






视频链接: 11、PyTorch中如何进行向量微分、矩阵微分与计算雅克比行列式_哔哩哔哩_bilibili
备注:大佬的第10讲和第11讲是连续的,这里只记录了第11讲,最好先回顾一下第10讲内容。
一、计算雅各比行列式
Autograd官网:Automatic Differentiation with torch.autograd — PyTorch Tutorials 1.13.1+cu117 documentation
jacobian API:torch.autograd.functional.jacobian — PyTorch 1.13 documentation
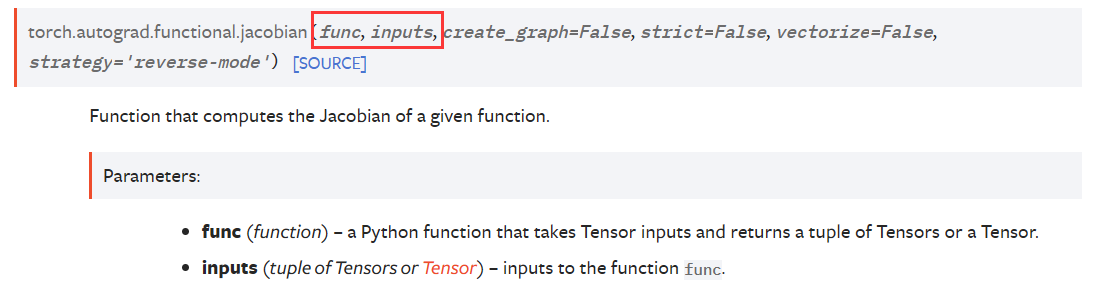
可以看到需要传入函数和函数的输入。
下面进行举例:
import torch
from torch.autograd.functional import jacobian # 导入库
# 首先是来计算雅各比
def func(x):
return x.exp().sum(dim=1)
# 计算y对x的雅各比矩阵
x = torch.randn(2, 3)
y = func(x)
print(x)
print(y)
print(jacobian(func, x)) # 传入函数名和输入
输出结果是:
tensor([[-2.2807, 1.7365, -0.0871],
[-1.3712, 0.4010, 0.6893]])
tensor([6.6962, 3.7394])
tensor([[[0.1022, 5.6773, 0.9166],
[0.0000, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000],
[0.2538, 1.4933, 1.9924]]])
输出结果的雅各比行列式中,第1行分别为 ∂ y 1 / ∂ x 11 \partial y_{1}/\partial x_{11} ∂y1/∂x11, ∂ y 1 / ∂ x 12 \partial y_{1}/\partial x_{12} ∂y1/∂x12, ∂ y 1 / ∂ x 13 \partial y_{1}/\partial x_{13} ∂y1/∂x13。第2行为 ∂ y 1 / ∂ x 21 \partial y_{1}/\partial x_{21} ∂y1/∂x21, ∂ y 1 / ∂ x 22 \partial y_{1}/\partial x_{22} ∂y1/∂x22, ∂ y 1 / ∂ x 23 \partial y_{1}/\partial x_{23} ∂y1/∂x23。依次类推,剩下的是 y 2 y_2 y2 对 x x x 的偏导。
二、向量微分
import torch
from torch.autograd.functional import jacobian
a = torch.randn(3)
def func(x):
return x+a
x = torch.randn(3, requires_grad=True) # x需要求梯度
y = func(x)
print(y)
y.backward(torch.ones_like(y))
print(x.grad) # 偏l/偏x = 偏l/偏y * 偏y/偏x
输出结果:
tensor([ 0.2931, -0.9664, -0.1255], grad_fn=<AddBackward0>) # y
tensor([1., 1., 1.]) # x.grad
解释一下backward()中为什么要传入torch.ones_like(y)?
backward默认前面的是一个标量,从输出结果上来看
y
y
y 并不是标量。因此,我们假定存在一个标量
l
l
l,并假定
l
l
l 对
y
y
y 的偏导数是全1的张量,即torch.ones_like(y)。则y.backward(torch.ones_like(y))是指
l
l
l 对
x
x
x 的偏导数。根据链式法则,即
∂
l
/
∂
x
=
∂
l
/
∂
y
∗
∂
y
/
∂
x
\partial l/\partial x=\partial l/\partial y * \partial y/\partial x
∂l/∂x=∂l/∂y∗∂y/∂x。
使用雅各比进行验证
print(torch.ones_like(y) @ jacobian(func, x))
# 前面是 偏l/偏y,默认是全1的张量,即v
输出结果如下:
tensor([1., 1., 1.])
与上面使用backward()求得的x.grad结果相同。
三、矩阵微分
a与b分别为两个矩阵,y是a与b矩阵相乘的结果。目标是分别求y对a、y对b的微分。
import torch
from torch.autograd.functional import jacobian
a = torch.randn(2, 3, requires_grad=True)
b = torch.randn(3, 2, requires_grad=True)
y = a @ b
print(y)
y的值即输出结果为:
tensor([[-4.0912, -0.7351],
[-1.7535, -1.7067]], grad_fn=<MmBackward0>)
使用backward进行计算:
y.backward(torch.ones_like(y)) # y不是标量,需要传入全1且与y形状相同的张量
print(a.grad)
print(b.grad)
得到a的梯度和b的梯度分别为:
tensor([[-0.0688, -3.7974, -1.3985], # 两行相同
[-0.0688, -3.7974, -1.3985]])
tensor([[ 2.1476, 2.1476], # 两列相同
[ 2.2903, 2.2903],
[-0.3992, -0.3992]])
使用雅各比进行验证
如果y对a进行偏微分,那么b相当于是一个常数矩阵。固定b的值,建立关于a的函数func(a)。因为a@b 是a的每一行与b的每一列进行相乘,所以这里先取a的第一行元素a[0]。
def func(a):
return a @ b
print(func(a[0]))
print(torch.ones_like(func(a[0])) @ jacobian(func, a[0]))
# 前面是 偏l/偏y,默认是全1的张量,即v
输出结果如下:
tensor([-4.0912, -0.7351], grad_fn=<SqueezeBackward3>)
tensor([-0.0688, -3.7974, -1.3985])
输出结果的第2行,与上面矩阵y对a的微分的第1行结果相同。
同理,我们使用a[1]进行验证:
print(torch.ones_like(func(a[1])) @ jacobian(func, a[1]))
输出结果:
tensor([-0.0688, -3.7974, -1.3985])
如果y对b进行偏微分,那么a相当于是一个常数矩阵。固定a的值,建立关于b的函数func(b)。因为a@b 是a的每一行与b的每一列进行相乘,所以这里取b的第一列元素b[:, 0]和第二列元素b[:, 1]。
def func(b):
return a @ b
print(func(b[:, 0]))
print(torch.ones_like(func(b[:, 0])) @ jacobian(func, b[:, 0]))
print(func(b[:, 1]))
print(torch.ones_like(func(b[:, 1])) @ jacobian(func, b[:, 1]))
结果如下:
tensor([-4.0912, -1.7535], grad_fn=<MvBackward0>)
tensor([ 2.1476, 2.2903, -0.3992])
tensor([-0.7351, -1.7067], grad_fn=<MvBackward0>)
tensor([ 2.1476, 2.2903, -0.3992])
可以看到第2、4行的输出结果,分别与上面矩阵y对b的微分的第1、2列结果相同。














 3171
3171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









