







目录
论文原文:
一、概览
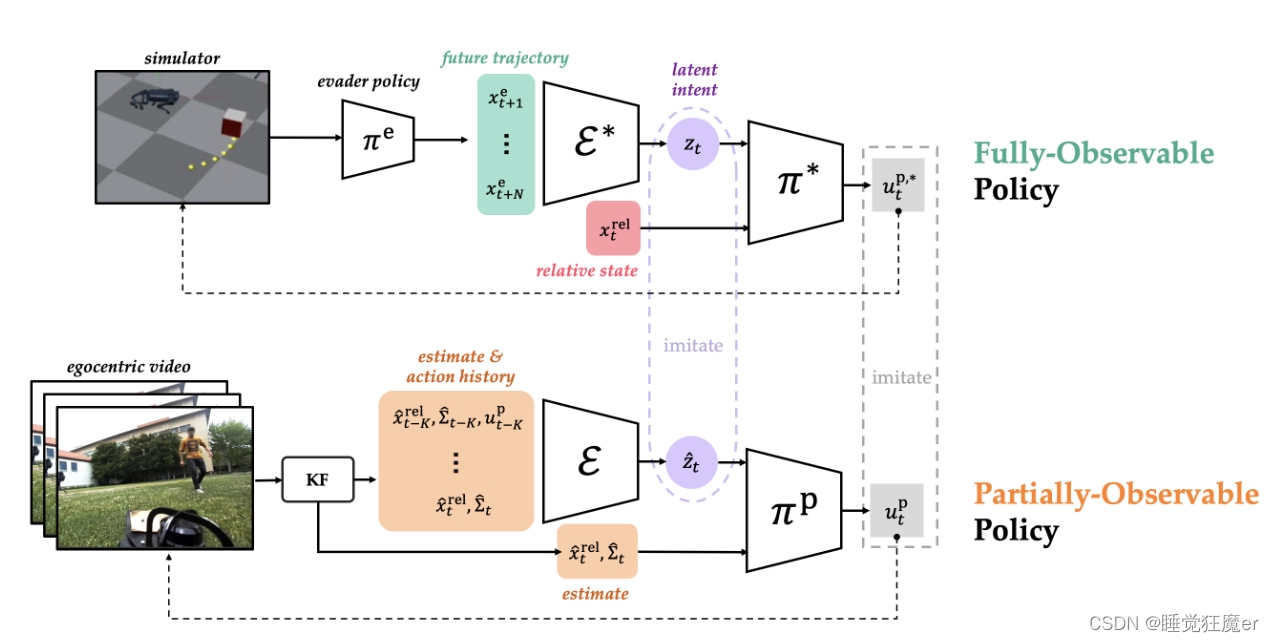
本篇论文致力于解决部分可观测条件下的四组机器人追逃博弈问题。直接使用强化学习训练智能体解决部分可观测问题是不成功的,因此论文使用特权学习的方法,将evader的未来轨迹也作为特权信息,首先在仿真环境中训练完全可观测策略
π
∗
\pi^*
π∗(fully-observable policy),并且训练一个用于预测evader未来轨迹的网络
ε
∗
\varepsilon^*
ε∗,然后使用这一组策略来监督训练机器人上的部分可观测策略
π
p
\pi^p
πp和意图预测预测网络
ε
\varepsilon
ε。通过这种方法,论文得到了难以处理的分布式部分可观测马尔可夫决策过程的最优策略的近似。
二、主要内容
2.1 问题简述
对于给定的evader策略
π
e
\pi^e
πe,pursuer的规划问题可以描述为一个有限时域的离散优化问题,目标是找到一个最优的策略
π
p
:
O
p
→
U
p
\pi^p:\mathcal O^p \to \mathcal U^p
πp:Op→Up,以最大化如下的目标函数
J
(
π
p
,
π
e
)
=
E
τ
∼
p
(
τ
∣
π
p
,
π
e
)
[
∑
t
=
0
T
γ
t
r
t
]
(1)
J(\pi^\mathrm{p},\pi^\mathrm{e})=\mathbb{E}_{\tau\sim p(\tau|\pi^\mathrm{p},\pi^\mathrm{e})}\Big[\sum_{t=0}^T\gamma^tr_t\Big] \tag{1}
J(πp,πe)=Eτ∼p(τ∣πp,πe)[t=0∑Tγtrt](1)
其中
τ
=
{
(
x
0
p
,
x
0
e
,
u
0
p
,
u
0
e
,
o
0
p
,
o
0
e
,
r
0
)
…
(
x
T
p
,
x
T
e
,
u
T
p
,
u
T
e
,
o
T
p
,
o
T
e
,
r
T
)
}
\tau=\{(x_{0}^{\mathrm{p}},x_{0}^{\mathrm{e}},u_{0}^{\mathrm{p}},u_{0}^{\mathrm{e}},o_{0}^{\mathrm{p}},o_{0}^{\mathrm{e}},r_{0})\ldots(x_{T}^{\mathrm{p}},x_{T}^{\mathrm{e}},u_{T}^{\mathrm{p}},u_{T}^{\mathrm{e}},o_{T}^{\mathrm{p}},o_{T}^{\mathrm{e}},r_{T})\}
τ={(x0p,x0e,u0p,u0e,o0p,o0e,r0)…(xTp,xTe,uTp,uTe,oTp,oTe,rT)}是在
π
e
\pi^e
πe和$
π
p
\pi^p
πp作用下得到的联合状态、动作、观测以及pursuer的奖励的轨迹,服从分布
p
(
τ
∣
π
p
,
π
e
)
p(\tau|\pi^{\mathrm{p}},\pi^{\mathrm{e}})
p(τ∣πp,πe);
γ
\gamma
γ是折扣因子。这个优化实际上是在求解一个包含两个智能体的、有限时域的、分布式、部分可观的马尔可夫决策过程(Dec-POMDP)。
记 x p ∈ R n p x^{\mathrm{p}}\in\mathbb{R}^{n_{\mathrm{p}}} xp∈Rnp是pursuer的状态, x e ∈ R n e x^{\mathrm{e}}\in\mathbb{R}^{n_{\mathrm{e}}} xe∈Rne是evader的状态。Policy π p \pi ^p πp的输入并不是所有智能体的状态,它的输出是机器人整体的线速度和角速度 u p ∈ U p u^p \in \mathcal U^p up∈Up,对于底层控制,论文采用的是预先训练好的步行控制策略。Evader同样控制自身的角速度和线速度 u e ∈ U e u^e \in \mathcal U^e ue∈Ue。 U i , i ∈ { p , e } \mathcal U^i, \ i \in\{p, e\} Ui, i∈{p,e}都是有界集。在仿真中,这一限制体现为pursuer的最大线速度是3 m/s,而evader的最大线速度是2.5 m/s。
奖励函数:pursuer的奖励函数有如下两种形式
P
u
r
s
u
i
t
:
r
t
=
−
∥
x
t
e
−
x
t
p
∥
2
2
C
a
p
t
u
r
e
:
r
T
=
α
⋅
1
{
∣
∣
x
T
e
−
x
T
p
∣
∣
2
2
≤
0.8
}
\begin{aligned} &Pursuit: r_t = -\| x_t^e - x_t^p\|_2^2\\ &Capture: r_T=\alpha\cdot\mathbb1\{||x_T^\mathrm{e}-x_T^\mathrm{p}||_2^2\leq0.8\} \end{aligned}
Pursuit:rt=−∥xte−xtp∥22Capture:rT=α⋅1{∣∣xTe−xTp∣∣22≤0.8}
这样设计的目的是让pursuer在每个时间步都追逐evader,并且尽可能在一个episode结束之前完成抓捕。
Evader的策略:由于现有的人机、机器人对机器人的追逃数据集较少,所以论文设计了三种evader的策略,分别是1)随机动作元(random motion primitives);2)多智能体强化学习(multi-agent RL);3)动态博弈。详细的evader策略设计在论文附录A.3节,感兴趣的读者可以自行阅读,本处不作赘述。
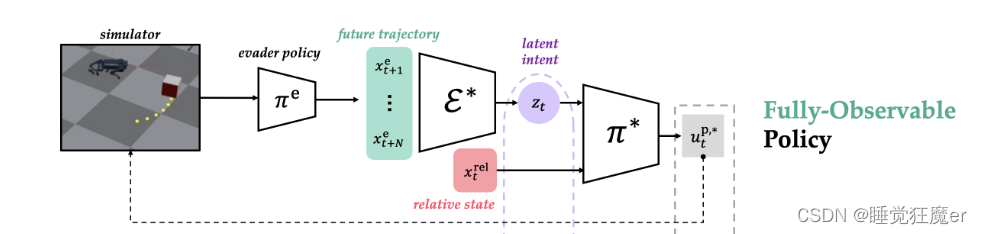
2.2 Fully-Observable Policy: Teacher
为什么要先设计一个Teacher?
如果想要实现对evader的抓捕,就要考虑它在当前和未来的行为,而evader的行为依赖于它自身的动力学和它的意图,而这些信息在实际场景中往往是难以直接获得的,因此论文先使用evader的未来行为作为特权信息,训练Teacher,再用Teacher监督部分可观测设定下的Student,从而提升Student在Partial-Observable时的性能。
完全可观测策略 π ∗ \pi^* π∗可以获得真实的pursuer和evader相对状态 x t rel x_t^{\text{rel}} xtrel以及evader的未来 N N N个状态 x t : t + N e x_{t:t+N}^\text{e} xt:t+Ne。因为pursuer的策略是从本体系的状态进行推理的,因此需要将 x t : t + N e x_{t:t+N}^\text{e} xt:t+Ne转换到相对坐标系中的 x t : t + N rel ∈ R N × 3 x_{t:t+N}^\text{rel}\in\mathbb{R}^{N\times 3} xt:t+Nrel∈RN×3。这条相对坐标系下的轨迹输入编码器 E ∗ ( x t : t + N rel ) = z t ∈ R 8 \mathcal{E}^*(x_{t:t+N}^\text{rel})=z_t\in\mathbb{R}^8 E∗(xt:t+Nrel)=zt∈R8从而学习evader意图和相对状态的低维表征。 z t z_t zt可以理解为evader未来一段时间内的表现,例如运动方向、策略类型(例如多项式轨迹的系数)以及控制量的上下界等等。在每个时间步 z t z_t zt都会被重新推理。
网络结构的设计方面,论文使用了神经元个数为[512, 256, 128]的多层感知机来构建
π
∗
\pi^*
π∗和
E
∗
\mathcal E^*
E∗。论文使用的训练算法是PPO(Proximal Policy Optimization)。
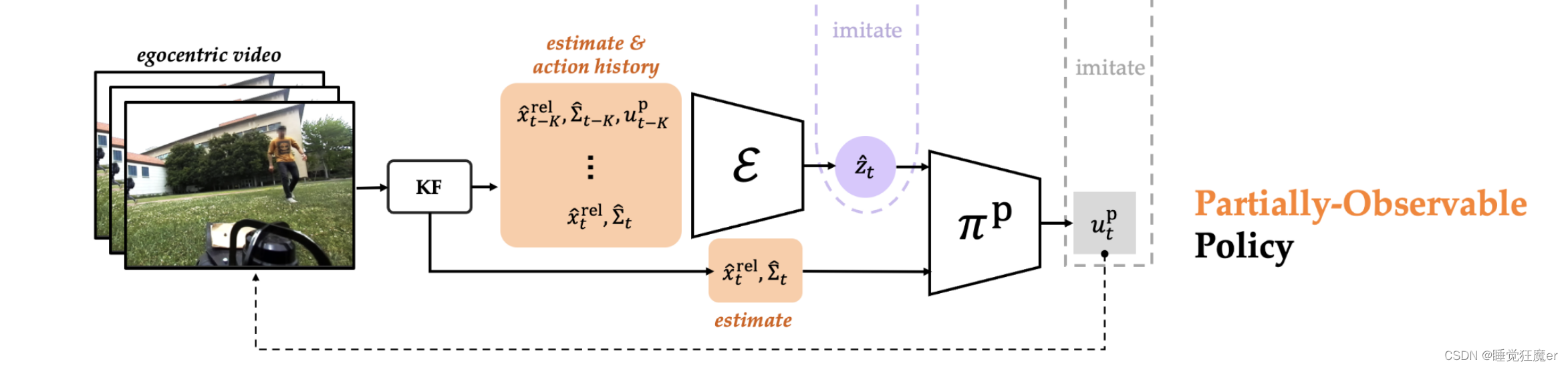
2.3 Partial-Observable Policy: Student
部分可观测策略
π
p
\pi^\text{p}
πp以RGB图像作为观测
o
t
p
∈
O
p
o_t^p \in \mathcal O^\text{p}
otp∈Op,论文使用ZED相机自带的3d物体检测算法将观测
o
t
p
o_t^p
otp转化为pursuer相机坐标系下的相对位置和航向角
y
t
∈
R
3
y_t\in \mathbb{R}^3
yt∈R3。论文使用卡尔曼滤波来估计相对状态
x
^
t
r
e
l
\hat x_t^{rel}
x^trel和对应的协方差矩阵
Σ
^
t
\hat\Sigma_t
Σ^t,其中系统模型是如下的线性系统
x
^
t
+
1
r
e
l
=
A
x
^
t
r
e
l
+
B
u
t
p
\hat x_{t+1}^{rel} = A \hat x_t^{rel} + B u_t^p
x^t+1rel=Ax^trel+Butp
这个模型在预测时是不考虑evader的策略的,相对状态的估计历史信息通过隐含意图估计网络
E
(
x
^
0
:
t
rel
,
Σ
^
0
:
t
,
u
0
:
t
−
1
p
)
\mathcal E (\hat x_{0:t}^\text{rel}, \hat \Sigma_{0:t}, u_{0:t-1}^p)
E(x^0:trel,Σ^0:t,u0:t−1p)进行编码。
论文使用了DAGGER和完全可观策略 π ∗ \pi^* π∗来监督隐含意图估计网络 E \mathcal E E和策略网络 π p \pi^p πp,策略网络的结构是神经元个数为[512, 256, 128]的多层感知机,而为了记录历史输入, E \mathcal E E使用了具有256个隐含状态的单层LSTM。
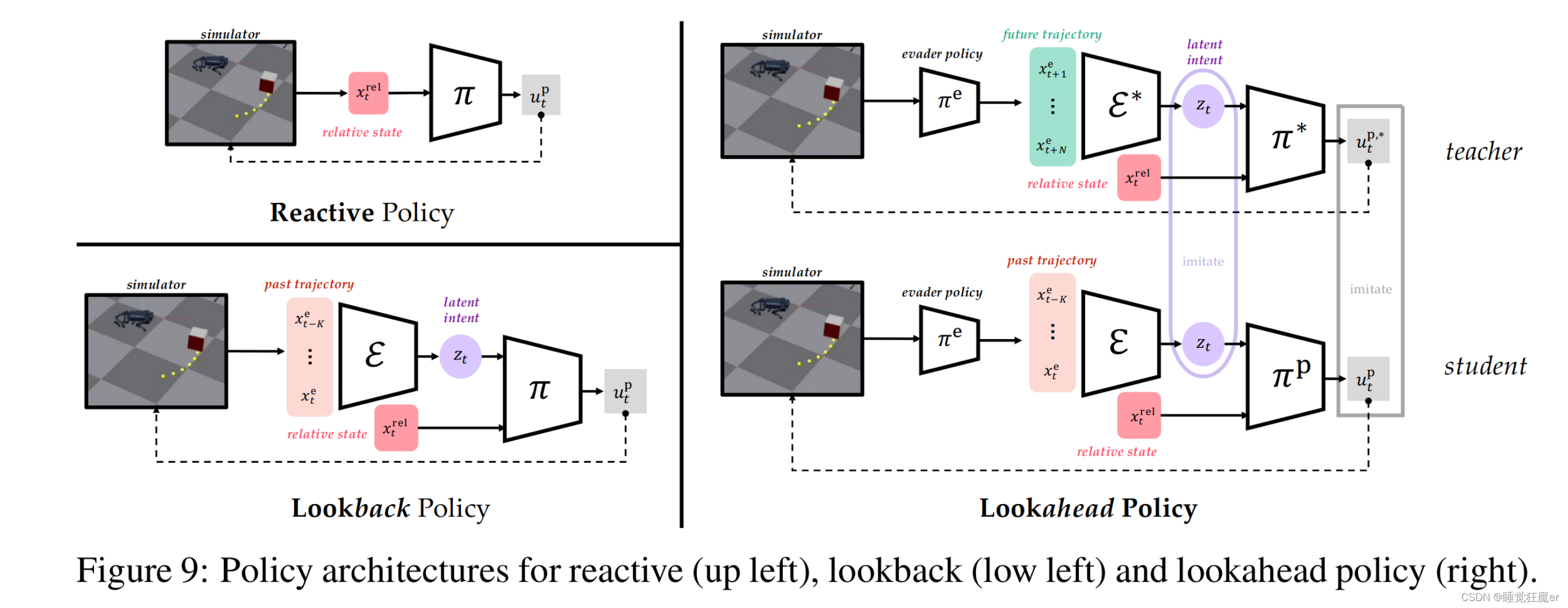
2.4 仿真实验
2.4.1 隐含意图预测网络的作用
论文里提到的特权信息主要是Evader未来时刻的轨迹信息,为了说明特权信息的有效性以及对未来轨迹预测的作用,这一部分固定Evader的策略为固定时间长度的Dubins路径,分别使用三种不同的策略来实施追逃:1)仅考虑当前时刻的相对状态的策略;2)隐含意图预测仅使用历史信息进行预测,训练过程中不使用 E ∗ \mathcal E^* E∗进行监督;3)隐含意图预测使用历史信息进行预测,训练过程中使用 E ∗ \mathcal E^* E∗进行监督。
使用这三种网络的结果如下图所示,可以看出使用未来轨迹信息进行特权学习的隐含意图估计网络能够帮助pursuer更快地实现抓捕。并且训练过程中第三种网络收敛速度也快于第二种网络。
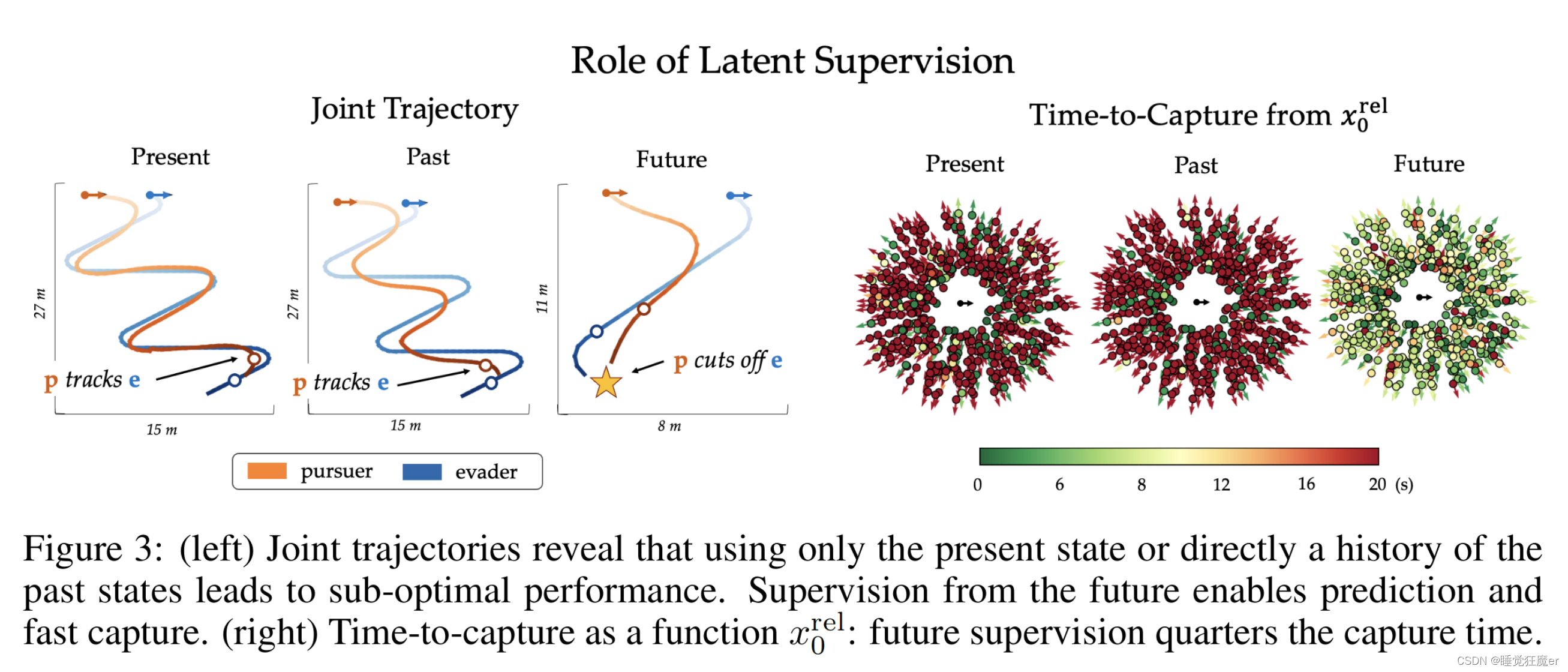
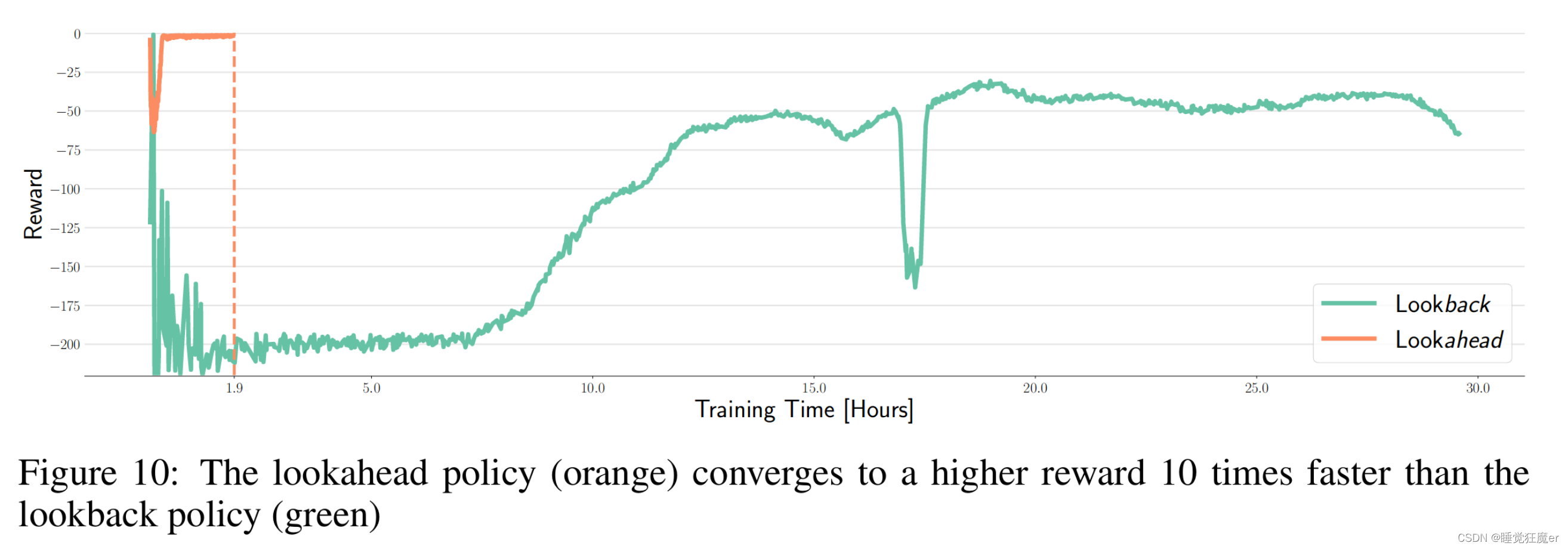
2.4.2 策略蒸馏依赖多样性与最优性的平衡
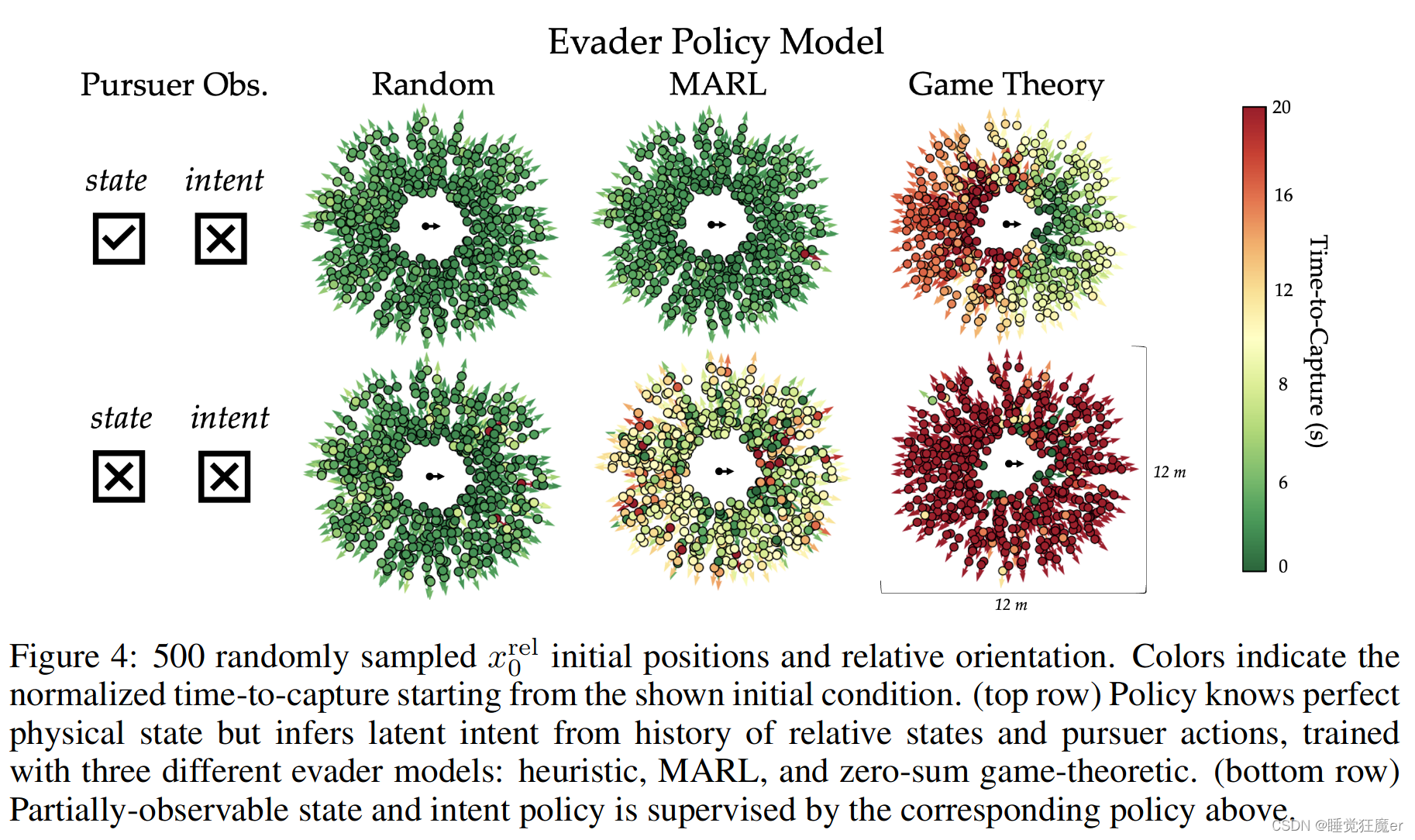
在完全可观情况下,论文采用了三种不同的Evader策略,分别是:
- 随机策略
π
r
a
n
d
e
(
t
)
\pi_{rand}^e(t)
πrande(t),从如下的动作基元
M
P
\mathcal{MP}
MP中随机采样动作并且执行一个随机采样的时间
t
t
t
V x = [ v ‾ x , 0.5 v ‾ x , 0 , 0.5 v ˉ x , v ˉ x ] V θ = [ v ‾ θ , 0.5 v ‾ θ , 0 , 0.5 v ˉ θ , v ˉ θ ] t ∼ Unif [ 1 , 3 ] \begin{aligned} V_x &= [\underline v_x, 0.5 \underline v_x, 0, 0.5 \bar v_x, \bar v_x] \\ V_\theta &= [\underline v_\theta, 0.5 \underline v_\theta, 0, 0.5 \bar v_\theta, \bar v_\theta] \\ t &\sim \text{Unif}[1, 3] \end{aligned} VxVθt=[vx,0.5vx,0,0.5vˉx,vˉx]=[vθ,0.5vθ,0,0.5vˉθ,vˉθ]∼Unif[1,3] - 多智能体强化学习策略
π
m
a
r
l
e
(
x
t
r
e
l
)
\pi_{marl}^e (x_t^{rel})
πmarle(xtrel),首先使用随机策略训练得到完全可观条件下的pursuer策略,固定pursuer策略,训练Evader策略,奖励函数设置如下:
E v a s i o n : r t = 2 ⋅ ∥ x t e − x t p ∥ 2 2 , C a p t u r e : r T = − 80 ⋅ 1 { ∥ x T e − x T p ∥ 2 2 ≤ 0.8 } Evasion:\ \ r_t = 2\cdot \| x_t^e - x_t^p\|_2^2, \;\; Capture: \ \ r_T = -80 \cdot \mathbb{1}\{ \| x_T^e - x_T^p\|_2^2 \leq 0.8 \} Evasion: rt=2⋅∥xte−xtp∥22,Capture: rT=−80⋅1{∥xTe−xTp∥22≤0.8}
训练过程中使用课程学习,在[1800, 2000, 2400, 2800, 3100, 3800]次迭代时每次增加20%的pursuer速度。
论文通过实验发现,在微分对策evader训练下的teacher策略对于student的监督起到了较差的效果,可能是由于teacher训练过程中最后收敛到了完备信息下的Nash Equilibria,但是这一条件对于partially observable的student来说难以达到。与之形成对比的是使用MARL或者在random evader训练下的teacher会对student的训练起到较好的作用。
2.4.3 覆盖范围对适应性的作用
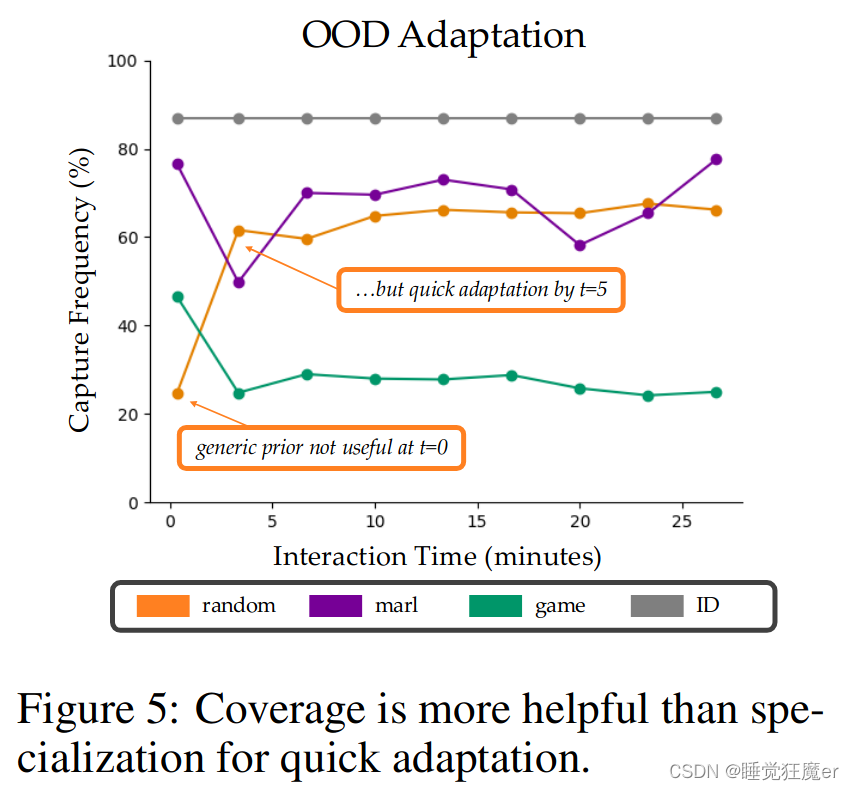
这里所说的覆盖范围指的是策略在训练时得到的对方策略的多样性,我个人理解和上一节所说的多样性是类似的概念,这里主要研究的是partially observable pursuer能多快的适应训练阶段没有出现过的evader。
论文分别使用 π r a n d p \pi_{rand}^p πrandp, π m a r l p \pi_{marl}^p πmarlp, π g a m e p \pi_{game}^p πgamep的partially observable evader追逐使用Dubins’路径的evader。在追逐过程中使用对应的teacher中的encoder E ∗ \mathcal E^* E∗对student的 E \mathcal E E进行微调。由于 π r a n d p \pi_{rand}^p πrandp在训练过程中从random的evader’s policy中学习到了比较好的意图表示,因此在训练过程中虽然初始的抓捕频率较低,但是在交互的第五分钟时就已经快速收敛。 π m a r l p \pi_{marl}^p πmarlp开始阶段比较好,但是由于训练时的evader采用MARL策略,pursuer‘s policy对evader的运动有一些先验信息的依赖,因此花了稍长的时间也适应了从未见过的evader’s policy。而 π g a m e p \pi_{game}^p πgamep则由于其先验依赖过强,在其他方法适应后仍表现出较差的抓捕频率。
2.5 实物实验
实物实验方面,论文分别设计了四足对人或者四足对四足的追逃实验。从笔者的直观感受来看,实物实验的效果并没有论文的仿真效果好,可能是受限于目标检测与卡尔曼滤波的性能限制,也有可能是不光在teacher与student之间存在比较大的gap,在sim和real之间还存在一些没有被充分考虑的部分可观测性质。感兴趣的读者可以自行访问项目主页(vision-based-pursuit)查看实物实验视频。
三、创新点
- 使用完全可观测的策略监督部分可观测策略的训练,从而避免了直接求解Dec-POMDP问题。
- 将Evader的未来轨迹作为特权信息,训练能够预测未来轨迹的隐含意图估计网络,并使用这个网络监督部分可观测情形下的隐含意图估计网络。
后记
由于笔者的拖延症以及其他各种事务,这篇博客写的时间很长,在创作过程中发现了一些DEMO效果更好的论文,这篇博客分享的论文其实实物效果相对来说不算很好,感兴趣的读者可以继续阅读:https://gonultasbu.github.io/pursuit-evasion/。笔者在阅读完毕之后可能也会出一期博客来分享这篇论文。
另外在这个过程中笔者还在文献调研中找到了一些使用RL做多智能体博弈的比较好的工作,但是大部分应用类的论文都采用MADDPG、MAPPO等方法,这种方法的Actor-Critic架构要求训练时必须有一个中心的Critic能够获取博弈双方各智能体的action和state,如果读者有多智能体控制的研究背景,很容易发现这种架构存在如下的缺陷:
- 需要中心节点
- 需要博弈对方的动作/控制量
目前已经有一些使用分布式训练分布式执行的架构来推进RL在博弈中应用的工作,但是可以改进的点仍有很多,希望本篇博客能够给读者带来一些启发。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









