






1.问题描述
一个url下包含了许多连接,想要下载其中包含的pdf文件。
按一下F12 打开开发者模式,查看网页下是否有pdf的链接。点击想要查看的元素,右击,选择其中的“检查”就可以定位到具体的位置,如下图所示:
以该网页为例
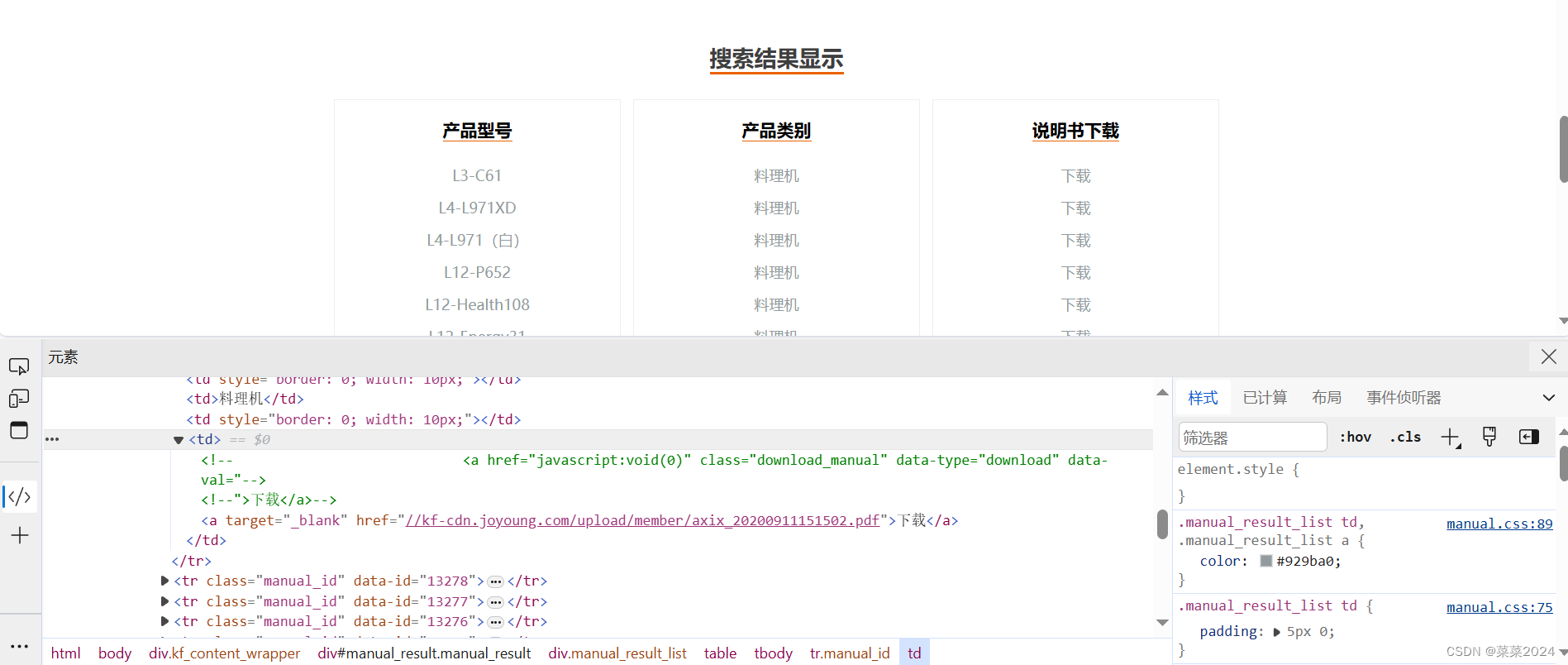
由图可以看出,网页中包含了我们想要的.pdf链接。(大多数网页都会封装编码一下,并不是直接放.pdf链接,所以具体还要看网页结构)pdf链接放在了标签为a的href中,所以下载此网页下所有的pdf可以用以下代码实现:
2.代码实现
# -*-coding:utf-8-*-
import requests
from urllib.parse import urlparse, urljoin
import os
from bs4 import BeautifulSoup
def GetUrlPdf(url,save_path):
# 确保保存路径存在
if not os.path.exists(save_path):
os.makedirs(save_path)
# 发送HTTP请求获取页面内容
response = requests.get(url)
response.raise_for_status()
# 如果请求失败,则抛出HTTPError异常
# # 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# # 找到所有你想要下载的链接(需要根据实际页面结构来定位)
# # 此页面所有文件链接都是.pdf格式,并且在一个特定的div或class中
# # 找到所有的‘a’标签的href且结尾是‘.pdf’的
file_links = soup.find_all('a', href=lambda href: href and href.endswith('.pdf'))
# 遍历链接并下载文件
for link in file_links:
# 构建完整的文件URL(如果链接是相对路径)
file_url = urljoin(url, link['href'])
# 下载文件
response = requests.get(file_url, stream=True)
response.raise_for_status()
# 提取文件名(这里需要根据你的URL结构或链接的href属性来提取)
filename = os.path.basename(urlparse(file_url).path)
# 将文件保存到本地
with open(os.path.join(save_path, filename), 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
print(f'Downloaded: {filename}')
if __name__=='__mian__':
save_path='./out'
url='https://kf.joyoung.com/manual/lists.html?product_cid=8&id=&title=&product_sub_cid=&page=9'
GetUrlPdf(url,save_path)
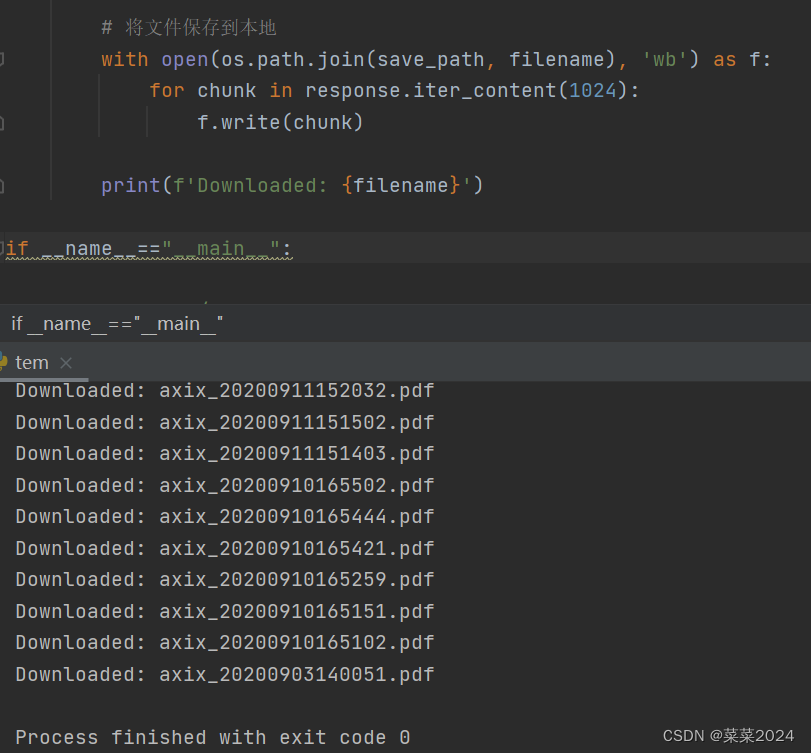
执行结果:
3.链接在其他属性标签
如果.pdf链接显式的在url,但是在其他标签标识中,使用Beautiful Soup中的find_all其他参数。
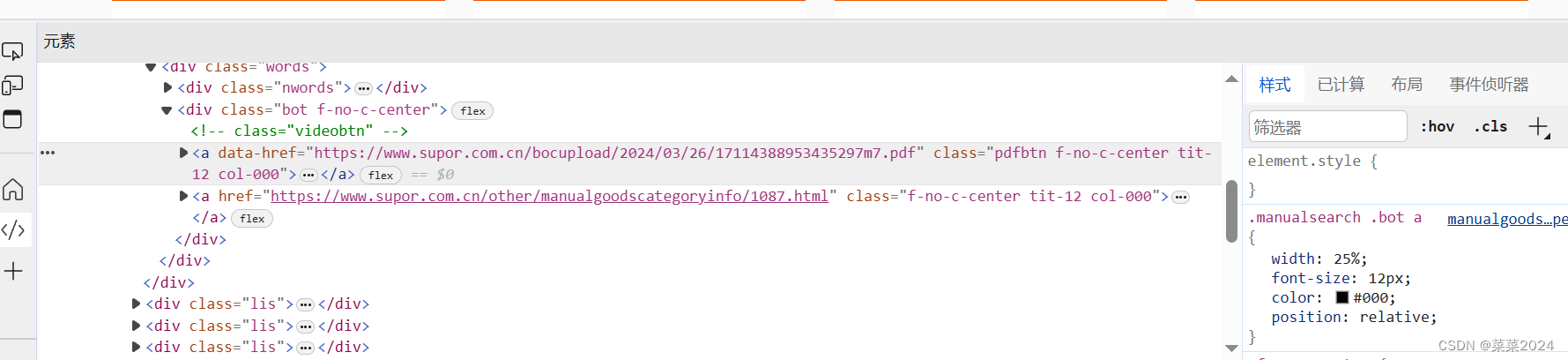
由上图可以看到.pdf连接在标签,属性为data-href。此时需要修改上述代码如下:
# 查找所有带有data-href属性的<a>标签
file_links = soup.find_all('a', attrs={'data-href': True})
很多时候都是封装的,只有通过模拟用户点击才能跳转到真正想要的链接,下篇学习爬虫模拟用户点击。















 6426
6426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









