






文章目录
引入
Spring Data Elasticsearch是Spring Data项目下的一个子模块。
- Spring Data 的使命是给各种数据访问提供统一的编程接口,不管是关系型数据库(如MySQL),还是非关系数据库(如Redis),或者类似Elasticsearch这样的索引数据库。从而简化开发人员的代码,提高开发效率。
Spring data elasticsearch使用
pom依赖:
application.yml文件配置:
spring:
data:
elasticsearch:
cluster-name: elasticsearch
cluster-nodes: 192.168.56.101:9300
实体类
public class Item {
Long id;
String title; //标题
String category;// 分类
String brand; // 品牌
Double price; // 价格
String images; // 图片地址
}
注解映射
Spring Data通过注解来声明字段的映射属性,有下面的三个注解:
@Document 作用在类,标记实体类为文档对象,一般有四个属性
- oindexName:对应索引库名称
otype:对应在索引库中的类型
oshards:分片数量,默认5
oreplicas:副本数量,默认1
@Id 作用在成员变量,标记一个字段作为id主键
@Field 作用在成员变量,标记为文档的字段,并指定字段映射属性:
- otype:字段类型,取值是枚举:FieldType
oindex:是否索引,布尔类型,默认是true
ostore:是否存储,布尔类型,默认是false
oanalyzer:分词器名称:ik_max_word
实例
@Document(indexName = "item",type = "docs", shards = 1, replicas = 0)
public class Item {
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title; //标题
。。。
@Field(index = false, type = FieldType.Keyword)
private String images; // 图片地址
}
创建索引
采用类的字节码信息创建索引并映射:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ItcastElasticsearchApplication.class)
public class IndexTest {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testCreate(){
// 创建索引,会根据Item类的@Document注解信息来创建
elasticsearchTemplate.createIndex(Item.class);
// 配置映射,会根据Item类中的id、Field等字段来自动完成映射
elasticsearchTemplate.putMapping(Item.class);
}
}
// 创建索引,会根据Item类的@Document注解信息来创建
// 配置映射,会根据Item类中的id、Field等字段来自动完成映射
删除索引
可以根据类名和索引名进行删除
@Test
public void deleteIndex() {
elasticsearchTemplate.deleteIndex("cars");
}
仓库文档操作Repository
Spring Data 的强大之处,就在于你不用写任何DAO处理,自动根据方法名或类的信息进行CRUD操作。只要你定义一个接口,然后继承Repository提供的一些子接口,就能具备各种基本的CRUD功能。
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
}
批量新增
代码:
@Test
public void indexList() {
List<Item> list = new ArrayList<>();
list.add(new Item(2L, "坚果手机R1", " 手机", "锤子", 3699.00, "http://image.leyou.com/123.jpg"));
list.add(new Item(3L, "华为META10", " 手机", "华为", 4499.00, "http://image.leyou.com/3.jpg"));
// 接收对象集合,实现批量新增
itemRepository.saveAll(list);
}
修改文档
修改和新增是同一个接口,区分的依据就是id,这一点跟我们在页面发起PUT请求是类似的。
基本查询
ElasticsearchRepository提供了一些基本的查询方法:
根据ID查询
@Test
public void testQuery(){
Optional<Item> optional = this.itemRepository.findById(1l);
System.out.println(optional.get());
}
查询所有
@Test
public void testFind(){
// 查询全部,并按照价格降序排序
Iterable<Item> items = this.itemRepository.findAll(Sort.by(Sort.Direction.DESC, "price"));
items.forEach(item-> System.out.println(item));
}
自定义方法
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
自定义方法规则
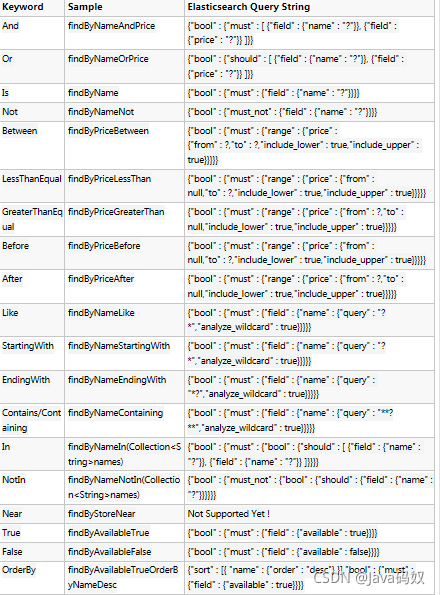
高级查询
QueryBuilders提供了大量的静态方法,用于生成各种不同类型的查询对象,例如:词条、模糊、通配符等QueryBuilder对象。
@Test
public void testNativeQuery(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本的分词查询
queryBuilder.withQuery(QueryBuilders.matchQuery("title", "小米"));
// 执行搜索,获取结果
Page<Item> items = this.repository.search(queryBuilder.build());
// 打印总条数
System.out.println("总条数:" + items.getTotalElements());
// 打印总页数
System.out.println("总页数:" + items.getTotalPages());
items.forEach(System.out::println);
}
分页查询与排序
利用NativeSearchQueryBuilder可以方便的实现分页
排序也通用通过NativeSearchQueryBuilder完成;
聚合为桶
@Test
public void testAgg(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(
AggregationBuilders.terms("brands").field("brand"));
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.repository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2、获取桶
List<StringTerms.Bucket> buckets = agg.getBuckets();
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key,即品牌名称
System.out.println(bucket.getKeyAsString());
// 3.5、获取桶中的文档数量
System.out.println(bucket.getDocCount());
}
}
AggregatedPage:聚合查询的结果类。它是Page的子接口:
AggregatedPage在Page功能的基础上,拓展了与聚合相关的功能,它其实就是对聚合结果的一种封装,可以对照聚合结果的JSON结构来看。
度量
@Test
public void testSubAgg(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(
AggregationBuilders.terms("brands").field("brand")
.subAggregation(AggregationBuilders.avg("priceAvg").field("price")) // 在品牌聚合桶内进行嵌套聚合,求平均值
);
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2、获取桶
List<StringTerms.Bucket> buckets = agg.getBuckets();
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key,即品牌名称 3.5、获取桶中的文档数量
System.out.println(bucket.getKeyAsString() + ",共" + bucket.getDocCount() + "台");
***// 3.6.获取子聚合结果:
InternalAvg avg = (InternalAvg) bucket.getAggregations().asMap().get("priceAvg");
System.out.println("平均售价:" + avg.getValue());***
}
}
















 1300
1300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











