






Roc曲线和PR曲线的理解及简单的代码实现
1.引言
Roc曲线和PR曲线常被用来在二分类问题中评估一个分类器的性能,所以在机器学习中搞清楚两种曲线的原理及其区别与实现是非常基础也是非常重要的。
2.几个度量的介绍与理解
首先我们必须要了解混淆矩阵:表示模型将样本分类的结果的矩阵
我们可以简单的举个例子:1000个标本,有100个正样本,其中40真实正确,60个真实错误(二分法中预测正确指真实结果为正例预测结果为正例,真实结果为反例预测结果为反例)
| 真实结果为正例 | 真实结果为反例 | |
|---|---|---|
| 预测结果为正例§ | TP:40 | FP:60 |
| 预测结果为反例(N) | FN:400 | TN:500 |
在Roc曲线和PR曲线中有四个重要的度量:精确率(查准率),召回率(查全率),真正例率,假正例率。
精确率(precison):
P
=
T
P
T
P
+
F
P
P=\frac{TP}{TP+FP}
P=TP+FPTP
召回率(recall):
R
=
T
P
T
P
+
F
N
R=\frac{TP}{TP+FN}
R=TP+FNTP
真正例率(tpr):
T
P
R
=
T
P
T
P
+
F
N
TPR=\frac{TP}{TP+FN}
TPR=TP+FNTP
假正例率(fpr):
F
P
R
=
F
P
T
N
+
F
P
FPR=\frac{FP}{TN+FP}
FPR=TN+FPFP
3.PR曲线的理解
召回率(recall): 理解为在所有的真实正例中,被正确预测的占比
精确度(precision):理解为在所有的预测正例中(包括正确预测得出正例和错误预测得出正例),预测正确的比例
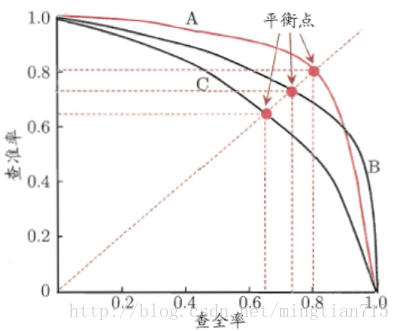
若一个学习器的P-R曲线被另一个学习器的曲线围住的话,则后者的性能优于前者。当存在交叉时,可以计算曲线围住面积,平衡点(BEP,精确度=召回度)是一种度量方式。但BEP过于简化,所以我们通常将两个度量合并在一起得到F1.(这里个人觉得F1与图像关联不大,只是一个定义,有误请指正)
F
1
=
2
R
P
R
+
P
=
2
∗
T
P
2
∗
T
P
+
F
P
+
F
N
F1=\frac{2RP}{R+P}=\frac{2*TP}{2*TP+FP+FN}
F1=R+P2RP=2∗TP+FP+FN2∗TP
我们可以理解将F1公式中的P当做R,可以发现当F1大,BEP相应的也大。
且PR曲线越靠右上方代表模型效果越好
接下来我们用简单的实例来说明PR曲线
首先我们先说明一下绘制PR曲线时的几个步骤。
- 我们将会有真实的标签(例如猫狗大战中,猫为1,狗为0)
- 当我们训练模型后会出现一个置信度(预测概率)
- 将置信度与标签一一对应从高到低排序
- 我们需要设置阈值(与精确度和召回率息息相关),我们将大于阈值的置信度做为正样本(及可以理解为我们预测的正确的数据)
- 然后将每一次阈值所划分出的混淆矩阵计算精确率和召回率
- 绘图
以下数据和接下来代码数据相同(置信度已由高到低排序)
这里我们把标签为1当做实际正确,标签为0当做实际错误
| 标签data_labels | 置信度confidence_scores |
|---|---|
| 1 | 0.9 |
| 1 | 0.78 |
| 0 | 0.6 |
| 1 | 0.46 |
| 0 | 0.4 |
| 0 | 0.37 |
| 1 | 0.2 |
| 1 | 0.16 |
在严谨的情况下我们一般阈值都是先设为1,然后逐步下降,但是我们用sklearn.metrics(Sklearn.metrics模块的功能是提供评估模型效果的指标函数,包括混淆矩阵、准确率、精确率、召回率、F值、ROC曲线、AUC、PR曲线等等。)来绘制PR曲线时,阈值是通过置信度从大到小取(这里数据取8次)。
我们取当阈值为0.6时的情况来讲解。
当阈值为0.6时,我们可以得到的正样本(其余为负样本)应该是置信度大于等于0.6的数据,为
| 标签data_labels | 置信度confidence_scores |
|---|---|
| 1 | 0.9 |
| 1 | 0.78 |
| 0 | 0.6 |
这里的正样本可以理解为我们预测为正确的样本有3个,但是其中真正正确的只有2个,所以我们的精确率precision=2/3。召回率recall我们可以理解为,在所有真正正确的样本中(这里有5个样本,就是标签为1的样本)我们预测的正样本中预测正确的样本的比例(正样本中标签为1的样本)所以,我们可以计算出recall=2/5.

总结:PR曲线因为对样本比例敏感,因此能够看出分类器随着样本比例变化的效果,而实际中的数据又是不平衡的,这样有助于了解分类器实际的效果和作用,也能够以此进行模型的改进。PR曲线的召回率不断上升,而精确率以略微震荡的方式呈下降趋势。
4.Roc曲线的理解
真正率(true positive rate,TPR)或灵敏度(sensitivity),定义为被模型正确预测的正样本的比例
真负率(true negative rate,TFR)或特指度(specificity),定义为被模型正确预测的负样本的比例
Roc曲线绘图过程与PR曲线类似,就是x轴,y轴的度量发生变化
这里我们沿用上面的数据,例子
| 标签data_labels | 置信度confidence_scores |
|---|---|
| 1 | 0.9 |
| 1 | 0.78 |
| 0 | 0.6 |
| 1 | 0.46 |
| 0 | 0.4 |
| 0 | 0.37 |
| 1 | 0.2 |
| 1 | 0.16 |
我们取阈值为0.46的情况进行分析
置信度大于0.46的样本为正样本(即我们预测为正确的样本),为
| 标签data_labels | 置信度confidence_scores |
|---|---|
| 1 | 0.9 |
| 1 | 0.78 |
| 0 | 0.6 |
| 1 | 0.46 |
真正率我们可以理解为正样本中我们预测正确的样本中(4个)真正正确的有3个(即正样本标签为1的样本)与真正正确的所有样本(所有样本标签为1的样本)的比值,所以TPR=3/5
真假率可以理解为预测正确的样本中(4个)真正错误的有1个(即正样本中标签为0的样本)与真正错误的所有样本(所有样本标签为0的样本)的比值,所以FPR=1/3

AUC(Area Under Curve)即指曲线下面积占总方格的比例。有时不同分类算法的ROC曲线存在交叉,因此很多时候用AUC值作为算法好坏的评判标准。面积越大,表示分类性能越好。(理想化的AUC为1)
当随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的分数将这个正样本排在负样本前面的概率就是AUC值。所以,AUC的值越大,当前的分类算法越有可能将正样本排在负样本值前面,既能够更好的分类。
在ROC空间,ROC曲线越凸向左上方向效果越好。
5.简要代码绘制两种曲线
因为只是理解ROC曲线和PR曲线的含义,所以我们这里没有用到大量的模型数据,只是简单的自己构造了一些标签和置信度,所以数据量很小,曲线并不平滑,标准的ROC曲线和PR曲线如上面两张图。现在附上代码
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve,roc_curve
plt.figure()
plt.title('PR Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.grid()
#只是理解两种曲线的含义,所以数据简单的构造
confidence_scores = np.array([0.9,0.46,0.78,0.37,0.6,0.4,0.2,0.16])
confidence_scores=sorted(confidence_scores,reverse=True)#置信度从大到小排列
print(confidence_scores)
data_labels = np.array([1,1,0,1,0,0 ,1,1])#置信度所对应的标签
#精确率,召回率,阈值
precision,recall,thresholds = precision_recall_curve(data_labels,confidence_scores)
print(precision)
print(recall)
print(thresholds)
plt.plot(recall,precision)
plt.show()
#真正率,假正率
fpr, tpr, thresholds = roc_curve(data_labels, confidence_scores)
#print(fpr)
#print(tpr)
plt.figure()
plt.grid()
plt.title('Roc Curve')
plt.xlabel('FPR')
plt.ylabel('TPR')
from sklearn.metrics import auc
auc=auc(fpr, tpr)#AUC计算
plt.plot(fpr,tpr,label='roc_curve(AUC=%0.2f)'%auc)
plt.legend()
plt.show()


如果想看更详细的代码,https://blog.csdn.net/jcfszxc/article/details/102829505
以上是作者对PR曲线及ROC曲线的简要理解,做为学习笔记,若有理解错误的地方,欢迎大家提出!















 8587
8587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









