏观同时执行,微观上也是同时执行。
-
程序:为了完成某些任务,使用机器语言编写的一组代码的集合,程序是静态的。
-
进程:进程是指正在运行的程序,进程是资源分配的基本单位,操作系统会为每个进程实时分配一些资源比如内存、CPU和磁盘读写的通道等。
-
线程:线程是细分的进程,一个进程同一时间需要完成多个任务执行多段代码,每段代码就代表一个线程,另外说明该进程是支持多线程的。也是后端程序需要的能力(并行),线程是由操作系统进行调度的。
-
内核态:内核态是操作系统中的一种特权状态或者运行模式,在内核态下,操作系统拥有最高权限和访问资源的能力,可以执行特权指令或者直接访问硬件资源。内核态下操作系统能够对资源进行分配、管理、释放和调度。
-
用户态:用户态是操作系统中的一种较低特权级别的一种状态,这种状态下,操作系统不能使用特权指令,也不能进行CPU状态改变,只能访问自己的内存资源。不能直接访问一些硬件资源。当程序需要访问一些资源或者执行特权指令时,需要通过系统调用请求操作系统内核来完成这些操作。系统调用是一种特殊的函数调用,它会将应用程序从用户态切换至内核态,并把控制权交给操作系统内核,内核态下的操作系统会执行中断程序,并将执行的结果返回给应用程序,完成操作之后,内核会将控制权交还给应用程序,内核态切换成用户态。
-
进程切换:进程切换包括进程调度和上下文切换,用于在不同进程之间进行CPU的调度和分配,当一个进程运行时,它占用了CPU和其他资源。当操作系统需要执行其他进程时,就会发生进程切换,进程切换需要保存当前进程的上下文信息和恢复调度构建下一个进程所需的上下文信息,上下文信息包括:CPU寄存器、程序计数器、内存地址映射表、进程控制块信息和栈指针等。
-
PCB:进程控制块,操作系统为了方便进程管理,为每个进程构建的数据结构。
-
线程切换:为了减少进程切换时上下文信息量,将进程再切分成独立的任务就是线程进行调度,进程切换时只要需要切换内存寄存器,线程控制块信息等,不需要切换完整的进程地址映射。
-
栈:线程独有的,每个线程被创建时都会获得一个独立的栈空间,用于存放局部变量、函数参数和返回地址等,栈具有先进后出的特点,主要用于函数调用时的上下文管理。每个线程的栈空间有固定大小,超过这个大小就会导致栈溢出。
-
堆:堆是进程的所有线程共有的空间,通常用于动态内存分配,不同线程可以并发的访问堆,因此堆的访问需要同步控制。
-
协程:协程是微线程,又称轻量级线程,其调度在用户态上运行,协程执行时能够保持当前的上下文(如局部变量和执行点),并在适当的时候挂起,稍后从挂起的地方继续执行。因为不涉及内核资源,协程切换时上下文信息切换的较少。协程占用的内存比线程少,因此相同的条件下能够运行更多的协程。
-
Go语言的协程调度方式:Go的协程调度是非抢占式调度,基于协作的调度模型,称为M:N调度(多个协程被多个OS线程管理)
7.2 Go语言的协程
package main
import (
"fmt"
"sync"
"time"
)
func worker(n int, w *sync.WaitGroup) {
defer w.Done()
for i := 0; i < 3; i++ {
time.Sleep(2 * time.Second)
fmt.Printf("hello worker %d\n", n)
}
}
func main() {
// 协程创建时使用的是外部变量的引用
for l := 0; l <= 5; l++ {
// fmt.Printf("当前值:%d; 其地址:%p\n", l, &l)
go func() {
fmt.Printf("当前值:%d; 其地址:%p\n", l, &l)
}()
}
// 最新版本中for循环进行了编译器优化,导致每次l都是不同的
// for l := 0; l <= 10; l++ {
// fmt.Printf("当前值==:%d; 其地址:%p\n", l, &l)
// }
// 但是在主程序中不存在这种
// s := 10
// fmt.Printf("当前值==:%d; 其地址:%p\n", s, &s)
// s++
// fmt.Printf("当前值==:%d; 其地址:%p\n", s, &s)
// 使用sync.WaitGroup进行线程的同步,防止主线程执行完之后直接结束程序
var w sync.WaitGroup
// 主协程启用一个工作者
w.Add(1)
worker(0, &w)
// 再同时创建五个工作者同时操作
for j := 1; j < 4; j++ {
w.Add(1)
go worker(j, &w)
}
w.Wait()
}注意:
-
Go语言的协程分主次,主协程执行完之后,就将终止程序的执行,可使用管道或者sync包结构体来同步
-
sync中的WaitGroup方法相当于操作系统中的PV操作
-
协程作用域:当协程使用外部变量时其使用的是外部变量的引用。与闭包一致
-
1.22版本之后for循环每次迭代会产生新的迭代变量,防止共享错误的问题。(以前版本中当引用迭代变量并进行操作时可能会导致其无法满足循环条件而继续工作)
-
当多个协程对共享资源进行访问时,会出现共享资源错乱的问题
package main
import (
"fmt"
"sync"
"time"
)
var gobalNum int = 0
func add(w *sync.WaitGroup) {
defer w.Done()
//
for i := 0; i < 3; i++ {
time.Sleep(1 * time.Second)
fmt.Printf("Add函数第%d轮取到gobalNum的值为:%d;其地址为%p\n", i, gobalNum, &gobalNum)
gobalNum = gobalNum + 1
fmt.Printf("Add函数第%d轮运算得到gobalNum的值为:%d;其地址为%p\n", i, gobalNum, &gobalNum)
}
}
func sub(w *sync.WaitGroup) {
defer w.Done()
for i := 0; i < 3; i++ {
time.Sleep(1 * time.Second)
fmt.Printf("Sub函数第%d轮取到gobalNum的值为:%d;其地址为%p\n", i, gobalNum, &gobalNum)
gobalNum = gobalNum - 1
fmt.Printf("Sub函数第%d轮运算得到gobalNum的值为:%d;其地址为%p\n", i, gobalNum, &gobalNum)
}
}
func main() {
// 创建一个sync.waitGroup防止主协程执行完就关闭程序
var w sync.WaitGroup
w.Add(2)
fmt.Printf("====初始gobalNum的值为:%d;其地址为%p\n", gobalNum, &gobalNum)
go add(&w)
go sub(&w)
w.Wait()
fmt.Printf("====结束gobalNum的值为:%d;其地址为%p\n", gobalNum, &gobalNum)
}
/*
====初始gobalNum的值为:0;其地址为0xc98400
Add函数第0轮取到gobalNum的值为:0;其地址为0xc98400
Add函数第0轮运算得到gobalNum的值为:1;其地址为0xc98400
Sub函数第0轮取到gobalNum的值为:0;其地址为0xc98400 <------------------
Sub函数第0轮运算得到gobalNum的值为:0;其地址为0xc98400 <------------------------错误
Sub函数第1轮取到gobalNum的值为:0;其地址为0xc98400
Sub函数第1轮运算得到gobalNum的值为:-1;其地址为0xc98400
Add函数第1轮取到gobalNum的值为:0;其地址为0xc98400 <-----------------
Add函数第1轮运算得到gobalNum的值为:0;其地址为0xc98400 <--------------------------错误
Sub函数第2轮取到gobalNum的值为:0;其地址为0xc98400
Sub函数第2轮运算得到gobalNum的值为:-1;其地址为0xc98400
Add函数第2轮取到gobalNum的值为:-1;其地址为0xc98400
Add函数第2轮运算得到gobalNum的值为:0;其地址为0xc98400
====结束gobalNum的值为:0;其地址为0xc98400
*/
解决办法:
-
使用sync.Mutex进行互斥访问共享资源
package main
import (
"fmt"
"sync"
"time"
)
var gobalNum int = 0
var lockgobalNum sync.Mutex
func add(w *sync.WaitGroup) {
defer w.Done()
//
for i := 0; i < 3; i++ {
time.Sleep(1 * time.Second)
lockgobalNum.Lock() // 加锁 <=========================================
fmt.Printf("Add函数第%d轮取到gobalNum的值为:%d;其地址为%p\n", i, gobalNum, &gobalNum)
gobalNum = gobalNum + 1
fmt.Printf("Add函数第%d轮运算得到gobalNum的值为:%d;其地址为%p\n", i, gobalNum, &gobalNum)
lockgobalNum.Unlock() //解锁 <=========================================
}
}
func sub(w *sync.WaitGroup) {
defer w.Done()
for i := 0; i < 3; i++ {
time.Sleep(1 * time.Second)
lockgobalNum.Lock() // 加锁 <=========================================
fmt.Printf("Sub函数第%d轮取到gobalNum的值为:%d;其地址为%p\n", i, gobalNum, &gobalNum)
gobalNum = gobalNum - 1
fmt.Printf("Sub函数第%d轮运算得到gobalNum的值为:%d;其地址为%p\n", i, gobalNum, &gobalNum)
lockgobalNum.Unlock() //解锁 <=========================================
}
}
func main() {
// 创建一个sync.waitGroup防止主协程执行完就关闭程序
var w sync.WaitGroup
w.Add(2)
fmt.Printf("====初始gobalNum的值为:%d;其地址为%p\n", gobalNum, &gobalNum)
go add(&w)
go sub(&w)
w.Wait()
fmt.Printf("====结束gobalNum的值为:%d;其地址为%p\n", gobalNum, &gobalNum)
}
/*
====初始gobalNum的值为:0;其地址为0x768400
Sub函数第0轮取到gobalNum的值为:0;其地址为0x768400
Sub函数第0轮运算得到gobalNum的值为:-1;其地址为0x768400
Add函数第0轮取到gobalNum的值为:-1;其地址为0x768400
Add函数第0轮运算得到gobalNum的值为:0;其地址为0x768400
Add函数第1轮取到gobalNum的值为:0;其地址为0x768400
Add函数第1轮运算得到gobalNum的值为:1;其地址为0x768400
Sub函数第1轮取到gobalNum的值为:1;其地址为0x768400
Sub函数第1轮运算得到gobalNum的值为:0;其地址为0x768400
Sub函数第2轮取到gobalNum的值为:0;其地址为0x768400
Sub函数第2轮运算得到gobalNum的值为:-1;其地址为0x768400
Add函数第2轮取到gobalNum的值为:-1;其地址为0x768400
Add函数第2轮运算得到gobalNum的值为:0;其地址为0x768400
====结束gobalNum的值为:0;其地址为0x768400
*/注意:
-
互斥锁Mutex的效率较低,用于读写次数不确定的场景
这里引入高效率锁 读写锁
-
RWmutex:读写锁常用读多写少的情况
在读的时候数据之间不产生影响,在写发生的时候才会产生影响
package main
import (
"fmt"
"sync"
"time"
)
// 定义一个共享的锁
// var lock sync.Mutex // 总共消耗: 789.1378ms
var lock sync.RWMutex // 总共消耗: 364.2697ms
// 构建一个waitGroup防止主程序结束
var mainWait sync.WaitGroup
// 读工作者的协程
func readWorker(n *int) {
defer mainWait.Done()
lock.RLock() // <========================RLock()=====================
fmt.Printf("n的值:%d\t", *n)
time.Sleep(10 * time.Millisecond)
lock.RUnlock() // <========================RUnLock()=====================
}
// 写工作者的协程
func writeWorker(n *int) {
defer mainWait.Done()
lock.Lock()
fmt.Print("对数据进行写\t")
*n = *n + 1
time.Sleep(100 * time.Millisecond)
lock.Unlock()
}
func main() {
// 统计程序运行时间,比较RWMutex和Mutex的性能差距
star := time.Now()
// 定义一个共享的资源
var gobalData int = 100
for i := 0; i < 30; i++ {
mainWait.Add(1)
go readWorker(&gobalData)
}
for i := 0; i < 3; i++ {
mainWait.Add(1)
go writeWorker(&gobalData)
}
mainWait.Wait()
final := time.Now()
consum := final.Sub(star)
fmt.Println("总共消耗:", consum)
}注意:
-
使用RLock()来区分是否是读操作,当发现是读操作时则不需要竞争性访问某些资源,当发现是写操作时则要互斥的访问某资源
-
耗时有差距的原因:在多核CPU比如说本机是8核CPU,同时运行了8个协程,当某一个时刻线程RLock()发现八个协程运行中都是进行读操作则协程之间可以并行的读取临界资源,当8个协程中有一个Lock(),则说明有一个协程是在修改临界区资源,则8个上锁的协程全部进行等待,等待Unlock()函数执行完,再进行判断
7.3管道
type hchan struct {
/* 实现缓冲区 */
/* 环形队列 */
qcount uint // 当前环形队列中元素个数
dataqsiz uint // 环形队列可存放元素个数 | 缓冲区长度
buf unsafe.Pointer // 环形队列开始指针
sendx uint // 写入的队列下标
recvx uint // 读取的队列下标
/* 类型信息 */
elemsize uint16 // 存储的元素大小
elemtype *_type // 存储的元素类型
closed uint32 // 管道关闭状态
/* 实现等待阻塞 */
/* 等待队列 */
recvq waitq // 等待读消息的协程队列
sendq waitq // 等待写消息的协程队列
/* 互斥锁 */
lock mutex // 互斥锁,chan 不允许并发读写
}概念:管道关键字为chan,分为有缓冲管道和无缓冲管道,主要用于协程并发,底层实现原理利用等待队列和环形队列。管道是线程安全的,多个协程访问管道时不会发生资源竞争。
作用:用于并发控制,且写入管道的数据都应该全部读完。
ch1 := make(chan int) //无缓冲管道
ch2 := make(chan int,2) //有缓冲管道
ch3 := make(chan any) //这里的any是interface{}的别名注意:
-
管道关闭之后就不能再往里面写入数据了。但是可以读取数据。读出得数据为0或者nil
-
到管道没有关闭时,此时管道为空,再取数据会发生死锁导致fatal err产生
package main
import "fmt"
func main() {
// 定义一个管道
var intChan chan int
// 不初始化的管道是无法使用。
intChan = make(chan int, 3)
fmt.Printf("管道的值:%v", intChan) //管道的值:0xc00010a080
// 向管道内存入数据
intChan <- 5
num := 20
intChan <- num
intChan <- 22
// intChan <- 10 存多了 fatal error: all goroutines are asleep - deadlock!
fmt.Printf("管的实际长度:%v,容量是:%v\n", len(intChan), cap(intChan))
// 从管道中取出数据
fmt.Println(<-intChan)
fmt.Println(<-intChan)
fmt.Println(<-intChan)
// fmt.Println(<-intChan) 取多了 fatal error: all goroutines are asleep - deadlock!
fmt.Printf("ch1管的实际长度:%v,容量是:%v\n", len(intChan), cap(intChan))
// 管道的关闭
ch2 := make(chan int, 3)
ch2 <- 9
ch2 <- 8
close(ch2)
// ch2 <- 5 // panic: send on closed channel
fmt.Println(<-ch2)
fmt.Println(<-ch2)
fmt.Println(<-ch2)
fmt.Println(<-ch2) //因为管道已经关闭且值也被取出来完了,随后再被取出来就是nil或者0
fmt.Printf("ch2管的实际长度:%v,容量是:%v\n", len(ch2), cap(ch2))
// 管道的遍历
ch3 := make(chan int, 6)
ch3 <- 1
ch3 <- 2
ch3 <- 3
ch3 <- 4
ch3 <- 5
// close(ch3) // 或者提前关闭管道
// 管道进行for-range时不再创建副本,直接取出管道内的值
for vs := range ch3 {
// 因此当管道内没有数据时,取管道数据的协程就会阻塞
if len(ch3) == 0 {
// 主线程进行管道取数据,数据已经取完,该协程阻塞,为防止主线程阻塞程序关闭,必须主动中断循环。
break
}
fmt.Println(vs)
fmt.Printf("ch3管的实际长度:%v,容量是:%v\n", len(ch3), cap(ch3))
}
defer func() {
if i := recover(); i != nil {
fmt.Println("报错:", i)
}
}()
fmt.Printf("ch3管的实际长度:%v,容量是:%v\n", len(ch3), cap(ch3))
}注意:
-
只有管道关闭时,取管道的协程才能收到false(在管道为空的时候)
-
管道进行for-range时不再创建副本,直接取出管道内的值
-
主线程进行管道取数据,数据已经取完,该协程阻塞,为防止主线程阻塞程序关闭,应该主动中断循环。
// 管道关闭&&管道为空&&协程阻塞 = false
_, ok := <-ch
// 管道为空&&协程阻塞 = fatal err 报致命错误
_, ok := <-ch 7.4协程和管道
特别注意:
-
管道如果没有关闭,进行空管道读取,超时之后会 报fatal err deadlock异常
-
只要管道最后带有关闭,依然会持续等待管道产生数据
-
管道如果没有关闭。进行持续的写入等待超时且没有读取到,协程也会报fatal err deadlock错
-
管道如果关闭,再进行写入时会 报panic错误
-
管道中没有数据时读取会返回默认值
-
使用range循环管道时,不关闭会导致deadlock错误
package main
import (
"fmt"
"sync"
"time"
)
// 消费者,每50毫秒了消费一个物品,消费100件
func Consumer(ch chan any, superVision *sync.WaitGroup) {
defer superVision.Done()
// for i := 0; i < 6; i++ {
// time.Sleep(500 * time.Millisecond)
// _, err := <-ch
// if err == false {
// fmt.Println("!!!!没有商品了!!!")
// break
// }
// fmt.Println("<===消耗一件商品")
// fmt.Printf("当前仓库还有:%v件商品; 仓库大小%v ;\n", len(ch), cap(ch))
// }
// 上述循环指定了从管道中取出多少,这种可能会导致死锁发生而报错,可使用下面方式
for {
_, ok := <-ch // 关键语句,只有管道关闭时,才能取出ok关键字
fmt.Println(ok)
time.Sleep(500 * time.Millisecond)
if ok {
fmt.Println("<===消耗一件商品")
fmt.Printf("当前仓库还有:%v件商品; 仓库大小%v ;\n", len(ch), cap(ch))
} else {
fmt.Println("!!!!没有商品了!!!")
return
}
}
}
// 生产者,每45毫秒生产一件商品,总共生产100件
func Produncter(ch chan any, superVision *sync.WaitGroup) {
defer superVision.Done()
for i := 0; i < 5; i++ {
time.Sleep(250 * time.Millisecond)
ch <- "Good"
fmt.Println("生产了一件商品===>")
fmt.Printf("当前仓库还有:%v件商品; 仓库大小%v ;\n", len(ch), cap(ch))
}
time.Sleep((1 * time.Second))
fmt.Println("生产了一件商品===>")
fmt.Printf("当前仓库还有:%v件商品; 仓库大小%v ;\n", len(ch), cap(ch))
ch <- "Good"
/****
******在确保没有生产者再生产时,需要生产者负责关闭仓库,避免死锁的发生
****/
defer close(ch)
}
func main() {
// 创建一个管道 代表仓库
store := make(chan any, 10)
// 创建一个监督完整时间完成得锁
var superVision sync.WaitGroup
superVision.Add(2)
// 创建两个协程
go Consumer(store, &superVision)
go Produncter(store, &superVision)
superVision.Wait()
}7.5特殊管道使用
select case从多个管道中随机只取出一个数据,如果都没有的话结束。
time.Tick()返回一个计时器,用于for range遍历管道时,每轮等待一段时间
只读只写的管道声明意义不大,通常声明双向管道,在函数中内限制双向管道为只读或者只写
package main
import (
"fmt"
"sync"
"time"
)
// 对管道只能进行读取
func Reader(ch <-chan int, w *sync.WaitGroup) {
defer w.Done()
for {
j, err := <-ch
if err {
fmt.Println("读取数据:", j)
} else {
fmt.Println("无数据可读")
break
}
}
}
// 对管道只能进行写入
func Writer(ch chan<- int, w *sync.WaitGroup) {
defer w.Done()
for i := 1; i < 5; i++ {
fmt.Println("写入数据:", i)
ch <- i
}
close(ch)
}
// 创建多个管道
func CreatChan(i int) []chan int {
res := []chan int{}
for j := 0; j < i; j++ {
res = append(res, make(chan int, 10))
}
return res
}
// 为多个仓库分配数据
func GeneratData(chs []chan int, w *sync.WaitGroup) {
defer w.Done()
for _, ch := range chs {
for i := 1; i < 5; i++ {
ch <- i
}
close(ch)
}
}
func main() {
// 创建一个空缓冲取管道
ch := make(chan int)
// 创建同步
var w sync.WaitGroup
w.Add(2)
// 将双向管道转换成单向管道限制操作
go Reader(ch, &w)
go Writer(ch, &w)
w.Wait()
// 可以使用select进行多管道读取
lc := CreatChan(4)
w.Add(3)
go GeneratData(lc, &w)
go func() {
defer w.Done()
select {
case data := <-lc[0]:
fmt.Println("接收多管道的0数据data:", data)
case data := <-lc[1]:
fmt.Println("接收多管道的1数据data:", data)
case data := <-lc[2]:
fmt.Println("接收多管道的2数据data:", data)
// 当多个管道都没有数据时避免阻塞,从default中选择一个
default:
fmt.Println("多个管道数据都已经接受完了!")
}
}()
go func() {
defer w.Done()
ticker := time.Tick(200 * time.Millisecond)
for v := range lc[3] {
<-ticker
fmt.Println("接收多管道的3数据v:", v)
}
}()
w.Wait()
}8.网络编程
这里仅介绍TCP。
TCP/IP协议:是一种面向连接、可靠的、基于字节流的传输层通信协议,因为是面向连接的协议,数据像流水一样传输,存在粘包问题。
TCP服务端:一个TCP服务段一次可以连接多个客户端,因此,当服务器每监听到有一个连接请求就可以创建一个协程去专门处理该连接请求的数据传输。
TCP客户端:主动呼叫服务器一端。
8.1服务端构建
步骤:
1.使用net.Listen("tcp",":port")创建监听某个端口以及某种协议的监听器
2.使用上步返回的监听器使用listener.Accept()建立连接,返回一个con(tcp连接),另外该con实现io.Reader接口,创建bufio流进行读取
3.可以直接对该连接进行con.Read(data),或者转换成bufio流进行读取
4.连接也能写入数据作为返还数据,con.Writer(responData)
package main
import (
"fmt"
"net"
)
func handleConnector(con net.Conn) {
defer con.Close()
addr := con.RemoteAddr()
fmt.Printf("===建立了来自 %v ; %v远端的连接===\n", addr.Network(), addr.String())
// 持续接收来自远端的数据
for {
// 持续读连接的数据
receiveData := make([]byte, 1024)
// 读取连接中数据
n, _ := con.Read(receiveData)
//或者使用缓存的形式进行读取
// linkFromClient := bufio.NewReader(con) // 说明con实现了io.Reader接口
// linkFromClient.Read(receiveData)
if n > 0 {
fmt.Printf("ReceiveData:%s\n", receiveData[:n])
// 回复数据端
con.Write([]byte("Receive data======\n"))
}
}
}
func main() {
// 创建一个监听端口的监听器
listenPort, err := net.Listen("tcp", ":8080")
if err != nil {
fmt.Println("监听端口异常=====")
return
} else {
fmt.Println("监听器创建成功=====")
}
// 无异常,持续监听端口
for {
// 一直接受客户端的连接
con, _ := listenPort.Accept()
// 对于每个连接器都开启一个go协程去处理
go handleConnector(con)
}
}8.2客户端的建立
步骤:
1.使用net.Dial("tcp","IP:port")建立对话连接,返回一个con和err(是否呼叫成功)
2.该con和上述TCP服务端监听Accept返回的con是一直的,能够进行读写。
package main
import (
"bufio"
"fmt"
"net"
"os"
)
func main() {
// 创建一个Dial(呼叫器)连接服务器
dialIpPort, err := net.Dial("tcp", "localhost:8080")
if err != nil {
fmt.Println("呼叫失败======", err)
return
}
// 延迟关闭呼叫
defer dialIpPort.Close()
reader := bufio.NewReader(os.Stdin) // 这里的os.stdin实现了io.Reader接口
// writer := bufio.NewWriter(dialIpPort) //也可以建立缓冲 写入连接
// 持续向服务端发送数据
for {
fmt.Println("请输入你想要发送的数据:")
postD, _ := reader.ReadString('\n')
// 停止发送数据 断开连接
if string(postD) == "end" {
break
}
// 向服务端发送数据
// pData := []byte(postD)
dialIpPort.Write([]byte(postD))
receiveBuf := make([]byte, 1024)
n, _ := dialIpPort.Read(receiveBuf)
fmt.Printf("接收成功:%v", string(receiveBuf[0:n]))
}
}9.反射
反射:reflect包下的函数,运行时动态的获取各种变量信息,典型用法是用静态类型interface{}保存一个值,通过调用TypeOf() 获取其动态类型信息,该函数返回一个Type类型的值,调用ValueOf()函数返回Value类型的值。
注意:
-
结构体得首字母的大小写会影响到其值的设置或者方法的获取
-
Elem()主要是获取原始对象并修改的,但是value必须是指针类型
-
通过reflect.TypeOf(x) == reflect.int 能够判断x是不是int类型
package main
import (
"fmt"
"reflect"
)
type B struct {
// 这里的变量首字母大写,才能通过reflect.ValueOf(interface{}(&b))Elem().Filed(0).SetInt()进行值得修改
X int
Y string
}
// 这里的方法名首字母需要大写,否则reflect无法识别
func (b B) PrintTest() {
fmt.Println("结构体的值:", b)
}
func testReflect(i any) {
fmt.Println("===================================")
TypeRes := reflect.TypeOf(i)
// 类别是一个大类,类型是具体的类,主要体现在结构体上
fmt.Printf(`
=============
TypeRes: %v
TypeRes变量类别: %v
`, TypeRes, TypeRes.Kind())
ValueRes := reflect.ValueOf(i)
fmt.Printf(`
=============
ValueRes: %v
`, ValueRes)
// value.interface()能够将value进行转换,返回一个接口
a := ValueRes.Interface()
fmt.Printf(`
=============
a的类型: %T
`, a)
_, ok := a.(float32)
var is string
if ok {
is = "是"
} else {
is = "不是"
}
fmt.Printf("%v %s float32类型\n", TypeRes, is)
fmt.Println("===================================")
}
func main() {
// 基本数据类型反射
a := 10
testReflect(a)
// 结构体类型
b := B{1, "张三"}
testReflect(b)
// 通过ValueOf获取value在setValue修改值,这里需要变量的引用
i := interface{}(&a)
v := reflect.ValueOf(i)
v.Elem().SetInt(100)
fmt.Println("=======", a)
// 通过valueOf获取结构体的value
j := interface{}(b)
w := reflect.ValueOf(j)
fmt.Println("=====w:", w)
fmt.Println("=====w.NumFiled:", w.NumField())
fmt.Println("=====w.NumMethod:", w.NumMethod())
fmt.Println("=====w.Filed1:", w.Field(0))
fmt.Println("=====w.Filed2:", w.Field(1))
// 方法索引按照 ASCLL码进行排列,A,B,C…… 索引:0,1,2……
w.Method(0).Call(nil) // 调用方法时,无参数函数可以使用nil作为参数
// 只有指针类型才能调用Elem()方法
// 修改结构体的值仍然需要使用指针变量,vk.Elem()表示vk指针的对象
k := interface{}(&b)
vk := reflect.ValueOf(k)
fmt.Println("vk======", vk.Kind())
fmt.Println("vk======", vk.Elem().Kind())
fmt.Println("vk======", vk.Elem().Field(0))
if vk.Kind() == reflect.Ptr && vk.Elem().Kind() == reflect.Struct {
vk.Elem().Field(0).SetInt(10)
vk.Elem().Field(1).SetString("王五")
fmt.Println("b======", b)
} else {
fmt.Println("vk 并不是指针类型 无法使用Elem()还原对象")
}
}
10.Context
表示上下文,常用于多个协程之间相互通信,比如多个协程之间可能需要同时取消,或者需要共享某些特定的值。
// 创建一个空上下文对象
ctx := context.Background()
// 关闭当前上下文环境
ctx.Done()10.1控制协程的取消
package main
import (
"context"
"fmt"
"sync"
"time"
)
var wa sync.WaitGroup
func main() {
// 创建一个空上下文对象
ctx := context.Background()
wa.Add(3)
go func(c context.Context) {
defer wa.Done()
select {
case <-time.After(1 * time.Second):
fmt.Println("父协程经过一秒结束")
case <-c.Done():
fmt.Println("父协程被取消")
}
}(ctx)
/*
基于上述空context创建一个带有取消的子context 函数返回:
子context:
函数:该函数的执行能够终止子context
*/
ctxWithCancle, cancle := context.WithCancel(ctx)
go func(c context.Context) {
defer wa.Done()
select {
case <-time.After(1 * time.Second):
fmt.Println("子协程经过一秒结束")
case <-c.Done():
fmt.Println("子协程被取消:", time.Now())
}
}(ctxWithCancle)
go func(c context.Context) {
defer wa.Done()
select {
case <-time.After(1 * time.Second):
fmt.Println("子协程经过一秒结束")
case <-c.Done():
fmt.Println("子协程被取消:", time.Now())
}
}(ctxWithCancle)
time.Sleep(900 * time.Millisecond)
// 调用上下文取消函数,直接终结包含该上下文对象的协程
cancle()
fmt.Println("context 创建成功===")
defer wa.Wait()
}10.2设定Context终结时间
package main
import (
"context"
"fmt"
"time"
)
func main() {
// 创建一个空上下文
ctx := context.Background()
/*
创建一个特定终结时间的上下文
*/
ctxWithTimeOut, cancle := context.WithTimeout(ctx, 2*time.Second)
go func(ct context.Context) {
select {
case <-time.After(3 * time.Second):
fmt.Println("协程1号==经过三秒任务完成===")
case <-ct.Done():
fmt.Println("协程1号==上下文环境结束===")
}
}(ctxWithTimeOut)
go func(ct context.Context) {
select {
case <-time.After(1 * time.Second):
fmt.Println("协程2号==经过一秒任务完成===")
case <-ct.Done():
fmt.Println("协程2号==上下文环境结束===")
}
}(ctxWithTimeOut)
time.Sleep(800 * time.Millisecond)
cancle()
time.Sleep(4 * time.Second)
fmt.Println("主任务结束===")
}注意:当设置了timeOut的context,当没有超时时先遇到了cancle()则提前取消
10.3对context设置一些值
package main
import (
"context"
"fmt"
"time"
)
func main() {
// 创建一个空上下文
ctx := context.Background()
// 在上下文中设置一些值
go func(c context.Context) {
time.Sleep(1 * time.Second)
ctx = context.WithValue(c, "key", "zhangsan")
}(ctx)
time.Sleep(2 * time.Second)
// 取出一些值
go func(c context.Context) {
time.Sleep(2 * time.Second)
fmt.Println(ctx.Value("key"))
}(ctx)
// 取出一些值
go func(c context.Context) {
time.Sleep(2 * time.Second)
fmt.Println(ctx.Value("key"))
}(ctx)
time.Sleep(3 * time.Second)
}10.4Http中的应用
package main
import (
"context"
"fmt"
"net/http"
"time"
)
func handlRequest(w http.ResponseWriter, r *http.Request) {
// 获取请求体的context
rctx := r.Context()
rctx, cancle := context.WithTimeout(rctx, 2*time.Second)
// 及时释放资源
defer cancle()
select {
case <-time.After(2200 * time.Millisecond):
fmt.Println("2.2秒请求处理完成")
w.Write([]byte("Hello world"))
case <-rctx.Done():
fmt.Println("请求处理超时==")
}
}
func main() {
http.HandleFunc("/", handlRequest)
http.ListenAndServe(":8080", nil)
}














 3368
3368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









