






 文章详细阐述了Vue页面加载时如何请求后台数据,包括getList方法中的分页查询逻辑,使用PageHelper进行分页处理,以及getDeptTree方法中构建树状图的过程,同时提到了部门ID在表单数据更新中的作用,以及dict字典的使用。
文章详细阐述了Vue页面加载时如何请求后台数据,包括getList方法中的分页查询逻辑,使用PageHelper进行分页处理,以及getDeptTree方法中构建树状图的过程,同时提到了部门ID在表单数据更新中的作用,以及dict字典的使用。
流程:加载Vue页面-- – >页面初始化请求后台数据
一、加载Vue页面
由上一讲可知,下图所示页面中,其Vue代码在ruoyi-ui\src\views\system\user\index.vue路径下。
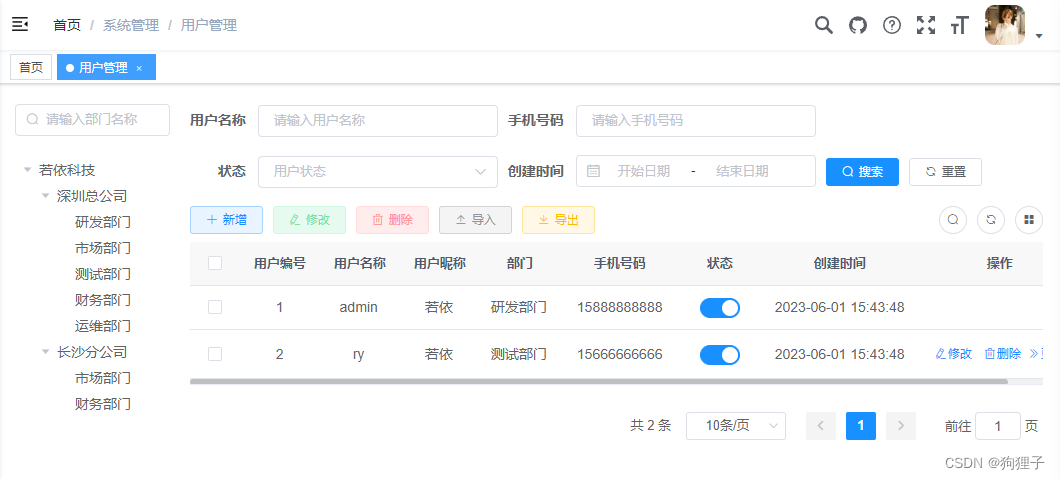

二、请求后台数据
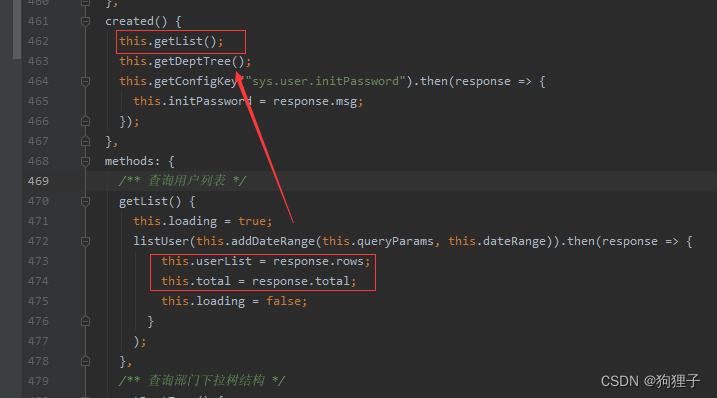
一个页面若要请求数据,则必定是在其初始化的时候,因而直奔对应index.vue中的created()方法:
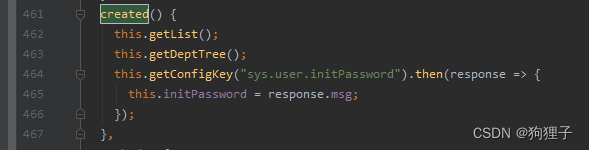
可明显看出这里请求了三次数据,其中getList和getDeptTree分别获取表单信息和树状图信息。
1、getList()方法:
- 首先看前端中的代码:
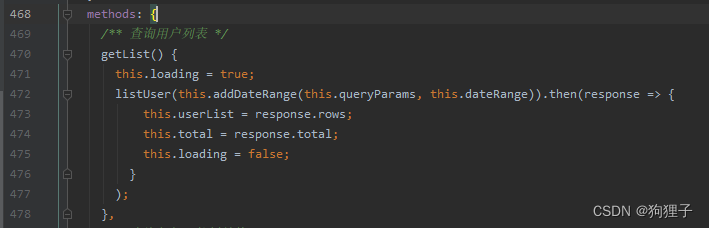
这里的this.loading = true;是用于在加载时,给一个加载效果(一般在接下来的函数成功执行后的回调中会把它改为false);接下来看一下listUser()的代码:
发现对后台发送带有参函数的request请求,这里的query可在后台使用ServletUtils.getParameter()方法获取。
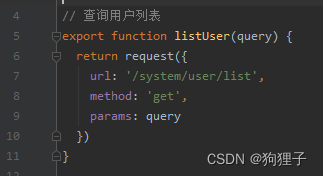
- 然后来看后台的代码:
(其中/system/user是对Controller层进行映射,/list是对list()方法进行映射)
- startPage()方法讲解
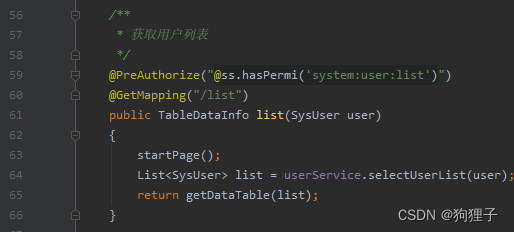
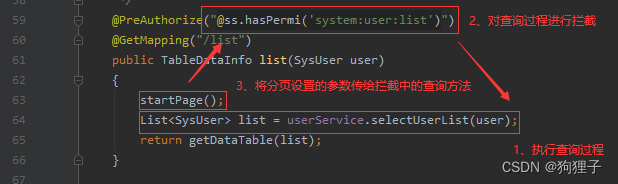
其中@PreAuthorize("@ss.hasPermi('system:user:list')")这一句用于检验当前用户是否拥有system:user:list权限,若有才能访问。startPage()用于设置分页,startPage()讲解如下:
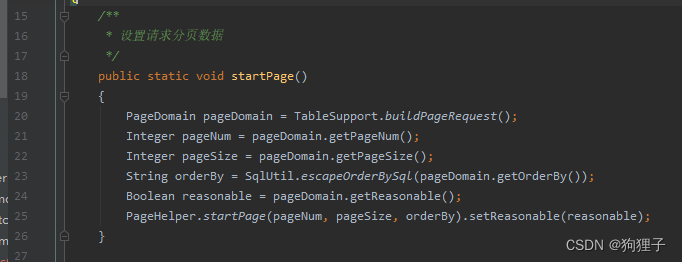
a.分页步骤:startPage()使用PageHelper结合MyBatis实现分页。 一、 其中PageHelper可以单独设置分页参数(如:当前第几页,每页设置多少参数),然后将这些参数存入到一个Thread中,之后在查询执行时获取当前线程中的分页参数,执行查询的时候通过拦截器,自动的在sql语句中添加分页参数,便可完成分页查询。(它要做的事便是将分页参数设置到PageHelper提供的对象中便可)(以此实现查询和分页的解耦合)。 二、 过程:1.先创建pageDomain对象用于获取分页信息,从http请求中获取分页参数,具体获取方式可以看buildPageRequest()方法中就是对PageNum、PageSize以及OrderByColumn等信息通过使用封装的ServletUtils.getParameter()等进行初始化设置;-- --> 2.在pageDomain中将pageNum和pageSize取出;-- --> 3.设置orderBy(依照什么字段排序)和reasonable(对参数进行逻辑处理,以此保证pageNum参数的正确性); – --> 4.调用PageHelper.startPage()将上面那些参数传进Thread中去,startPage()的任务便完成了。
线程的初学习
b.查询步骤:List<SysLogininfor> list = logininforService.selectLogininforList(logininfor);这一句实现查询过程。
– – > 分页逻辑抽象过程:
c.返回结果:使用return getDataTable(list);来返回结果,并将结果封装成一个DataTable的数据格式,以供前端表格的使用。
4. selectUserList的查询过程
跟进service层中:
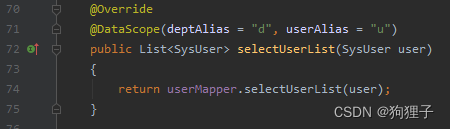
再进入对应的mapper层,执行相应sql语句。

最终返回的对象便是封装后的admin和ry那两个用户的相关数据
5. getDataTable():
前后端分离的封装。
已知后台给前端返回数据时,一定有特定的格式(如:前面讲解中返回使用的AjaxResult类型),而这里便是使用getDataTable方法返回代码中设置的这些数据:
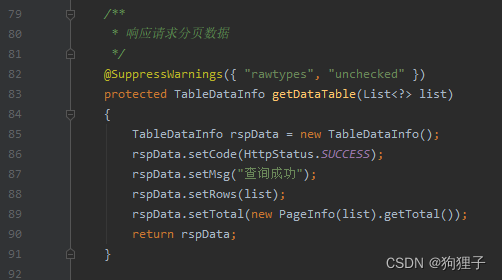
这里 @SuppressWarnings({ "rawtypes", "unchecked" })中的@SuppressWarnings注解用于去除警告。
最终,返回到前端的getList()方法中,并对userList和total进行赋值操作,并在vue中加载出表格。
getList()流程笔记总结!!!
2、getDeptTree()方法
-
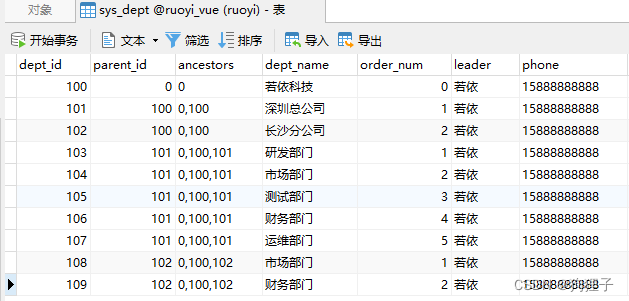
数据库:
所用数据库表为sys_dept。其思路大致为:前端发请求 --> 从数据库把数据弄出 --> 后端想办法把数据转为树状 --> 返回前端。 -
看前端中代码:
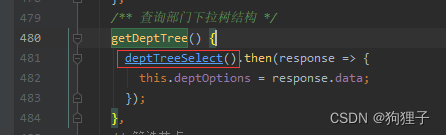
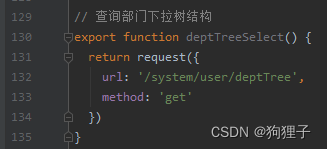
紧接着去后端找请求的方法。 -
看后端中代码:
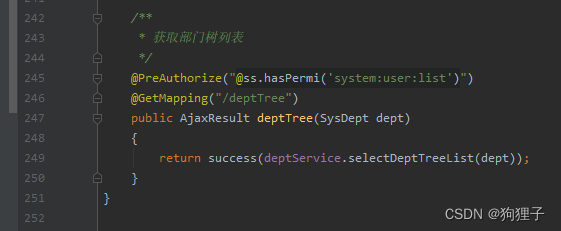
其中success()方法用于将其中参数封装为AjaxResult类型,便于前端统一接收使用。(前后端交互固定格式)
再对使用方法追踪:
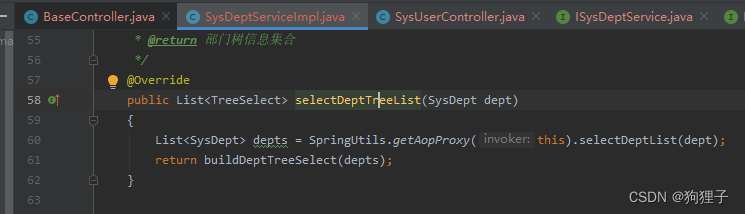
-
后端DeptService实现类中
SpringUtils.getAopProxy(this)方法的作用:
在若依框架中,接口可能存在多个切面,这些切面用于实现不同的功能,如事务管理、日志记录等。而在此情形下若直接调用selectDeptList方法,只会执行该方法本身的业务逻辑,而不会执行其他切面的逻辑,也就是不会执行如下图所示的selectDeptList()方法中的@DataScope(deptAlias = “d”) 数据权限验证逻辑。
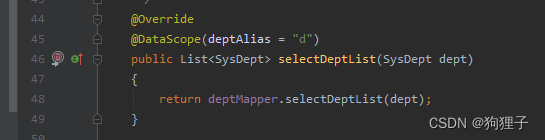
因此,为保证所有的切面逻辑都能得到执行,需要通过Spring AOP的代理机制来获取对象,然后再调用selectUserList方法。通过SpringUtils.getAopProxy(this)这个方法,获取到当前对象的AOP代理对象,从而在调用selectUserList方法时,能够触发所有的切面逻辑。使得最终返回的List< SysDept >对象包含所有切面的处理结果,从而有效提高代码的灵活性和可维护性。 -
后端DeptService实现类中
selectDeptList(dept)的作用:(查出所有部门数据)
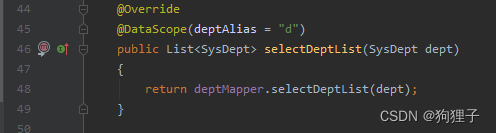
继续向mapper中追踪,看到sql语句
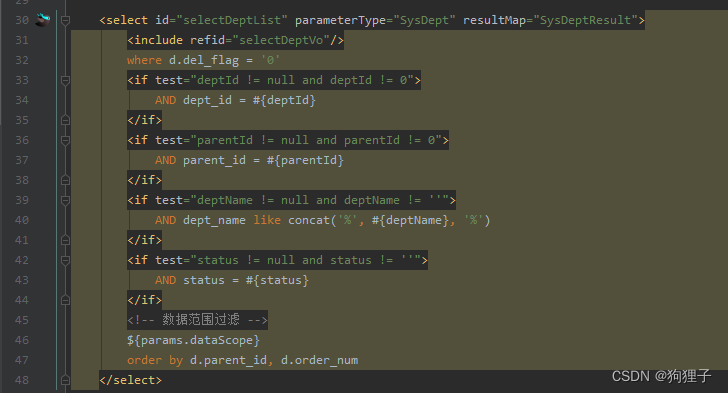
对于selectDeptTreeList()方法,执行前,dept的内容展示如下:
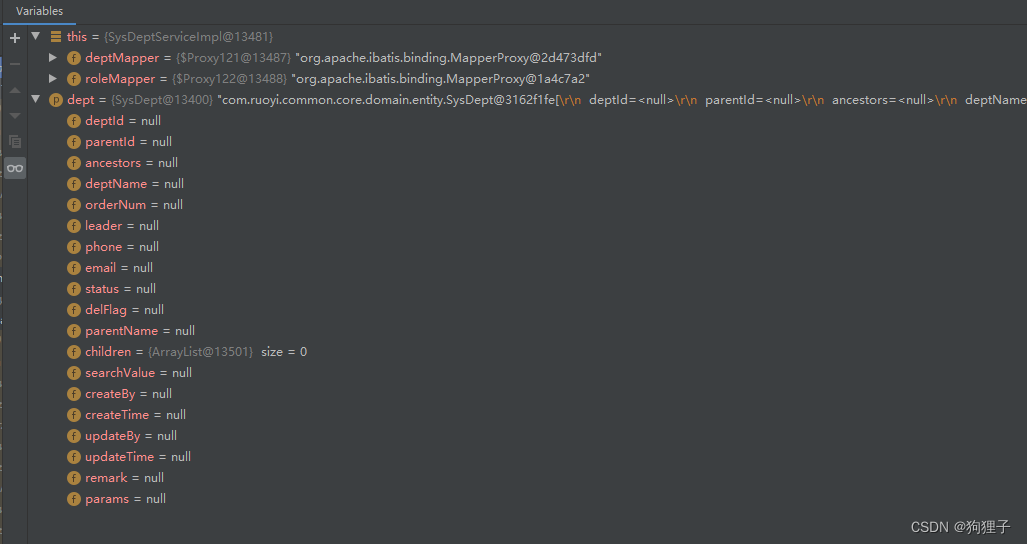 该方法执行后,dept内容仍为空,但依据sql语句所找出的depts集合中有10条对象,展示如下:
该方法执行后,dept内容仍为空,但依据sql语句所找出的depts集合中有10条对象,展示如下:
-
后端DeptService实现类中
buildDeptTreeSelect方法的作用:(将depts数据组装成树状结构)
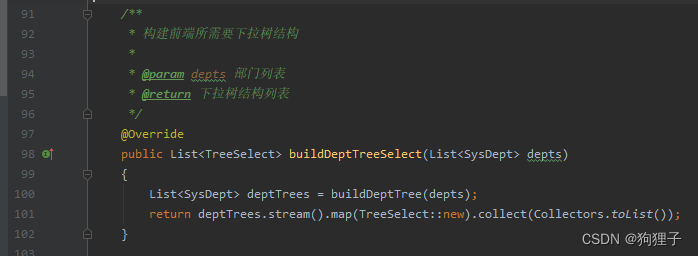
==》首先需要从数据库中构建起dept_id和parent_id的逻辑关系
==》然后再通过Java实现
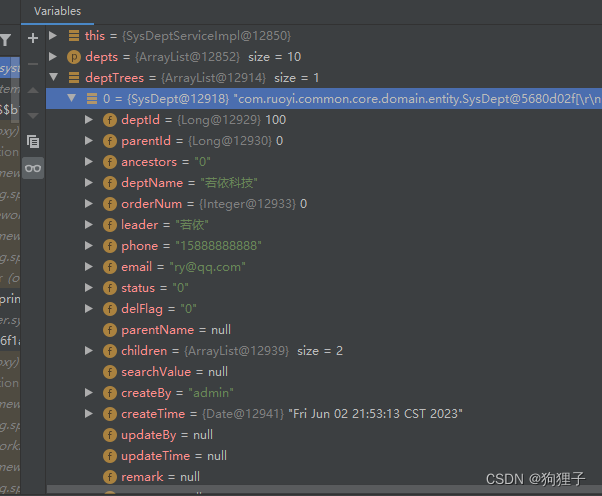
6.1.其中buildDeptTree(depts)是核心语句,通过debug可发现,原本集合depts中的10条平行数据,在经过此方法后,产生了1条树状图数据,并从其中children中可以以此找到之前的10条数据。

那么来看一下buildDeptTree(depts)是如何实现的:
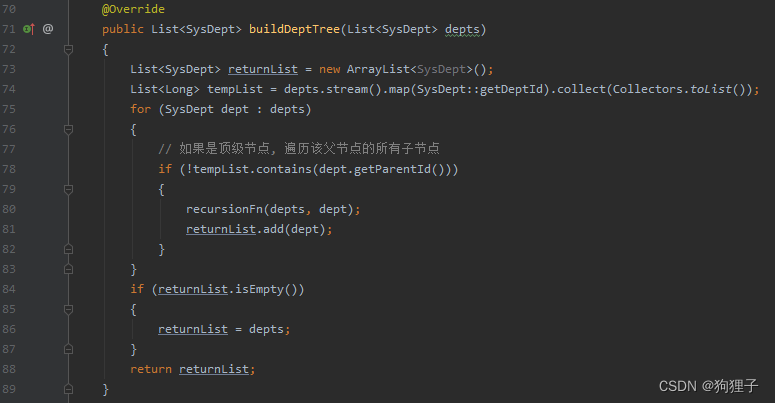
!!可以看到在对depts树状数据进行遍历的时候先是使用stream流depts.stream().map(SysDept::getDeptId).collect(Collectors.toList())把SysDept实体类对象合集数据放到map根据SysDept实体类对应的getDeptId方法循环,转换为Long型的List;然后在找到顶级结点的情况下,再使用recursionFn(depts,dept) 参数分别为当前集合与当前对象的递归方法将子节点按倒父节点下(类似动态菜单路由的实现)(具体recursionFn代码见项目)。
由此可知,下图中拿到的deptTrees,为已经组装好的数据:

6.2.利用stream流返回(stream流的使用)
return deptTrees.stream().map(TreeSelect::new).collect(Collectors.toList())的功能是给改一下泛型,即将原本为SysDept类型的deptTrees集合中的对象拿出,全部封装为TreeSelect类型,再放到一个集合中。(即从大量数据中只保存自己需要的部分:属性名一样直接去读,不一样通过注解映射)前后对比如下图所示:(前者与数据库匹配,后者与前端匹配)
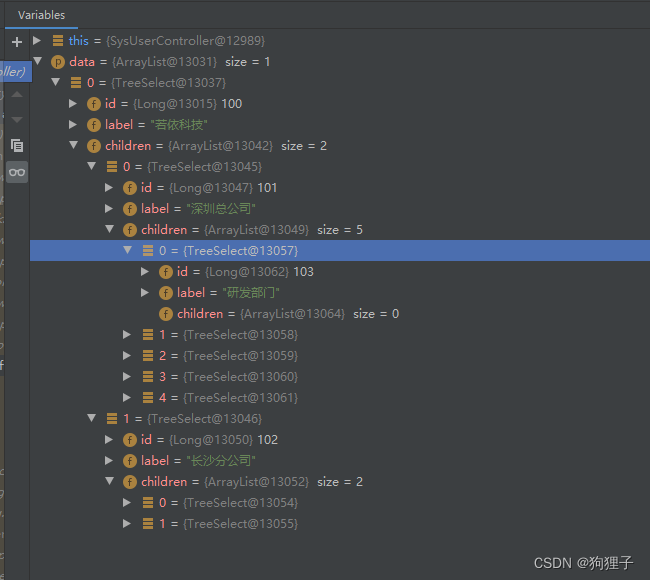
-
带着树状数据返回前端
接收返回的数据:
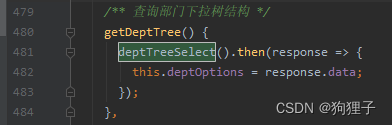
显示树状图:
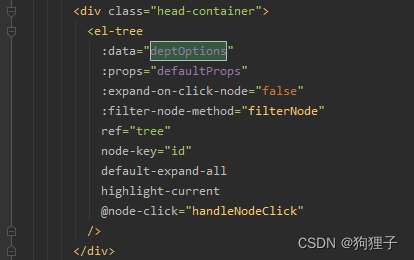
3、点击树状图后表单数据随之变化的代码解读
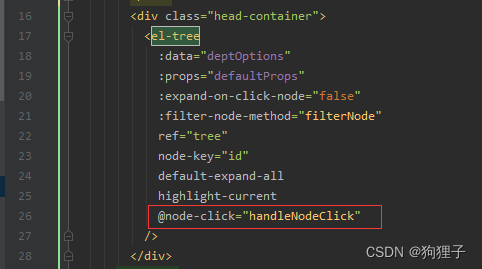
可看到树状图的点击事件’handleNodeClick’
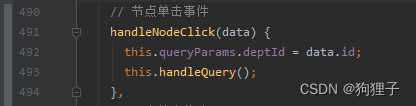
再看’handleQuery’方法,其中又调用了getList方法来加载用户信息,(注意!!! 这里使用是有条件的,在使用handleNodeClick方法时,讲点击的部门id拿到并传给了queryParams.deptId,此时会将此参数传到后台,然后再调用getList方法通过部门id进行条件查询)
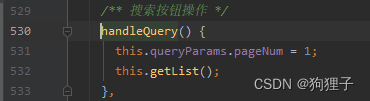
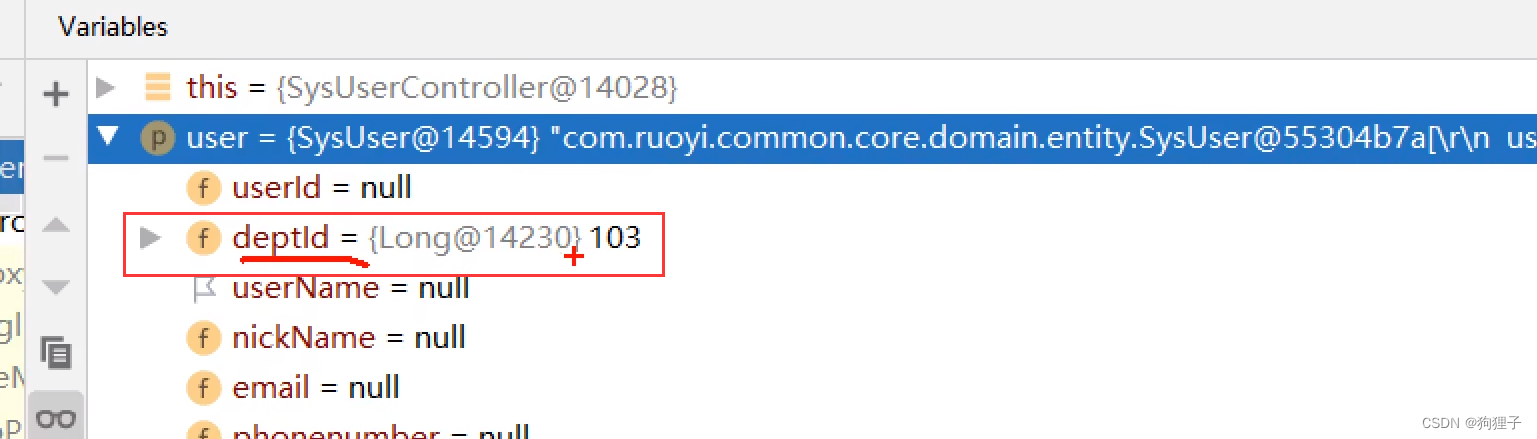
这里的deptId在显示表单时是为null的,只有点击树状图后,这里的getList方法才会给deptId变量赋值(通过queryParams.deptId)

















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









