







索引
一、索引的分类
主键索引(primary key):唯一的标识,一张表只可以有一个,并且不可以重复。
Error occur in execute SQL. Caused by: 执行失败:Duplicate column name 'examdate'--出现重复的索引就会出这个错误
二、索引的使用
SHOW INDEX from `result` /*显示表中的所有索引*/
alter TABLE `result` add FULLTEXT INDEX `subjectno`(`subjectno`);/*创建一个新的全局索引*/
EXPLAIN SELECT * FROM `grade` WHERE MATCH(`gradeid`) against('5');/*查找全局索引*/
EXPLAIN SELECT * FROM `grade` WHERE `gradeid` ='5'/*解释分析sql语句*/
三、测试
/*创建一个表格*/
CREATE TABLE `app_user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT '',
`email` varchar(50) NOT NULL,
`phone` varchar(20) DEFAULT '',
`gender` tinyint(4) unsigned DEFAULT '0',
`password` varchar(100) NOT NULL DEFAULT '',
`age` tinyint(4) DEFAULT NULL,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
/*写一个函数,批量生成一百万条数据*/
DELIMITER $$
-- 写函数之前必须要写,标志
CREATE FUNCTION mock_data ()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTO `app_user`(`name`,`email`,`phone`,`gender`)VALUES(CONCAT('用户',i),'19224305@qq.com','123456789',FLOOR(RAND()*2));
SET i=i+1;
END WHILE;
RETURN i;
END;
-- 执行函数
SELECT mock_data() -- 执行此函数 生成一百万条数据
-- 第一种查询方式 直接查询
SELECT * FROM `app_user` WHERE `name`='用户9999'-- 用时:380ms 查询的次数就是表的列数,是利用遍历查询的
-- 第二种查询方式:建立索引来查询 直接建立一个普通索引,直接引用就可以,他会把索引用序号拍起来,下一次直接使用
CREATE INDEX id_app_user_name ON app_user (`name`);-- 用时4ms ;建立普通的索引的话,查询就是查询一次
SELECT * FROM `app_user` WHERE `name`='用户99999'
-- 全局索引 语法:SELECT * FROM [表名] WHERE MATCH ([列名]) AGAINST ([属性值])-
CREATE FULLTEXT INDEX id_app_user_name ON app_user (`name`);
SELECT * FROM `app_user` WHERE MATCH (`name`) AGAINST ('用户9999')-- 用时:6ms
四、索引原则
- 索引的数量不是越多越好
- 索引应该设置在不经常更新的数据上
- 索引应该设置在经常查询的字段上
- 数据量太小就不用添加索引
五、深入了解数据库索引的数据结构
连接地址: https://blog.codinglabs.org/articles/theory-of-mysql-index.html
1.b-tree(m阶的b-tree)
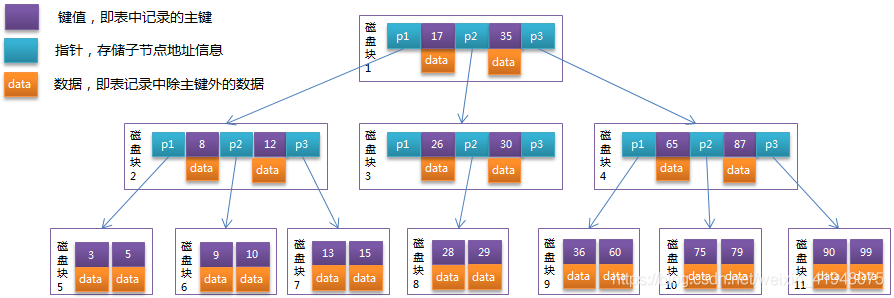
- 在第一轮中,找到关键字的话,直接输出数据,如果没有的话,那么就继续向下查找。查找按照二分查找的规则进行。比数值小的就在左边,比关键字大的就在另一边。它查找的结束位置可能是任何节点的任何位置。不一定要是叶子节点或是根节点。
- 每个节点最多有m个孩子节点
- 若根节点不是叶子节点,则至少有2个孩子。
例如:模拟查找关键字29的过程
模拟查找关键字29的过程:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。B-Tree相对于AVLTree缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
2.b+tree(InnoDB和MyIRam使用的都是b+Tree)
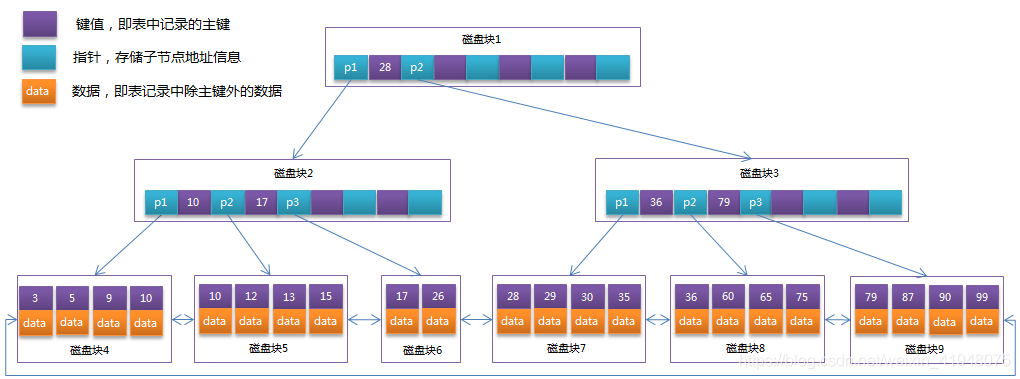
- 所有的叶子结点中包含了全部关键字的信息(数据),非叶子节点只存储键值信息(关键字),及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接,所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B树的非终节点也包含需要查找的有效信息)
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
- 请尽量在InnoDB上采用自增字段做主键

















 3775
3775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









