







Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding
CVPR 2023 基于稀疏掩膜的条件扩散模型视觉解码

背景
了解大脑活动并恢复编码信息是认知神经科学的关键目标,但由于脑信号的复杂潜在表征以及相关数据(fMRI-image)标注的稀缺,从大脑活动记录中重构出具有正确语义的高质量图片是一个充满挑战的问题。
主要贡献
提出MinD-Vis: Sparse Masked Brain Modeling with Double-Conditioned Latent Diffusion Model for Human Vision Decoding,该框架利用大规模表征学习模拟大脑中的稀疏编码(包括视觉皮层),此外,本文使用了更大的表征-数据空间比来提高已学习表征的信息容量。
- 提出Sparse-Coded Masked Brain Modeling(SC-MBM),它是在生物学指导下设计的有效视觉解码脑特征学习器;
- 增强双条件潜在扩散模型(latent diffusion model with double conditioning , DC-LDM),加强解码的一致性,并允许相同语义下的差异;
- 结合SC-MBM的表征能力与DC-LDM的生成能力,与之前的方法相比,MinD-Vis生成的图像更可信,语义信息保存更好;
- 对多个数据集执行定量和定性测试,包括以前未用于评估此任务的新数据集。
主要内容与方法
动机
- 功能磁共振成像(fMRI)测量脑血氧水平依赖性(BOLD)变化为3D体素,作为大脑活动潜在变化的代理。相邻体素通常具有相似的幅度,表明fMRI中存在空间冗余。
- fMRI数据是在刺激出现期间的平均数据。在视觉处理层次中,一个ROI通常被提取为体素的一维向量,而体素数量通常比像素数量少(ROI size < image size),这使得fMRI转换为image时有很大的维度差异。
- 由于实验条件和扫描仪设置的不同,来自不同数据集的fMRI数据可能有显著的域偏移;即使在相同的扫描条件下,由于个体差异,ROI大小和位置不匹配仍然存在。
本文方法概述
基于上述分析,本文提出MinD-Vis,包括两个阶段:
- Stage A:在把掩膜信号建模作为pretext task的大fMRI数据集中训练得到自编码器,从而学习fMRI表征,并将学到的表征作为Stage B图像生成过程的条件。
- Stage B:通过交叉注意(cross-attention)和时间步调节(time-step conditioning)进行条件合成,将Stage A中得到的fMRI编码器与LDM集成。在这个阶段,编码器使用配对注释与LDM中的交叉注意头进行联合微调。
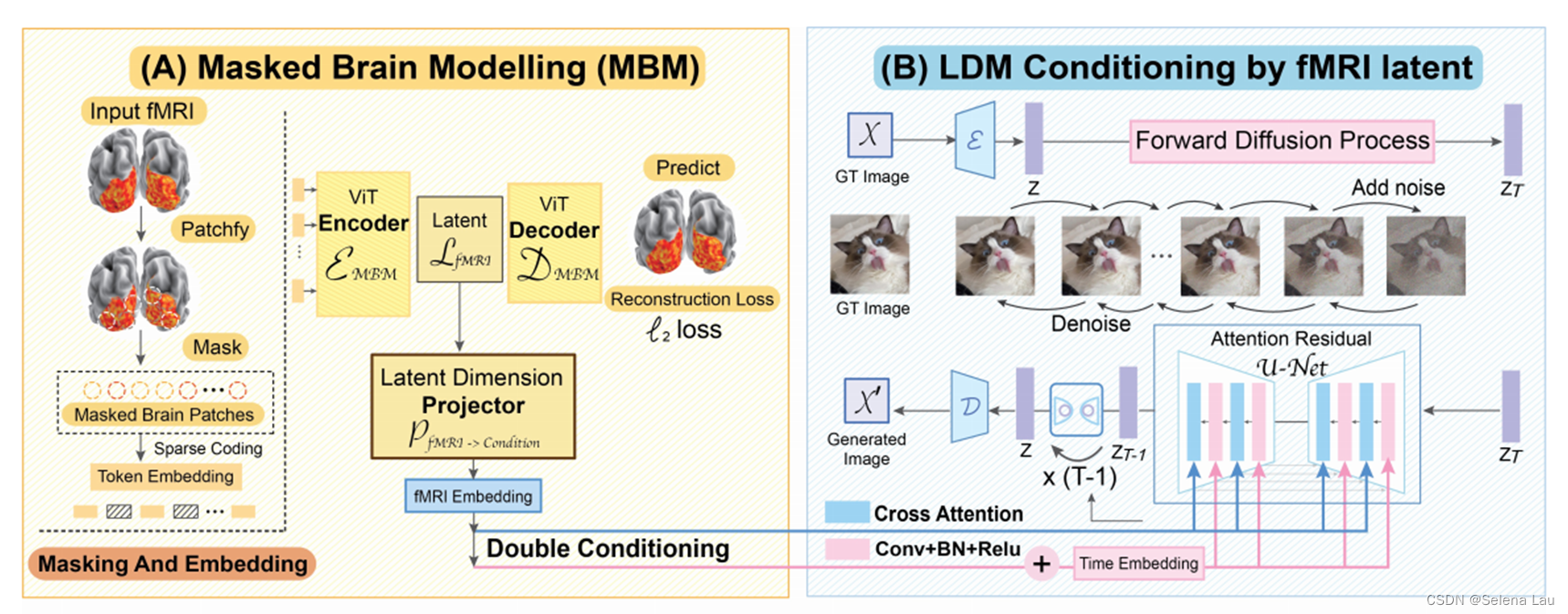
Stage A: Sparse-Coded MBM (SC-MBM)
- 测量BOLD的fMRI是一种对神经元活动的间接和汇总的测量,可以通过功能网络进行分层分析,而由fMRI数据体素组成的功能网络在响应外部刺激时存在隐式相关性,通过恢复掩膜体素来学习这些隐含的相关性将使预训练模型对fMRI数据有深入的上下文理解。然后将矢量化的体素分成小块,然后使用步长等于小块大小的一维卷积层将小块转换成嵌入。
- 由于fMRI中存在空间冗余,即使屏蔽了很大一部分fMRI数据,仍然可以恢复fMRI数据。因此,在MinD-Vis的第一阶段,可以在不失去掩膜建模的学习能力的情况下,屏蔽了很大一部分fMRI块,以节省计算量。
- Masked Image Modeling (MIM)使用embedding-to-patch-size比约为1,使得表征大小与原始数据大小相似。本文使用了较大的比值,在较大的fMRI表征空间下显著增加了信息容量。这种设计也与大脑中信息的稀疏编码有关,被认为是表征感觉信息的一般策略。
- 本文还采用了非对称架构,编码器学习有效的fMRI表征,而解码器预测被掩膜的patch。因此,本文将解码器的尺寸减小,只要预训练收敛,在Stage B中丢弃解码器。
视觉编码与脑启发稀疏编码:
本文从视觉编码机制的角度阐述了SC-MBM学习视觉刺激表征的生物学基础。理论和实证研究表明,视觉刺激在初级视觉皮层中是稀疏编码的,大多数自然图像仅激活视觉皮层中的部分神经元。这种策略提高了信息传递效率,并在大脑中产生最小的冗余。因此,通过不同的成像方式,包括功能磁共振成像(fMRI),可以从初级视觉皮层收集的一小部分数据中重建自然场景的视觉信息。说明稀疏编码也可以成为计算机视觉中视觉编码的有效方法。
稀疏编码本质上是一种使用过完备基来表示数据的编码策略,通过更多局部性来生成更平滑的表征。
在SC-MBM中,fMRI数据被划分成小块以引入局部性约束。然后将每个patch编码成一个比原始数据空间大得多的高维向量空间,从而为fMRI表征创造了一个过完备的空间。SC-MBM模拟脑视觉编码,是一种生物学上有效的脑特征学习器,可用于fMRI解码。
Stage B: Double-Conditioned LDM (DC-LDM)
为了进一步从Stage A得到的抽象表征中解码视觉内容,并允许采样差异,本文将解码任务制定为一个条件合成问题,并使用预训练的LDM进行处理。
- LDM一般时对把输入放到矢量量化编码器得到的图像潜在空间进行操作,但本文简化将输入直接作为LDM潜在变量的表征。特别是给出fMRI数据z,旨在通过
q
(
x
t
−
1
∣
x
t
,
z
)
q(x_{t-1}|x_t, z)
q(xt−1∣xt,z)学习反向扩散过程;条件信息是通过基于注意力的UNet中的cross-attention heads进行应用,其中:


- 在对条件生成模型进行采样时,多样性和一致性是两个相反的目标。在许多图像生成任务中,跨模态(如标签到图像和文本到图像)的采样多样性非常重要。然而,fmri到图像的转换更多地依赖于生成一致性——来自相似大脑活动的解码图像预期应该是语义相似的。因此,特别是对于概率扩散模型,需要一个更强的条件调节机制来保证生成一致性,因此本文使用cross-attention conditioning与time steps conditioning相结合作为更强的条件调节机制。在时间步调节中,把另一个合适的维度映射加入到time step embedding,而其作为UNet的中间层就可以得到:
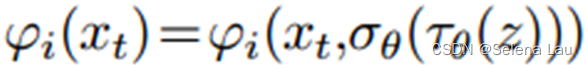
扩散概率模型的优化目标是:
 进而重新表述为双条件:
进而重新表述为双条件:
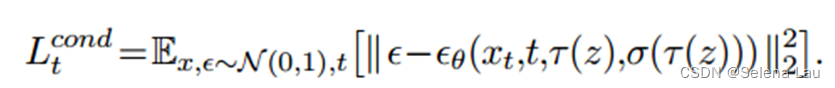
微调:
在用SC-MBM对fMRI编码器进行预训练后,通过双条件作用将其与预训练的LDM集成。通常,编码器的输出是平均的,或者添加一个cls token,为下游任务生成一个池化的一维特征向量。这种策略对于预测和分类等任务是有效的,在这些任务中,学习到的知识需要被提炼出来,产生可区分的特征;但是为了保留fMRI表征的稀疏性和信息容量,将池化成一维向量是不合适的,本文使用卷积层将编码器的输出汇集到一个潜在维度
R
M
×
d
γ
\mathbb R^{M \times d_\gamma}
RM×dγ中。
fMRI编码器、cross-attention heads、projection heads联合优化,其他部分固定。
cross-attention heads的微调是连接预训练条件反射空间和fMRI潜在空间的关键。通过fMRI图像对端到端进行微调,在此过程中,通过大容量的fMRI表征可以学习到fMRI与图像特征之间更清晰的联系。
实验
数据集
- Human Connectome Project (HCP) :通常用于神经科学研究,仅包含功能磁共振成像数据。
- Generic Object Decoding Dataset (GOD) :为fmri解码而设计的fmri图像配对数据集
- Brain, Object, Landscape Dataset (BOLD5000)
上游预训练数据集包括来自HCP和GOD的fMRI数据;
GOD中的配对在我们的主要分析中用于微调。GOD由来自200个不同类别的1250张不同的图像组成,其中1200张图像作为训练集,其余50张图像作为测试集。训练集和测试集没有重叠的类。本文研究使用BOLD5000数据集作为验证数据集。它由来自4916张不同图像的5254对fmri图像组成,其中113张用于测试。这是BOLD5000首次用于fMRI解码任务。
实现
patch size 16
embedding dimention 1024
encoder depth 24
mask ratio 0.75
使用ImageNet class-conditioned pre-trained LDM
评估方法
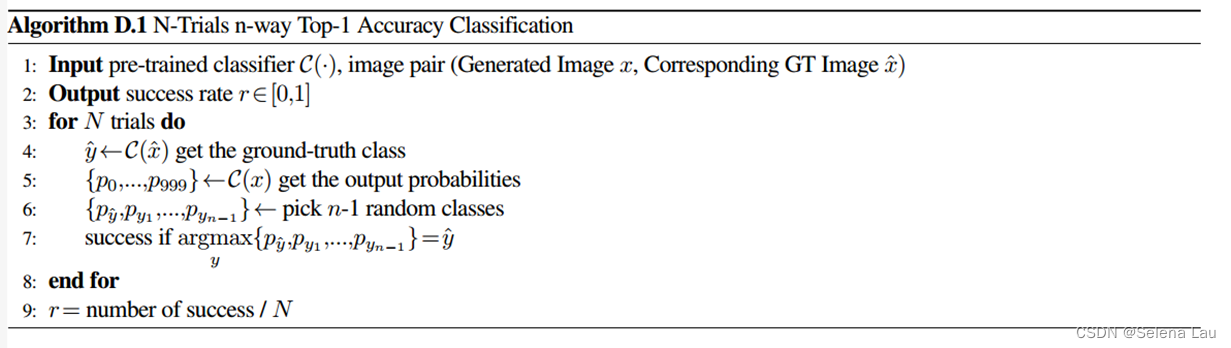
-
N-way Classification Accuracy :使用n-way top-1和top-5准确率分类任务来评估结果的语义正确性,其中对于多次试验,在n−1个随机选择的类别加上正确的类别中计算top-1和top-5分类准确率。本文提出了一种更直接和可重复的方法,其中使用预训练的ImageNet1K分类器来确定生成图像的语义正确性,而不是手工制作的特征。
-
Frechet inception distance (FID) :一种评估图像生成质量的常用指标,由于GOD中可用的图像数量有限,FID在我们的实验中仅用作参考,这可能导致低估分布。
结果

实验过程中发现,在某些情况下观察到颜色不匹配,但色差保存得很好。这表明在额叶中,颜色类别信息是作为一个认知过程来处理的,而视觉皮层只识别颜色的差异。

本文方法生成了更多可信的细节,如水和波浪、保龄球上的绘图、马车的轮子等。

通过对相同的fMRI数据在不同的随机状态下进行多次解码,验证了方法的一致性。
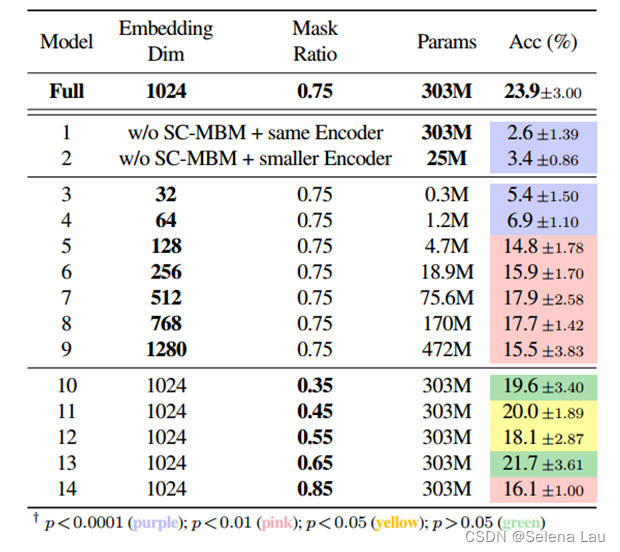
为了证明SC-MBM学习了有用的表征,我们直接使用fmri图像对训练了两个模型,而没有使用SC-MBM预训练。第一个模型由一个未经训练的fMRI编码器组成,其结构与完整模型相同。第二个模型由一个深度仅为2的未经训练的fMRI编码器组成。
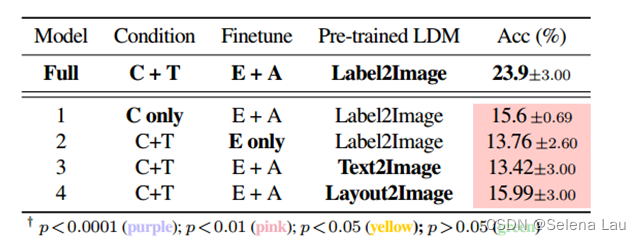
在LAION和OpenImages上(第3行和第4行)预训练的模型生成的图像在视觉上不那么有利和可信。这个结果令人惊讶,因为LAION和OpenImages都包含来自不同类别的不同图像。本文将其表现不佳的主要原因归因于其条件反射潜空间的复杂性。在训练对有限的情况下,类条件反射潜空间比文本条件反射模型和布局条件反射模型的潜空间更容易适应。

BOLD5000上的实验结果。

图中的河流和蓝天,可能反映了受试者在观看视觉刺激时脑海中想象的风景,并被他们的大脑活动所捕获。虚构图像的特征也可以从视觉皮层解码。
总结
局限性
目前MinD-Vis缺乏强大的像素级引导和解释分析,这限制了其像素级性能和对MBM学习的特征的生物学理解。
未来工作
与其他工作相似,本文MinD-Vis只关注使用视觉皮层的个人解码。但作为一个复杂的认知过程,人类视觉可能受到视觉皮层以外区域的影响。因此,未来的研究应扩展到跨学科的推广,并纳入其他大脑区域。
Conclusion
本文提出了一个两阶段的MinD-Vis框架,仅使用来自大脑记录的少数成对的fmri图像注释来解码视觉刺激。在Stage A中,采用了一种带有掩膜建模的fMRI预训练方法,从大规模未标记的fMRI数据集中学习可泛化的上下文知识;在Stage B中,使用具有双条件的潜在扩散模型从学习到的fMRI表征中生成可信的可见图像。本文在多个数据集上验证了MinD-Vis的解码结果,并表明与以前的方法相比,本文提出的模型生成了更可信和语义相似的图像,将最先进的技术向前推进了相当大的一步。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









