







论文:Hybrid Ranking Network for Text-to-SQL
⭐⭐⭐
arXiv:2008.04759
HydraNet 也是利用 PLM 来生成 question 和 table schema 的 representation 并用于生成 SQL,并在 SQLova 和 X-SQL 做了改进,提升了在 WikiSQL 上的表现。
一、Intro
论文总结了 WikiSQL 上做 Text2SQL 的 3 个挑战:
- 如何融合来自 NL question 和 table schema 的信息,这是由 encoder 处理的;
- 如何保证输出的 SQL 查询是可执行且准确的,这是由 decoder 处理的;
- 如何利用 PLM。
本篇模型主要解决第 3 个问题,同时顺带解决了前两个问题。本论文认为,之前的方法没有很好地将 task model 和 PLM 对齐,从而导致 PLM 的力量被 task model 削弱,比如 SQLova 和 X-SQL 都是在 BERT 编码结果上施加了另外的 pooling 层(如添加 LSTM 操作等),这带来了信息丢失和不必要的复杂性。但本文是充分利用 BERT 的功能,认为 [CLS] 的 output representation 捕获了 question 和 columns 的所有融合信息,这也正是 decoder 所需要的 column vector,因此,本文工作没有应用进一步的 pooling 或者额外的复杂曾,这让模型结构更加简单高效。
二、HydraNet
HydraNet 将 Text2SQL 视为一个多任务学习问题。
2.1 PLM 的 encode
给定一个 question q q q 和候选列 c 1 ∼ c k c_1 \sim c_k c1∼ck。
针对每一个 column c i c_i ci,我们为它构造一个 pair:

其中:
- Concat 表示字符串的拼接,本文使用空格连接
- ϕ c i \phi_{c_i} ϕci 表示 column c i c_i ci 的类型:string、real 等
- t c i t_{c_i} tci 表示 c i c_i ci 的 table name
然后,将 concat 的拼装结果作为 x,question 作为 y,得到下面的 token 序列:

将上面的 token seq 输入给 BERT 做编码,从而得到 seq representation。
2.2 Tasks
本文考虑没有嵌套结构的 SQL query,这里将一个 SQL 表述为以下的形式:
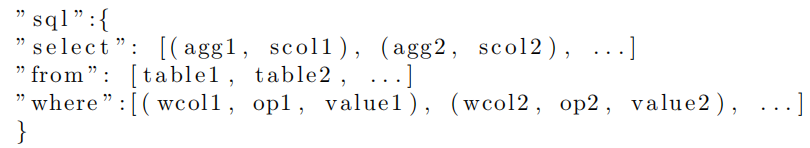
也就是一个 SQL 包括 SELECT、FROM、WHERE 这三个部分。
我们将上面的 SQL query 中的 objects 分为两类:
- 与特定 column 有关联的 objects:比如 aggregator、value text span
- 与特点 column 无关的全局 objects:比如 select-num(select 从句的个数)和 where-num(where conditions 的个数)
2.2.1 对与 column 有关的 objects 的预测
对于每个 col-question 的 pair ( c i , q ) (c_i, q) (ci,q),对于上面 1 中的与 column 有关的 objects 的预测可以被视为对 sentence pair 的分类或者 QA task。
使用 BERT 输出的 seq representation 来做预测:
- 对于一个 aggregator a j a_j aj 的预测:将 h [ C L S ] h_{[CLS]} h[CLS] 经过一个仿射变换再经过一个 softmax 后做分类。
- 对一个 condition operator o j o_j oj 的预测:也是将 h [ C L S ] h_{[CLS]} h[CLS] 经过一个仿射变换再经过一个 softmax 做分类。
- 对 value text span 的 start index 和 end index 的预测:分别计算 question 中每个 token 作为 start index 和 end index 的概率,并选择概率最大的作为 start 和 end 形成 text span。
2.2.2 对于与 column 无关的 objects 的预测
为了预测 select-num n s n_s ns,计算出概率 P ( n s ∣ q ) P(n_s | q) P(ns∣q),然后能够让这个概率最大的 n s n_s ns 值就是预测的结果。这个概率的计算公式为:

其中, P ( n s ∣ c i , q ) P(n_s | c_i, q) P(ns∣ci,q) 可以被视为一个 sentence pair 的分类; P ( c i ∣ q ) P(c_i | q) P(ci∣q) 可以被视为 column c i c_i ci 和 question q q q 的 similarity,它的具体计算可以参考下一节。
与 n s n_s ns 类似,where-num n w n_w nw 的预测方式也是几乎一模一样。
2.2.3 Column Ranking
对于所有候选的所有 columns,我们需要计算出两个 rank:SELECT-Rank 和 WHERE-Rank,是根据是否存在于 SELECT 或 WHERE 语句中的分数的排名。
对于 SELECT-Rank 的排名分数的计算方式如下:

也就是利用 h [ C L S ] h_{[CLS]} h[CLS] 来计算。同样,WHERE-Rank 的分数计算也是如此。
以上这个公式也就是计算出的 P ( c i ∣ q ) P(c_i | q) P(ci∣q),可以用于上一节的计算。
基于排名分数,就可以做排名了。做出排名后,SELECT-Rank 的前 select-num 就可以作为选出的 SELECT 中的 columns 结果了,另外的 WHERE 的 columns 的选择也是如此。
2.3 Execution-guided decoding
论文还使用 Execution-guided decoding 来防止生成的 SQL 出现错误。
三、总结
在 WikiSQL 上做了实验,发现 HydraNet 的性能优于其他方法。尤其值得注意的是,其表现甚至与使用了 MT-DNN 作为 PLM 的 X-SQL 效果一样好,尽管 MT-DNN 明显比 BERT-Large 要好。
另外,HydraNet 的架构更加简单,参数也更少,它只在 PLM 的输出中增加了 Dense 层。这样得到的 HydraNet 泛化性更好。
总的来说,本文提出的 HydraNet 更好的利用了 BERT-style 的 PLM,保持了架构的简单,并在 WikiSQL 排行榜上表现出很好的效果。但是,HydraNet 所支持的语法仍较为简单,仍然需要扩展。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









