







我先随便写一下,时间紧任务重,后面再慢慢完善……毕竟是第一次用_
Read_data
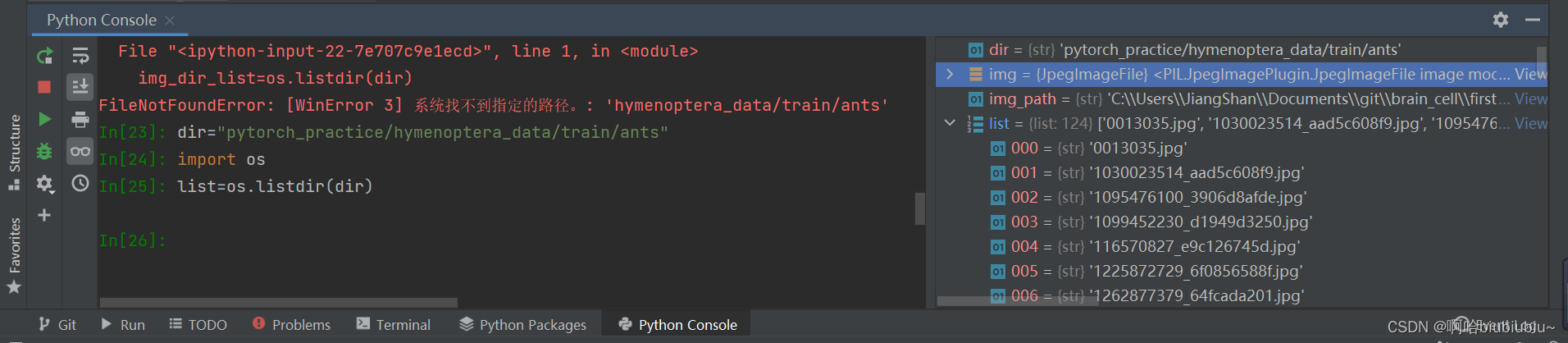
利用console直接读图片

在console中可以看到img的相关信息


集成Dataset类,写自己的dataset
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
self.path=os.path.join(self.root_dir,self.label_dir)
self.img_path=os.listdir(self.path)
def __getitem__(self, index):
img_name=self.img_path[index]
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)
img=Image.open(img_item_path)
label=self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
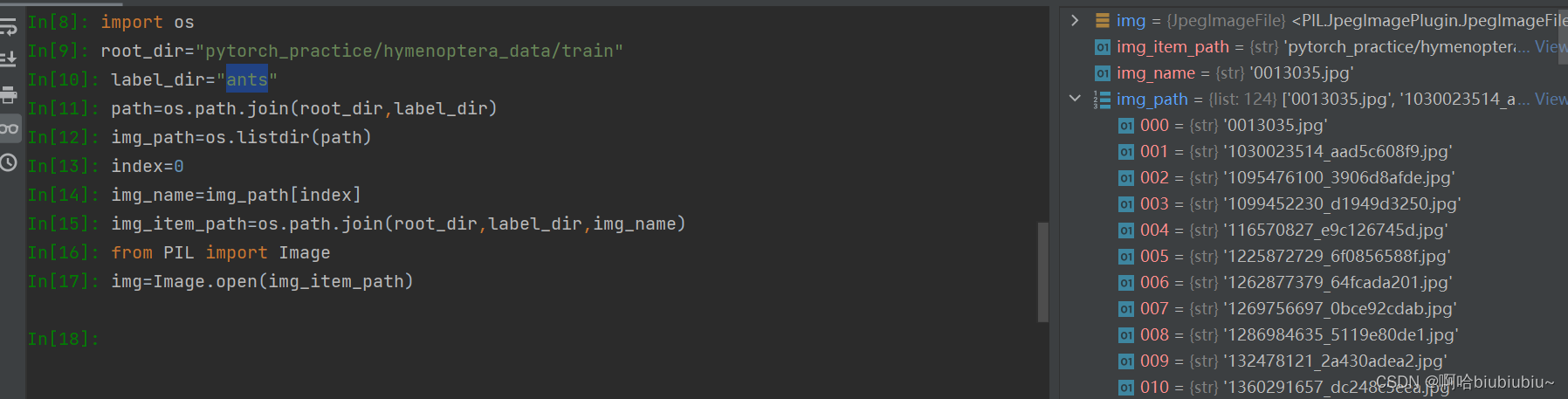
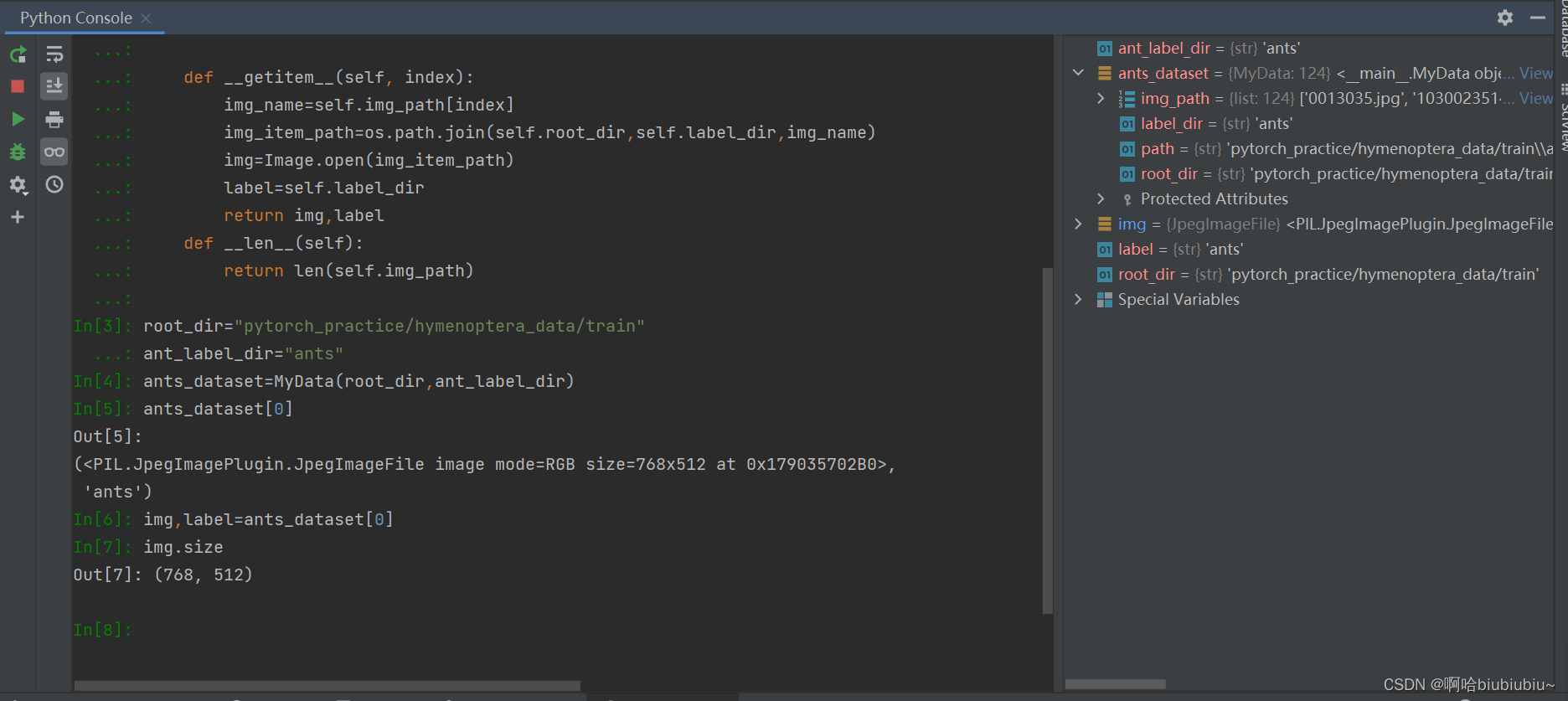
root_dir="C:/Users/JiangShan/Documents/git/brain_cell/first_source/pytorch_practice/hymenoptera_data/train"
ant_label_dir="ants"
ants_dataset=MyData(root_dir,ant_label_dir)
ima,label=ants_dataset[0]
print(label)
可以在console中看到各个变量或者类的属性及方法
Transform
看官方文档,主要关注输入输出,需要什么参数
或者在python文件中导入
from torchvision import transforms
在pycharm中按住ctrl点transform,再点transform会出现这个文件transforms.py
transforms.py中有很多类,里面都有很好的解释,选择transforms中需要的类来作为工具,然后使用对应的功能
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path="../hymenoptera_data/train/ants/0013035.jpg"
img=Image.open(img_path)
print(img)
# <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=768x512 at 0x26968217130>
tensor_trans=transforms.ToTensor()
tensor_img=tensor_trans(img)
# print(tensor_img)
# tensor([[[0.3137, 0.3137, 0.3137, ..., 0.3176, 0.3098, 0.2980],
# [0.3176, 0.3176, 0.3176, ..., 0.3176, 0.3098, 0.2980],
# [0.3216, 0.3216, 0.3216, ..., 0.3137, 0.3098, 0.3020],
# ...,
# [0.3412, 0.3412, 0.3373, ..., 0.1725, 0.3725, 0.3529],
# [0.3412, 0.3412, 0.3373, ..., 0.3294, 0.3529, 0.3294],
# [0.3412, 0.3412, 0.3373, ..., 0.3098, 0.3059, 0.3294]],
#
# [[0.5922, 0.5922, 0.5922, ..., 0.5961, 0.5882, 0.5765],
# [0.5961, 0.5961, 0.5961, ..., 0.5961, 0.5882, 0.5765],
# [0.6000, 0.6000, 0.6000, ..., 0.5922, 0.5882, 0.5804],
# ...,
# [0.6275, 0.6275, 0.6235, ..., 0.3608, 0.6196, 0.6157],
# [0.6275, 0.6275, 0.6235, ..., 0.5765, 0.6275, 0.5961],
# [0.6275, 0.6275, 0.6235, ..., 0.6275, 0.6235, 0.6314]],
#
# [[0.9137, 0.9137, 0.9137, ..., 0.9176, 0.9098, 0.8980],
# [0.9176, 0.9176, 0.9176, ..., 0.9176, 0.9098, 0.8980],
# [0.9216, 0.9216, 0.9216, ..., 0.9137, 0.9098, 0.9020],
# ...,
# [0.9294, 0.9294, 0.9255, ..., 0.5529, 0.9216, 0.8941],
# [0.9294, 0.9294, 0.9255, ..., 0.8863, 1.0000, 0.9137],
# [0.9294, 0.9294, 0.9255, ..., 0.9490, 0.9804, 0.9137]]])
transform中几个常用类的的使用
from PIL import Image
from torchvision import transforms
imag=Image.open("../hymenoptera_data/train/ants/0013035.jpg")
# print(type(imag))
# <class 'PIL.JpegImagePlugin.JpegImageFile'>
#ToTensor
trans_totensor=transforms.ToTensor()
imag_tensor=trans_totensor(imag)
# print(type(imag_tensor))
# <class 'torch.Tensor'>
print(imag_tensor[0][0][0])
#Normalize
trans_normal= transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
# (各维度均值,各维度标准差)
# 计算公式:output[channel] = (input[channel] - mean[channel]) / std[channel]
imag_normal=trans_normal(imag_tensor)
print(imag_normal[0][0][0])
#Resize
#img PIL->resize->img_resize PIL
print(imag.size)
# (768, 512)
trans_resize=transforms.Resize((512,512))
imag_resize=trans_resize(imag)
print(imag_resize.size)
# (512, 512)
#Compose-resize-2
trans_resize_2=transforms.Resize(512)
trans_compose=transforms.Compose([trans_resize_2])
imag_resize_2=trans_compose(imag)
print(imag_resize_2.size)
# (768, 512)
#RandomCrop
trans_rc=transforms.RandomCrop(512)
trans_compose_2=transforms.Compose([trans_rc])
for i in range(10):
i=trans_compose_2(imag)
print(i)
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E8E0>
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E970>
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E8E0>
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E970>
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E8E0>
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E970>
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E8E0>
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E970>
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E8E0>
# <PIL.Image.Image image mode=RGB size=512x512 at 0x1ED7CC7E970>
Dataset
import torchvision
train_set=torchvision.datasets.CIFAR10(root="../",train="true",download=True)
test_set=torchvision.datasets.CIFAR10(root="../",train="false",download=True)
print(train_set)
print(test_set)
# Dataset CIFAR10
# Number of datapoints: 50000
# Root location: ../
# Split: Test
# Dataset CIFAR10
# Number of datapoints: 50000
# Root location: ../
# Split: Test
print(test_set[0])
# (<PIL.Image.Image image mode=RGB size=32x32 at 0x2001E782370>, 6)
print(test_set.classes)
img,target=test_set[0]
print(img)
print(target)
print(test_set.classes[target])
# ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
# <PIL.Image.Image image mode=RGB size=32x32 at 0x175D53B8670>
# 6
# frog
dataset+transform
dataset_transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set=torchvision.datasets.CIFAR10(root="../",train="true",transform=dataset_transform,download=True)
test_set=torchvision.datasets.CIFAR10(root="../",train="false",transform=dataset_transform,download=True)
print(test_set[0])
# (tensor([[[0.2314, 0.1686, 0.1961, ..., 0.6196, 0.5961, 0.5804],
# [0.0627, 0.0000, 0.0706, ..., 0.4824, 0.4667, 0.4784],
# [0.0980, 0.0627, 0.1922, ..., 0.4627, 0.4706, 0.4275],
# ...,
# [0.8157, 0.7882, 0.7765, ..., 0.6275, 0.2196, 0.2078],
# [0.7059, 0.6784, 0.7294, ..., 0.7216, 0.3804, 0.3255],
# [0.6941, 0.6588, 0.7020, ..., 0.8471, 0.5922, 0.4824]],
#
# [[0.2431, 0.1804, 0.1882, ..., 0.5176, 0.4902, 0.4863],
# [0.0784, 0.0000, 0.0314, ..., 0.3451, 0.3255, 0.3412],
# [0.0941, 0.0275, 0.1059, ..., 0.3294, 0.3294, 0.2863],
# ...,
# [0.6667, 0.6000, 0.6314, ..., 0.5216, 0.1216, 0.1333],
# [0.5451, 0.4824, 0.5647, ..., 0.5804, 0.2431, 0.2078],
# [0.5647, 0.5059, 0.5569, ..., 0.7216, 0.4627, 0.3608]],
#
# [[0.2471, 0.1765, 0.1686, ..., 0.4235, 0.4000, 0.4039],
# [0.0784, 0.0000, 0.0000, ..., 0.2157, 0.1961, 0.2235],
# [0.0824, 0.0000, 0.0314, ..., 0.1961, 0.1961, 0.1647],
# ...,
# [0.3765, 0.1333, 0.1020, ..., 0.2745, 0.0275, 0.0784],
# [0.3765, 0.1647, 0.1176, ..., 0.3686, 0.1333, 0.1333],
# [0.4549, 0.3686, 0.3412, ..., 0.5490, 0.3294, 0.2824]]]), 6)
Dataloader
from torch.utils.data import DataLoader
import torchvision
test_set=torchvision.datasets.CIFAR10(root="../",train="false",transform=torchvision.transforms.ToTensor(),download=True)
test_loader=DataLoader(dataset=test_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#batch_size每次取多少张图片,shuffle是否打乱,drop_last最后的一组不足batch_size时是否丢弃
img,target=test_set[0]
print(target)
print(img.shape)
# 6
# torch.Size([3, 32, 32])
print(len(test_loader))
'''for data in test_loader:
imgs,targets=data
print(len(data))'''














 7772
7772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









