







论文:GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
⭐⭐⭐⭐
arXiv:1804.07461, ICLR 2019
文章目录
-
- 一、论文速读
- 二、GLUE 任务列表
-
- 2.1 CoLA(Corpus of Linguistic Acceptability)
- 2.2 SST-2(The Stanford Sentiment Treebank)
- 2.3 MRPC(The Microsoft Research Paraphrase Corpus)
- 2.4 STSB(The Semantic Textual Similarity Benchmark)
- 2.5 QQP(The Quora Question Pairs)
- 2.6 MNLI(The Multi-Genre Natural Language Inference Corpus)
- 2.7 QNLI(Qusetion-answering NLI)
- 2.8 RTE(The Recognizing Textual Entailment datasets)
- 2.9 WNLI(Winograd NLI)
一、论文速读
GLUE benchmark 包含 9 个 NLU 任务来评估 NLP 模型的语义理解能力。这些任务均为 sentence or sentence-pair NLU tasks,语言均为英语。
二、GLUE 任务列表
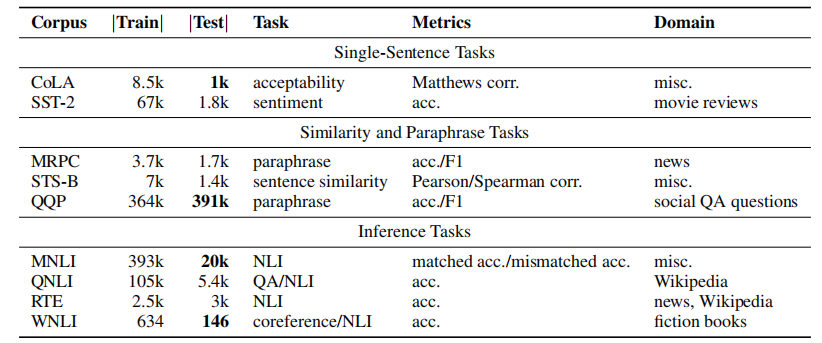
下图是各个任务的一个统计:
2.1 CoLA(Corpus of Linguistic Acceptability)
单句子分类任务。每个 sentence 被标注为是否合乎语法的单词序列,是一个二分类任务。
样本个数:训练集 8551 个,开发集 1043 个,测试集 1063 个。
label = 1(合乎语法) 的 examples:
- She is proud.
- she is the mother.
- Will John not go to school?
label = 0(不合乎语法) 的 examples:
- Mary wonders for Bill to come.
- Yes, she used.
- Mary sent.
注意到,这里面的句子看起来不是很长,有些错误是性别不符,有些是缺词、少词,有些是加s不加s的情况,各种语法错误。但我也注意到,有一些看起来错误并没有那么严重,甚至在某些情况还是可以说的通的。
2.2 SST-2(The Stanford Sentiment Treebank)
单句子分类任务:给定一个 sentence(电影评论中的句子),预测其情感是 positive 还是 negative,是一个二分类任务。
样本个数:训练集 67350 个,开发集 873 个,测试集 1821 个。
label = 1(positive)的 examples:
- two central performances
- against shimmering cinematography that lends the setting the ethereal beauty of an asian landscape
- a better movie
label = 0(negative)的 exampl
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









