







学习工具:
dir():打开,看见
help():官方的解释文档
加载数据
dir(torch.cuda.is_available) -----------注意,不是is_available()
输出前后带_ _,表明.is_available不是分割区,是函数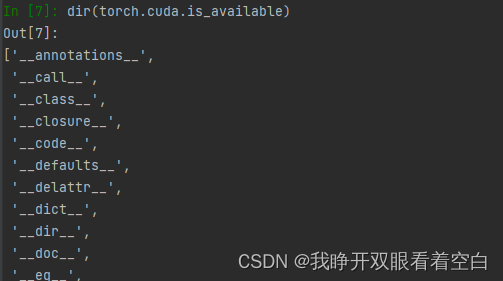
————————————————————————————————————————————
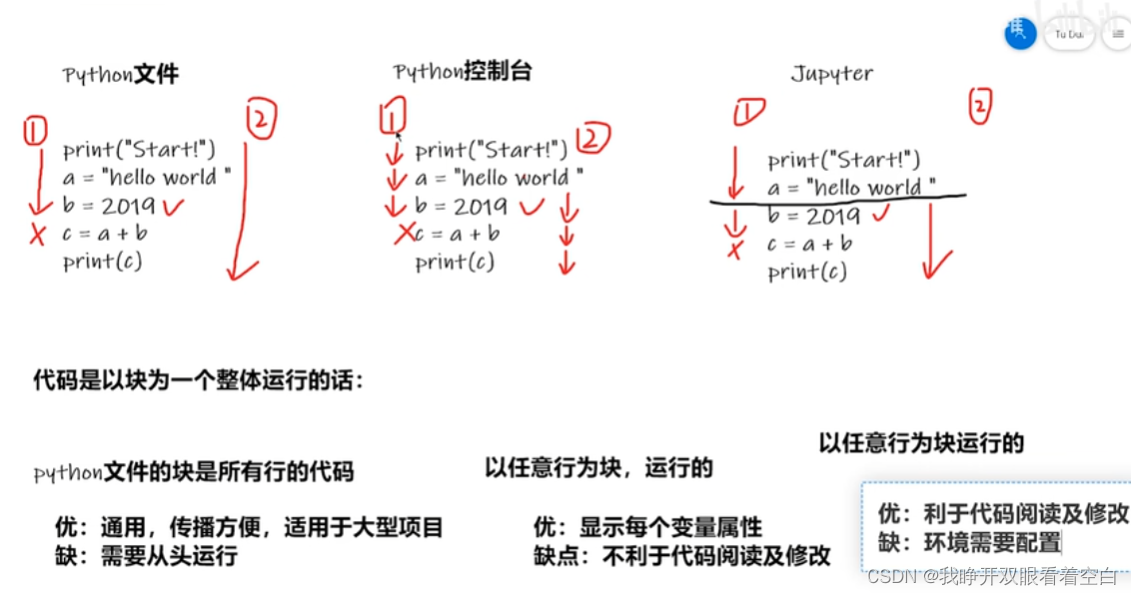
三种写代码的不同
———————————————————————————————————————————————————————
windows里用\表示转译

———————————————————————————————————————————————————————
1.os.path.join() 拼接地址
2.os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
它不包括 . 和 … 即使它在文件夹中。
只支持在 Unix, Windows 下使用。
加载数据代码
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir, label_dir):
# 为整个class提供全局变量
# 为一些方法提供一些量
self.root_dir = root_dir
self.label_dir=label_dir
self.path=os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)
img=Image.open(img_item_path)
label=self.img_path
return img,label
def __len__(self):
return len(self.img_path)
root_dir=r"data/dataset/train"
ants_label_dir="ants_image"
bees_label_dir="bees_image"
ants_dataset=MyData(root_dir,ants_label_dir)
bees_dataset=MyData(root_dir,bees_label_dir)
#合并
train_dataset = ants_dataset + bees_dataset
#img,label = ants_dataset[0]
#img.show()
#会展现出第0张蚂蚁的图片
ants_jpgname=ants_dataset.img_path
bees_jpgname=bees_dataset.img_path
for i in ants_jpgname:
ants_lebelname=i.split('.jpg')[0]+'.txt'
with open(r"D:\shenduxuexi\data\dataset\train\ants_label\{}".format(ants_lebelname),'w') as f:
pass
#这里是写入每张照片的信息
for i in bees_jpgname:
bees_lebelname=i.split('.jpg')[0]+'.txt'
with open(r"D:\shenduxuexi\data\dataset\train\bees_label\{}".format(bees_lebelname),'w') as f:
pass
#这里是写入每张照片的信息
Tenserboard
是TensorFlow提供的一个强大的可视化工具,也是一个Web应用程序套件,通过运行本地服务器,在浏览器中显示训练过程中记录的数据。
探究模型不同阶段是怎么输出的
from torch.utils.tensorboard import SummaryWriter
#创建实例
writer = SummaryWriter(logs)
#两种方法
writer.add_image()
writer.add_scalar()
writer.close()
writer.add_scalar():
def add_scalar(
self,
tag,#标题
scalar_value,#y轴
global_step=None,#x轴
walltime=None,
new_style=False,
double_precision=False,
):
在Terminal激活环境: conda cativate 环境名
打开端口:
tensorboard --logdir=logs
#logdir=事件文件所在文件夹名
#默认打开端口是6006
#指定端口防止与别人冲突:
tensorboard --logdir=logs --port=6007

writer.add_image()
- 利用Opencv读取图片,获得numpy类型图片数据
先pip install opencv-python
import cv2
cv_img = cv2.imread(img_path)

- 用numpy.array(),对PIL图片进行转换。 用Image.open()打开的图像文件是PIL型
img=Image.open(image_path)
import numpy as np
img_array=np.array(img)
type(img_array)#数据类型
img_array.shape#数据维度
*PyCharm 错误:Empty suite:py文件不要以test开头 *
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
from PIL import Image
#创建实例
writer = SummaryWriter('logs')
image_path=r"D:\shenduxuexi\data\dataset\train\ants_image\0013035.jpg"
img_PIL=Image.open(image_path)
img_array=np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
writer.add_image("test",img_array,1,dataformats='HWC')
#不改变tag,只改变step和图片地址,出来的图会在一个框内,可以看每一步是什么图片
#dataformats是看add_image文档得的
#y=x
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
#多了logs文件夹,里面是tensorboard的事件文件
writer.close()
transform
主要是对图形进行变化、处理
transforms结构及用法
拿一定格式的图片,经过transforms.py的工具,得到想要的图片的结果or图片的变化
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
# python 用法
# tensor数据类型
# 通过transforms.ToTensor去解决两个问题
# 1.transforms要怎么使用
# 2.why 需要Tensor数据类型
# tensor数据类型包装了进行深度学习的时候需要的一些数据
img_path = r"D:\shenduxuexi\data\dataset\train\ants_image\0013035.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs1")
#1.transforms要怎么使用
# 实例化ToTensor,将图片转化为tensor类型
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
#print(tensor_trans)
# 2.why 需要Tensor数据类型
# tensor数据类型包装了进行深度学习的时候需要的一些数据
writer.add_image("Tensor_img",tensor_img)
writer.close()
常见的Transforms

from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs2")
img = Image.open(r'D:\shenduxuexi\images\0013035.jpg')
#ToTensor
trans_totensor=transforms.ToTensor()
img_tensor=trans_totensor(img)
writer.add_image("ToTensor",img_tensor)
#Normalize
#三个0表示 第一个通道 第一行 第一列
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1,2,3],[2,4,5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normlize",img_norm,1)
#Resize
print(img.size)
trans_resize=transforms.Resize((512,512))
img_resize=trans_resize(img)
#img 经过resize,PIL->PIL
print(img_resize)
#输出的是PIL类型,若想在tensorboard上显示,用ToTensor转化为tensor类型
img_resize=trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
#Compose - resize
# 输入的是一个序列,不改变高和宽的比例,只改变最小边
trans_resize_2 = transforms.Resize(512)
#它包含了两个变换操作:首先是trans_resize_2,负责调整图像大小;其次是trans_totensor,将调整大小后的图像从PIL格式转换为PyTorch张量。
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
#应用了这个组合变换到原始图像img上。
img_resize_2 = trans_compose(img)
writer.add_image("Resize",img_resize_2,1)
#RandomCrop 随机裁剪,裁剪的结果是原图片的一部分
#如果RandomCrop中的数字大于图片大小就会报错
trans_random = transforms.RandomCrop(200)
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(1,10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()
主要看输入什么类型,输出什么类型
多看官方文档(阅读源码)
关注方法需要什么参数
不知道返回值是什么的时候,多print(),print(type))
torchvision数据集的使用
torchvision
torchvision.models提供了多种预训练模型
torchvision.datasets提供了数据集
torchvision.transforms提供了图像预处理功能
import torchvision
from torch.utils.tensorboard import SummaryWriter
#对图片进行一些操作
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
#
train_set = torchvision.datasets.CIFAR10(root=r"./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root=r"./dataset",train=False,transform=dataset_transform,download=True)
# print(test_set[0])
# print(test_set.classes)
#
# img,target = test_set[0]
# print(img)
# print(target)
writer = SummaryWriter("p10")
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()
DataLoader的使用
DataLoader是PyTorch中用于数据预处理和批处理的核心工具。它可以按需加载数据并将其分批送入神经网络进行训练。DataLoader不仅支持数据的批量加载,还可以对数据进行打乱(shuffle)、多进程加载(multiprocessing loading)等操作,以提高数据处理的效率和模型训练的性能。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#这种配置适合于测试阶段,因为测试通常不需要像训练那样频繁地更新模型权重,而且保持数据顺序可能有助于评估模型在特定数据顺序下的表现。
#测试数据集中第一张图片和target
img,target=test_data[0]
print(img.shape)
print(target)
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(targets)

import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#这种配置适合于测试阶段,因为测试通常不需要像训练那样频繁地更新模型权重,而且保持数据顺序可能有助于评估模型在特定数据顺序下的表现。
#测试数据集中第一张图片和target
img,target=test_data[0]
print(img.shape)
print(target)
writer=SummaryWriter("dataloader")
#epoch,多次对这一批数据进行抓取,shuffle应该设置为True
for epoch in range(2):
step = 0
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("epoch = {}".format(epoch), imgs, step)
step=step+1
#不用epoch时:
# step = 0
# for data in test_loader:
# imgs,targets = data
# # print(imgs.shape)
# # print(targets)
# writer.add_images("test_data", imgs, step)
# step=step+1
writer.close()
神经网络基本骨架——nn.Module
要创建一个自定义的神经网络模型,需要继承 nn.Module 类并重写其 init 和 forward 方法。在 init 方法中定义模型的层和参数,forward 方法定义模型的前向传播逻辑。
import torch
from torch import nn
class mod(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):
output = input+1
return output
MOD=mod()
x=torch.tensor(1.0)
output=mod(x)
print(output)
卷积操作
stride (int or tuple, optional): 卷积步长,可以是单个整数或包含两个整数的元组 (stride_height, stride_width),默认为 1。
padding (int or tuple, optional): 输入张量两侧的零填充大小,可以是单个整数或包含两个整数的元组 (padding_height, padding_width),默认为 0。
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
#torch.reshape函数在PyTorch中用于改变张量的形状,而不改变其数据。
input = torch.reshape(input,(1,1,5,5))
# (batchsize,channal,5,5)
kernel = torch.reshape(kernel,(1,1,3,3))
print(input.shape)
print(kernel.shape)
output1 = F.conv2d(input,kernel,stride=1)
print("output1 = \n",output1)
output2 = F.conv2d(input,kernel,stride=2)
print("output2 = \n",output2)
output3 = F.conv2d(input,kernel,stride=1,padding=1)
print("output3 = \n",output3)

卷积层
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(R"D:\shenduxuexi\dataset",train=False,transform=torchvision.transforms.ToTensor(),
download=True)
dataloader= DataLoader(dataset,batch_size=64)
class Ycb(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
ycb=Ycb()
print(ycb)
writer = SummaryWriter("nn_conv2")
step=0
for data in dataloader:
imgs,targets=data
output = ycb(imgs)
# print(imgs.shape)
# print(output.shape)
#torch.Size([64, 3, 32, 32])
writer.add_images("input",imgs,step)
#输出卷积后数据先看对应数据是否符合输出要求!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!'''
#output:torch.Size([64, 6, 30, 30])
# 直接add_image(soutput)会报错,add_images函数要求通道数为3
# 用torch.reshape改变通道数,其中第一个不知道写啥写-1,会自动计算
output=torch.reshape(output, (-1, 3, 30, 30))
#!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!'''
writer.add_images("output", output, step)
step=step+1
writer.close()
池化层
最大池化层——下采样
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(r"D:\shenduxuexi\dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
# input = torch.tensor([[1,2,0,3,1],
# [0,1,2,3,1],
# [1,2,1,0,0],
# [5,2,3,1,1],
# [2,1,0,1,1]])
#
# input = torch.reshape(input,(-1,1,5,5))
# class Ycb()
# ....
# output = ycb(input)
# print(output)
class Ycb(nn.Module):
def __init__(self):
super().__init__()
#ceil_mode:ceil floor
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
ycb=Ycb()
writer=SummaryWriter("nn_maxpool")
step=0
for data in dataloader:
imgs,targets=data
writer.add_images("input",imgs,step)
output=ycb(imgs)
#池化不会改变通道数,不用跟卷积一样改变
writer.add_images("output",output,step)
step=step+1
writer.close()

非线性激活
ReLU()
Sigmoid()
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# input = torch.tensor([[1,-0.5],
# [-1,3]])
# output = torch.reshape(input,(-1,1,2,2))
dataset = torchvision.datasets.CIFAR10(r"D:\shenduxuexi\dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class Ycb(nn.Module):
def __init__(self):
super().__init__()
self.relu1=ReLU()
self.sigmoid1=Sigmoid()
def forward(self,input):
output = self.sigmoid1(input)
return output
ycb=Ycb()
writer = SummaryWriter("relu")
step=0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output=ycb(imgs)
writer.add_images("output",output,step)
step+=1
writer.close()

正则化层:对输入进行正则化,可以加快训练速度
线性层
先看弄成线性后的in_f是多少
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("D:\shenduxuexi\dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
for data in dataloader:
imgs,targets = data
print(imgs.shape)
output=torch.reshape(imgs,(1,1,1,-1))
print(output.shape)

torch.flatten 是 PyTorch 库中的一个函数,用于将张量展平为一维张量。
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("D:\shenduxuexi\dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Ycb(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = Linear(196608,10)
def forward(self,input):
output = self.linear1(input)
return output
ycb=Ycb()
for data in dataloader:
imgs,targets = data
print(imgs.shape)
output = torch.flatten(imgs)
print(output.shape)

搭建实战,Sequential使用
Sequential写法!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
复刻

import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d, Conv2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# class Ycb(nn.Module):
# def __init__(self):
# super().__init__()
# self.conv1 = Conv2d(3, 32,5,padding=2)#padding是根据公式算的
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32,32,5,padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32,64,5,padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024,64)
# self.linear2 = Linear(64,10)
# def forward(self, x):
# x=self.conv1(x)
# x=self.maxpool1(x)
# x=self.conv2(x)
# x=self.maxpool2(x)
# x=self.conv3(x)
# x=self.maxpool3(x)
# x=self.flatten(x)
# x=self.linear1(x)
# x=self.linear2(x)
# return x
#若用Sequential,代码会更简洁
class Ycb(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, x):
x=self.model1(x)
return x
ycb = Ycb()
print(ycb)
input = torch.ones((64,3,32,32))
output = ycb(input)
print(output.shape)
writer=SummaryWriter("seq")
#add_graph函数通常用于将模型的计算图添加到TensorBoard中
writer.add_graph(ycb,input)
writer.close()
损失函数
1. 计算了实际输出与目标的差距
2. 为更新输出提供了一定的依据(反向传播) grad
nn_loss.py
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1,2,3.])
targets = torch.tensor([1,2,5.])
inputs=torch.reshape(inputs,(1,1,1,3))
targets=torch.reshape(targets,(1,1,1,3))
#MAE 平均绝对误差
loss=L1Loss()
result = loss(inputs,targets)
#MSE 均方误差
loss_mse=nn.MSELoss()
result_mse = loss_mse(inputs,targets)
#交叉熵
x=torch.tensor([0.1,0.2,0.3])
y=torch.tensor([1])
x=torch.reshape(x,(1,3))
loss_cross=nn.CrossEntropyLoss()
result_cross=loss_cross(x,y)
print(result_cross)
nn_loss_network.py
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("D:\shenduxuexi\dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Ycb(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, x):
x=self.model1(x)
return x
loss = nn.CrossEntropyLoss()
ycb = Ycb()
for data in dataloader:
imgs,targets=data
outputs=ycb(imgs)
# #输出outputs和targets,看看选哪个损失函数,这里选的交叉熵
# print(outputs)
# print(targets)
result_loss=loss(outputs,targets)
print(result_loss)
#一定是经过了loss的变量进行反向传播
result_loss.backward()
#print(ycb)
优化器
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("D:\shenduxuexi\dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
class Ycb(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, x):
x=self.model1(x)
return x
loss = nn.CrossEntropyLoss()
ycb = Ycb()
optim=torch.optim.SGD(ycb.parameters(),lr=0.01)#刚开始学习速率用大一点的,后来用小一点的
for epoch in range(20):
#看每一轮loss是多少
running_loss=0.0
for data in dataloader:
imgs,targets=data
outputs=ycb(imgs)
result_loss=loss(outputs,targets)
#把优化器的参数设置为0
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss=running_loss+result_loss
print(running_loss)
#会发现loss会慢慢变小

现有网络模型的使用和修改
import torchvision
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
vgg16_false = torchvision.models.vgg16(weights=None)
vgg16_true = torchvision.models.vgg16(weights='DEFAULT')
print(vgg16_true)
vgg16_true的classifier结果:
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
1. 对vgg16_true加一层线性层
import torchvision
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
vgg16_false = torchvision.models.vgg16(weights=None)
vgg16_true = torchvision.models.vgg16(weights='DEFAULT')
train_data = torchvision.datasets.CIFAR10("D:\shenduxuexi\dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#如何利用现有的网络,去改变他的结构 迁移学习
#以vgg16为前置网络
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))
print(vgg16_true)
结果会是
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)#多了这个
)
2. 修改最后的线性层
import torchvision
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
vgg16_false = torchvision.models.vgg16(weights=None)
vgg16_true = torchvision.models.vgg16(weights='DEFAULT')
train_data = torchvision.datasets.CIFAR10("D:\shenduxuexi\dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#如何利用现有的网络,去改变他的结构 迁移学习
# #以vgg16为前置网络,加层
# vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))
# print(vgg16_true)
#2. 修改网络
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096,10,True)
print(vgg16_false)
修改前

修改后

网络模型的保存与读取
一般保存和读取会在不同的文件里
方式1
import torchvision
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
vgg16=torchvision.models.vgg16(pretrain=False)
#保存方式1 不仅保存了网络结构,也保存了一些网络参数
torch.save(vgg16,"vgg16_method1.pdh")#推荐后缀为pdh
#加载方式1 对应保存方式1
model = torch.load(("vgg16_method1.pdh"))
#陷阱
class Ycb(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Conv2d(3,64,kernel_size=3)
def forward(self,input):
output = self.conv1(input)
return output
ycb=Ycb()
#保存
torch.save(ycb,"ycb_mothod1.pth")
#在另一个文件里加载
model=torch.load("ycb_mothod1.pth")
#会报错,需要把保存的文件在加载的文件里import from model_save import *
方式2
import torchvision
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
vgg16=torchvision.models.vgg16(pretrain=False)
#保存方式2(官方推荐) 把vgg16的参数保存成字典,只保存了模型参数
torch.save(vgg16.state_dict(),"vgg16_method2.pdh")
#加载方式2
# 因为保存方式2只保存了字典,所以要先载入模型
vgg16 = torchvision.models.vgg16(pretrained = False)
# 再把参数填充进去
vgg16.load_state_dict(torch.load(("vgg16_method1.pdh")))
















 8050
8050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









