






文章目录
论文链接: DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation (arxiv.org)
DreamBooth是一种微调文生图扩散模型的方法,最大的特点是Subject-Driven,针对某一个特定的主体,生成这个主体可以是一个动物或者某个物体,包括人都是可以的。

有特定小狗的一些照片,一般 3-5 张就能生成模型没有见过它做的事情的图片,比如说去到了这个希腊,去游泳,这都是模型没有见到过的照片,但是模型却能生成出来。并且这些生成的图片都有很高的保真度,能够保持这个物体的主要特征。
Abstract
如今 AI 生成已经有很大的发展,但是这些模型都缺少能够通过一个给定的很小量的 reference set ,去模仿生成该 set 中所指定 subject 的图片。这种针对特定物体的生成,在此前绝大部分的生成模型都是做不到的。在这篇文章中,作者提出了一个新的方法 DreamBooth,用来个性化文生图 diffusion models。
个性化指只要给模型某一个具体主体的很少几张图片之后,让一个预训练好的文生图模型将这个特定的 subject 绑定到一个 unique identifier 上去,那模型只要见到这个 unique identifier,就知道我们想要生成的是这个特定的主体。
一旦模型学会了这个 unique identifier,这个 identifier 就可以用来生成某个特定物体的照片,并且是重情景化的,也就是出现在各种各样,以前没有出现过的情景之中。通过提出了一种new autogenous prior preservation loss,从而保证生成这个主体的多样性,不仅仅是把物体局限在输入图片所聚合一些 pose、view 上面去,而且能生成一些这个模型没有见过这个主体出现的 pose、view。
这种技术可以应用非常困难的任务上,包括 subject recontextualization 主体重情景化,text-guided view synthesis 通过文本指导的全新视角的生成,以及 artist rendering 艺术渲染,让主体的照片具有某种艺术风格。做这些任务都能保证这个主体的主要特点是不变的。
最后作者说他们提供了一种数据集,然后在这种数据集上我们就能够评估这种主体去驱动的生成的效果。
1.Introduction
现在的一些模型能够生成很高质量的各种各样的图片。这些模型的优势就是他们有非常强大的语义先验,语义先验是通过非常多的图片文本对 image-caption pairs 来训练获得的,模型通过训练都能建立起文本和图像之间的对应关系。当模型见到比如说一个单词“dog”,那模型就知道就是要生成狗的样子。但是这些模型都缺少这种能力,给定一个特定主体 subject reference set 去生成这个具体对象在不同的情境中的一些照片。
主要的原因是这些模型的表达能力是有限的,模型的 output domain 里面并没有该特定物体在不同情况下的输出,所模型的表达能力限制生成特定物体在不同情景下的图片。即使你用最详细的文本对于某个物体进行描述,这个模型依然可能会生成出不一样外表的物体,没有办法固定。
既然现有模型就有这些缺点,那我们就是要去克服这种缺点。作者就通过绑定一个新的词汇和这个特定的主体,这样模型就建立了这个新的 word 和这个特定主体之间的关系。当模型见到这个文本中还有特定 word 的时候,模型就能够生成指定的主题,并且结合模型本身强大的先验能力,能够让指定的主体去重情景化,出现在完全不同的一些情景之中,同时保持这个特定主体的主要的特征。
用一个 unique identifier 去绑定特定的主题。unique identifier 实际上是一个非常稀有的 token。例如,“A [V] dog” 中的 V 就是特定物体的 identifier,dog 是特定物体所属的类别。V 就相当于在 dog 这个 class 下面新建了一个对象。把这样的文本和图片输入到模型中去,模型可能会出现 language drift 的现象,指的就是因为你输入的这只狗的图片,通过不断去 fine-tuning 整个模型,那么模型可能会渐渐地把 dog 这个概念收敛到这个特定的狗上面去,也就是说模型遗忘了 dog 本身指的是各种各样不同的狗,而最终只是过拟合到这只特定的狗上去。也就是说模型对 dog 这个词含义发生了drift 漂移。
为了缓解这个现象,作者提出了 class-specific prior preservation loss,从而让模型依然知道 dog 这个单词代表的是各种各样的狗,而不是这只特定的狗,这样能使生成具有多样性。相当于模型是知道狗长什么样子,它能够把它见过的狗站着、趴着或者跑起来是什么样子与这只特定的狗之间建立了一个桥梁,让模型也能间接能明白这只特定的狗它跑起来是什么样子。这个 loss 实际上就是保证了模型生成的多样性,而不仅局限于喂给模型的这几张图片的样子,实际上就是指的模型的可编辑性很高。
作者将 DreamBooth 用到各种各样的任务中去,然后通过两种方式去分析模型效果的好坏。其中一种是 ablation studies,通过一些具体的评估指标去评估他们的模型,去评估他们的方法和其他的一些模型之间生成图片的差别。另一种是 user study,相当于请了一群评委发问卷。
DreamBooth是第一次用来去应对这种主体驱动 subject-driven 的挑战,仅仅使用了非常少的随意拍摄的某个主体的图片,就能生成这个主体在各种各样不同的情形中的图片,并且能保证它独特的特点。
最后作者又强调了他们构建了一个数据集,这个数据集包含各种各样的主体在不同的情景之中,并且建立了一个新的评估标准,去评估针对主体做生成的模型的生成效果好坏。通过主体保真性和文本保真性这两种指标去评估模型的好坏。
2.Related work
Image Composition: 图片合成是将给定的主体克隆到新的场景中。如果想要合成一种新的主体姿势,那么可能需要去使用 3D 重建技术,通过多个视角的图片去重建起这个物体的三维模型,然后再投射到各个平面上去。但是这种三维重建技术会使得光照、阴影和物体之间的连接可能会产生一些问题,且不能产生全新的场景,也就是没有办法实现作者想要的这种特定主体在全新的情景中之中的生成。
Text-to-Image Editing and Synthesis: 首先讲到了这种GAN,因为 clip 的出现让图像和文本在 representation 层面上能够做到更好的结合。这种多模态的结合使得图像生成产生了很大的进步,可以用文本去指导图像和生成。但是这些工作在 structural scenarios 上面工作的很好。什么叫结构化的场景?比如人脸的编辑。因为每个人的人脸结构都是固定的,它都是由脸型、嘴或者头发这些特征所组成的,那么会比较容易地通过去控制某个特定结构的特征,来实现改变某个特定结构的效果。比如把红色头发换成蓝色头发,因为人脸是一个结构比较固定的数据,所以这种相对容易一点。但是当你把数据拓展到包含各种各样不同主体的数据集上的时候,可能就会比较困难,因为这个时候你数据集的结构是不确定的,这个时候控制起来就会比较难。
当然也有一些工作,比如说 VQ-GAN 缓解了这种现状,包括最近的 diffusion models 也能够在这种生成上超过GAN系列的效果。但是很多工作只能去做这种全局的编辑,都没有办法实现对一个特定主体的在不同情境下的生成。
Controllable Generative Models: 比如 user-provided mask,就是用户去人为地设定一个 mask,让它只生成 mask 里面的东西,就是控制生成区域的一些工作。但是这些工作依然不能实现作者想要的这种特定主题的生成。GAN 系列的一些改进是可以实现生成特定的人脸,但是需要 100 张照片去训练,就是比较多,另外这种技术目前也只能受限于人脸的领域。
Textual Inversion 让模型去学习一个全新的概念,就是某一个物体或者某一种风格,它通过让模型在文本端建立一个新的 token,让模型针对这个新的 token 来生成指定的物体风格。这种方法并不改变扩散模型本身的权重,所以表达能力依然受限。因为把 diffusion model 的参数都给冻住了,而仅仅在文本编码端去学习一个新的输入。这种方式的输出域是没有改变的,因为模型参数没有变化,能够投射的 y 的范围并没有改变,这就导致通过 Textual Inversion 这种方法生成的特定主体也很难去保证它所有关键的视觉特征。
3.Method
3.1 Text-to-Image Diffusion Models
这一节实际上在讲 diffusion model 的背景知识,diffusion model 在训练过程中,会把一个原始图片经过很多步的加噪声,让它近似地为一个各项同性的高斯噪声。在生成阶段,给模型一个噪声,而模型就能一步一步通过这些噪声预测出之前一步的图片是什么样子,然后经过很多步之后还原出原图的样子,这是一个去噪的过程,公式表示为:
E
x
,
c
,
ϵ
,
t
[
w
t
∥
x
^
θ
(
α
t
x
+
σ
t
ϵ
,
c
)
−
x
∥
2
2
]
\mathbb{E}_{\mathbf{x},\mathbf{c}, \epsilon ,t } [w_t\left \|\hat{ \mathbf{x} }_\theta (\alpha _t \mathbf{x}+\sigma _t \epsilon , \mathbf{c}) - \mathbf{x} \right \|^2_2 ]
Ex,c,ϵ,t[wt∥x^θ(αtx+σtϵ,c)−x∥22]
x
\mathbf{x}
x 就是原图。
3.2 Personalization of Text-to-Image Models
我们的任务就是要把特定的主体能够植入到我们的输出域中,让模型能输出特定个体的一些图片,一个自然的想法就是用少量的数据去 fine-tuning 整个模型,但是这种方式很有可能会造成 overfitting 和模式坍塌 model-collapse,这会在 GAN 里面发生。比如模型可能会走捷径,并没有学会这个特定物体的分布是什么样子,也不可能让生成的物体具有多样性。
作者的方法能让模型不要忘了模型的一些先验知识,然后去 overfit 到这个很小的数据集上去。因为一旦模型 overfit 到很小的 training images 上面去,就没有办法生成很多样的图片了,就只能生成很像你训练集的那几张图片的图片。
Designing Prompts for Few-Shot Personalization: 文生图模型建立了每个文本和图像之间的对应关系,这实际上就像一个字典。如果想要模型认识到这个特定物体,当然也要把这个物体加入到字典中去,那怎么样让这个物体和字典的一些词汇产生关联?就是用 “a [identifier] [class noun]”,identifier 和原本词典里面有的 class 类的词产生关联,这样自定义的 identify 就能和 class 有关的词产生关联,这种网络状的铺开就能让特定 identify 产生与各种各样的词之间的关联,具有多样性。
类别描述词 class descriptor 既可以是用户人工给定的,也可以是通过一个分类器 classifer 去自动标定。将 class descriptor 放在这个句子里面,目的是让 class noun,这个模型的先验去和这个独特的 subject 产生联系。
如果你用一个错误的类描述,或者不用类描述,都会降低你这个模型性能,或者增加训练的时间。这本质上就是让模型的类别 prior,能绑定到这个特定的物体上,让特定物体直接获取了这个模型很强大的先验,直接就知道这个物体到底是哪个类,那么自然继承了这个类的很多特征。然后通过模型已知的类也能联系到这个物体的其他行为。给定特定的狗的图片中并没有跑步的照片,但是通过 dog 这个大类能够联系到这个文生图模型中狗跑步的样子,自然也建立起了特定的狗和跑步之间的关联,这样就能生成特定狗去跑步的照片了,实现了模型生成的多样化。
Rare-token Identifiers: identifier 应该怎么去选?首先必须要很稀有。如果选用一个常见的词汇,比如 :“unique”,“special” 这种词的话,其实模型对这些词是有一个很强大的语义先验,这样模型就会混淆,模型对 unique 这个词的认识逐渐从一个非常强大的先验 慢慢地偏移到 他认为 unique 就是这只狗。所以需要选一个 weak prior,就是模型很少见,这样学习起来肯定会更快一点,从而使模型能很容易把这个词的特点和指定的物体直接关联上。另外一种不太好的方式,就是 random characters 随机字符,例如(“xxy5syt00”),因为文本模型在处理文本输入时会进行一些词根词缀的切割,像这种随机的字符组合,文本编码器有可能会每个单词单独去处理,因为每个单词其实文本是具有一定的先验的,这也是不太好的。
作者选用 unique identifier 的方法,就是去查 token 词典,去查哪些 token 被用得很少。对于文本模型来讲,输入的 text 和 token 其实是一一对应的,如果找到用得很少的token,然后再反向的得到它的text,就可以为 identifier。这个 identifier 在文本模型里面是比较短且不常见的字符。
3.3 Class-specific Prior Preservation Loss
该 loss 是保证模型生成多样性的一个关键。DreamBooth 实际上是 fine-tuning 所有层的所有参数的方法,甚至包括这个文本编码器。如果不做任何处理,就会导致:
-
laguage drift
当使用一个很小的图像文本对去 fine-tuning 生成模型时,对于你文本中提及的词汇,模型会慢慢地偏移到文本中指定的物体上去,可能会忘了它本身的含义。如果输入了一条特定的狗,模型会慢慢认为狗就只有你这一条狗,而忘了它其实还可以代表很多种类的狗,就是模型学了新的,忘了旧的。
-
reduced output diversity。
如果 fine-tuning 一个模型不做任何处理,它很有可能会使这个输出域局限在你这个特定的物体,特定的这几张图片的这个分布上去,从而没有办法生成具有多样性的图片,无法生成全新的视角,全新的姿势或者结构的一些图片。这种现象通常为训练时间过长,模型发生过拟合。
为了克服上面提到两个问题,提出了autogenous class-specific prior preservation loss,就是让模型继续保持这个特定类别的 prior,以此能达到模型生成多样性、克服语言漂移的现象。
本质上,让模型生成一些样本去监督整个训练过程,以此让模型保持住这个prior,让模型依然知道狗跑着跳着睡各自是什么样子,这样也能够把各种各样不一样的姿势或者环境连接到这个特定的主体上去,让模型知道这个特定主体跑或者跳都是什么样子。
那刚刚提到的模型需要自己生成一些样本,那怎么生成呢?就是通过这个文本“a [class noun]”,该文本的区别在于把之前的特定的名词 identifier 去掉了,只有类别,让模型生成各种各样这个类别的个体。在训练的过程中,虽然模型的参数变化了,但是输入这个词汇依然要能生成模型,开始微调之前通过这个词汇生成的那些图片。如果模型训练越久,通过这种只有 class 生成的图片和原本 fine-tuning 之前生成的图片相差太远,那就说明模型对 class 这个词的理解已经发生了语言漂移的现象。
E
x
,
c
,
ϵ
,
ϵ
′
,
t
[
w
t
∥
x
^
θ
(
α
t
x
+
σ
t
ϵ
,
c
)
−
x
∥
2
2
+
λ
w
t
′
∥
x
^
θ
(
α
t
′
x
p
r
+
σ
t
′
ϵ
′
,
c
p
r
)
−
x
p
r
∥
2
2
]
\mathbb{E}_{\mathbf{x},\mathbf{c}, \epsilon , {\epsilon }', t } [w_t\left \|\hat{ \mathbf{x} }_\theta (\alpha _t \mathbf{x}+\sigma _t \epsilon , \mathbf{c}) - \mathbf{x} \right \|^2_2 + \lambda w_{{t}'}\left \| \hat{ \mathbf{x} }_\theta (\alpha _{t'} \mathbf{x}_{\mathrm{pr} }+\sigma _{t'} {\epsilon}' , \mathbf{c}_{\mathrm{pr} }) - \mathbf{x}_{\mathrm{pr} } \right \| ^2_2]
Ex,c,ϵ,ϵ′,t[wt∥x^θ(αtx+σtϵ,c)−x∥22+λwt′∥x^θ(αt′xpr+σt′ϵ′,cpr)−xpr∥22]
第一项是之前提到的一般的扩散模型的误差表示,第二项是 prior preservation loss,具体我们就直接看这个图。
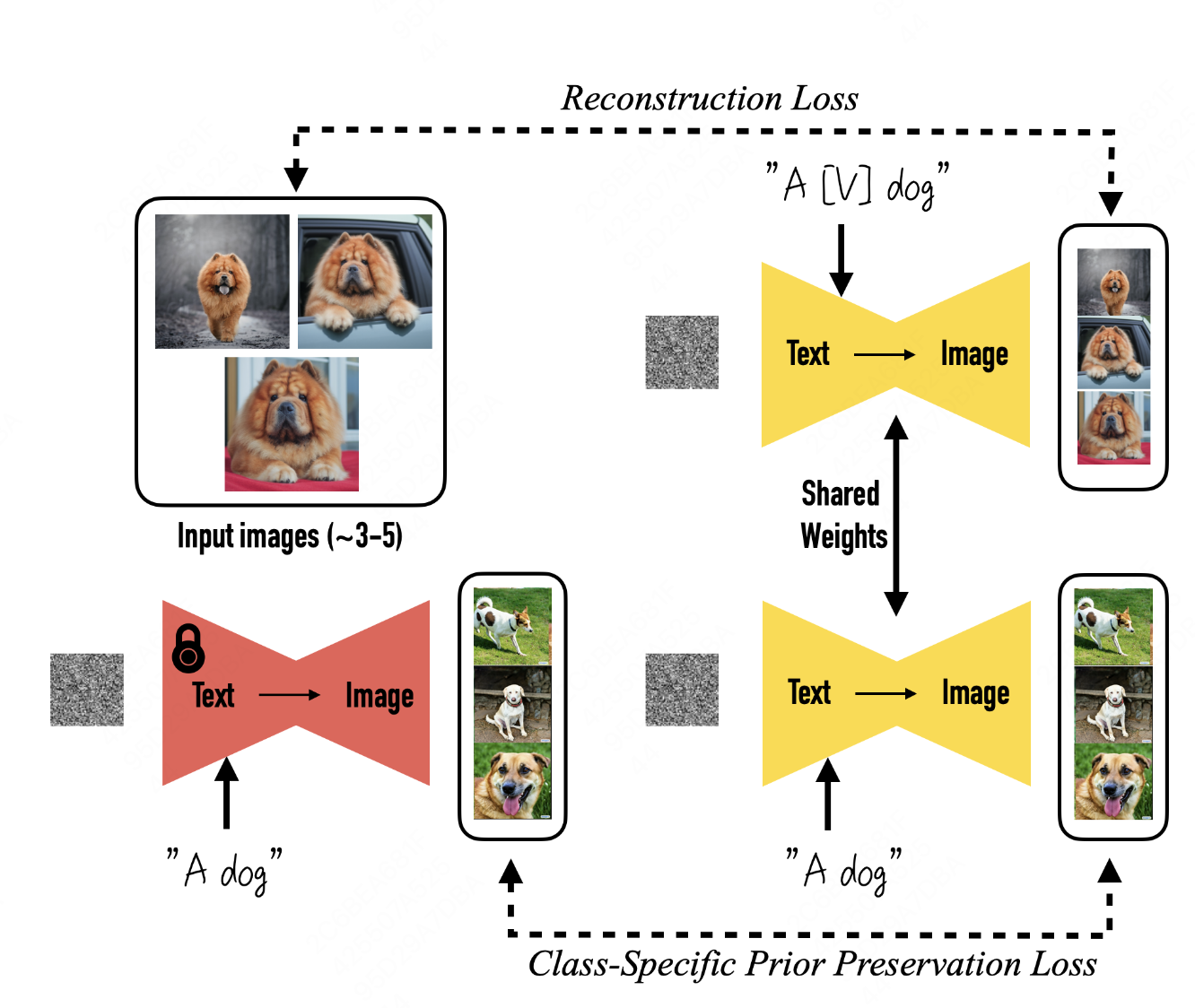
训练过程中输入了左上角这些特定狗的图,在普通的训练过程中,就会有一个 reconstruction loss,让输入作为监督信号,让模型的生成去接近输入图片,这个时候输入的词是 “a [V] dog”,带有特定类别的 identifier 的 class。
下面这部分是文章提出的 prior reservation loss。在开始训练之前,只用这个类别的词去生成一些系列图片,比如a dog,模型生成了很多狗的图片,它是各种各样不同的狗,在各种各样不同的环境中。当训练开始之后,虽然参数更新了,但是输入 a dog,模型需要依然能够生成这些和原本的狗,就是训练开始之前的狗一样的图片,而不是去生成特定的狗,表示模型在训练过程中对 dog 这个单词的认识并没有发生改变,也就是说模型没有发生语言漂移。
4.Experiments
4.1 Dataset and Evaluation
Dataset: 数据集包含 30 个物体,其中既有静止不动的物体,也有活着的动物,每个物体有 25 种不同的prompts,从而组合起来就形成了 750 种不同的图片文本对。为了评估模型的好坏,需要对每个图像文本对生成 4 个图片,这样总共就生成了 3000 个不同的图片。
Evaluation Metrics:
-
subject fidelity 主体保真度:
评估特定物体的生成是否相似。用 CLIP-I 和 DINO 这两个模型分别提取原始真实图片和生成图片之间的特征,然后对比这些特征之间的余弦相似度,如果相似度越高,就说明生成图片与原图的更相似,也就反映了生成物体的保真性更高。 为什么使用 DINO 和 clip 去提取这种图像特征去对比保真度?因为 DINO 和 CLIP 都是基于对比学习的方法,对比学习的损失是同一个样本之间才会是被认为正样本,会尽量让它们相似,那对于那种不同样本,即使是你同一个类下的不同样本,它也会被认为是负向样本,会尽量让特征远离,让它们的特征更不相似。因此这两个算法实际上是能够区分每一个单独个体的,因为它会让不同个体的 embedding 表达都尽量远离。
-
prompt fidelity 的保真度:
评估生成图片和输入的文本之间特征的相似度,使用 CLIP-T 分别去提取文本和图像特征,比较生成的图像和输入的文本之间的相似度,如果比较近的话,就说明图像更加遵循输入文本的控制,和输入的文本相似度更高。
总而言之,生成的图片里面的个体要尽可能和原图中的个体相似,又要与输入文本相似,这就是保真性。
4.2 Comparisons
作者对比了用 DreamBooth 和 Texture Inversion 这两种方法,在 stable diffusion 和 Imagen 上的生成效果,通过计算余弦相似度矩阵,值越大,保真度越好。
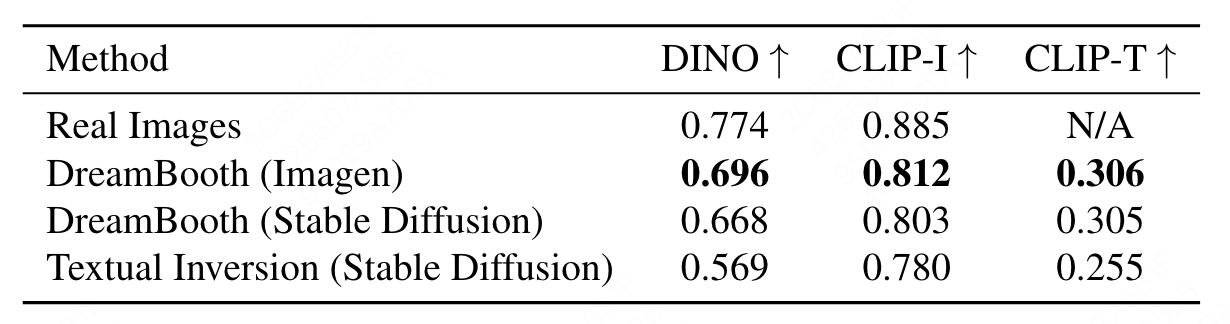
最下面这一行是 Test Inversion,均不如 DreamBooth 在两个模型上的指标,其中 DreamBooth 在 Imagen 上的保真度要高于它在 stable diffusion 上的保真度。因为相比 stable diffusion,Imagen 拥有更强大的表达能力和更高的生产图片的质量。
此外,作者还做了一个 user study,就是给用户发一些问卷调查,对比 Texture Inversion 生成图片和用 DreamBooth 生成的图片之间,谁的保证度更高,它也分为图像保真度和文本保真度。

DreamBooth 不管是主体保真性还是文本保真性,都远远高于 Textual Inversion 所得到的结果的。通过对比这两个表,发现余弦相似度的差距只有 0.1,但是反映到用户的感受上来讲,它差距是巨大的。
4.3 Ablation Studies
Prior Preservation Loss(PPL) Ablation
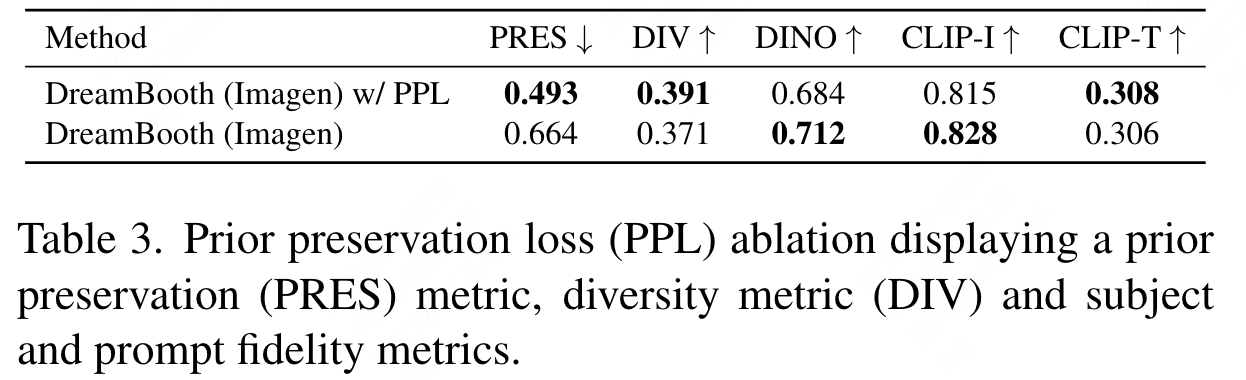
- prior preservation metric (PRES) 用于评估模型语言漂移。对于训练完后的模型,输入某一个类来生成图片,希望不指定特定物体和指定特定物体之间生成的图片,越不相似越好。说明模型越保持住 class prior,依然具有生成不是这个特定狗的一些其他狗的能力。PRES 的指标越不相似越好,即数值越低越好。
- DIV (Diversity Matrix) 用于描述模型生成多样性。同一个 prompt 下生成的一组图片之间的平均余弦相似度距离。对于同一个prompt,如果希望生成更多的种类的样本,需要余弦相似度越低越好,说明更多样。但是注意的是,div 实际上是一个距离的概念,值越大,代表距离越远,代表模型的多样性会越好。
可以看到,在防止语言漂移和保持文本多样性上,带上 PPL 都是要比不带要更好。对于三四列,带上之后模型的保真度不如不带的,毕竟不带这个PPL,模型肯定会更加拟合到你的目标训练集上去,所以保真度会更好。但这其实有可能是一种过拟合,并不是我们需要的。也就是说加上 PPL 之后,实际上是在多样性和保真度之间做了一个权衡。

图 6 直观地展示了加不加这个 loss 的效果。可以看到中间这行不加生成图都是这种很相似的姿势,所有的狗都是趴着的,但如果加上这个 loss 之后,这个狗就可以站着、蹲着,就有不同的姿势了,而且背后的环境差异也会更大一些。
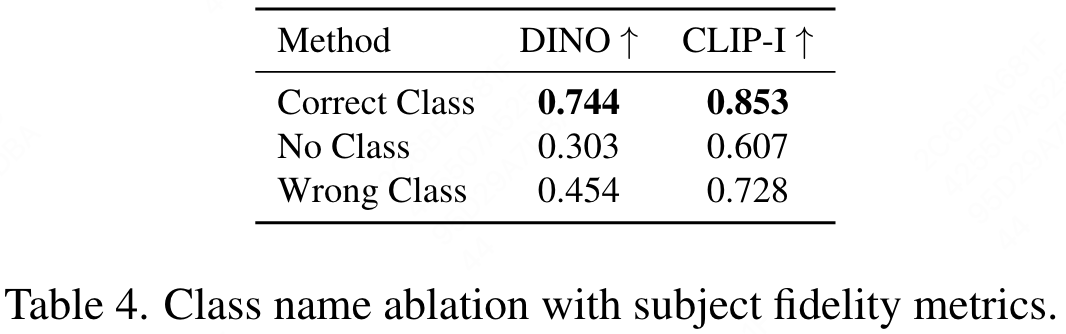
Class-Prior Ablation
针对 class noun做的实验,作者用了三种不同的方式,一种是加入一个错误的类标志,一种是加入正确的类标志,还有一种是不加类标志。如果加了一些错误的类标志,比如说把 can 罐头加到一个书包的文本里面去,那么就有可能生成一个圆柱状的书包,也就是说可能会生成一种原本不属于这个物体的形状,这也是我们不想要的。如果训练不加这个 class 的话,那么这个整个训练就比较难以收敛,而且也会生成一些错误的样本。如果你设置正确的class,输入到训练中序模型的保真度都是更高的,而且差距非常明显。
4.4 Applications
具体看论文中的图7.8。
4.5 Limitations

除了上图提出的3种限制之外,DreamBooth 在一些简单的个体上会学习得很容易,比如说猫猫狗狗,但是如果这个主体本来就很稀有,模型学习起来就会非常的难。即使模型的保真度很高,但有时候也会生成一些不存在于这个主体的特征。
5.Conclusions
DreamBooth 只需要很少的特定主体的图片就能做这种特定主体的生成,而且能够把它生成在不同的情境中。整个模型的多样性和保真性都很好,甚至在很多情况下和真实的图片都比较难以区分。


















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









