









Python获取电子书籍数据-以当当网为例
(一)以css方式获取
import requests,csv
from bs4 import BeautifulSoup
import codecs #自然语言编码转换库
def main():
res=requests.get("http://book.dangdang.com/20180504_by11")
res.encoding = res.apparent_encoding #获得真实编码
soup=BeautifulSoup (res.text,'html.parser')
info=[]
for item in soup.select('#bd li'):
names=item.select('.name')[0].text.strip()
price_n=item.select('.price span')[2].text.strip()
price_f = item.select('.price span')[3].text.strip()
price=price_n+price_f
info.append([names,price])
# print(info)
with codecs.open('book.csv','w',encoding='utf-8-sig') as f:
writer = csv.writer(f)
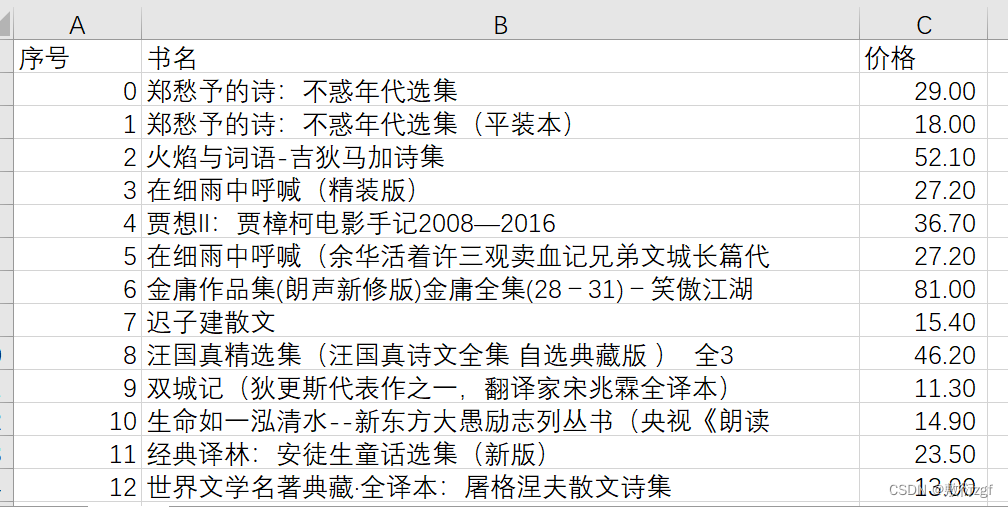
writer.writerow(['序号', '书名', '价格'])
for i,l in enumerate(info):
writer.writerow([i,l[0],l[1]])
#print(price,text,image,sep='\n**********************\n',end='\n*****')#多变量值分隔
if __name__ == '__main__':
main()
(二)以xpath方式获取
import urllib.request
import requests,csv
from lxml import etree
import codecs #自然语言编码转换库
def main():
url = "http://book.dangdang.com/20180504_by11"
request = urllib.request.Request(url=url) # 不需要headers
response = urllib.request.urlopen(request)
content = response.read().decode('GBK') # 通过网页查看charset = gb2312
tree = etree.HTML(content)
book_list = tree.xpath("//div[@class='con body']//li/p/a/text()") # 通过xpath获取a标签中的书名
price_n_list = tree.xpath("//div[@class='con body']//li/p[@class='price']//span[@class='num']/text()") # span中的价格由两部分组成
price_f_list = tree.xpath("//div[@class='con body']//li/p[@class='price']//span[@class='tail']/text()")
info = [] # 定义列表存放书籍信息
for item in range(len(book_list)) :
names= book_list[item]
price_n = price_n_list[item]
price_f = price_f_list[item]
price = price_n+ price_f
info.append([names,price])
# print(info)
# 将列表中的数据存放到csv文件中
with codecs.open('book.csv','w',encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(['序号', '书名', '价格'])
for i,l in enumerate(info):
writer.writerow([i,l[0],l[1]])
#print(price,text,image,sep='\n**********************\n',end='\n*****')#多变量值分隔
if __name__ == '__main__':
main()
















 2091
2091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











