







 本文详细介绍了RISC架构(如ARM)与CISC架构(如x86-64和x86)的区别,重点讲解了x86-64的寄存器、指令集、内存地址计算和控制流程。此外,涵盖了Assembly语言基础,如指令格式、数据类型操作和控制流技巧,以及过程调用和内存管理的原理。
本文详细介绍了RISC架构(如ARM)与CISC架构(如x86-64和x86)的区别,重点讲解了x86-64的寄存器、指令集、内存地址计算和控制流程。此外,涵盖了Assembly语言基础,如指令格式、数据类型操作和控制流技巧,以及过程调用和内存管理的原理。
CMU15-213 Machine Level Programming
本篇参考了 小土刀的博客。
1、history of Intel processors and architecture


精简指令集计算机(reduced instruction set computer,RISC)或简译为精简指令集,是计算机中央处理器的一种设计模式。这种设计思路可以想像成是一家模块化的组装工厂,对指令数目和寻址方式都做了精简,使其实现更容易,指令并行执行程度更好,编译器的效率更高。
基于RISC的架构:
- ARM架构,过去称作高级精简指令集机器(Advanced RISC Machine,更早称作艾康精简指令集机器,Acorn RISC Machine),是一个精简指令集(RISC)处理器架构家族。ARM处理器非常适用于移动通信领域,符合其主要设计目标为低成本、高性能、低耗电的特性。
与之相对应的是复杂指令集电脑(Complex Instruction Set Computer,CISC)是一种微处理器指令集架构,复杂指令集的特点是指令数目多而复杂,每条指令字长并不相等,电脑必须加以判读,并为此付出了性能的代价。
复杂指令集电脑(Complex Instruction Set Computer,CISC)是一种微处理器架构。复杂指令集的特点是指令数目多而复杂,每条指令字长并不相等,电脑必须加以判读,并为此付出了性能的代价。
基于CISC的架构:
-
x86泛指一系列基于Intel 8086且向后兼容的中央处理器指令集架构。最早的8086处理器于1978年由Intel推出,为16位微处理器。现时英特尔将其称为IA-32(即 Intel Architecture, 32-bit),一般情形下指代32位的架构。
-
x86-64(又称x64,即64-bit extended,64位拓展)是一个处理器的指令集架构,基于x86架构的64位拓展,向后兼容于16位和32位的x86架构。由2003年AMD对于x86发展了64位的扩展,并命名为AMD64。后来英特尔也推出了与之兼容的处理器,并命名为Intel 64。两者被统称为x86-64或x64,开创了x86的64位时代。
注意:英特尔早在1990年代就与惠普合作提出了一种用在安腾系列处理器中的独立的64位架构,这种架构被称为IA-64。IA-64是一种崭新的系统,和x86架构完全没有相似性;不应该把它与x86-64或x64弄混。
2、C、Assembly、machine code

ISA:指令集架构,Microarchitecture:指令集架构的底层实现。
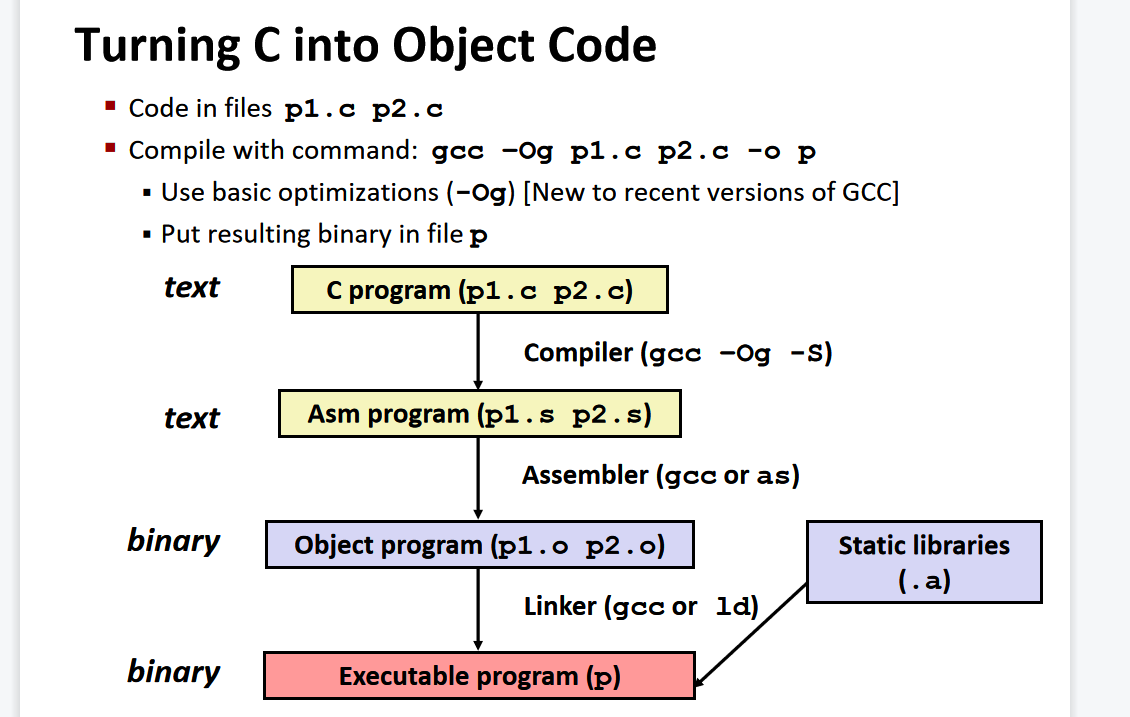
-
Assembler
- Translates .s into .o
- Binary encoding of each instruction
- Nearly-complete image of executable code
- Missing linkages between code in different files
-
Linker
- Resolves references between files
- Combines with static run-time libraries
- E.g., code for malloc, printf
- Some libraries are dynamically linked,Linking occurs when program begins execution
-
Compiling Into Assembly:
gcc –Og –S sum.c-S表示stop
-
Compiling into Object code:
gcc -Og sum.c -o sum指定编译出的Object Code放在sum文件中
-
Disassemble(反汇编)

-
gdb

Anything that can be interpreted as executable code can be disassembled。
Machine Level Programming 1:Assembly Basics汇编基础

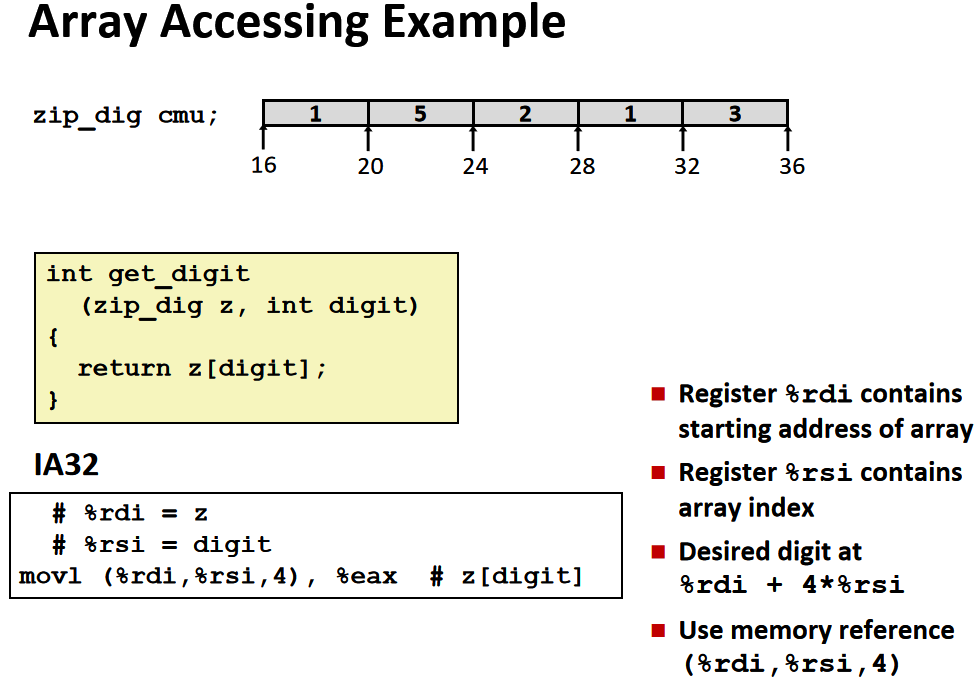
x86-64有16个64位的寄存器,其中8个沿用旧的x86架构中的名称,还有新引入的8个,将它们从%8命名到%r15

这些寄存器的名字来自于8086的遗留,在8086时,它们的名字与它们的功能相对应。但是在x86-64中,这些名字和功能没有任何关系。
x86-64 架构中的整型寄存器如下图所示(暂时不考虑浮点数的部分)
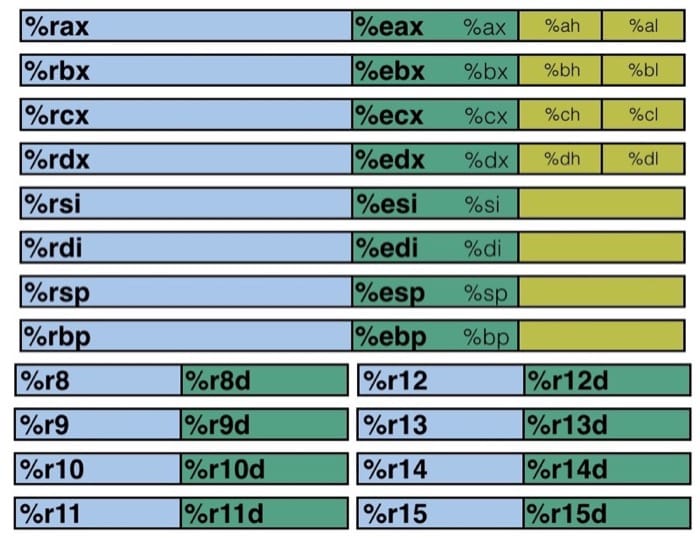
仔细看看寄存器的分布,我们可以发现有不同的颜色以及不同的寄存器名称,黄色部分是 16 位寄存器,也就是 16 位处理器 8086 的设计,然后绿色部分是 32 位寄存器(这里我是按照比例画的),给 32 位处理器使用,而蓝色部分是为 64 位处理器设计的。这样的设计保证了令人震惊的向下兼容性,几十年前的 x86 代码现在仍然可以运行!
前六个寄存器(%rax, %rbx, %rcx, %rdx, %rsi, %rdi)称为通用寄存器,有其『特定』的用途:
- %rax(%eax) 用于做累加
- %rcx(%ecx) 用于计数
- %rdx(%edx) 用于保存数据
- %rbx(%ebx) 用于做内存查找的基础地址
- %rsi(%esi) 用于保存源索引值
- %rdi(%edi) 用于保存目标索引值
而 %rsp(%esp) 和 %rbp(%ebp) 则是作为栈指针和基指针来使用的。
moving data
下面我们通过 movq 这个指令来了解操作数的三种基本类型:立即数(Imm)、寄存器值(Reg)和内存值(Mem)。

对于 movq 指令来说,需要源操作数和目标操作数,源操作数可以是立即数、寄存器值或内存值的任意一种,但目标操作数只能是寄存器值或内存值。指令的具体格式可以这样写 movq [Imm|Reg|Mem], [Reg|Mem],第一个是源操作数,第二个是目标操作数,例如:
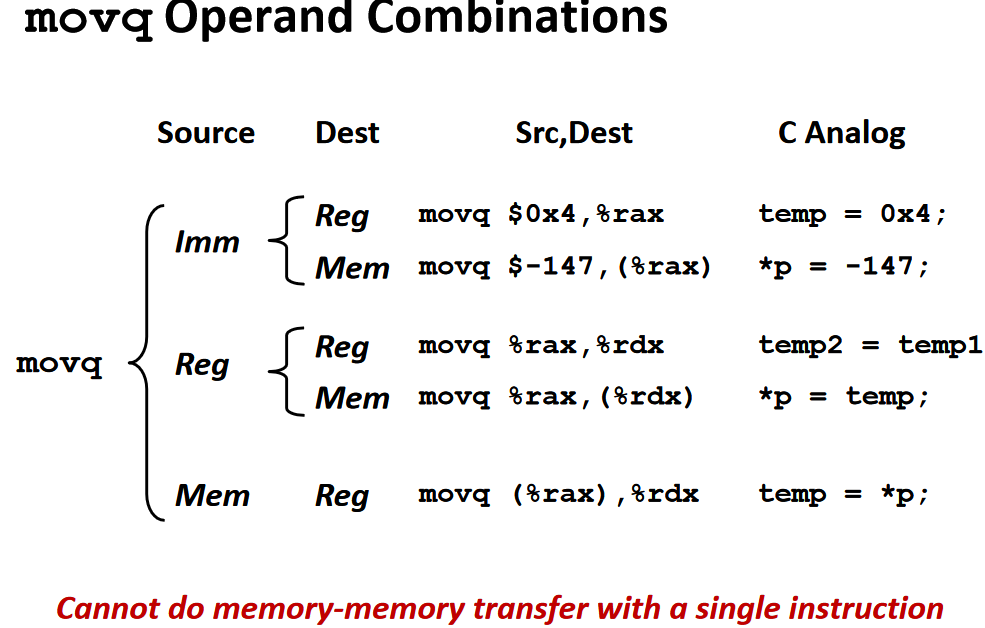
movq Imm, Reg->mov $0x5, %rax->temp = 0x5;movq Imm, Mem->mov $0x5, (%rax)->*p = 0x5;movq Reg, Reg->mov %rax, %rdx->temp2 = temp1;movq Reg, Mem->mov %rax, (%rdx)->*p = temp;movq Mem, Reg->mov (%rax), %rdx->temp = *p;
这里有一种情况是不存在的,没有 movq Mem, Mem 这个方式,也就是说,我们没有办法用一条指令完成内存间的数据交换。
Memory Addressing Modes

( )类似于C语言中的解引用*,来获得对应地址的内存单元的内容,这也分两种情况:
-
Normal,普通模式,®,相当于
Mem[Reg[R]],也就是说寄存器 R 指定内存地址,类似于 C 语言中的指针,语法为:movq (%rcx), %rax也就是说以 %rcx 寄存器中存储的地址去内存里找对应的数据,存到寄存器 %rax 中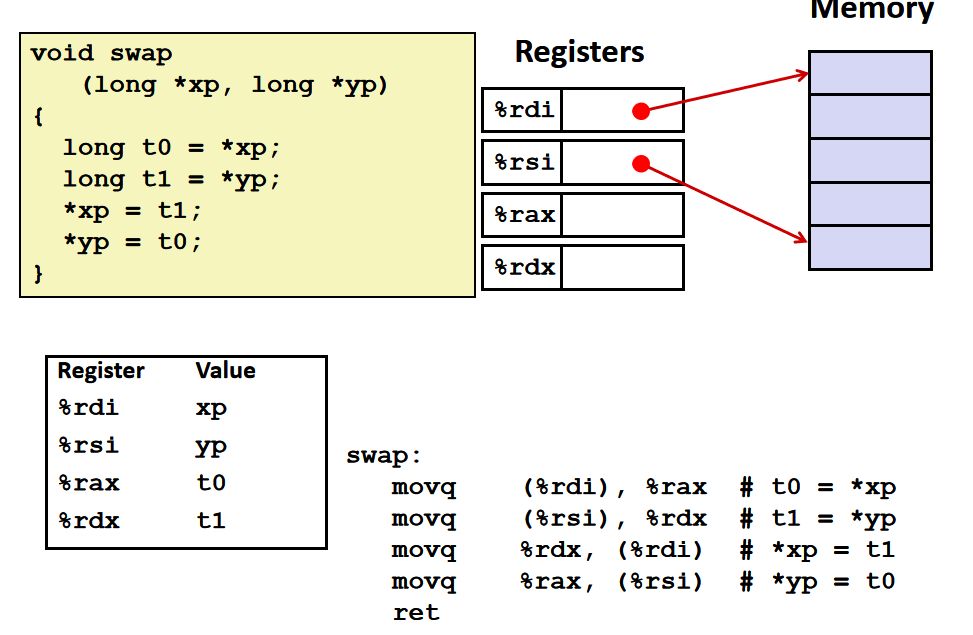
-
Displacement,移位模式,D®,相当于
Mem[Reg[R]+D],寄存器 R 给出起始的内存地址,然后 D 是偏移量,语法为:movq 8(%rbp),%rdx也就是说以 %rbp 寄存器中存储的地址再加上 8 个偏移量去内存里找对应的数据,存到寄存器 %rdx 中。对于寻址来说,比较通用的格式是D(Rb, Ri, S)->Mem[Reg[Rb]+S*Reg[Ri]+D],其中:D- 常数偏移量Rb- 基寄存器Ri- 索引寄存器,不能是 %rspS- 系数
除此之外,还有如下三种特殊情况
(Rb, Ri)->Mem[Reg[Rb]+Reg[Ri]]D(Rb, Ri)->Mem[Reg[Rb]+Reg[Ri]+D](Rb, Ri, S)->Mem[Reg[Rb]+S*Reg[Ri]]

这里假设 %rdx 中的存着
0xf000,%rcx 中存着0x0100,那么0x8(%rdx)=0xf000+0x8=0xf008(%rdx, %rcx)=0xf000+0x100=0xf100(%rdx, %rcx, 4)=0xf000+4*0x100=0xf4000x80(, %rdx, 2)=2*0xf000+0x80=0x1e080

地址计算指令leaq:

具体格式为 leaq Src, Dst,其中 Src 是地址的表达式,然后把计算的值存入 Dst 指定的寄存器,也就是说,无须内存引用就可以计算,类似于 p = &x[i];。与( )类似于解引用*对应,leaq指令类似于C语言中的&,来获取src的地址值。常用来和( )相配合,计算x+k *y的值。类似”不解引用“。
-
算术表达式
需要两个操作数的指令:

需要一个操作数的指令:

example:
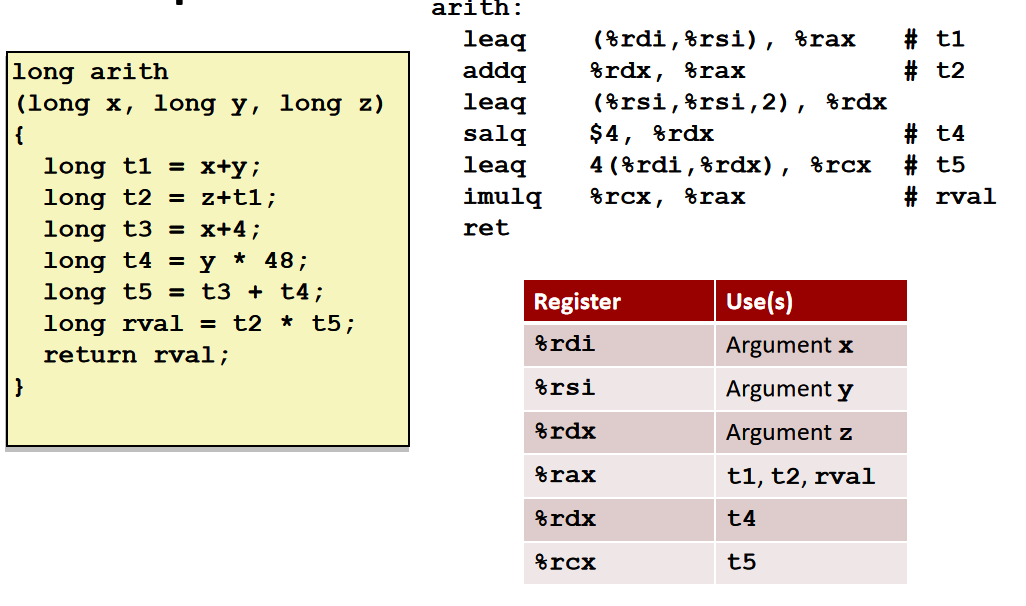
leaq:计算地址;salq向左移位;imulq相乘
- add指令只能用于计算类似x+=y的表达式,不能计算类似x=y+z的表达式。
- imulq只能计算x* =y的表达式,不能计算x=y* z的表达式。
- *所以通常使用leaq来计算形如x=y+z,x=k*y,x=z+k y这种有多个参数的表达式。
注意:x86-64的参数顺序与8086是相反的,右边的是dest,左边的才是src。
指令中的q代表quad(四),Intel内部术语,代表四个字。在早期8086中,一个字是16位,四个字就是64位,代表这是64位的指令。
Machine Level Programming 2:control流程控制
寄存器中存储着当前正在执行的程序的相关信息:
- 临时数据存放在 (%rax, …)
- 运行时栈的地址存储在 (%rsp) 中
- 目前的代码控制点存储在 (%rip, …) 中
- 目前测试的状态放在 CF, ZF, SF, OF 中
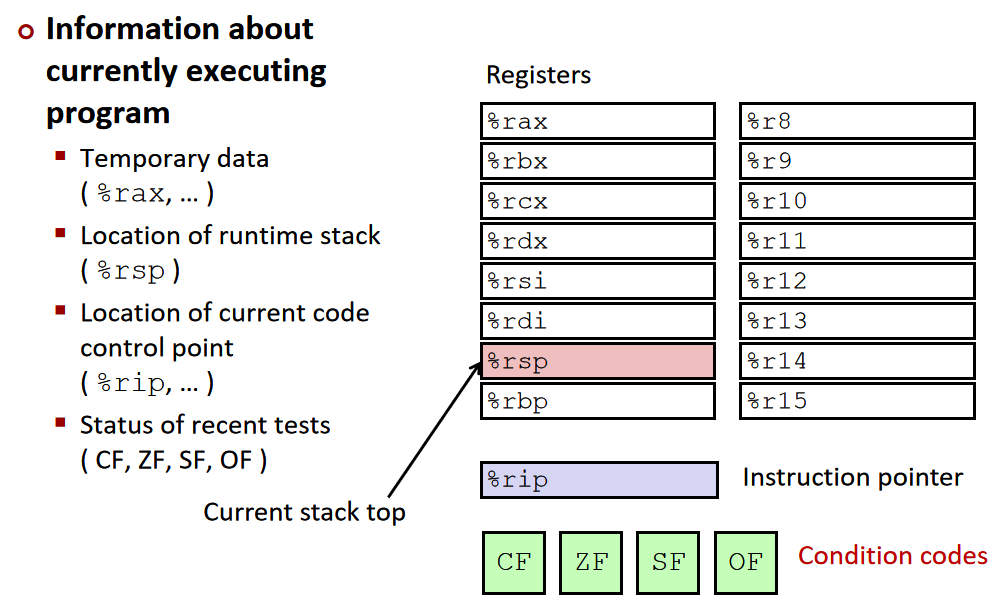
condition code条件代码
四个标识位(CF, ZF, SF, OF)就是用来辅助程序的流程控制的,意思是:
- CF: Carry Flag (针对无符号数)
- ZF: Zero Flag
- SF: Sign Flag (针对有符号数)
- OF: Overflow Flag (针对有符号数)
可以看到以上这四个标识位,表示四种不同的状态。注意CF是针对无符号数判断是否溢出,OF是针对有符号数判断是否溢出(因为无符号数溢出的条件和有符号数溢出的条件不同)。
set condition code
-
Implicit setting隐式设置:通过算术运算来设置。假如我们有一条诸如
t = a + b的语句,汇编之后假设用的是addq Src, Dest,那么根据这个操作结果的不同,会相应设置上面提到的四个标识位,而因为这个是执行算术运算操作时顺带进行设置的,称为隐式设置。
- 如果两个数相加,在最高位还需要进位(也就是溢出了),那么 CF 标识位就会被设置
- 如果 t 等于 0,那么 ZF 标识位会被设置
- 如果 t 小于 0,那么 SF 标识位会被设置
- 如果 2’s complement 溢出,那么 OF 标识位会被设置为 1(溢出的情况是
(a>0 && b > 0 && t <0) || (a<0 && b<0 && t>=0))
这四个条件代码,是用来标记上一条命令的结果的各种可能的,是自动会进行设置的。注意,使用
leaq指令的话不会进行设置。 -
Explicit setting显式设置:
-
compare:
具体的方法是使用
cmpq指令,cmpq Src2(b), Src1(a)等同于计算a-b(注意 a b 顺序是颠倒的),然后利用a-b的结果来对应进行条件代码的设置:
- 如果在最高位还需要进位(也就是溢出了),那么 CF 标识位就会被设置
- a 和 b 相等时,也就是
a-b等于零时,ZF 标识位会被设置 - 如果 a < b,也就是
(a-b)<0时,那么 SF 标识位会被设置 - 如果 2’s complement 溢出,那么 OF 标识位会被设置(溢出的情况是
(a>0 && b < 0 && t <0) || (a<0 && b>0 && t>0))
-
Test:使用
testq指令,具体来说testq Src2(b), Src1(a)等同于计算a&b(注意 a b 顺序是颠倒的),然后利用a-b的结果来对应进行条件代码的设置,通常来说会把其中一个操作数作为 mask:- 当
a&b == 0时,ZF 标识位会被设置 - 当
a&b < 0时,SF 标识位会被设置

- 当
-
reading condition code
获取状态码的方式:基于状态码设置目标寄存器的低位(低字节)为0或为1,不改变剩余的7个字节。
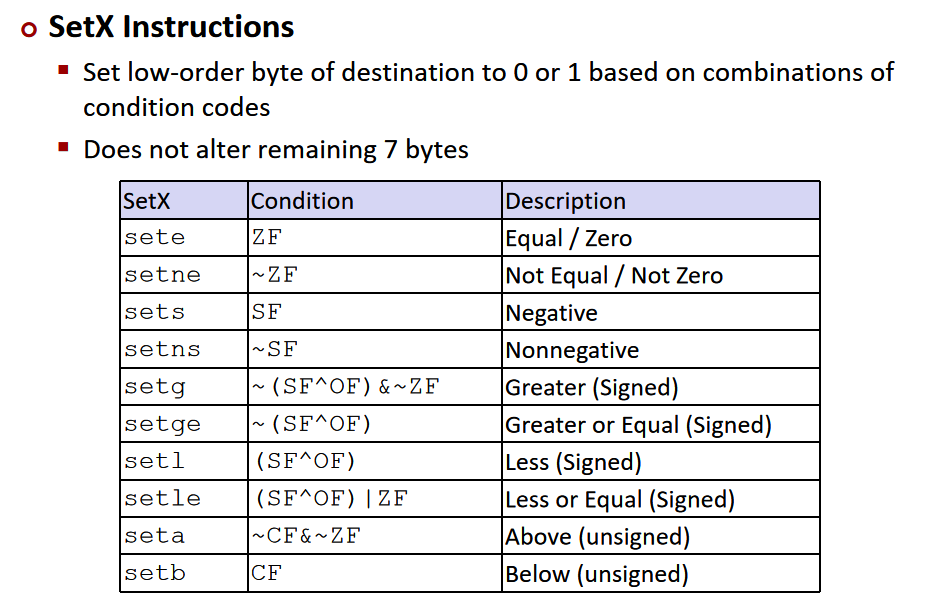
我们可以直接引用寄存器的最低字节:

由于setX指令只改变最低位的字节,所以要获取状态码,我们还需要改变剩余的7个字节。可以使用movzbl指令(move zero extension byte to long),对低位的一个字节进行0扩展,即将它的高位全部扩展为0,然后存入另一个寄存器。

%eax是%rax的一个32位的寄存器,AMD规定,只要一个寄存器的4字节被设置为0,剩余的字节也会被设置为0。
以上的操作最终获取了x>y的结果(即状态码),存入%rax寄存器中。
condition branches:
jump
-
条件跳转:
跳转实际上就是根据条件代码的不同来进行不同的操作
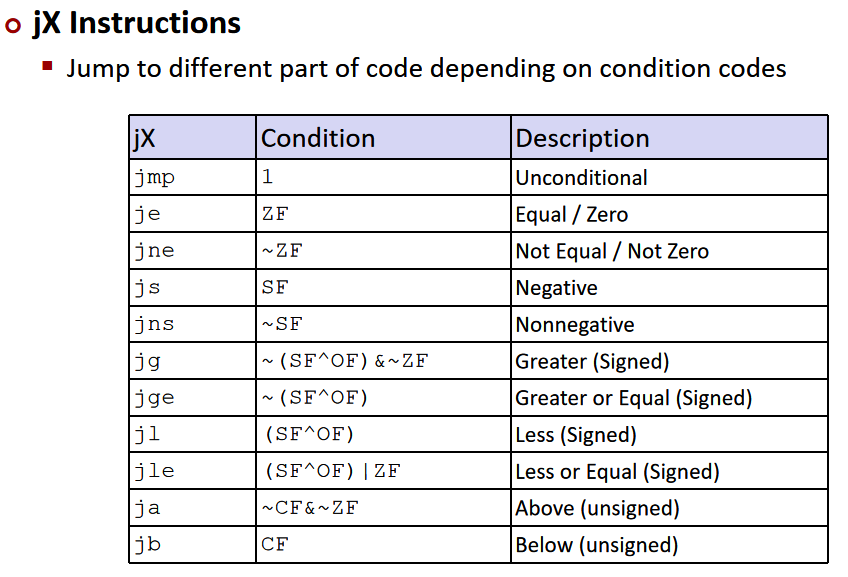

%rdi 中保存了参数 x,%rsi 中保存了参数 y,而 %rax 一般用来存储返回值,然后直接ret。调用函数知道要在%rax获取被调用函数的返回值。
可以使用C语言中的goto语句,类似于汇编语言中的jump

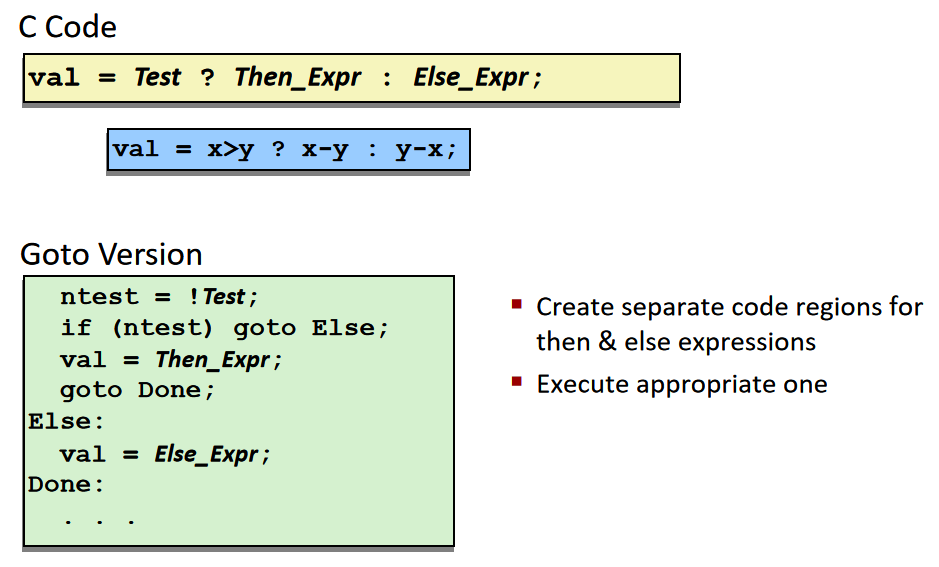
conditional move:
实际上汇编出来的代码,并不是像上面这样的,会采用另一种方法来加速分支语句的执行。现在我们先来说一说,为什么分支语句会对性能造成很大的影响。
我们知道现在的 CPU 都是依靠流水线工作的,比方说执行一系列操作需要 ABCDE 五个步骤,那么在执行 A 的时候,实际上执行 B 所需的数据会在执行 A 的同时加载到寄存器中,这样运算器执行外 A,就可以立刻执行 B 而无须等待数据载入。如果程序一直是顺序的,那么这个过程就可以一直进行下去,效率会很高。但是一旦遇到分支,那么可能执行完 A 下一步要执行的是 C,但是载入的数据是 B,这时候就要把流水线清空(因为后面载入的东西都错了),然后重新载入 C 所需要的数据,这就带来了很大的性能影响。为此人们常常用『分支预测』这一技术来解决(分支预测是另一个话题这里不展开),但是对于这类只需要判断一次的条件语句来说,其实有更好的方法。

具体的做法是:对于只有两个分支的条件语句,将两个分支的结果都计算出来,然后利用条件语句进行赋值。

上图提前将两个分支都算出来,将x-y的结果保存在rax中,y-x的结果保存在rdx中,再根据条件语句判断是否修改rax的值。

但是也有一些情况并不适用于:
- 因为会把两个分支的运算都提前算出来,如果这两个值都需要大量计算的话,就得不偿失了,所以需要分支中的计算尽量简单。
- 另外在涉及指针操作的时候,如
val = p ? *p : 0;,因为两个分支都会被计算,所以可能导致奇怪问题出现 - 最后一种就是如果分支中的计算是有副作用的,那么就不能这样弄
val = x > 0 ? x*= 7 : x+= 3;,这种情况下,因为都计算了,那么 x 的值肯定就不是我们想要的了。
Loop
先来看看并不那么常用的 Do-While 语句以及对应使用 goto 语句进行跳转的版本:
// Do While 的 C 语言代码
long pcount_do(unsigned long x)
{
long result = 0;
do {
result += x & 0x1;
x >>= 1;
} while (x);
return result;
}
// Goto 版本
long pcount_goto(unsigned long x)
{
long result = 0;
loop:
result += x & 0x1;
x >>= 1;
if (x) goto loop;
return result;
}
这个函数计算参数 x 中有多少位是 1,翻译成汇编如下:
movl $0, %eax # result = 0
.L2: # loop:
movq %rdi, %rdx
andl $1, %edx # t = x & 0x1
addq %rdx, %rax # result += t
shrq %rdi # x >>= 1
jne .L2 # if (x) goto loop
rep; ret
其中 %rdi 中存储的是参数 x,%rax 存储的是返回值。
换成更通用的形式,
-
do-while表示如下:
// C Code do Body while (Test); // Goto Version loop: Body if (Test) goto loop -
而对于 While 语句的转换,会直接跳到中间
// C While version while (Test) Body // Goto Version goto test; loop: Body test: if (Test) goto loop; done:如果在编译器中开启
-O1优化,那么会把 While 先翻译成 Do-While,然后再转换成对应的 Goto 版本,因为 Do-While 语句执行起来更快,更符合 CPU 的运算模型。 -
最常用的 For 循环,也可以一步一步转换成 While 的形式,如下:
// For for (Init; Test; Update) Body // While Version Init; while (Test) { Body Update; }
switch
switch语句在底层使用一个跳转表来记录每一个case的地址,所以它的时间复杂度是O(1)。
Machine Level Programming 3:procedure过程调用
**过程调用(也就是调用函数)**具体在 CPU 和内存中是怎么实现的,在过程调用中主要涉及三个重要的方面:
- 传递控制:包括如何开始执行过程代码,以及如何返回到开始的地方
- 传递数据:包括过程需要的参数以及过程的返回值
- 内存管理:如何在过程执行的时候分配内存,以及在返回之后释放内存
在 x86-64 中,所谓的栈,实际上一块内存区域,这个区域的数据进出满足先进后出的原则。越新入栈的数据,地址越低,所以栈顶的地址是最小的。下图中箭头所指的就是寄存器 %rsp 的值,这个寄存器是栈指针,用来记录栈顶的位置。
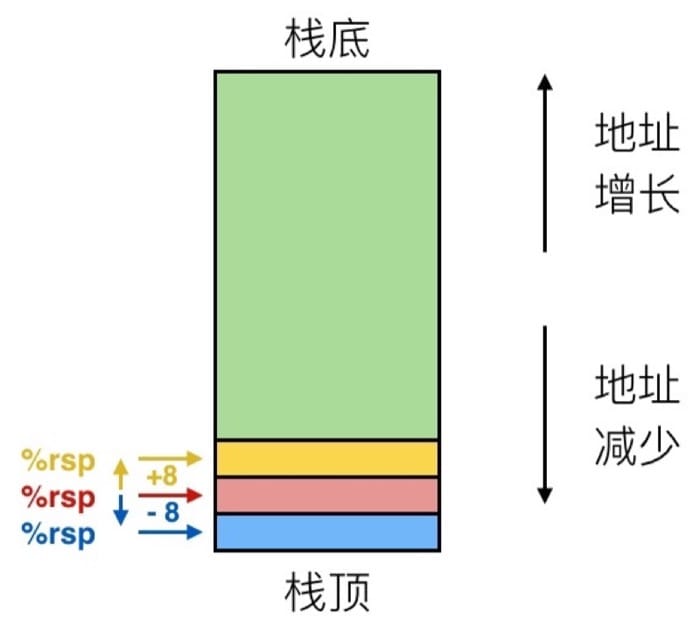
我们假设一开始 %rsp 为红色,对于 push 操作,对应的是 pushq Src 指令,具体会完成下面三个步骤:
- 从地址
Src中取出操作数 - 把 %rsp 中的地址减去 8(也就是到下一个位置)
- 把操作数写入到 %rsp 的新地址中
这个时候 %rsp 就对应蓝色。
重来一次,假设一开始 %rsp 为红色,对于 pop 操作,对应的是 popq Dest 指令,具体会完成下面三个步骤:
- 从 %rsp 中存储的地址中读入数据
- 把 %rsp 中的地址增加 8(回到上一个位置)
- 把刚才取出来的值放到
Dest中(这里必须是一个寄存器)
这时候 %rsp 就对应黄色。
passing control传递控制:
了解了栈的结构之后,我们先通过一个函数调用的例子来具体探索一下过程调用中的一些细节。
// multstore 函数
void multstore (long x, long, y, long *dest)
{
long t = mult2(x, y);
*dest = t;
}
// mult2 函数
long mult2(long a, long b)
{
long s = a * b;
return s;
}
对应的汇编代码为:
0000000000400540 <multstore>:
# x 在 %rdi 中,y 在 %rsi 中,dest 在 %rdx 中
400540: push %rbx # 通过压栈保存 %rbx
400541: mov %rdx, %rbx # 保存 dest
400544: callq 400550 <mult2> # 调用 mult2(x, y)
# t 在 %rax 中
400549: mov %rax, (%rbx) # 结果保存到 dest 中
40054c: pop %rbx # 通过出栈恢复原来的 %rbx
40054d: retq # 返回
0000000000400550 <mult2>:
# a 在 %rdi 中,b 在 %rsi 中
400550: mov %rdi, %rax # 得到 a 的值
400553: imul %rsi, %rax # a * b
# s 在 %rax 中
400557: retq # 返回
可以看到,过程调用是利用栈来进行的,通过 call label 来进行调用(先把返回地址入栈,然后跳转到对应的 label),返回的地址,将是下一条指令的地址,通过 ret 来进行返回(把地址从栈中弹出,然后跳转到对应地址)
call指令先将当前%rip指向的下一条指令的地址push入栈,然后将被调用函数的起始地址送到%rip
被调用函数结束后,ret指令先将栈顶的地址pop到%rip。
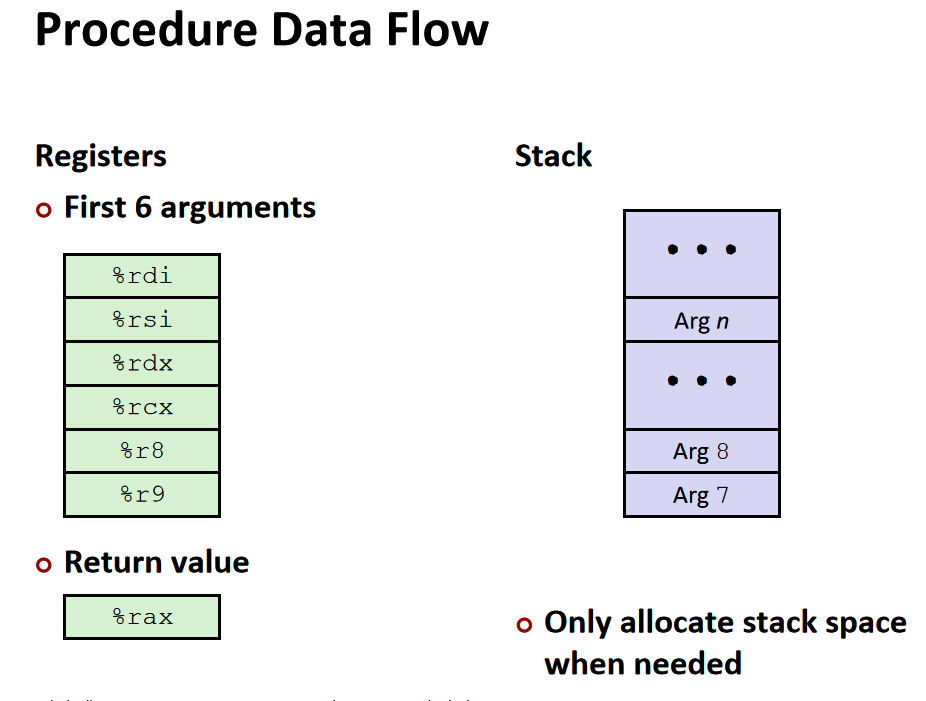
passing data传递数据:
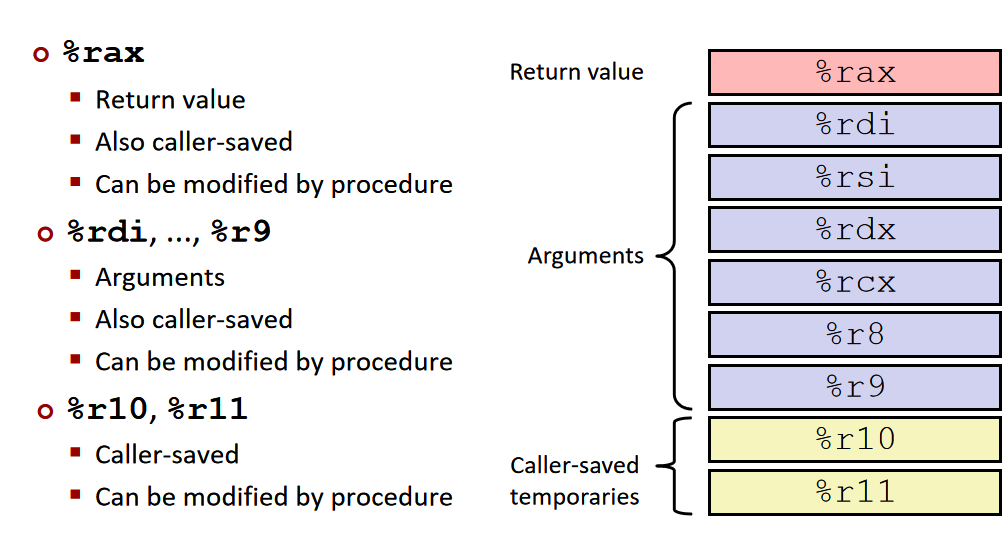
如果参数没有超过六个,那么会放在:%rdi, %rsi, %rdx, %rcx, %r8, %r9 中。如果超过了,会另外放在一个栈中。而返回值会放在 %rax 中。
managing local data内存管理:stack frame
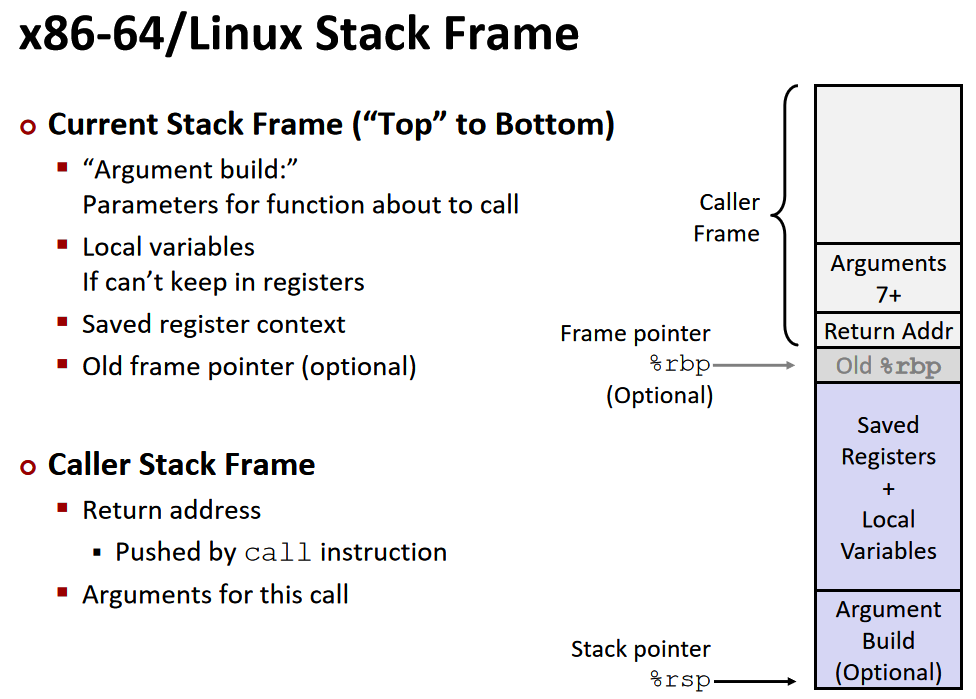
栈中不仅存有地址,还有每一次函数的局部变量。每一次函数调用,即call之后,ret之前,在栈中形成的局部栈称为stack frame。对于每个过程调用来说,都会在栈中分配一个帧 Frames。每一帧里需要包含:
- 返回信息
- 本地存储(如果需要)
- 临时空间(如果需要)
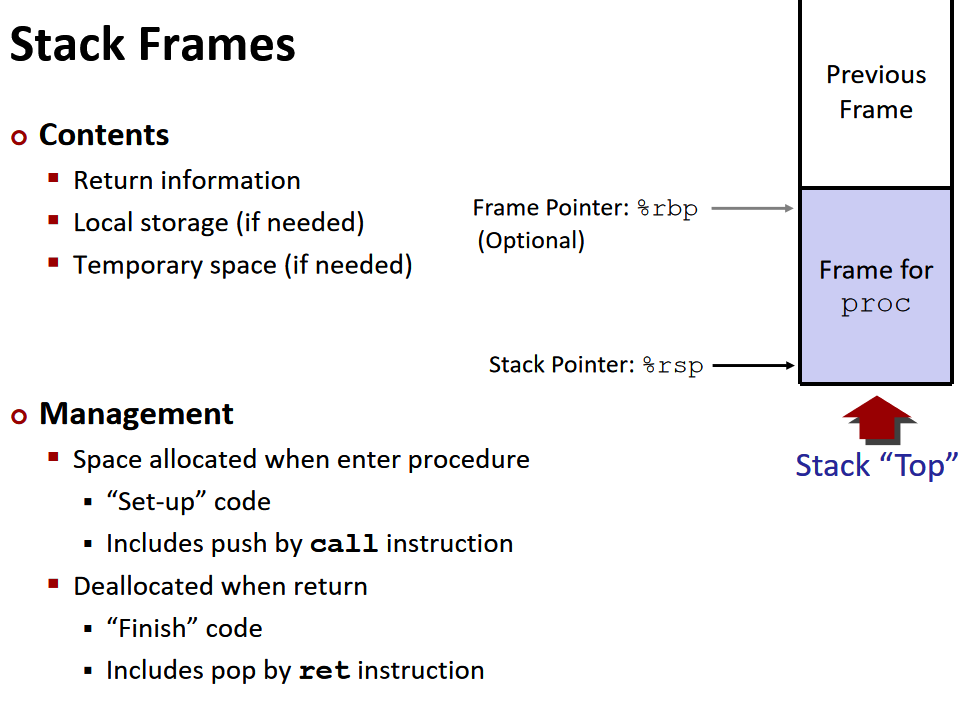
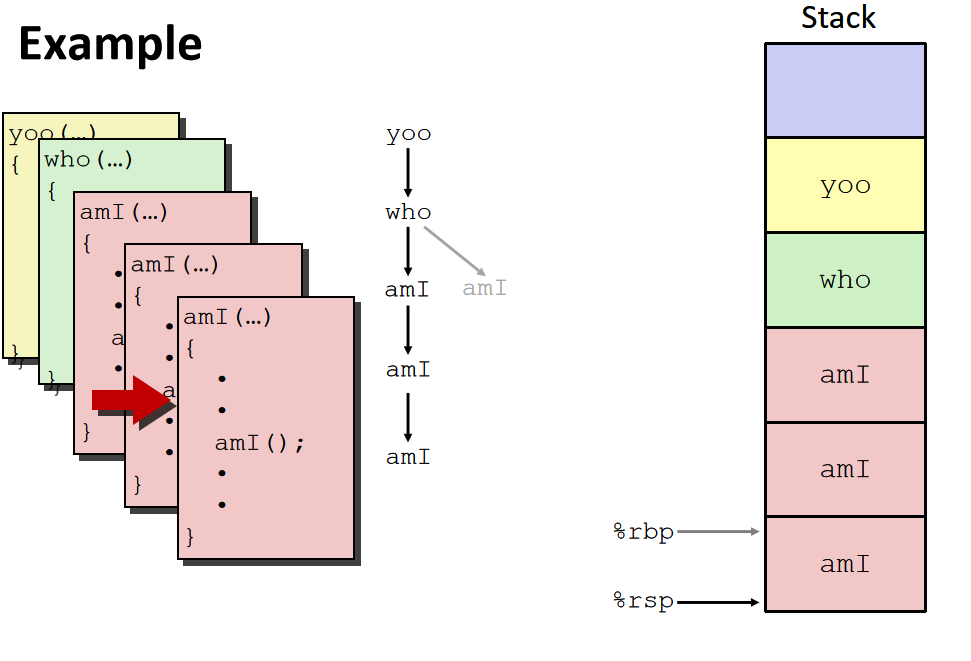
整一帧会在过程调用的时候进行空间分配,然后在返回时进行回收,在 x86-64/Linux 中,栈帧的结构是固定的,当前的要执行的栈中包括:
- Argument Build: 需要使用的参数
- 如果不能保存在寄存器中,会把一些本地变量放在这里
- 已保存的寄存器上下文
- 老的栈帧的指针(可选)
而调用者的栈帧则包括:
- 返回地址(因为
call指令被压入栈的,即调用者的下一条指令所在的地址) - 调用所需的参数
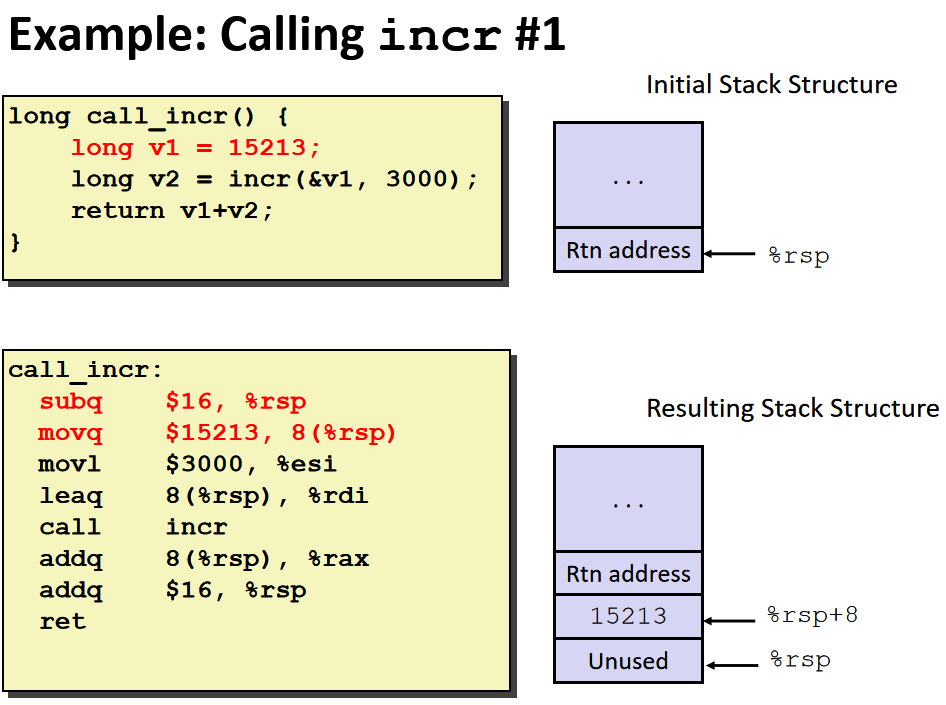
在C语言程序中需要获得v1的地址,所以我们不能将v1存入寄存器中,因为我们无法获得寄存器的地址,我们应该将15213存入内存单元中,也就是当前函数调用的stack frame中。
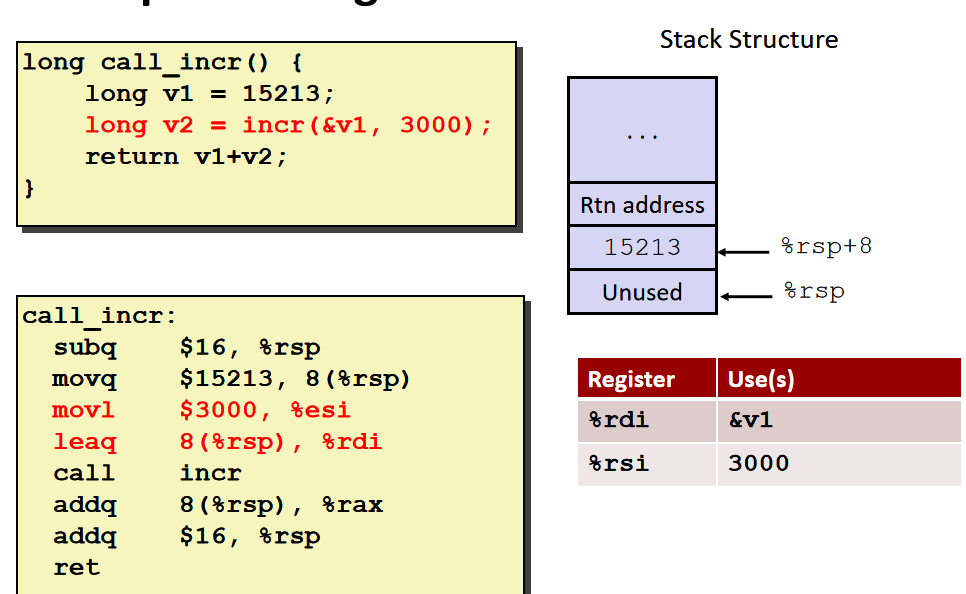
由于3000是一个足够小的32位数,所以编译器使用了movl,将它移动到32位的寄存器%esi中,当设置32位的寄存器的值时,会自动将它对应的64寄存器的高位置为0 。
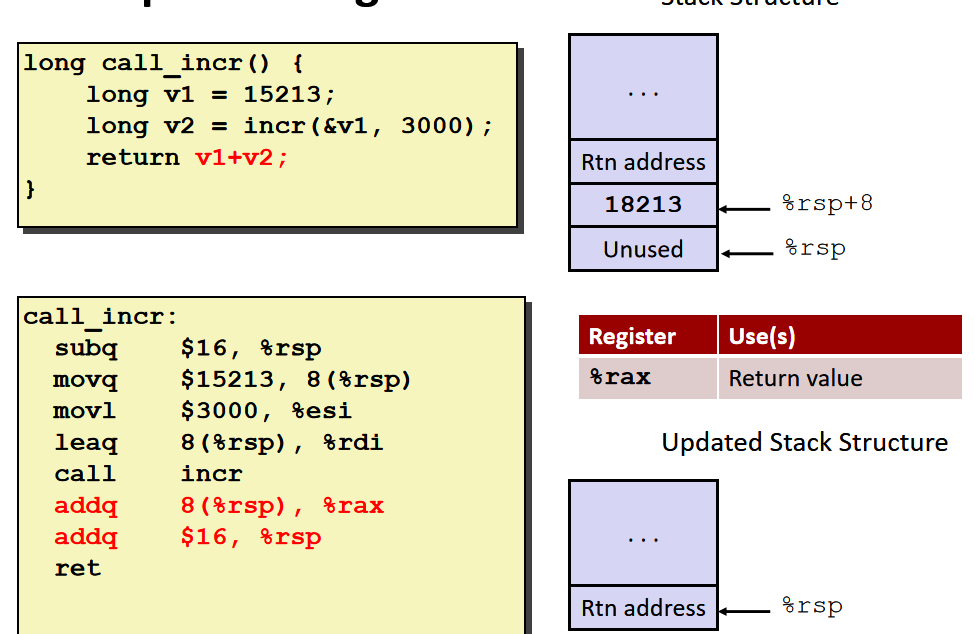
该函数执行结束后%rsp回到函数调用前的位置,编译器会计算出该函数需要多少栈空间,然后将%rsp加上占用的空间。
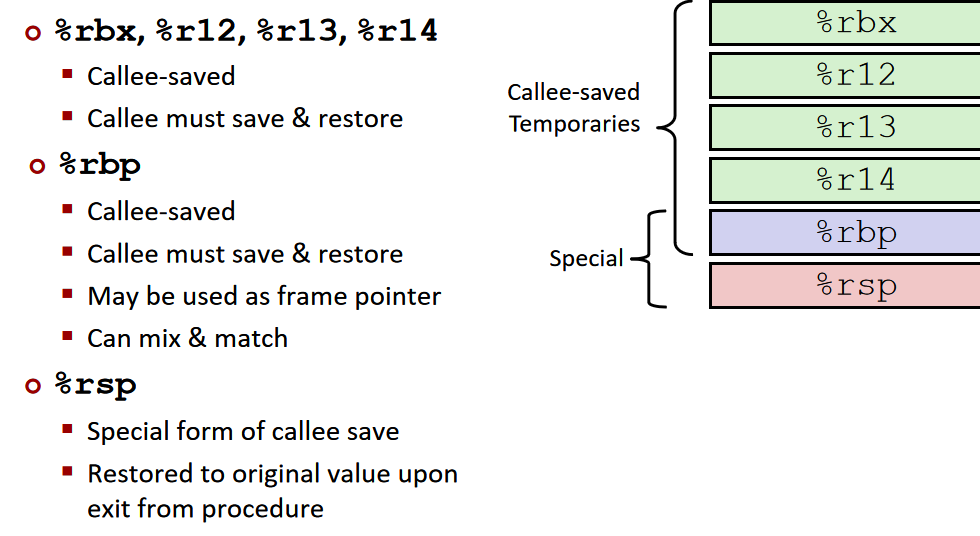
register saving convention:

-
caller saved:
-
callee saved:
Machine Level Programming 4:data
在机器级代码中没有数组这种高级概念,而是将它视作存储在连续位置上的字节的集合。C编译器的工作就是生成代码为数组分配内存

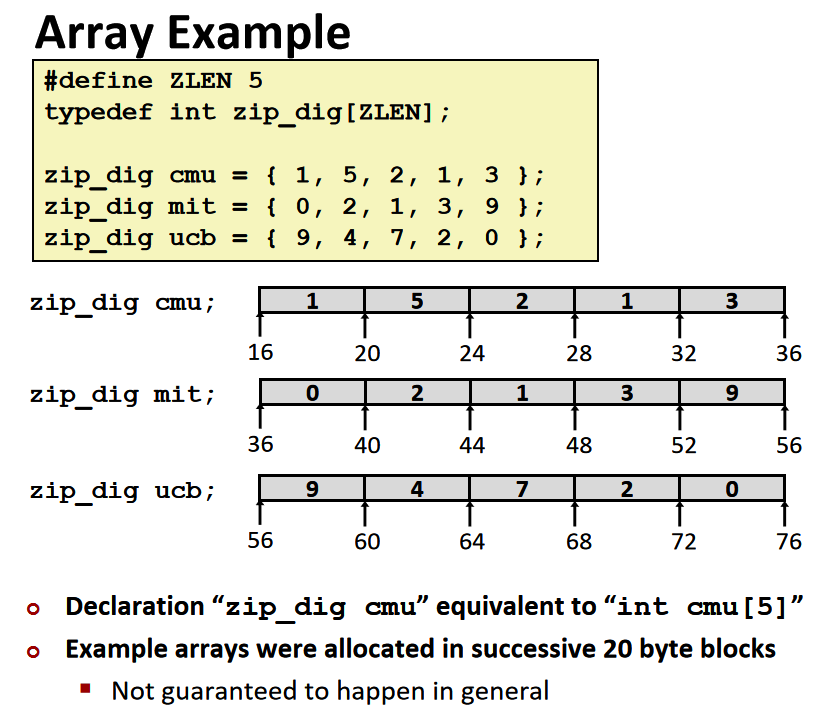
当声明数组时,我们给数组分配了数组容量大小的空间,对数组名解引用可以得到数组所在的空间。声明指针时,我们只是给指针分配了空间,即8个字节,而没有声明指针的指向,对指针解引用没有意义。
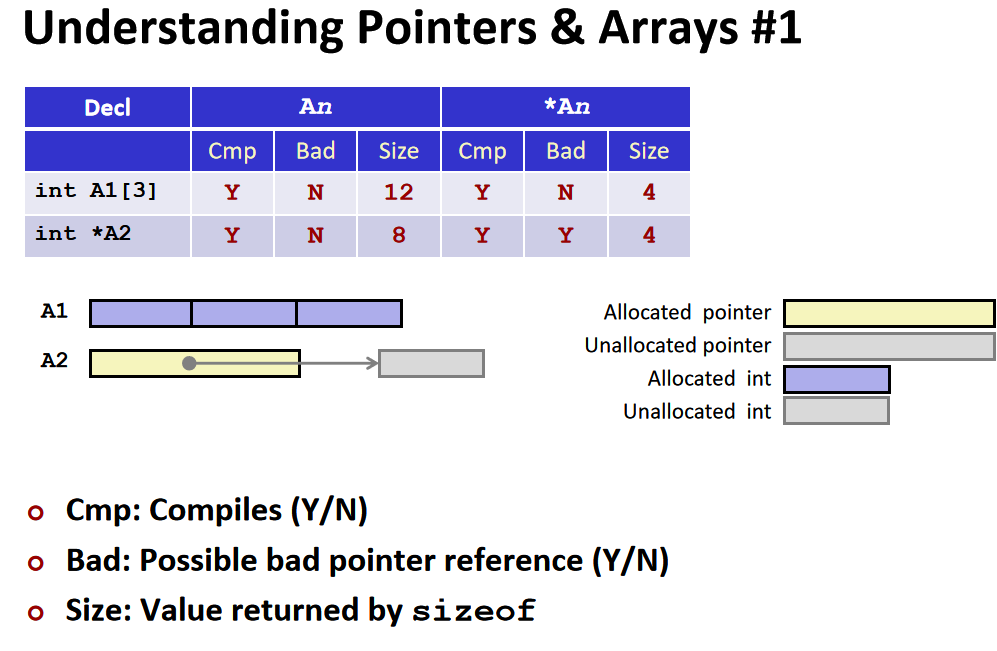
int *A2只是声明了一个指针,编译器给指针分配了8个字节的空间,但是没有初始化,所以对A2解引用会出现异常。
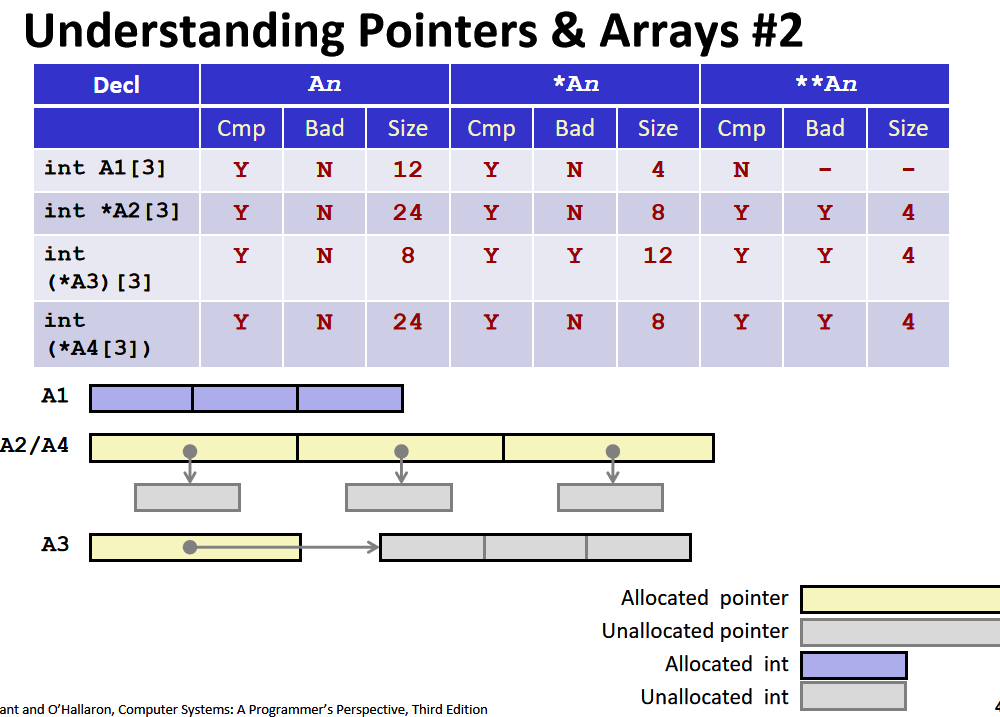
从括号内向外读,[]的优先级高于*号,所以A2和A4先和[]结合,表明A2和A4是数组,类型是int *。而A3先和 *结合,表明A3是一个指针,指向一个数组
所以第二行和第四行表示声明了一个数组,类型是指向整数的指针;第三行表示声明了一个指针,指向类型是int的数组。
空括号表示法等价于指针,因为我们没有给它初始化大小。


Structure



Alignment
内存对齐主要遵循下面三个原则:
- 结构体变量的起始地址能够被其最宽的成员大小整除
- 结构体每个成员相对于起始地址的偏移能够被其自身大小整除,如果不能则在前一个成员后面补充字节
- 结构体总体大小能够被最宽的成员的大小整除,如不能则在后面补充字节
我们有这样一个结构体:
struct rec
{
int a[4];
size_t i;
struct rect *next;
};
那么在内存中的排列是

如果我们换一下结构体元素的排列顺序,可能就会出现和我们预想不一样的结果,比如
struct S1
{
char c;
int i[2];
double v;
} *p;
因为需要对齐的缘故,所以具体的排列是这样的:

具体对齐的原则是,如果数据类型需要 K 个字节,那么地址都必须是 K 的倍数,比方说这里 int 数组 i 需要是 4 的倍数,而 v 则需要是 8 的倍数。
文中讲“具体对齐的原则是,如果数据类型需要 K 个字节,那么地址都必须是 K 的倍数”——这只是windows的原则,而Linux中的对齐策略是“2字节数据类型的地址必须为2的倍数,较大的数据类型(int,double,float)的地址必须是4的倍数”
为什么要这样呢,因为内存访问通常来说是 4 或者 8 个字节位单位的,不对齐的话访问起来效率不高。具体来看的话,是这样:
- 1 字节:char, …
- 没有地址的限制
- 2 字节:short, …
- 地址最低的 1 比特必须是
0
- 地址最低的 1 比特必须是
- 4 字节:int, float, …
- 地址最低的 2 比特必须是
00
- 地址最低的 2 比特必须是
- 8 字节:double, long, char *, …
- 地址最低的 3 比特必须是
000
- 地址最低的 3 比特必须是
- 16 字节:long double (GCC on Linux)
- 地址最低的 4 比特必须是
0000
- 地址最低的 4 比特必须是
对于一个结构体来说,所占据的内存空间必须是最大的类型所需字节的倍数,所以可能需要占据更多的空间,比如:
struct S2 {
double v;
int i[2];
char c;
} *p;

根据这种特点,在设计结构体的时候可以采用一些技巧。例如,要把大的数据类型放到前面,加入我们有两个结构体:
struct S4 {
char c;
int i;
char d;
} *p;
struct S5 {
int i;
char c;
char d;
} *p;
对应的排列是:

这样我们就通过不同的排列,节约了 4 个字节空间,如果这个结构体要被复制很多次,这也是很可观的内存优化。
Machine Level Programming 5:Advanced Topics
x86-64 Linux内存布局
x86-64的内存地址为64位,但由于硬件的限制只能实际只能使用47位。

最上面是运行时栈,有 8MB 的大小限制,一般用来保存局部变量。然后是堆,动态的内存分配会在这里处理,例如 malloc(), calloc(), new() 等。栈和堆的增长方向相反。然后是数据(data),指的是静态分配的数据,比如说全局变量,静态变量,常量字符串。最后是共享库等可执行的机器指令,这一部分是只读的。
内存分配的例子:


buffer overflow缓冲区溢出
可以见到,栈在最上面,也就是说,栈再往上就是另一个程序的内存范围了,这种时候我们就可以通过这种方式修改内存的其他部分了


之所以会产生这种错误,是因为访问内存的时候跨过了数组本身的界限修改了 d 的值。如果不检查输入字符串的长度,就很容易出现这种问题,尤其是针对在栈上有界限的字符数组。
在存储来自一条消息的字符串时,将会出现很多有关缓冲区溢出的问题。由于无法提前知道字符串的大小,所以对于已经分配的缓冲区来说,这个字符串可能会过大。引发这个问题的罪魁祸首之一就是那些存储字符串但是不检查边界情况的库函数 ,比如gets()函数,此函数的目的一般是从终端的输入中读取键入的字符串。
在 Unix 中,gets() 函数的实现是这样的:
// 从 stdin 中获取输入
char *gets(char *dest)
{
int c = getchar();
char *p = dest;
while (c != EOF && c != '\n')
{
*p++ = c;
c = getchar();
}
*p = '\0';
return dest;
}
只要gets没有遇到EOF和换行,它就会一直向缓冲添加字符。而当有人调用gets函数,他将传递一个指向已经分配好的缓冲区的指针,在该函数中没有东西限制应该读取多少字符,最后输入的字符有可能超出已分配好的缓冲区。类似的情况还在 strcpy, strcat, scanf, fscanf, sscanf 中出现
比如说
void echo() {
char buf[4]; // 太小
gets(buf);
puts(buf);
}
void call_echo() {
echo();
}
我们来测试一下这个函数,可能的结果是:
unix> ./echodemo
Input: 012345678901234567890123
Output: 012345678901234567890123
unix> ./echodemo
Input: 0123456789012345678901234
Segmentation Fault
虽然在 echo() 中声明 buf 为 4 个 char,但是输入23个数字都没问题,大于等于24就会dump
实际的汇编代码是:

我们看 4006cf 这一行,可以发现实际上给 %rsp 分配了 0x18 ,即24个字节的空间,再算上字符串末尾的’\n’,所以最多可以容纳23个数字。
在调用gets之前的内存空间如下:

在call_echo的栈帧的最低地址的位置存放的是返回call_echo的地址 4006f6,也就是调用echo的下一条指令的地址,用于返回之后继续执行。一个地址的大小为八个字节,所以分配了八个字节的空间。
在echo中,给rsp分配了24个字节的空间,四个字节的空间给buf,剩下的20个字节未使用。
我们输入字符串 01234567890123456789012 之后,栈帧中缓冲区被填充,此时虽然缓冲区溢出了,但是并没有损害当前的状态,程序还是可以继续运行(也就是没有出现Segmentation Fault)

但是如果再多一点的话,也就是输入 0123456789012345678901234,内存中的情况是这样的:

把返回地址给覆盖掉了,当 echo 执行完成要回到 call_echo 函数时,就跳转到 0x400034 这个内容未知的地址中了。也就是说,通过缓冲区溢出,我们可以在程序返回时跳转到任何我们想要跳转到的地方!攻击者可以利用这种方式来执行恶意代码!
代码注入攻击:

攻击者通过向gets中输入一串提前写好的,想要被攻击机器执行的程序exploit code(小于等于给rsp分配的空间),再输入一段无关的数据padding以填满分配的空间,此时再输入之前的exploit code 的地址B,以覆盖原本的函数返回地址。当Q执行ret指令返回时,就会直接跳转到exploit code,执行注入的代码。
缓冲区溢出攻击的要求是:攻击者必须知道缓冲区的地址,还要知道机器给rsp分配多大的空间。

避免缓冲区溢出攻击的方式
-
使用更安全的方式写代码

-
System-Level Protections提供系统层级的保护
- 随机分配栈的空间大小
- 随机移动栈的地址
让攻击者难以预测注入代码的位置。

-
将栈中的内容标记为不可执行

-
Stack Canaries
在超出缓冲区的位置加一个特殊的值,如果发现这个值变化了,那么就知道出问题了


Return Oriented Programming Attacks
返回导向编程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









