







什么是优化器
在深度学习中,有损失的概念,损失告诉了我们模型在当前时刻的表现,我们需要利用损失来优化我们的模型,使其性能更好,那么如何优化呢?实际上,我们需要做的是计算损失,并且尽量将损失减小。神经网络的每一层都有很多的权重,这些参数决定着网络的输出,也决定着损失的大小,因此,以减小损失的方式更新权重,这个过程就叫做优化。优化器的作用就是优化网络。
常用的优化器
SGD(随机梯度下降)
每次只选择一个样本的数据来进行更新梯度。优点是参数更新快,缺点是每次更新采用的数据量小,容易震荡。
公式如下:
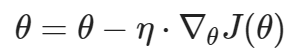
BGD(批量梯度下降)
每次迭代会使用全部的数据来更新梯度。优点是梯度更新平滑,缺点是参数更新较慢。
公式如下:
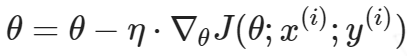
MBGD(小批量梯度下降)
小批量随机梯度下降可以看作是 SGD 和 BGD 的中间选择,每次选择数量为 n 的数据进行计算,既节约的每次更新的计算时间和成本,也减少了 SGD 的震荡,使得收敛更加快速和稳定。
公式如下:

momentum(动量)
主要解决随机梯度下降时的震荡问题,通过加入一个momentum参数,以本次计算得到的梯度和上次梯度更新的加权和作为本次要更新的梯度,加速网络收敛,同时抑制震荡,但是有可能难以找到最优点,因此在模型训练的后期通常会将其关闭。
公式如下:
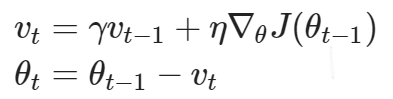
Adagrad
Adagrad(adaptive gradient algorithm),实际上是在梯度更新时依据每个参数的重要程度对其进行自适应加权,具体做法是对不同参数使用不同的学习率,对于更新频率较低的参数施以较大的学习率,对于更新频率较高的参数用以较小的学习率。
RMSprop
主要解决Adagrad学习率会急剧下降的问题。
Adam
Adam(adaptive moment estimation)是目前最常被采用的优化器,是每个参数自适应学习率的方法。相当于RMSprop和momentum的结合。
















 5071
5071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











