







1.explain是什么?它能帮助我们做什么呢?
explain是mysql的解释工具,它反映了mysql底层是如何理解我们写的sql语句,并且如何执行。可以帮助我们获悉sql语句中表的加载顺序,数据读取操作的操作类型,表的哪些索引可能被使用,哪些索引被真正的使用,及表之间的引用关系(譬如连接查询时,到底以哪一张表为基准与其它表进行比对)等等。整理的表格如下:

2.怎么样看懂explain给出的信息?
博主的环境是mysql5.7,部署在centos7上。让我们先用explain做一下小的case观察一下:

我们现在观察表头就好,不需要看对应表头的值是多少,接下来我会解释。
- id,可以告诉我们表的加载顺序
- select_type:查询类别,可以初步分为简单查询,子查询,连接查询等等
- table:那当然就是表的名字啦!
- partitions:该列显示的为分区表命中的分区情况。非分区表该字段为空(null)。
- type:sql底层实际访问数据的类别,由好到坏依次为system>const>eq_ref>ref>range>index>all
- possible_keys:查询中可能用到的索引
- key:查询中真正用到的索引。
- key_len:代表索引的长度,以字节为单位。
- ref:数据的寻找参考了哪一个字段
- rows:显示MySQL认为它执行查询时必须检查的行数。估算出的行数值,不是精确值。行数越少越好.
- Extra:额外的重要信息!
接下来一一介绍哦。用到的表的信息如下:

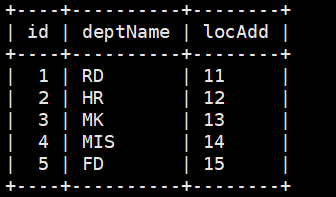
其中表一的deptId字段参考表二的id字段
1.id的理解

在上述的连接查询中,表a和b的id一栏都是1,那就代表它们的加载优先级是相同的,并且实际的加载顺序是从上到下的,也就是说,b表先加载,a表后加载。
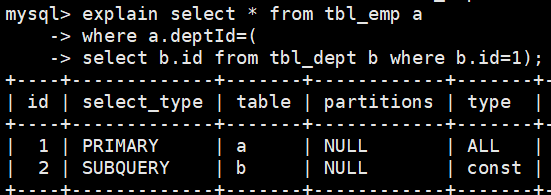
在上述的子查询中,a表的id是1,b表的id是2,那么代表b的加载先于a表,这也符合我们的认识,子查询中内层查询先于外层。
由此我们可以得出结论,id一栏表示表的加载顺序,当id相同时,加载顺序是从上到下的,不同时,id一栏的数字越大,那么加载越优先。
2.select_type的理解
代表sql语句查询类型,常见的有以下几种。
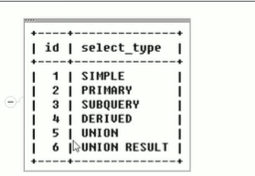
- SIMPLE简单查询
- PRIMARY主查询,是相对于SUBQUERY的概念,在子查询外围就是主查询。
- SUBQUERY子查询,相信学过mysql基础的都知道子查询的含义。
- DERIVED是衍生查询,代表查询过程出现了临时表。
- UNION查询时使用了UNION关键字
- UNION RESULT是UNION结果集的合并。
看一个综合案例.
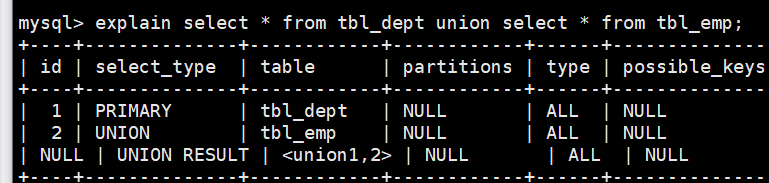
3.table的理解
很简单,就是列出表的名字,取了别名是会用别名。
4.type的理解
**注意这是很重要的一环。**代表mysql底层对查询的优化程序。
-
system级别
system表只有一行记录(等于系统表),是const类型的特例,平时不会出现。
只会在MYISAM或者MEMORY引擎上用,这里我们用的是默认的INNODB引擎,不变演示,了解下概念就好. -
const级别
代表通过索引字段一次就找到了需要的记录。
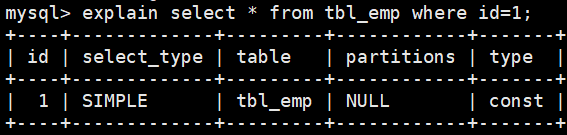
由于我们明确的指出了需要找id为1的记录,并且id字段是主键。那么就代表了它是个索引字段,并且唯一。所以通过一次扫描就可以找到。 -
eq_ref
表示唯一线性扫描,也是表中只有一条记录匹配,常见于主键或者唯一索引。很容易与const搞混。简单地说是const是直接按主键或唯一键读取,eq_ref用于联表查询的情况,按联表的主键或唯一键联合查询。更直接的区别是,eq_ref可以是唯一匹配,多条记录。
看一个例子:
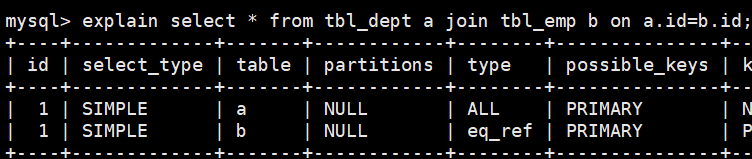
a表和b表的id字段都是唯一的,那就代表一旦匹配,那就直接可以停止搜索了。 -
ref的理解
ref表示是非唯一性匹配,返回匹配某个单独值的所有行,本质上也是索引访问,可能找到多个符和条件的行。比如在一个银行系统中,找一个叫做王芳的人,而名字这个字段是建立了索引的。通过这个名字可以找到多条记录。
临时建一个索引.

利用name字段作为条件查询。
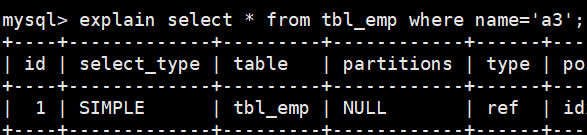
-
range的理解
range是检索指定范围内的行,key列显示使用了哪一个索引,一般where后面的条件是一个范围内的信息是启用.。也就是搜索时用到了部分唯一索引值。
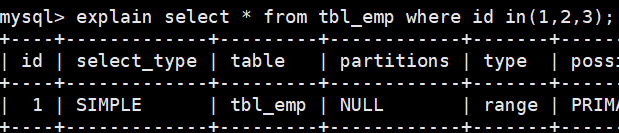
-
index的理解
在字段建立了索引的情况下,用到了所有的索引。
5.possible_keys和key代表可能用到的索引和真正用到的索引。
6.key_len的理解
用到的索引字段的长度。以字节为单位。但是请注意,变长字段需要额外的2个字节,固定长度字段不需要额外的字节。而null都需要1个字节的额外空间,所以以前有个说法:索引字段最好不要为NULL,因为NULL让统计更加复杂,并且需要额外一个字节的存储空间。这个字段在后续还会使用。帮助我们理解索引失效的情况。
7.ref的理解
哪些列或常量被用来查找索引列的值。
const:代表常量值

连接查询时:

查找a表的索引的值用到了e.id字段。
8.rows的理解
代表了实际查询的行数。一个估算值,不精确。越少越好。
9.Extra的理解
- using file sort:在使用order by关键字的时候,如果待排序的内容不能由所使用的索引直接完成排序的话,那么mysql有可能就要进行文件排序。出现这个问题可就大了,对性能的损耗十分严重。

- using temporary:有的爽了,天崩地裂。不仅没有用索引字段排序,而且在排序的过程中还创建了临时表,占用了额外的空间。出现这个情况时,要九死一生了。
**- using index:**很好。代表我们的查询或排序是走了索引的。要涨工资了。















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









