











前言
Hello,大家好!我是
GISer Liu😁,一名热爱AI技术的GIS开发者。本文是作者参加2024DataWhale冬令营的技术设计方案,希望我的分享能对各位开发者有所帮助。😲
在本文中,作者将从地理信息提取大模型Lora微调数据集的设计思路,构建步骤到训练部署进行详细讲解;
一、项目介绍
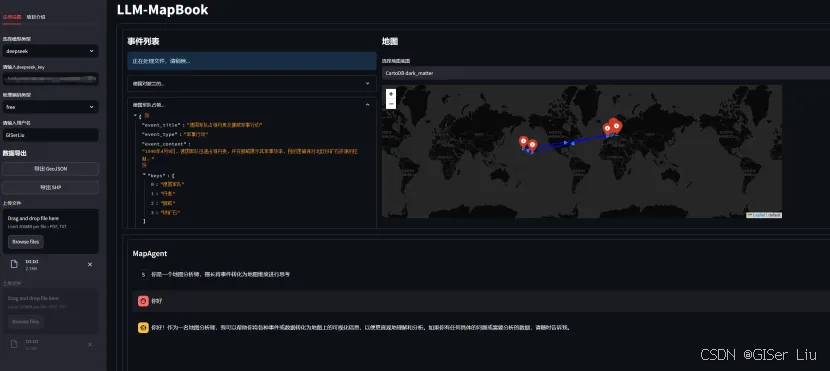
AI-MapBook 是一个作者前段时间结合了大语言模型(LLM)与地图技术的创新项目,旨在从文本中提取地理信息并生成相应的地图展示。该项目的核心目标是利用大模型的强大生成能力,结合本地部署的高效性,实现对地理信息的精准提取和格式化输出,从而为文本中的地理信息提供自动化的地图展示。
更多细节查看代码仓库,如果觉得我的项目不错可以给我一个Star哦🙂
二、问题背景

在 AI-MapBook 项目中,我们面临一个关键挑战:
- 如何从大量的文本数据中稳定地提取指定标准格式的地理信息,并以 JSON 格式输出。
- 目前,我们使用的在线大模型在生成 JSON 格式数据时结果高效稳定,但实际需求中常常需要本地部署;
- 而本地小模型虽然速度快,但生成质量不高,格式不稳定。
为了解决这一问题,我们计划通过构建数据集进行LoRA 微调,提升本地小模型(如 Qwen2.5)在地理信息提取任务上的性能表现。
三、代码阅读
在在线模型DeepSeek和本地模型如Qwen中,我们进行地理信息提取。以下是代码逻辑:
def process_event(self, event_text: str, language: str = '英语'):
prompt = f'''
您是一名地理分析师,您的任务是分析给定的历史或新闻情报,定位事件的内容,发生的位置,时间,相关的人物和历史事件,然后给出事件的地理描述,作为事件的属性信息。
你要生成的内容要包裹在```event```中,案例格式如下,要包含以下字段:
```event
"event_title": "有关ABC公司新产品的情报",
"event_type": "市场情报",
"address": "beijing",
"event_content": "根据对社交媒体平台的监听和分析,我们发现了以下有关ABC公司新产品的情报:1. ABC公司将在本月底发布其新的智能手机,该手机将具有更快的处理器、更大的内存和更长的电池寿命。2. 该新产品将是ABC公司在智能手机市场上的重要攻势,旨在与竞争对手的旗舰产品竞争。3. 在社交媒体上,用户对该新产品的期待度较高,有些用户甚至表示愿意预订该产品。",
"keys": ["Twitter", "Facebook", "LinkedIn"],
```
生成的address要求:
- 严格符合地理编码和OSM的命名规范,
- 地址address严格使用英语,
- 过去的地址使用现在的地址来表示,不然地理编码不能识别;
- 符合官方地名,严格地理编码器能识别;
- address要求真实地址,地图可查。不能是模糊的地名,而是具体详细,地图上可查的官方地址,例如 北京,而不是 北京周边,例如 德国 而不是 德国和法国;
- event_content部分是一个主要内容简介,限制200字内;
- 生成的内容是一个json格式 一定要用大括号符号扩住,严格要求为json格式;
- 将扩住后的生成的json情报信息包裹在```event```中,要求完整且精炼。
- 严格要求一个事件的address仅用一个地址来表达,不能同时用多个地址描述,例如北京和上海
好的,请根据以下用户输入的问题进行分析生成回答,address字段内容严格使用{language}输出,其他字段内容中文输出:
{event_text}
一定要符合上面要求,一个事件仅用一个地址来表达,不能同时用多个地址描述
'''
if self.model_type == 'deepseek':
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system",
"content": "您是一名地理事件分析技术专家,您的任务是从分析文本,定位地理信息并获取相关事件。"},
{"role": "user", "content": prompt},
],
stream=False
)
event = ModelBack.parse_event(response.choices[0].message.content)
return event
elif self.model_type == 'ipex_llm':
response = self.ipex_llm_generate(prompt)
print("返回的事件", response)
event = ModelBack.parse_event(response)
return event
def ipex_llm_generate(self, prompt: str):
messages = [{"role": "user", "content": prompt}]
with torch.inference_mode():
text = self.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True)
model_inputs = self.tokenizer(
[text], return_tensors="pt").to('cpu')
generated_ids = self.model.generate(
model_inputs.input_ids, max_new_tokens=8192)
processed_generated_ids = []
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids):
input_length = len(input_ids)
new_tokens = output_ids[input_length:]
processed_generated_ids.append(new_tokens)
generated_ids = processed_generated_ids
response = self.tokenizer.batch_decode(
generated_ids, skip_special_tokens=True)[0]
return response
仔细阅读一下代码逻辑,分为在线deepseek版本的提取,和离线qwen的提取逻辑;还包括提示词的构建;
代码中阐述了在线版本和本地版本实现地理信息提取的案例,其中提示词是至关重要的。
四、数据集构建
思路如下:
我们参考上述代码,将
event_text也就是新闻信息作为包含地理信息的文本输入,外面再包裹一层对 AI 的人设以及输出要求作为模型微调训练数据集的输入prompt;然后将 DeepSeek 的高质量输出的 JSON 格式数据作为模型微调训练数据集的输出;如此迭代循环5000次,构建完整的微调数据集。
下面是具体步骤;🤔
1. 数据集格式
我们的数据集将包含以下字段:
- 输入(Input):新闻文本内容。
- 系统提示(System Prompt):定义模型行为的提示,例如“你是一名地理分析师,负责从新闻文本中提取地理信息”。
- 输出(Output):生成的 JSON 格式地理信息数据。
2. 数据集构建
① 爬虫爬取新闻数据
我们将使用爬虫从新闻网站抓取包含地理信息的新闻文本。示例代码如下:
import requests
from bs4 import BeautifulSoup
import json
class NewsScraper:
def __init__(self, base_url):
self.base_url = base_url
def fetch_news(self, category="news"):
url = f"{self.base_url}/{category}"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
articles = soup.find_all('article')
news_list = []
for article in articles:
title = article.find('h2').text.strip()
content = article.find('p').text.strip()
news_list.append({"title": title, "content": content})
return news_list
else:
print(f"Failed to fetch news from {url}")
return []
def save_news(self, news_list, filename="news_data.json"):
with open(filename, 'w', encoding='utf-8') as f:
json.dump(news_list, f, ensure_ascii=False, indent=4)
# 示例使用
scraper = NewsScraper("https://example-news-website.com")
news_data = scraper.fetch_news()
scraper.save_news(news_data)
这里我们即可以选择从API获取,也可以直接爬取网页源码,作者使用的网页爬取,具体代码就不展示了,大家可以指定网站,查看结构,让GPT帮助你撰写爬取代码;😂
② 生成系统提示和人设要求
我们将为每个新闻文本生成一个系统提示,例如:
你是一名地理分析师,负责从新闻文本中提取地理信息,并生成 JSON 格式的输出。
③调用在线大模型 API 生成数据集
使用高级大模型(如 DeepSeek)生成 JSON 格式的地理信息数据。示例代码如下:
from openai import OpenAI
import re
class DatasetGenerator:
def __init__(self, api_key, base_url, model_name, system_message):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.model_name = model_name
self.system_message = system_message
self.dataset = []
def generate_dataset(self, news_list, num_samples=2):
for news in news_list:
for _ in range(num_samples):
instruction = f"根据以下新闻内容和格式要求,提取地理信息并生成 JSON 格式的输出:\n{news['content']}"
response = self._get_model_response(instruction)
output = self._extract_output(response)
data_element = {
"input": news['content'],
"system_prompt": self.system_message,
"output": output
}
print(data_element)
self.dataset.append(data_element)
def _get_model_response(self, instruction):
response = self.client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": self.system_message},
{"role": "user", "content": instruction},
],
stream=False
)
return response.choices[0].message.content
@staticmethod
def _extract_output(response):
pattern = r'```json(.*?)```'
match = re.search(pattern, response, re.DOTALL)
if match:
return match.group(1).strip()
else:
return ""
def save_dataset(self, filename):
import json
with open(filename, 'w', encoding='utf-8') as f:
json.dump(self.dataset, f, ensure_ascii=False, indent=4)
# 示例使用
api_key = "your_openai_api_key"
base_url = "https://api.openai.com"
model_name = "deepseek-chat"
system_message = ''' 您是一名地理分析师,您的任务是分析给定的历史或新闻情报,定位事件的内容,发生的位置,时间,相关的人物和历史事件,然后给出事件的地理描述,作为事件的属性信息。
你要生成的内容要包裹在```event```中,案例格式如下,要包含以下字段:
```event
"event_title": "有关ABC公司新产品的情报",
"event_type": "市场情报",
"address": "beijing",
"event_content": "根据对社交媒体平台的监听和分析,我们发现了以下有关ABC公司新产品的情报:1. ABC公司将在本月底发布其新的智能手机,该手机将具有更快的处理器、更大的内存和更长的电池寿命。2. 该新产品将是ABC公司在智能手机市场上的重要攻势,旨在与竞争对手的旗舰产品竞争。3. 在社交媒体上,用户对该新产品的期待度较高,有些用户甚至表示愿意预订该产品。",
"keys": ["Twitter", "Facebook", "LinkedIn"],
```
生成的address要求:
- 严格符合地理编码和OSM的命名规范,
- 地址address严格使用英语,
- 过去的地址使用现在的地址来表示,不然地理编码不能识别;
- 符合官方地名,严格地理编码器能识别;
- address要求真实地址,地图可查。不能是模糊的地名,而是具体详细,地图上可查的官方地址,例如 北京,而不是 北京周边,例如 德国 而不是 德国和法国;
- event_content部分是一个主要内容简介,限制200字内;
- 生成的内容是一个json格式 一定要用大括号符号扩住,严格要求为json格式;
- 将扩住后的生成的json情报信息包裹在```event```中,要求完整且精炼。
- 严格要求一个事件的address仅用一个地址来表达,不能同时用多个地址描述,例如北京和上海
好的,请根据以下用户输入的问题进行分析生成回答,address字段内容严格使用{language}输出,其他字段内容中文输出:
一定要符合上面要求,一个事件仅用一个地址来表达,不能同时用多个地址描述'''
dataset_generator = DatasetGenerator(api_key, base_url, model_name, system_message)
dataset_generator.generate_dataset(news_data)
dataset_generator.save_dataset("news_dataset.jsonl")
④ 循环迭代构建数据集
import re
from openai import OpenAI
class DatasetGenerator:
def __init__(self, api_key, base_url, model_name, system_message):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.model_name = model_name
self.system_message = system_message
self.dataset = []
def generate_dataset(self, instructions, num_samples=2):
for instruction in instructions:
for _ in range(num_samples):
response = self._get_model_response(instruction)
question = self._extract_question(response)
output = self._extract_output(response)
data_element = {
"instruction": question,
"input": "",
"output": output
}
print(data_element)
self.dataset.append(data_element)
def _get_model_response(self, instruction):
response = self.client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": self.system_message},
{"role": "user", "content": instruction},
],
stream=False
)
return response.choices[0].message.content
@staticmethod
def _extract_question(response):
pattern = r'```question(.*?)```'
match = re.search(pattern, response, re.DOTALL)
if match:
return match.group(1).strip()
else:
return ""
@staticmethod
def _extract_output(response):
pattern = r'```output(.*?)```'
match = re.search(pattern, response, re.DOTALL)
if match:
return match.group(1).strip()
else:
return ""
def save_dataset(self, filename):
import json
with open(filename, 'w', encoding='utf-8') as f:
json.dump(self.dataset, f, ensure_ascii=False, indent=4)
# Function to read topics from a file
def read_topics(filename):
with open(filename, 'r', encoding='utf-8') as f:
topics = [line.strip() for line in f.readlines()]
return topics
⑤ 人工手动微调数据集
为了确保数据质量,我们将对生成的数据集进行人工检查和调整,确保 JSON 格式的正确性和地理信息的准确性。
这里我们通过手动的方式进行检查修改,可以进行随机采样;也可以构建一个Agent用于检查筛选;
五、数据清洗与预处理
各位可以按照自己的需求进行选择使用🙂👌;
以下是数据清洗和预处理的完整代码:
import json
import logging
logging.basicConfig(level=logging.INFO, filename='data_cleaning.log', filemode='w')
def load_dataset(filename):
dataset = []
with open(filename, 'r', encoding='utf-8') as f:
for line in f:
try:
data = json.loads(line)
dataset.append(data)
except json.JSONDecodeError:
logging.warning(f"Skipping invalid JSON line: {line}")
return dataset
def remove_duplicates(dataset):
seen = set()
unique_dataset = []
for data in dataset:
input_text = data.get("input", "")
if input_text not in seen:
seen.add(input_text)
unique_dataset.append(data)
return unique_dataset
def is_valid_address(address):
return isinstance(address, str) and address.strip() != ""
def validate_event_content(content):
return isinstance(content, str) and len(content) <= 200
def validate_json_output(dataset, required_keys, error_counts):
cleaned_dataset = []
for data in dataset:
if "output" not in data:
error_counts["missing_output"] += 1
logging.warning(f"Missing output field: {data}")
continue
output_str = data["output"]
try:
output_json = json.loads(output_str)
if not isinstance(output_json, dict):
error_counts["invalid_json"] += 1
logging.warning(f"Output is not a JSON object: {output_str}")
continue
if not all(key in output_json for key in required_keys):
error_counts["missing_keys"] += 1
logging.warning(f"Missing keys in output: {output_str}")
continue
if not isinstance(output_json.get("event_title"), str):
error_counts["invalid_event_title"] += 1
logging.warning(f"Invalid event_title type: {output_json.get('event_title')}")
continue
if not isinstance(output_json.get("event_type"), str):
error_counts["invalid_event_type"] += 1
logging.warning(f"Invalid event_type type: {output_json.get('event_type')}")
continue
if not is_valid_address(output_json.get("address")):
error_counts["invalid_address"] += 1
logging.warning(f"Invalid address: {output_json.get('address')}")
continue
if not validate_event_content(output_json.get("event_content")):
error_counts["event_content_too_long"] += 1
logging.warning(f"Event content too long: {output_json.get('event_content')}")
continue
if not isinstance(output_json.get("keys"), list) or not all(isinstance(k, str) for k in output_json.get("keys", [])):
error_counts["invalid_keys"] += 1
logging.warning(f"Invalid keys format: {output_json.get('keys')}")
continue
cleaned_dataset.append(data)
except json.JSONDecodeError:
error_counts["invalid_json"] += 1
logging.warning(f"Invalid JSON output: {output_str}")
return cleaned_dataset
def clean_dataset(input_file, output_file, required_keys):
error_counts = {
"invalid_json": 0,
"missing_keys": 0,
"invalid_address": 0,
"event_content_too_long": 0,
"invalid_keys": 0,
"missing_output": 0
}
dataset = load_dataset(input_file)
logging.info(f"Loaded {len(dataset)} entries.")
dataset = remove_duplicates(dataset)
logging.info(f"Removed duplicates, {len(dataset)} unique entries remaining.")
dataset = validate_json_output(dataset, required_keys, error_counts)
logging.info(f"Cleaned dataset has {len(dataset)} valid entries.")
logging.info(f"Errors summary: {error_counts}")
with open(output_file, 'w', encoding='utf-8') as f:
for data in dataset:
json.dump(data, f, ensure_ascii=False)
f.write('\n')
# Example usage
required_keys = ["event_title", "event_type", "address", "event_content", "keys"]
clean_dataset("news_dataset.jsonl", "cleaned_news_dataset.jsonl", required_keys)
- 加载数据集:
load_dataset函数从 JSON Lines 文件中加载数据集,跳过无效的 JSON 行并记录日志。
- 去重:
remove_duplicates函数通过检查input字段来去除重复的条目。
- 验证 JSON 输出:
validate_json_output函数检查每个条目的output字段,确保其为有效的 JSON 对象,并且包含所有必需的字段(如event_title、event_type、address等)。- 该函数还会检查地址是否有效、事件内容是否在 200 字以内,以及
keys字段是否为字符串列表。
- 错误处理与日志记录:
- 所有错误都会被记录到日志文件中,并统计错误类型和数量。
- 保存清洗后的数据集
- 清洗后的数据集会被保存到新的文件中,每行一个 JSON 对象。
六、模型微调
-
上传数据集到星火平台
将清洗后的数据集上传至星火平台。选择Alpaca格式;

-
选择模型进行微调
选择 Qwen2.5-3B 模型进行微调,配置训练参数,例如学习率为 0.001、训练轮数为 10 轮等。

-
训练与测试
在星火平台上进行模型训练,并在测试集上评估模型性能,确保生成的 JSON 数据稳定且准确。
暂时还没有训练完毕,后续补发截图;
七、模型下载与效果发布
在模型管理中选择训练好的模型,进行下载;

- 本地部署:将微调后的模型部署到本地服务器,确保其能够在本地环境中稳定运行。
- 效果发布:将模型集成到 AI-MapBook 项目中,进行实际应用测试,并根据反馈进行进一步优化修改。
《大模型LLM の 地图故事》
八、结论
通过上述方案,我们旨在解决 AI-MapBook 项目中 JSON 数据生成不稳定的痛点,提升本地小模型的生成质量,实现高效、稳定的地理信息提取和格式化输出。这一方案不仅提高了模型的实用性,也为类似任务提供了可借鉴的思路。🎉🎉🎉
OK,今天就学到这里了,各位佬,加油!🙂👌
文章参考
相关地址

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











