







引言
在深度学习的世界里,如何在保证模型效能的同时减少其复杂性,一直是研究人员追求的目标。随着移动设备的普及,MobileNetV1应运而生,提供了一种在移动和嵌入式设备上运行高效深度学习模型的可能。
MobileNet V1 由谷歌在 2017 年 4 月提出,核心原理是利用深度可分离卷积(Depthwise Separable Convolution)来构建轻量级的深度神经网络。这种设计显著减少了模型的参数数量和计算量,同时保持了较高的准确率。
深度可分离卷积
深度可分离卷积将传统的卷积操作分解为两个更简单的步骤:
深度卷积(Depthwise Convolution):对每个输入通道使用不同的滤波器进行卷积,实现空间特征的提取。
逐点卷积(Pointwise Convolution):将深度卷积的输出结果通过1x1的卷积核进行组合,实现通道间的组合。
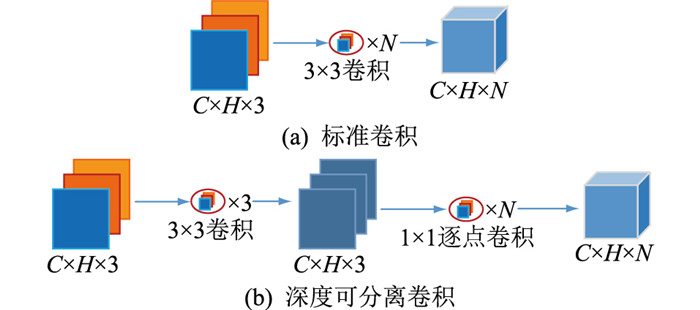
和普通网络比具体有什么区别呢?
标准卷积网络
对于 12×12×3的输入图像,即图像尺寸为 12×12,通道数为3,对图像进行 5×5卷积,没有填充(padding)且步长为1。如果我们只考虑图像的宽度和高度,使用 5×5卷积来处理 12×12大小的输入图像,t最终可以得到一个 8×8的输出特征图。为了获取更多特征假设使用256个卷积核来学习256个不同类别的特征。此时参数量达到(不含偏置项):
参数量 = 卷积核高度 × 卷积核宽度 × 输入通道数 × 输出通道数
参数量 = 5 × 5 × 3 × 256= 983040
乘法操作个数 = 卷积核高度 × 卷积核宽度 × 输入通道数 × 输出特征图宽度 × 输出特征图高度 × 输出通道数
乘法操作个数 = 5 × 5 × 3 × 8 × 8 × 256= 1228800
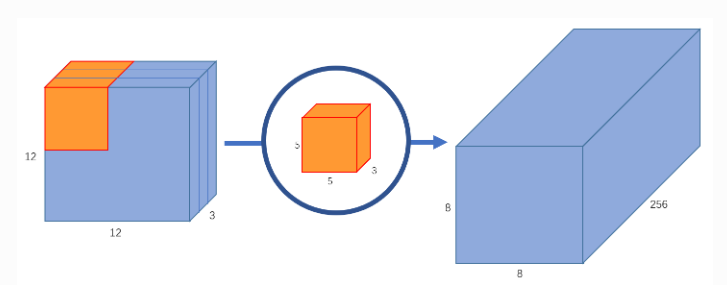
深度卷积
首先使用5×5的卷积核进行逐通道运算,分别提取输入图像中3个 channel 的特征得到3个 8×8×1的输出特征图,即8×8×3的输出特征图。
参数量 =5 × 5 × 3 = 75
乘法操作个数 = 5 × 5 × 3 × 8 × 8= 4800
此时会发现通道数不变,缺少通道间的特征融合,故而需要逐点卷积,其作用可以理解为升维或降维。
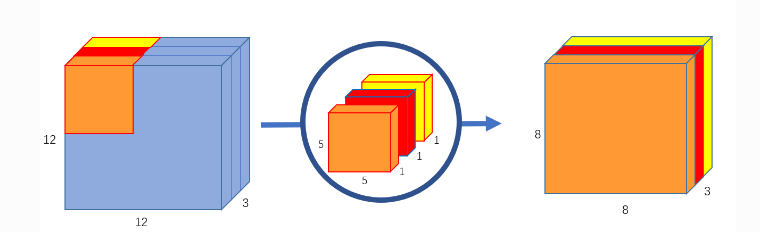
逐点卷积
再深度卷积的基础上使用 1×1卷积核进行卷积,此时可以选择3通道对上文 8×8×3的特征图进行运算 得到8×8×1的输出特征图 ,若使用256个1×1的3通道卷积,则可得到 8×8×256的特征图。
乘法操作个数(PW)= 8 × 8 × 3 × 256= 49152
参数量(PW)= 3 × 256= 768

核心层

网络瘦身其他方法
下采样(Stride):在某些深度可分离卷积块中,会使用步长大于1的卷积来减小特征图的空间尺寸,从而减少计算量,加速模型并保持感受野大小。
宽度乘数(Width Multiplier, α):整个网络中,宽度乘数被用来按比例缩小网络的宽度,即减少每层的滤波器数量,从而进一步减少模型的参数量和计算成本。
分辨率乘数(Resolution Multiplier, β):控制输入图像的分辨率,间接控制中间层feature map的大小。允许用户在精度和速度之间进行权衡。
全局平均池化(Global Average Pooling, GAP):在网络的尾部,使用GAP层替代全连接层,以减少参数量并保持平移不变性。GAP层将每个通道的空间维度平均化为一个值,得到一个形状为(1x1xC)的特征向量,其中C是通道数。
💻代码
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, DepthwiseConv2D, BatchNormalization, ReLU, Dense, GlobalAveragePooling2D, Dropout, Activation
# 定义深度可分卷积块
def BottleneckV1(inputs, in_channels, out_channels, stride):
# DW卷积层
x = DepthwiseConv2D(kernel_size=3, padding='same', strides=stride, depth_multiplier=1, use_bias=False)(inputs)
x = BatchNormalization()(x) # 批量归一化
x = ReLU(max_value=6)(x) # ReLU6激活函数
# PW卷积层
x = Conv2D(out_channels, kernel_size=1, strides=1, use_bias=False)(x)
x = BatchNormalization()(x) # 批量归一化
x = ReLU(max_value=6)(x) # ReLU6激活函数
return x
# MobileNetV1模型定义
def MobileNetV1(num_classes=5):
inputs = Input(shape=(224, 224, 3)) # 输入层
x = Conv2D(32, kernel_size=3, strides=(2, 2), padding='same', use_bias=False)(inputs)
x = BatchNormalization()(x) # 批量归一化
x = ReLU(max_value=6)(x) # ReLU6激活函数
# 以下是MobileNet V1的深度可分卷积架构层
x = BottleneckV1(x, 32, 64, (1, 1)) # Bottleneck模块
x = BottleneckV1(x, 64, 128, (2, 2)) # 随着模块的增加,步长和输出通道数可能会变化
x = BottleneckV1(x, 128, 128, (1, 1)) # 重复Bottleneck模块建模深度网络
x = BottleneckV1(x, 128, 256, (2, 2))
x = BottleneckV1(x, 256, 256, (1, 1))
# 重复的深度卷积和逐点卷积模块
x = BottleneckV1(x, 256, 512, (2, 2))
for _ in range(5): # 512输出通道数的Bottleneck重复5次
x = BottleneckV1(x, 512, 512, (1, 1))
x = BottleneckV1(x, 512, 1024, (2, 2)) # 步长为2的Bottleneck模块,增加输出尺寸
x = BottleneckV1(x, 1024, 1024, (1, 1)) # 输出通道数为1024的Bottleneck模块
x = GlobalAveragePooling2D()(x) # 全局平均池化层
x = Dense(1024)(x) # 全连接层
x = Dropout(0.2)(x) # Dropout防止过拟合
x = Dense(num_classes)(x) # 全连接层,设置输出类别数
outputs = Activation('softmax')(x) # Softmax激活函数获取概率分布
model = Model(inputs, outputs) # 定义模型的输入输出
return model
# 创建MobileNetV1模型实例
model = MobileNetV1(num_classes=5)
model.summary() # 输出模型结构
# 编译模型,准备训练
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])















 2466
2466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









