






此脚本功能为将VOC转YOLO格式,并划分训练集,验证集和测试集。小白式修改,只需修改parser.add_argument中的默认值即可。
主要为分为三个点:
1、标签和对应数字以字典形式的键值对必须一一对应,由于是字典存储,键和值的位置可以随意,例如:{'apple':0,'banana':1}和{'banana':1,'apple':0}效果一样。
2、将default修改为指定存放xml文件夹地址(只包含),存放images文件夹地址(只包含),out_path地址可以不新建文件夹,脚本运行后会自动生成,但在default中需要指明该文件存放在何处。
3、指定训练集,验证集,测试集比例
注意点:
1、此脚本会检测数据中宽高为0,不能被除0的数据,不用于转化。
2、尽量用绝对路径,我用相对路径有时候容易出错。如果在复制绝对路径时出现了转义字符,将'\'改为‘/’即可。
import os
import xml.etree.ElementTree as ET
import random
from shutil import copyfile
import argparse
def get_normalized_box(box, image_width, image_height):
xmin = float(box.find("xmin").text) / image_width
ymin = float(box.find("ymin").text) / image_height
xmax = float(box.find("xmax").text) / image_width
ymax = float(box.find("ymax").text) / image_height
return ((xmin + xmax) / 2, (ymin + ymax) / 2, xmax - xmin, ymax - ymin)
count_zero_dimensions = 0
files_with_zero_dimensions = []
train_images_count = 0
val_images_count = 0
test_images_count = 0
total_images_count = 0
original_images_total_count = 0
def convert_xml_to_txt(xml_path, out_path, split, class_mapping):
global count_zero_dimensions, files_with_zero_dimensions, train_images_count, \
val_images_count, test_images_count, total_images_count, original_images_total_count
if not os.path.exists(out_path):
os.makedirs(out_path)
filename = os.path.splitext(os.path.basename(xml_path))[0]
txt_file = open(os.path.join(out_path, filename + ".txt"), "w")
root = ET.parse(xml_path).getroot()
size = root.find("size")
width = int(size.find("width").text)
height = int(size.find("height").text)
if width == 0 or height == 0:
count_zero_dimensions += 1
files_with_zero_dimensions.append(filename)
print(f"Warning: {filename} has zero width or height. Excluding this data.")
return
for obj in root.iter("object"):
name = obj.find("name").text
index = class_mapping.get(name)
if index is not None:
box = get_normalized_box(obj.find("bndbox"), width, height)
txt_file.write("%s %.6f %.6f %.6f %.6f\n" % (index, *box))
else:
print(f"Warning: Unknown class '{name}' in {xml_path}")
txt_file.close()
print(f"{xml_path} converted for {split}")
if split == "train":
train_images_count += 1
elif split == "val":
val_images_count += 1
elif split == "test":
test_images_count += 1
total_images_count += 1
def split_dataset(original_images_folder, annotations_folder, out_path, class_mapping,
train_ratio=0.8, val_ratio=0.1, test_ratio=0.1):
global original_images_total_count, count_zero_dimensions, files_with_zero_dimensions, \
train_images_count, val_images_count, test_images_count, total_images_count
file_list = os.listdir(annotations_folder)
random.shuffle(file_list)
train_split = int(len(file_list) * train_ratio)
val_split = int(len(file_list) * (train_ratio + val_ratio))
train_files = file_list[:train_split]
val_files = file_list[train_split:val_split]
test_files = file_list[val_split:]
# Create output folders
os.makedirs(os.path.join(out_path, "images", "train"), exist_ok=True)
os.makedirs(os.path.join(out_path, "images", "val"), exist_ok=True)
os.makedirs(os.path.join(out_path, "images", "test"), exist_ok=True)
os.makedirs(os.path.join(out_path, "labels", "train"), exist_ok=True)
os.makedirs(os.path.join(out_path, "labels", "val"), exist_ok=True)
os.makedirs(os.path.join(out_path, "labels", "test"), exist_ok=True)
for file in file_list:
annotation_path = os.path.join(annotations_folder, file)
original_images_total_count += 1
# Only convert and copy when width and height are both non-zero
root = ET.parse(annotation_path).getroot()
size = root.find("size")
width = int(size.find("width").text)
height = int(size.find("height").text)
if width == 0 or height == 0:
count_zero_dimensions += 1
files_with_zero_dimensions.append(file)
print(f"Warning: {file} contains zero width or height...Excluding this data")
continue
for split, files in [("train", train_files), ("val", val_files), ("test", test_files)]:
if file in files:
output_folder_images = os.path.join(out_path, "images", split)
output_folder_labels = os.path.join(out_path, "labels", split)
convert_xml_to_txt(annotation_path, output_folder_labels, split, class_mapping)
copyfile(os.path.join(original_images_folder, file.replace(".xml", ".jpg")),
os.path.join(output_folder_images, os.path.basename(file.replace(".xml", ".jpg"))))
print(f'Total occurrences of zero width or height: {count_zero_dimensions}')
print(f'Files with zero width or height: {tuple(files_with_zero_dimensions)}')
print(f'Total number of images in the original dataset: {original_images_total_count}')
print(f'Total number of images in the dataset after excluding zero width or height: {total_images_count}')
print(f'Number of images in the training set: {train_images_count}')
print(f'Number of images in the validation set: {val_images_count}')
print(f'Number of images in the test set: {test_images_count}')
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Process some images and annotations.')
# 把标签和代表标签的数字以字典形式对应好
parser.add_argument('--class_mapping', type=dict, default={'apple':0, 'banana':1, 'orange':2},
help='Mapping of class names to indices')
# default改为只存放图片的地址
parser.add_argument('--original_images_folder', type=str,default='Y:\yolov5-v7.0\my_dataset/fruits\images',
help='Path to the folder containing original images')
# default改为只存放xml的地址
parser.add_argument('--annotations_folder', type=str,default='Y:\yolov5-v7.0\my_dataset/fruits/annotations',
help='Path to the folder containing annotations')
# 指定一个路径存放转化后的训练集,验证集,测试集,最后一级地址可以不用建文件夹会自动生成
parser.add_argument('--out_path', type=str,default='Y:\yolov5-v7.0\my_dataset/fruits/xml_to_yolo',
help='Output path for processed images and labels')
# 指定训练集,验证集,测试集所占比例
parser.add_argument('--train_ratio', type=float, default=0.8, help='Ratio of images for training set')
parser.add_argument('--val_ratio', type=float, default=0.1, help='Ratio of images for validation set')
parser.add_argument('--test_ratio', type=float, default=0.1, help='Ratio of images for test set')
args = parser.parse_args()
original_images_folder = args.original_images_folder
annotations_folder = args.annotations_folder
out_path = args.out_path
class_mapping = args.class_mapping
split_dataset(original_images_folder, annotations_folder, out_path, class_mapping,
train_ratio=args.train_ratio, val_ratio=args.val_ratio, test_ratio=args.test_ratio)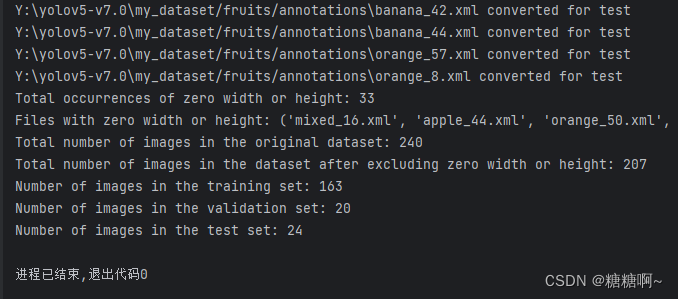
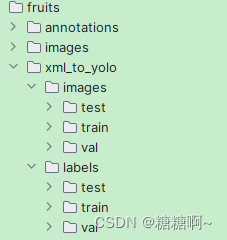
运行结果如上所示。














 2653
2653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









