







SimCLR是对比学习系列文章里比较容易理解的一个模型框架,这也是Hinton大神的又一篇作品,值得我们仔细阅读与学习。以下就是学习过程中的相关心得笔记,希望能够帮到你,如有错误请指正,我们一起进步!
0、摘要:
首先,本论文在开头就对提出的SimCLR框架进行了定义。SimCLR:一种简单的视觉表征对比学习框架。所提出的这种框架无需专门的架构和存储库。
1、前言
“在没有人类监督的情况下,学习有效的视觉表示是一个长期存在的问题。现在主流的视觉表示方法都属于以下两类之一:生成式和判别式”。
本文引入了一个简单的框架,用于对比学习视觉表示,并将其命名为SimCLR。我们可以先看一下本文提出模型在ImageNet上的表现(Top1)。
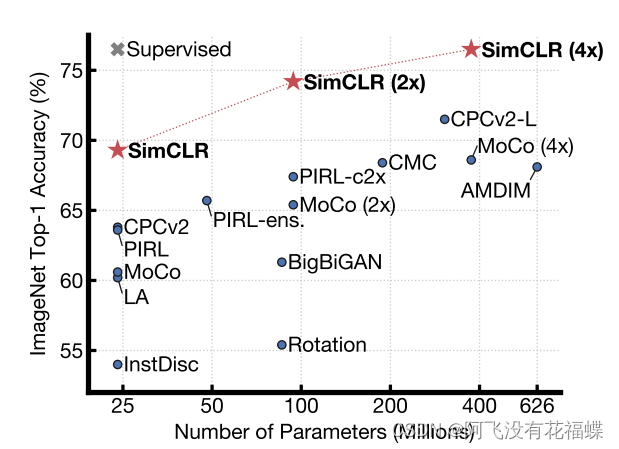
SimCLR主要包含:
(1)数据增强的组合对于对比预测任务非常重要;
(2)在表征和对比损失之间引入非线性变换,可提高学习表示的质量;
(3)具有对比交叉熵损失的表示学习受益于标准化嵌入和适当调整的温度参数;
(4)对比学习相较于有监督学习需要更大的batch size和epoch。
2、方法
(1)对比学习框架
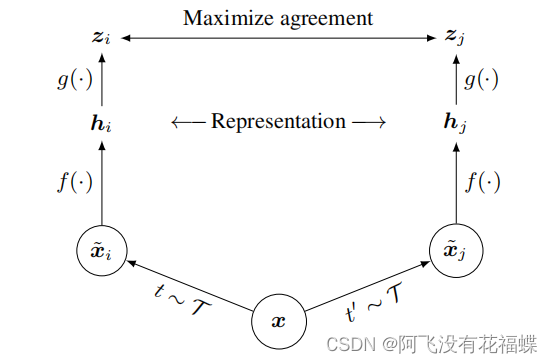
①数据增强(data augmentation)
如上图所示,将输入图像x进行不同的数据增强方法,生成和
。假设这里的输入图像为n个,则正样本数量为2n,负样本数量为2(n-1)。
②编码器CNN(encoder)
该编码器用来提取来自数据增强样本的向量,网络架构上的选择是很自由的,本文选择的是ResNet网络模型。
③projection head
本文较大的一个创新点就是在编码器之后加入了一个projection head,也就是图中的g函数。本质上,这个g函数就是个mlp层(全连接层+Relu激活函数),对f函数提取到的特征进行非线性变换,实验结果也证明该操作的效果非常显著。需要注意一点,这个g函数只在训练的时候使用,在下游任务中则除去g(.)。
④对比损失函数(loss function)
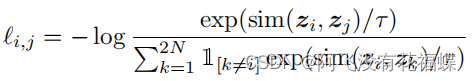
从上面可以看到,SimCLR相较于其他对比学习模型来讲比较简单,文章大部分篇章还是作者在做消融实验来证明该模型的有效性。
(2)使用大批次进行训练
本文的的训练批次是从256到8192不等,使用Cloud TPUs进行训练。(这里不得不感叹有钱真好)
3、数据增强

SimCLR模型中使用的数据增强方法基本上将图像领域中的图像处理方法都用到了,同时如何将这些数据增强方法组合起来也很重要,于是作者做了相关的消融实验来证明“数据增强操作的组成对于学习良好表示至关重要”。从下图中我们可以看到,数据增强组合操作效果较好的有Crop和Color。
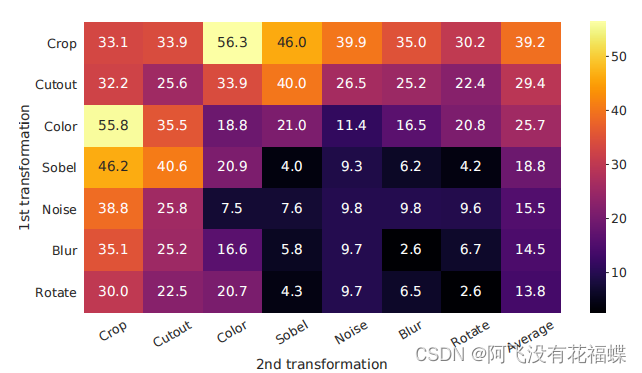
同时,为了进一步证明颜色增强的重要性,本文又通过改变颜色增强强度进行了相关实验。

上述结果表明颜色增强改善了无人监督模型的线性评估能力,同时该数据增强方法在无人监督模型上的效果优于监督学习。
4、其他
文章剩下的篇幅主要是在介绍编码器、projection head、损失函数以及batch size,内容较为繁琐。首先是编码器,本文选取ResNet50作为基础神经网络编码器,来从数据增强后的向量中提取表示向量;其次是nonlinear peojection head,实验结果证明在表征层和损失函数之间加入该层可以提高对比学习的质量,本文选取了非常简单的单层MLP;然后是损失函数,本文选取NT-Xent损失函数,具体的描述内容不好描述,详见原文;最后是batch size,最终实验结果如下图所示,可以看到增大训练轮数和batch size可提高模型的Top1准确率,这也证明了文章中的结论“Contrastive learning benefits(more) from larger batch sizes and longer training”。

消融实验:
(1)线性评估
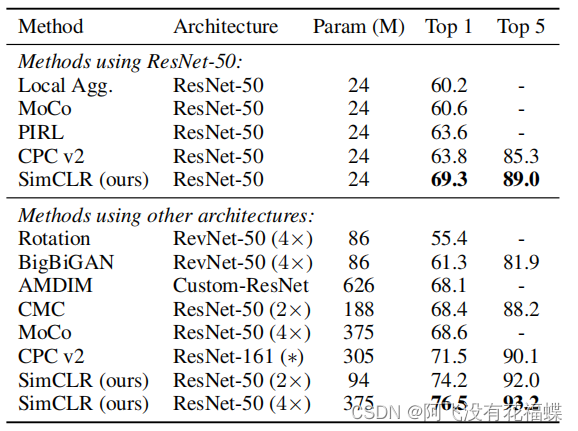
(2)半监督学习
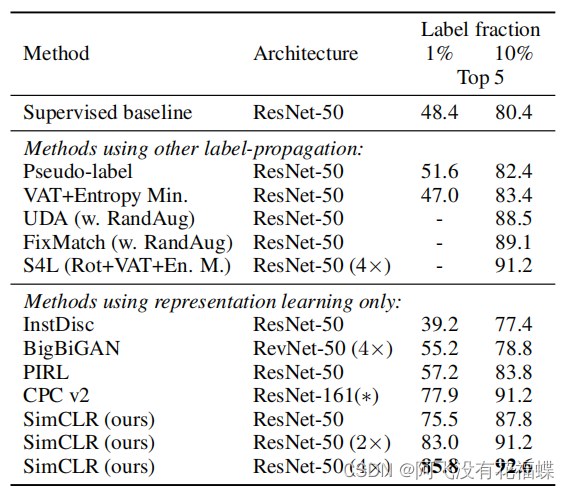
(3)迁移学习

5、结论
作者在文中提出,本文框架中的组成部分都在以前的工作中出现过,本文所提出的SimCLR模型为一种简单对比学习模型,对后续有关对比学习的研究有很重要的意义。从学术研究上讲,该模型原理简单易懂;从工程上讲,该模型使用了128块GPU/TPU来训练1000轮,这是普通实验室根本无法达到的水平。综上,对比学习与有监督学习最大的不同或者说是创新之处在于:数据增强方法的选择、非线性层的选择、损失函数的选择。关于对比学习的研究仍在继续,期待更轻便、更高效的模型!















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









