






NeuralNLP-NeuralClassifier是腾讯开发的一个多层多分类应用工具,支持的任务包括,文本分类中的二分类、多分类、多标签,以及层次多标签分类。支持的文本编码模型包括 FastText, TextCNN, TextRNN, RCNN, VDCNN等。
想要找图像的层次分类,本人太菜了,需要有源代码的,发现层次分类在NLP自然语言处理里面较多一些,o(╥﹏╥)oo(╥﹏╥)o。先学习一下NeuralNLP-NeuralClassifier吧,没有大佬推荐图像方面的层次分类啊,感谢感谢!!!
本篇并不涉及层次分类,使用的TextCNN分类网络,主要学习其参数配置、数据处理和评估部分。
1.项目介绍
1.1系统环境需求
Python 3.x
PyTorch 0.4或更高版本
Numpy 1.14.3或更高版本
支持CPU进行训练
1.2 目录介绍
|--conf # config文件存放目录
|--data # 所有数据和schema存放目录
|--dataset # 构建dataloader所需脚本
|--evaluate
|--model
|--classification # 项目中使用到的所有特征编码器
|--attention.py
|--embedding.py
|-- ...... 各模型通用的一些模块
|--predict.txt # 执行预测生成的预测结果
|--checkpoint_dir_{} # 训练过程中保存下来的权重文件目录
|--dict_{} # 加载数据时产生的缓存文件目录
|--train.py # 训练脚本
|--eval.py # 评估脚本
|--predict.py # 预测脚本
1.3 数据格式
{
"doc_label":["Computer--MachineLearning--DeepLearning", "Neuro--ComputationalNeuro"],
"doc_token": ["I", "love", "deep", "learning"],
"doc_keyword": ["deep learning"],
"doc_topic": ["AI", "Machine learning"]
}
"doc_keyword" and "doc_topic" are optional.
- "doc_label"文档对应的所有标签构成的list,如果是单分类任务,list的长度为1,层次分类任务,各层之间用“–”进行分隔
- "doc_token"是这篇文档对应的所有token,中文可以使用各种分词工具进行分词
- “doc_keyword” 和"doc_topic"是在fasttext算法中提供额外的输入特征的,可以不提供,但是这两个字段必须要有,可以置为空
2.参数配置
{
"task_info":{
"label_type": "sigle_label", # 单标签还是多标签,二分来,多分类用single_label, 多层次分类用multi_label
"hierarchical": false, # 是否是层次分类
"hierar_taxonomy": "data/rcv1.taxonomy", # 如果是层次分类,层次结构树的路径
"hierar_penalty": 0.000001 # 层次标签传递中的惩罚系数
},
"device": "cuda", # cuda还是cpu
"model_name": "TextCNN", # 编码器模型的名称
"checkpoint_dir": "checkpoint_dir_rcv1", # 模型权重文件保存路径
"model_dir": "trained_model_rcv1",
"data": {
"train_json_files": [
"data/rcv1_train.json" # 训练集路径
],
"validate_json_files": [
"data/rcv1_dev.json"
],
"test_json_files": [
"data/rcv1_test.json"
],
"generate_dict_using_json_files": true,
"generate_dict_using_all_json_files": true,
"generate_dict_using_pretrained_embedding": false,
"generate_hierarchy_label": true,
"dict_dir": "dict_rcv1",
"num_worker": 4
},
"feature": {
"feature_names": [
"token" # 使用token作为特征还是char作为特征
],
"min_token_count": 2,
"min_char_count": 2,
"token_ngram": 0,
"min_token_ngram_count": 0,
"min_keyword_count": 0,
"min_topic_count": 2,
"max_token_dict_size": 1000000,
"max_char_dict_size": 150000,
"max_token_ngram_dict_size": 10000000,
"max_keyword_dict_size": 100,
"max_topic_dict_size": 100,
"max_token_len": 256, #数据处理中会用到此参数,最大token长度
"max_char_len": 1024, #数据处理中会用到此参数
"max_char_len_per_token": 4, #每个token最多只取4个字符
"token_pretrained_file": "",
"keyword_pretrained_file": ""
},
}
2.1 训练评估命令
训练命令:
python train.py conf/train.json
评估命令:
python eval.py conf/train.json
预测命令:
python predict.py conf/train.json data/predict.json
第一个参数是训练时的config文件,第二个参数是需要预测的文本
预测时指定待预测的文本路径,预测结果会保存在项目路径下的predict.txt中。
3.代码解读
主要解读的是品谷部分eval.py,采用TextCNN网络。
3.1 数据处理部分
使用的是ClassificationDataset。eval.py中:
test_dataset = globals()[dataset_name](conf, conf.data.test_json_files)
- 从这里进行数据类的初始化,执行ClassificationDataset(DatasetBase)的__init__部分。
- 然后中间一堆调用,到DatasetBase中的def getitem(self, idx)。
getitem 方法通常用于按索引获取数据集中的样本。当你想要访问数据集中的某个特定样本时,你可以使用索引来调用这个方法。idx 参数就是你要访问的样本的索引。 其功能主要有以下几点:
1.根据提供的索引 idx,从数据集中检索相应的样本。
2.对样本进行必要的预处理或转换(例如,图像加载、缩放、归一化等)。
3.返回处理后的样本,通常是一个字典或元组,其中包含输入数据和对应的标签(如果有的话)
def __getitem__(self, idx):
if idx >= self.sample_size:
raise IndexError
index = self.sample_index[idx]
# self.sample_index的得到方式在初始化部分,贴在下面。
# index第一个表示是哪个个config文件,第二个表示是哪行
# eval.py评估时只使用了一个配置文件,第一个位置总是0。
with open(self.files[index[0]]) as fin:
fin.seek(index[1])
# f.seek移动指针到指定的位置
json_str = fin.readline()
#。读取了指定的一行内容
return self._get_vocab_id_list(json.loads(json_str))
# self.sample_index的得到方式:
for i, json_file in enumerate(json_files):
with open(json_file) as fin:
self.sample_index.append([i, 0])
while True:
json_str = fin.readline()
if not json_str:
self.sample_index.pop()
break
self.sample_size += 1
self.sample_index.append([i, fin.tell()])
# fin.tell() 查看当前的文件指针位置。显示读取了多少字节
# self.sample_index是一个列表,第一个位置表示config文件是哪个,test.py中就只有一个cpnfig,所有i都是0,
# 第二个表示config文件中每行的指针位置。也就是得到了每行的指针位置 。
# self._get_vocab_id_list函数如下:
doc_labels = json_obj[self.DOC_LABEL] # 一行的label
doc_tokens = \
json_obj[self.DOC_TOKEN][0:self.config.feature.max_token_len]
# doc_tokens 是一个列表,里面是这行所有的单词
self._token_to_id()有两个预先定义的全局信息。
char_map数字和字母有个对应的数字,一共56个。
token_map常见单词的对应数字,一共有77062个常见单词,每个单词对应一个数字。
self._token_to_id()函数中对每个单词进行编码,编码的方式是从token_map映射得到数字,每个单词对应一个数字。
对每个单词的字母进行编码,使用char_map进行字母映射,一个单词转成了一个列表,列表元素个数是单词的字母个数,数字对应具体的字母。
char_id_list,是将每个单词的编码信息拉平,是一维列表。
char_in_token_id_list是一个二维列表,存储每个单词的编码信息。
token_id_list对应是每个token也就是每个单词对应的数字。
在eval.py中:
for batch in test_data_loader:
...
logits = model(batch)
if not is_multi:
result = torch.nn.functional.softmax(logits, dim=1).cpu().tolist()
else:
result = torch.sigmoid(logits).cpu().tolist()
主要是这个batch,也就是数据处理部分的最后结果。这个1024应该是配置文件中eval中"batch_size": 1024.
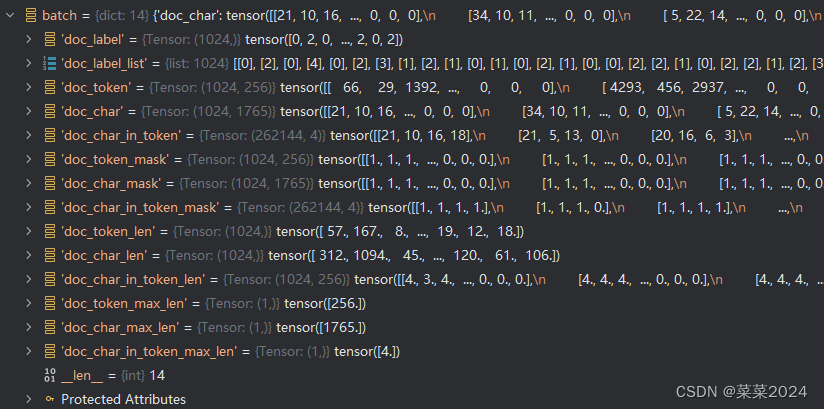
doc_label是batch_size行也就是1024行对应的文本标签,
doc_label_list就是doc_label转成二维列表了,
doc_token是这1024行中选择了256个token(也就是单词,每个单词按照token_map中对应了一个数字),max_token_len=256,某行不够256个单词的填补0.
doc_char是这1024行中的选择的token的字母编码
doc_char_in_token是max_char_len_per_token=4,所以应该是每个token只取前四个字母编码。所以也就是这1024行中有262144个token.(1024*256)
doc_token_mask维度和doc_token相同,表示token的有效性,有单词的为1,填充的为0。
doc_char_mask、doc_char_in_token_mask类似
doc_char_in_token_len 代表每行里面256个token中包含的字母个数(超过4的取前四个字母,所以里面的数字都不大于4)。
3.2 网络结构部分
TextCNN:
TextCNN(
(token_embedding): Embedding(
(dropout): Dropout(p=0.0, inplace=False)
# 在训练过程中随机将输入张量中的一部分元素置零,防止过拟合只在训练是生效,eval时不使用
(embedding): Embedding(77063, 64, padding_idx=0)
)
# torch.nn.Embedding主要用于实现词嵌入(Word Embedding)的功能。
# 词嵌入是将离散的词汇表中的单词映射到一个低维连续向量空间的过程,这些向量可以捕捉到单词之间的语义关系。
(char_embedding): Embedding(
(dropout): Dropout(p=0.0, inplace=False)
(embedding): Embedding(56, 64, padding_idx=0)
)
(dropout): Dropout(p=0.5, inplace=False)
(convs): ModuleList(
(0): Conv1d(64, 100, kernel_size=(2,), stride=(1,), padding=(1,))
(1): Conv1d(64, 100, kernel_size=(3,), stride=(1,), padding=(2,))
(2): Conv1d(64, 100, kernel_size=(4,), stride=(1,), padding=(3,))
)
(linear): Linear(in_features=300, out_features=7, bias=True)
)
# out_features=7 这个是label一共是7种从0-6
def forward(self, batch):
if self.config.feature.feature_names[0] == "token":
# 训练时传入token还是char,单词还是字母,可以在配置文件中指定
embedding = self.token_embedding(
batch[cDataset.DOC_TOKEN].to(self.config.device))
# 传入的数据是doc_token是这1024行中选择了256个token(也就是单词)
# 每个单词按照token_map中对应了一个数字),max_token_len=256
# 某行不够256个单词的填补0.
# 输入batch[cDataset.DOC_TOKEN]是1024*256
# 输出embedding 1024*256*64
else:
embedding = self.char_embedding(
batch[cDataset.DOC_CHAR].to(self.config.device))
embedding = embedding.transpose(1, 2)
# 输出embedding 1024*64*256
pooled_outputs = []
for i, conv in enumerate(self.convs):
#convolution = torch.nn.ReLU(conv(embedding))
convolution = torch.nn.functional.relu(conv(embedding))
# convolution第一层 1024*100*257,
#第二层变成1024*100*258
#第三层变成1024*100*259
pooled = torch.topk(convolution, self.top_k)[0].view(
convolution.size(0), -1)
# 选择257种最大的1个,变成了1024*100
pooled_outputs.append(pooled)
doc_embedding = torch.cat(pooled_outputs, 1)
# 三层进行拼接 doc_embedding 1024*300
return self.dropout(self.linear(doc_embedding))
# 返回的时 1024*7
# torch.nn.Dropout是一个模块,用于在训练过程中随机将输入张量中的一部分元素置零。
# 这种技术通常用于防止神经网络过拟合,通过减少神经元之间的复杂共适应性,使得模型更鲁棒。
# torch.nn.Dropout(p=dropout)的构造函数接受一个参数p,它表示在训练过程中,每个元素被置零的概率。
# 每个元素都有p的概率在每次前向传播时变为0。只在训练是生效,eval时不使用。
# torch.nn.Embedding是PyTorch神经网络库中的一个类,它主要用于实现词嵌入(Word Embedding)的功能。
# 词嵌入是将离散的词汇表中的单词映射到一个低维连续向量空间的过程,这些向量可以捕捉到单词之间的语义关系。
torch.nn.Embedding的构造函数接受几个参数:
num_embeddings(int):词典中词的总数,即嵌入矩阵的行数。
embedding_dim(int):嵌入向量的维度,即嵌入矩阵的列数。
padding_idx(int,可选):如果给定,在嵌入查找时遇到此索引时,返回全零向量。这在处理变长序列时特别有用,因为可以用这个索引来填充较短的序列,以便它们与最长的序列具有相同的长度。
max_norm(float,可选):如果嵌入向量的范数超过这个值,则进行归一化。
norm_type(float,可选):用于计算范数的p值。默认为2,对应于L2范数。
scale_grad_by_freq(boolean,可选):如果设置为True,则根据在mini-batch中单词出现的频率对梯度进行缩放。
sparse(boolean,可选):如果为True,梯度将相对于嵌入权重进行稀疏更新。
torch.nn.Embedding类可以无缝地与其他PyTorch层集成,并参与模型的构建、训练与推理过程。在训练过程中,嵌入层的权重(即嵌入矩阵)会根据模型的损失函数进行优化,以更好地捕捉词汇表中单词的语义关系。
后面就是得到结果evaluator.evaluate进行评估了
for batch in test_data_loader:
if model_name == "HMCN":
(global_logits, local_logits, logits) = model(batch)
else:
logits = model(batch)
if not is_multi:
result = torch.nn.functional.softmax(logits, dim=1).cpu().tolist()
# 输出的1024*7的结果进行softmax,并转成列表1024列,每列长度为7
else:
result = torch.sigmoid(logits).cpu().tolist()
predict_probs.extend(result)
standard_labels.extend(batch[ClassificationDataset.DOC_LABEL_LIST])
(_, precision_list, recall_list, fscore_list, right_list,
predict_list, standard_list) = \
evaluator.evaluate(
predict_probs, standard_label_ids=standard_labels, label_map=empty_dataset.label_map,
threshold=conf.eval.threshold, top_k=conf.eval.top_k,
is_flat=conf.eval.is_flat, is_multi=is_multi)
logger.warn(
"Performance is precision: %f, "
"recall: %f, fscore: %f, right: %d, predict: %d, standard: %d." % (
precision_list[0][cEvaluator.MICRO_AVERAGE],
recall_list[0][cEvaluator.MICRO_AVERAGE],
fscore_list[0][cEvaluator.MICRO_AVERAGE],
right_list[0][cEvaluator.MICRO_AVERAGE],
predict_list[0][cEvaluator.MICRO_AVERAGE],
standard_list[0][cEvaluator.MICRO_AVERAGE]))
evaluator.save()

















 579
579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









