







6月14日,本文的作者之一孙剑老师因病离世,让人扼腕叹息,他的研究成果极大推动了人工智能技术的发展和应用,孙老师的逝世是人工智能技术领域的一大损失。哀悼!
论文:https://arxiv.org/abs/1512.03385
代码:网上开源的有很多,github、Pytorch官网、paperswithcode网站等。
先聊一聊为什么想写这篇随笔。最开始这篇文章是我刚接触深度学习时就看过的一篇文章,当时有点囫囵吞枣,现在重新读了一篇,收获良多,所以想记录一下自己的学习过程。如有错误,恳请指正,我们一起进步!
首先要讲一讲神经网络研究中的这一个说法:“The Deeper, The Better”,通俗的来讲:网络层数越深,网络的提取特征的能力、表达的能力也会对应提高;同时层数的增加会使得神经网络能调整的参数变多。然而,复杂化神经网络是一把双刃剑,会带来一系列问题:梯度消失、梯度爆炸、过拟合、网络退化等问题。
梯度消失和梯度爆炸的根本原因是因为深度神经网络结构以及反向传播算法。优化神经网络的方法都是基于反向传播的思想,即根据损失函数计算的误差通过反向传播的方式,指导深度网络权值的更新。关于梯度消失/爆炸问题,已经有许多解决的方法,如归一化等。这个文章中也做了对应的说明。

ResNet所解决的正是深度神经网络训练过程中遇到的“退化问题”。下图为网络退化现象,我们可以看到深层模型通过训练反而取得更高的训练、测试误差。这种问题就引发了研究者的思考,能否对网络单元进行一定的改造来改善或者解决网络退化问题呢?

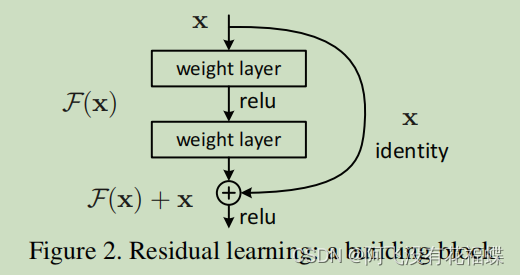
假设网络的输入为X (identity Function),输出为H(X),也就是我们要求解映射,所以问题就变成了求解网络的残差映射函数F(X) (ResNet Function),F(X)=H(X)-X,H(X)是观测值,X是上一层网络输出的特征映射,然后问题就变成了求H(X)=F(X)+X。如果H(X)趋近于X,就说明残差在接近0,这样就保证了加深后的网络准确率至少不低于原来的网络。

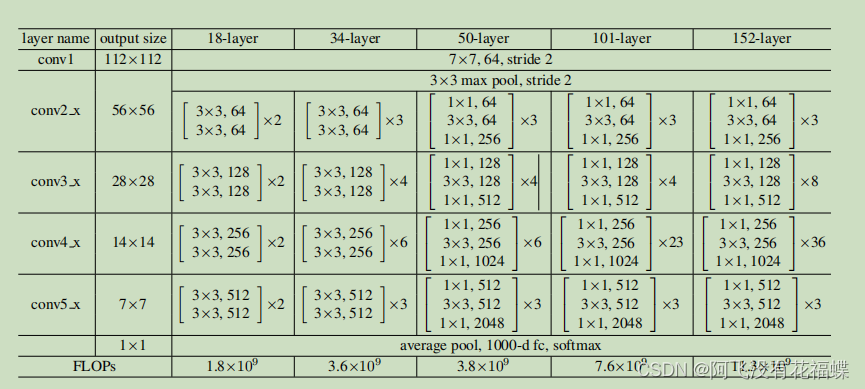
网络结构上,网络模型采用了上图所示的两种形式:with "short connection"的ResNet模块、降采样的ResNet模块,具体网络模型的实现可以去参考相关代码。如下图所示,为5种不同层数的ResNet网络结构。
之后作者做了大量的对比消融实验,证明了ResNet的可行性,实验设计的很有说服力,设计实验的思想可以学习一下,具体设置可详见论文,这里不再赘述。
这里有两个问题需要明确一下:
Q1:既然采用了残差结构,为什么当层数达到10^3的数量级时,会出现退化问题?
A1:当层数达到10^3的数量级时,退化的原因就不是网络结构的问题了,而是因为层级太深,而普通训练的数据集太小,完全不能满足这个级别网络的训练,这就导致了过拟合。
Q2:在ResNet论文中,利用残差网络训练的模型,在训练中会有突然快速收敛?
A1:训练过程中突然收敛快应该是学习率调整策略所导致的,一般网络的训练过程都会设置学习率衰减策略(指数衰减、固定步长衰减、多步长衰减、余弦退火衰减)。
以上就是关于ResNet的学习笔记,如有错误,还请及时指正,我们一起进步!















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









