







之前的5篇文章全部讲的是处理单个CSV文件。但是,在大多数情况下,我们需要处理很多文件,而手工处理效率低,或者文件多到手工处理根本行不通。在这种情况下,使用Python可以规模化地处理文件,减少了人为工作量的同时,也有效地减少了人为犯错的概率。
为了规模化地处理CSV文件,我们需要使用Python内置的glob模块。我们使用下面的语句来导入该模块:
import glob
读取多个CSV文件
在本例中,我们需要先新建3个CSV文件,如下图所示。
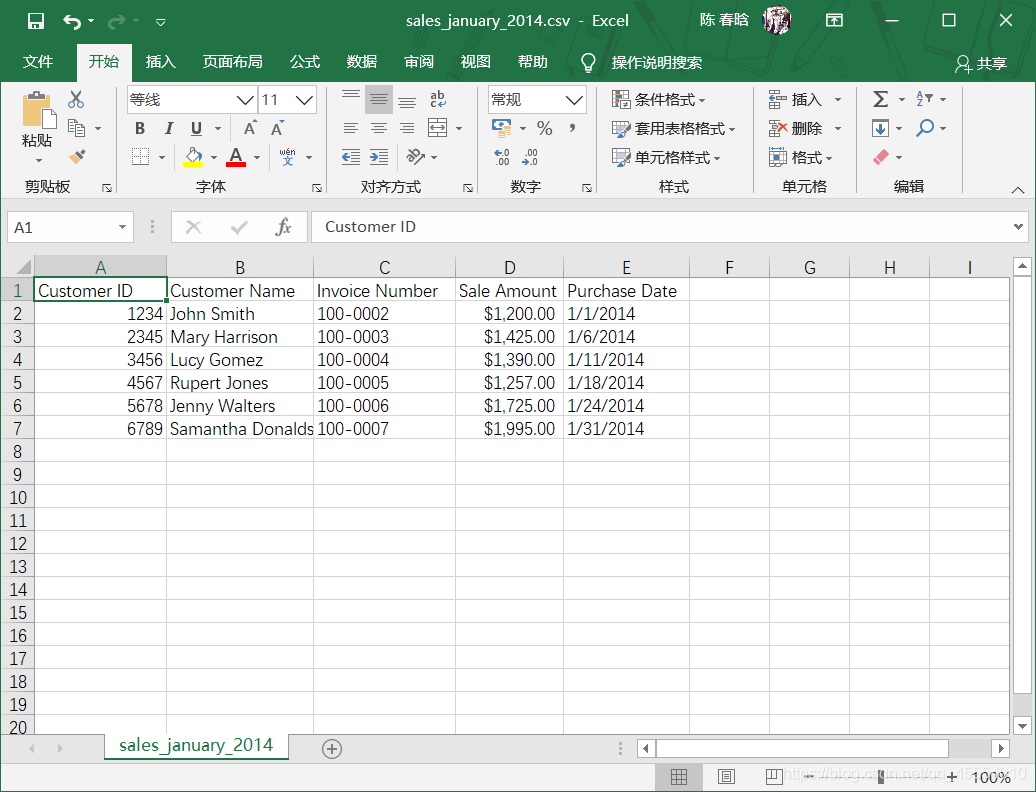
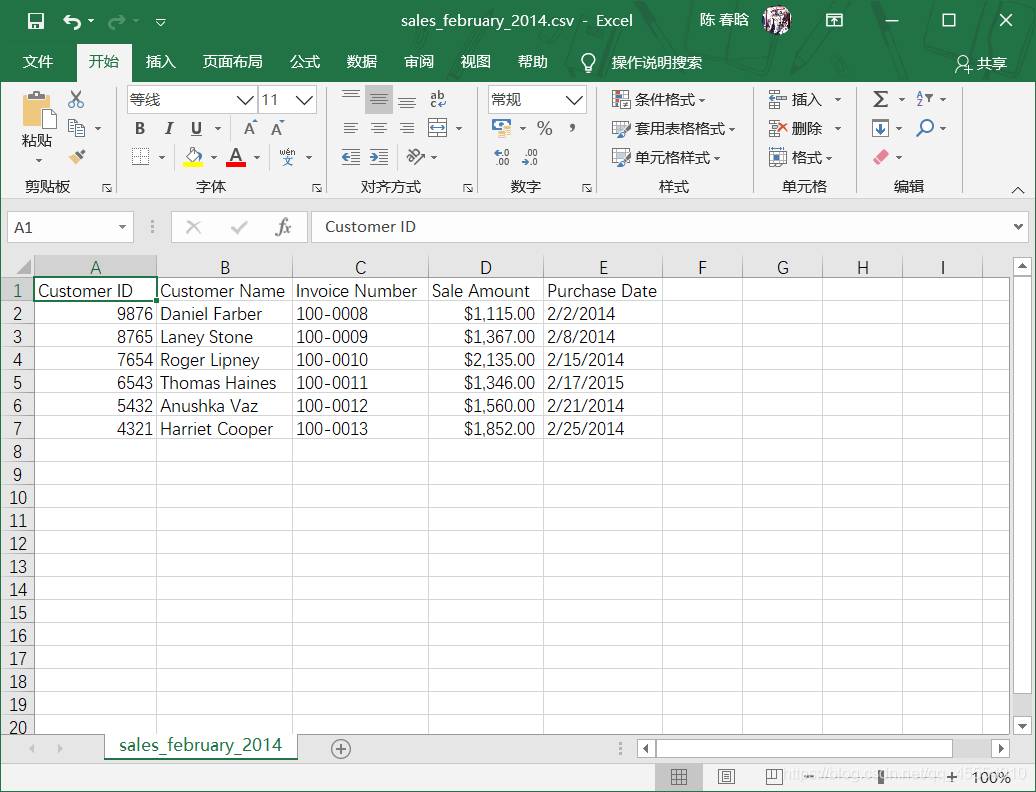
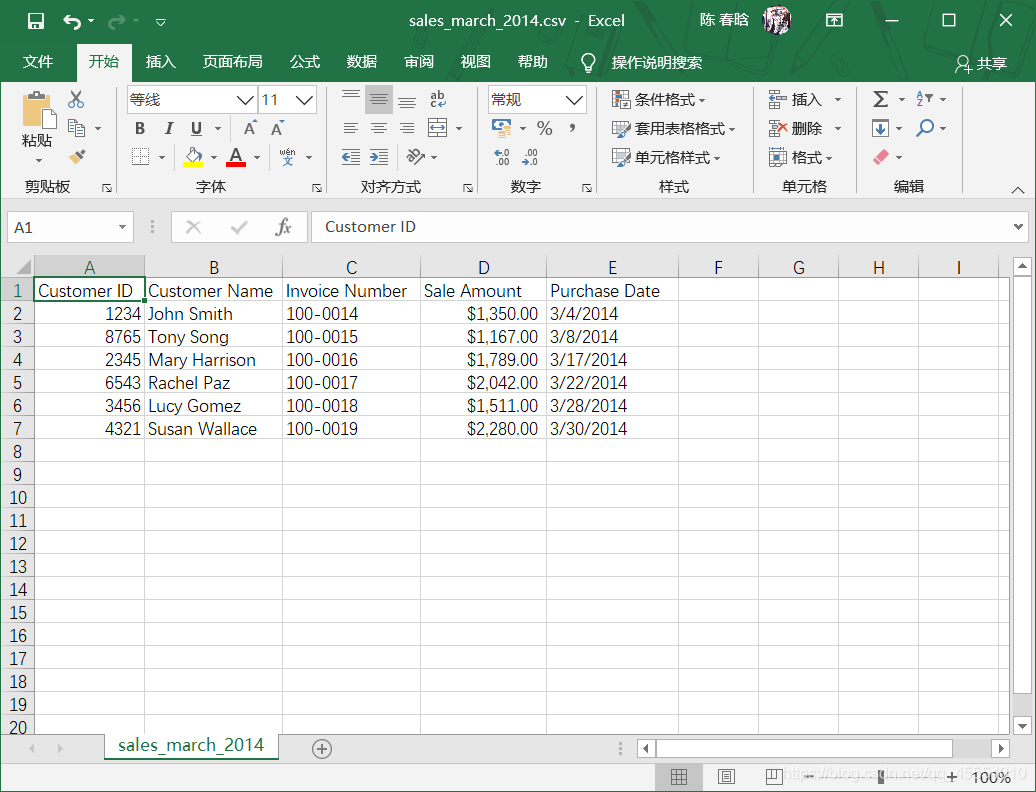
我们先从最简单的行列计数开始。尽管有些时候我们知道要处理的文件中的内容,但在多数情况下,文件是别人发送给我们的,我们不会立即知道文件中的内容。因此,行列计数是最简单的,也是最重要的。
我们编写下列代码,来读取上面创建的3个CSV文件。
#!/usr/bin/env python3
import csv
import glob
import os
import sys
input_path = sys.argv[1]
file_counter = 0
for input_file in glob.glob(os.path.join(input_path, 'sales_*')):
row_counter = 1
with open(input_file, 'r', newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
header = next(filereader, None)
for row in filereader:
row_counter += 1
print('{0!s}: \t{1:d} rows \t{2:d} columns'.format(os.path.basename(input_file), row_counter, len(header)))
file_counter += 1
print('Number of files: {0:d}'.format(file_counter))
我们来解释一下上面的代码。
import os
这行代码导入了Python内置的os模块,它提供的函数可以列出和解析我们要处理的文件路径名。
for input_file in glob.glob(os.path.join(input_path, 'sales_*')):
...
这里创建了一个for循环,它将数据处理扩展到多个文件中。os模块中的os.path.join()函数将圆括号中的两部分连在一起,其中input_path是包含输入文件的文件夹的路径,sales_*表示任何以模式sales_开头的文件名。glob模块中的glob.glob()函数将sales_*中的*转换为实际的文件名。也就是说,在这个例子中,glob.glob()和os.path.join()两个函数创建了一个包含3个输入文件的列表。然后,for循环语句对于列表中每个输入文件执行下面缩进的各行代码。
我们在命令行窗口中运行这个脚本。
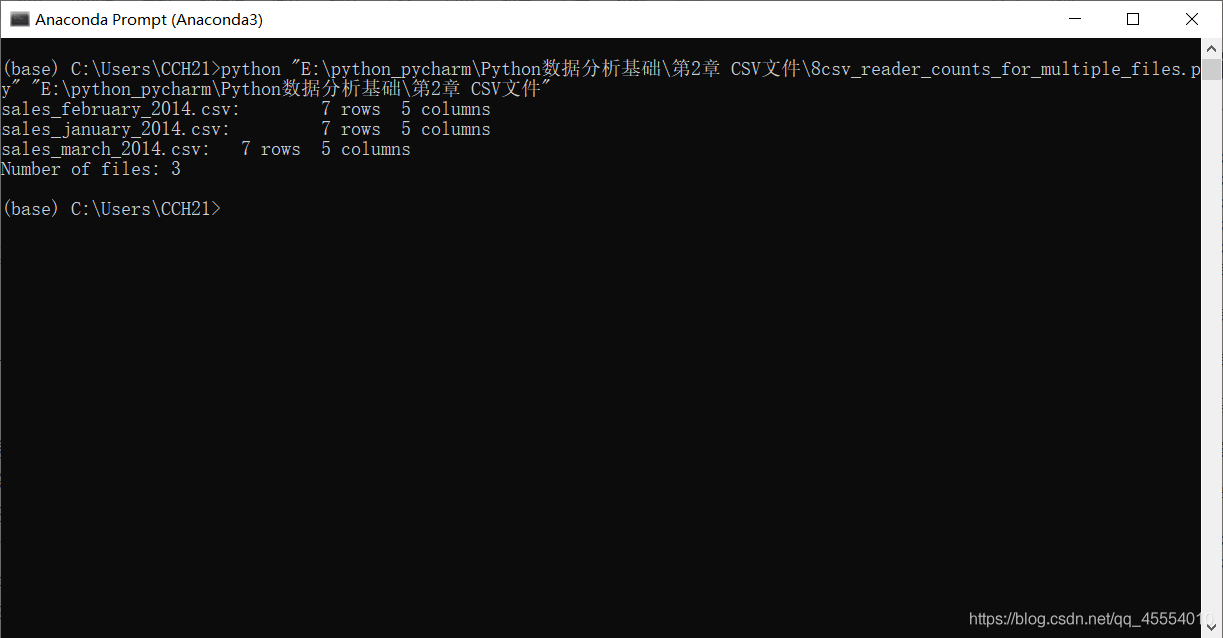
可以看到,输出结果显示脚本处理了3个文件,每个文件都有7行和5列。
从多个文件中连接数据
上面讲了如何读取多个CSV文件,接下来讨论如何把多个CSV文件中的数据连接起来。
1.基础Python
代码如下:
#!/usr/bin/env python3
import csv
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
first_file = True
for input_file in glob.glob(os.path.join(input_path, 'sales_*')):
print(os.path.basename(input_file))
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'a', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
if first_file:
for row in filereader:
filewriter.writerow(row)
first_file = False
else:
header = next(filereader, None)
for row in filereader:
filewriter.writerow(row)
我们来解释一下上面的代码。
with open(output_file, 'a', newline='') as csv_out_file:
和之前不同,这里open()函数中的参数不是'w'(可写)而是'a'(追加)。这里为什么不用可写模式呢?我们先来讨论一下可写模式和追加模式的区别。
| 模式 | 描述 |
|---|---|
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
使用追加模式,每个输入文件中的数据可以追加(也就是添加)到输出文件中。而如果使用可写模式,从一个输入文件中输出的数据会覆盖掉前一个输入文件中的数据,最后的输出文件会只包含最后处理的那个输入文件中的数据。
first_file = True
for input_file in glob.glob(os.path.join(input_path, 'sales_*')):
...
if first_file:
for row in filereader:
filewriter.writerow(row)
first_file = False
else:
header = next(filereader, None)
for row in filereader:
filewriter.writerow(row)
这里的if-else语句根据前面创建的first_file变量来区分当前文件是否为第一个输入文件。做这个区分的目的是将标题行仅写入输出文件一次,避免重复输入。if代码块处理第一个输入文件,将所有行写入输出文件。else代码块处理余下的输入文件,使用next()方法将每个输入文件中的标题行赋给变量header,这样就可以在后面的处理过程中跳过标题行,然后将数据行写入输出文件。
我们在命令行窗口运行这个脚本,并打开输出文件查看结果。
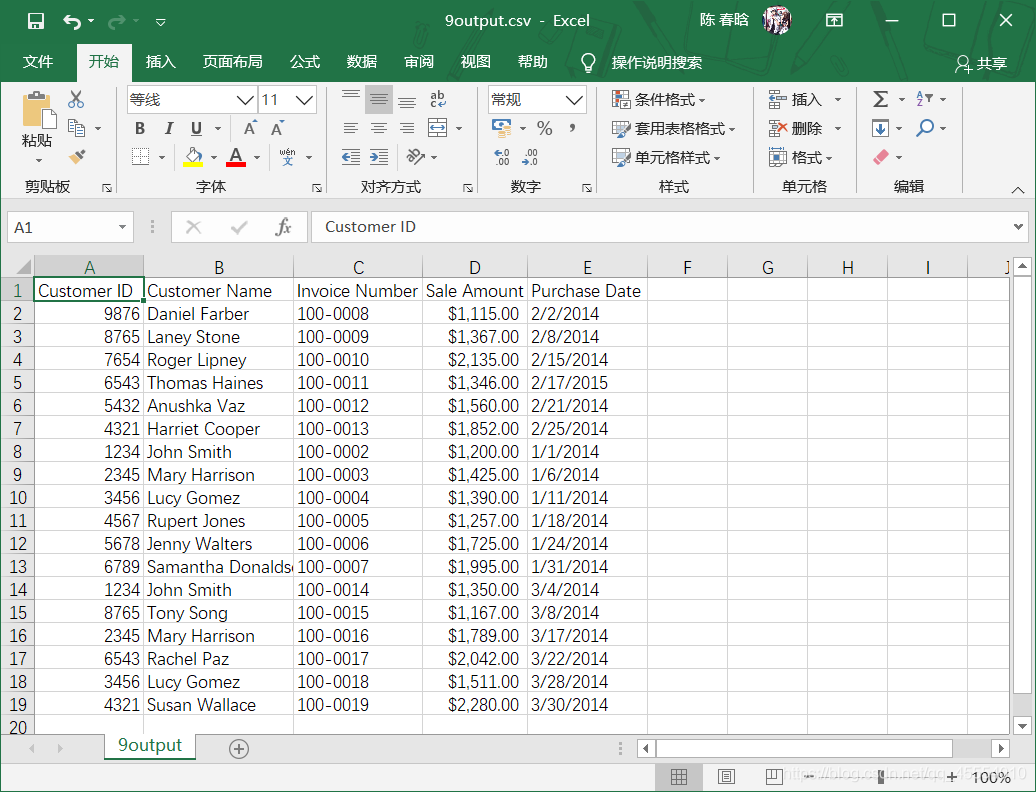
2.pandas
pandas模块可以直接从多个文件中连接数据。代码如下:
#!/usr/bin/env python3
import pandas as pd
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
all_files = glob.glob(os.path.join(input_path, 'sales_*'))
all_data_frames = []
for file in all_files:
data_frame = pd.read_csv(file, index_col=None)
all_data_frames.append(data_frame)
data_frame_concat = pd.concat(all_data_frames, axis=0, ignore_index=True)
data_frame_concat.to_csv(output_file, index=False)
使用pandas模块连接多个文件中的数据,基本过程就是将每个输入文件读取到pandas数据框中,将所有数据框追加到一个数据框列表,然后使用concat()函数将所有数据框连接成一个数据框。concat()函数可以使用axis参数来设置连接数据框的方式,axis=0表示从头到尾垂直堆叠,axis=1表示并排地平行堆叠。
此处省略输出结果。
计算每个文件中值的总和与均值
有些时候,当有多个输入文件时,需要对每个输入文件计算一些统计量,如总和、均值等。
1.基础Python
代码如下:
#!/usr/bin/env python3
import csv
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
output_header_list = ['file_name', 'total_sales', 'average_sales']
csv_out_file = open(output_file, 'a', newline='')
filewriter = csv.writer(csv_out_file)
filewriter.writerow(output_header_list)
for input_file in glob.glob(os.path.join(input_path, 'sales_*')):
with open(input_file, 'r', newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
output_list = []
output_list.append(os.path.basename(input_file))
header = next(filereader)
total_sales = 0.0
number_of_sales = 0.0
for row in filereader:
sale_amount = row[3]
total_sales += float(str(sale_amount).strip('$').replace(',', ''))
number_of_sales += 1
average_sales = '{0:.2f}'.format(total_sales / number_of_sales)
output_list.append(total_sales)
output_list.append(average_sales)
filewriter.writerow(output_list)
csv_out_file.close()
我们来解释一下上面的代码。
output_header_list = ['file_name', 'total_sales', 'average_sales']
csv_out_file = open(output_file, 'a', newline='')
filewriter = csv.writer(csv_out_file)
filewriter.writerow(output_header_list)
这里创建了一个输出文件的列标题列表output_header_list,并创建filewriter对象,使用writerow()将标题行写入输出文件。
output_list = []
output_list.append(os.path.basename(input_file))
这里创建了一个空列表output_list,保存要写入输出文件中的每行输出。下面一行代码将输入文件的文件名追加到output_list中。
header = next(filereader)
这行代码使用next()函数除去每个输入文件的标题行。
之后的代码内容和之前学习过的内容类似,代码本身也比较简单易懂,故在此不再赘述。
我们在命令行窗口运行这个脚本,并打开输出文件查看结果。
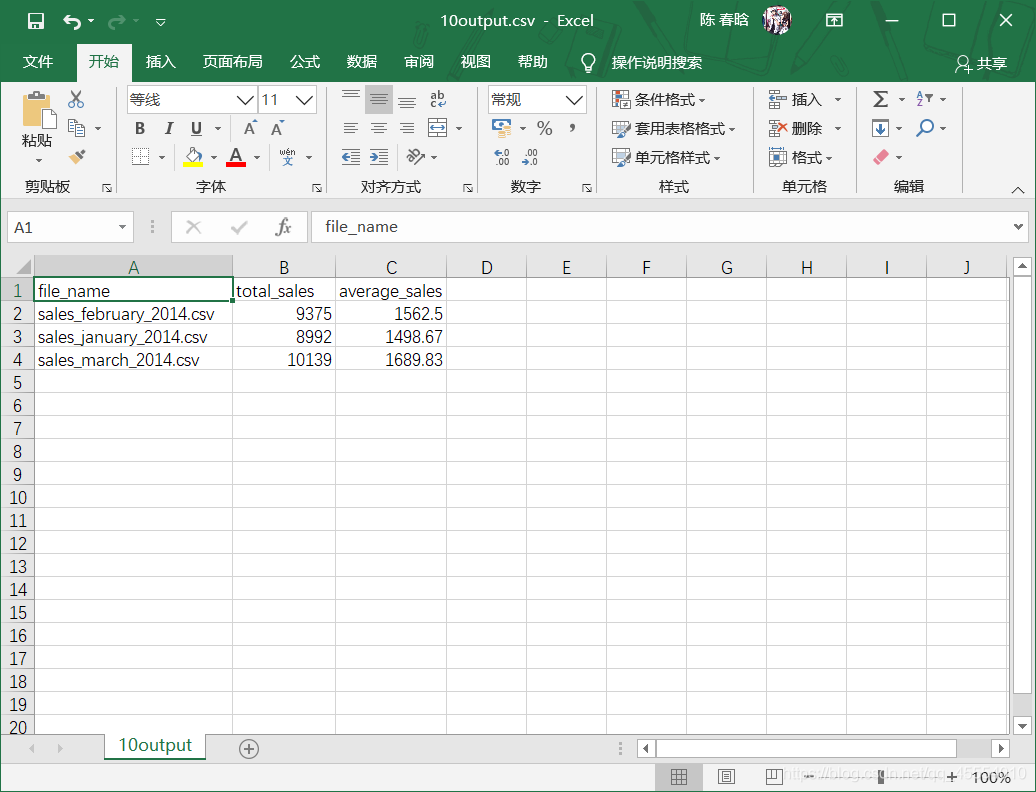
2.pandas
pandas模块中提供了一些摘要统计函数,比如sum()和mean()。使用pandas模块的代码如下:
#!/usr/bin/env python3
import pandas as pd
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
all_files = glob.glob(os.path.join(input_path, 'sales_*'))
all_data_frames = []
for input_file in all_files:
data_frame = pd.read_csv(input_file, index_col=None)
total_sales = pd.DataFrame([float(str(value).strip('$').replace(',', ''))
for value in data_frame.loc[:, 'Sale Amount']]).sum()
average_sales = pd.DataFrame([float(str(value).strip('$').replace(',', ''))
for value in data_frame.loc[:, 'Sale Amount']]).mean()
data = {'file_name': os.path.basename(input_file),
'total_sales': total_sales,
'average_sales': average_sales}
all_data_frames.append(pd.DataFrame(data, columns=['file_name', 'total_sales', 'average_sales']))
data_frames_concat = pd.concat(all_data_frames, axis=0, ignore_index=True)
data_frames_concat.to_csv(output_file, index=False)
使用列表生成式将销售额这一列中带$的字符转换为浮点数,然后使用数据框函数将这个对象转换为一个DataFrame,以便可以使用sum()和mean()这两个函数计算列的总计和均值。因为输出文件中的每行应该包含输入文件名,以及文件中销售额的总计和均值,所以可以将这3种数据组合成一个文本框,使用concat()函数将这些数据框连接成为一个数据框,并将这个数据框写入文件。
此处省略输出结果。
写在最后
以上就是Python数据分析中有关CSV文件的全部内容。由于本人能力有限,学习时间也比较短,难免出现纰漏,如果发现还请指正。
我的邮箱:1398635912@qq.com















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









