






一、算法介绍
逻辑回归模型是一种判别概率模型,直接学习条件概率分布 P(Y | X)作为预测模型。
· 二元逻辑回归模型:
设 x = {x1, x2, ……, xn} 为输入, Y = {0, 1}为输出,w = {w1, w2, ……, wn}和b是参数。
对于给定的输入x,可以求得P(Y = 1 | X = x)和P(Y = 0 | X = x),比较这两个条件概率的大小,将实例x分到概率较大的类。
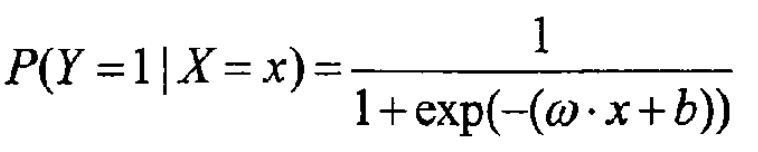
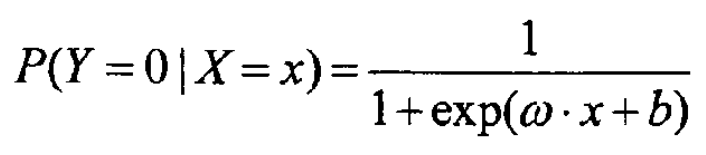
· 参数估计:
此部分参考博客https://blog.csdn.net/zouxy09/article/details/20319673的推导
假设我们有n个独立的训练样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1},则似然函数如下所示。
显然,我们要让模型最大化地满足训练集,即最大似然估计,因此要求使得L(θ)最大的θ。

通过上述推导可知,对应的梯度上升算法如下:
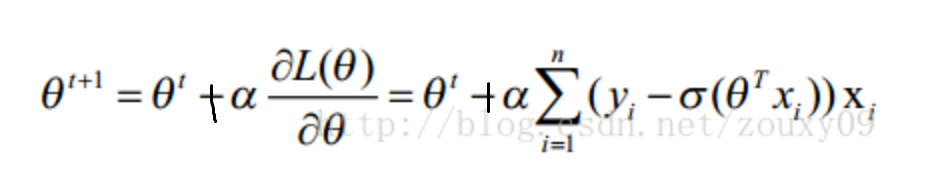
这里我们使用随机梯度上升,即一次仅用一个样本点的回归误差来更新回归系数。
这样,每次梯度上升的值为 α ×(y - y.hat)× xi,其中α为更新速率,y是标签(0或1),y.hat是sigmoid计算出来的概率 P(Y = 1 | X = xi),y - y.hat即为损失,xi为该文本的特征向量。
二、代码实现
这里使用酒店评价中文数据集,分为积极、消极两类。训练集共有评价6000条左右,测试集共有评价202条。积极、消极评论各占一半。
· 数据预处理函数textprocess.py:
# coding=utf-8
import os
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
class Textprocess:
def __init__(self):
# 原始语料库路径
self.corpus_path = ''
self.neg_path = ''
self.pos_path = ''
self.data_list = []
self.label_list = []
def preprocess(self):
dir_list = os.listdir(self.corpus_path)
for mydir in dir_list:
if mydir == 'neg':
save_path = self.neg_path
elif mydir == 'pos':
save_path = self.pos_path
class_path = self.corpus_path + '/' +mydir + '/'
files = os.listdir(class_path)
for file in files:
file_path = class_path + file
with open(file_path, 'r',encoding='gb18030', errors='ignore') as f:
file_content = f.read()
corpus_array = file_content.splitlines()
corpus = ''
for line in corpus_array:
line = line.strip()
corpus += line
corpus += '\n'
with open(save_path, 'a+', encoding='gb18030', errors='ignore') as f:
f.write(corpus)
def segment(self,pospath, segpath):
f = open(pospath, 'r', encoding='gb18030', errors='ignore')
for line in f.readlines():
seg_line = jieba.cut(line,cut_all=False)
seg_line = ' '.join(seg_line)
with open(segpath, 'a+', encoding='gb18030', errors='ignore') as save_file:
save_file.write(seg_line)
f.close()
# path1 为训练集neg分词结果
# path2 为训练集pos分词结果
def data_set(self, path1, path2):
f = open(path1, 'r', encoding='gb18030', errors='ignore')
for line in f.readlines():
self.data_list.append(line)
self.label_list.append('0')
f.close()
f = open(path2, 'r', encoding='gb18030', errors='ignore')
for line in f.readlines():
self.data_list.append(line)
self.label_list.append('1')
def getstopword(self,stopword_path):
stop_file =open(stopword_path,'rb')
stop_content = stop_file.read()
stopword_list = stop_content.splitlines()
stop_file.close()
self.stopword_list = stopword_list
def tfidf_set(self):
vectorizer = TfidfVectorizer(stop_words=self.stopword_list,sublinear_tf = True, max_features =10000)
self.vectorizer = vectorizer
# tf-idf 权重
tfidf = vectorizer.fit_transform(self.data_list)
self.weight = tfidf
# 获得词库
self.myvocabulary = vectorizer.vocabulary_
· 逻辑回归函数logistic_regression.py:
import textprocess
import math
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import numpy as np
train = textprocess.Textprocess()
train_neg_seg = r'.\酒店评价\train_neg_seg'
train_pos_seg = r'.\酒店评价\train_pos_seg'
train.data_set(train_neg_seg, train_pos_seg)
train.getstopword('stopword.txt')
train.tfidf_set()
myvocabulary = train.myvocabulary
train_tfidf = pd.DataFrame(train.weight.toarray(),columns=train.vectorizer.get_feature_names())
train_weight = train_tfidf.values
train_label = train.label_list
test = textprocess.Textprocess()
test_pos_seg = r'.\酒店评价\test_pos_seg'
test_neg_seg = r'.\酒店评价\test_neg_seg'
test.data_set(test_neg_seg, test_pos_seg)
vectorizer = TfidfVectorizer(vocabulary = myvocabulary)
test_tfidf = vectorizer.fit_transform(test.data_list)
test_weight = pd.DataFrame(test_tfidf.toarray(),columns=vectorizer.get_feature_names())
test_weight = test_weight.values
test_label = test.label_list
# 训练集样本数为5798,特征数为10000
num_samples = 5798
num_feature = 10000
weight = np.array([1 for i in range(num_feature)])
bias = 1
max_iter = 500
lr = 0.01
# 计算概率
def sigmoid(x,w,b):
return 1.0 / (1 + math.exp(-(np.dot(x,w) + b)))
def train_model(w, b):
for i in range(max_iter):
for j in range(num_samples):
output = sigmoid(train_weight[j, :], w, b)
error = int(train_label[j]) - output
w = w + lr * train_weight[j, :] * error
b = b + lr*error
return w, b
def predict(new_w, new_b):
count = 0
test_sum = len(test_weight)
for i in range(test_sum):
output = sigmoid(test_weight[i, :], new_w, new_b)
if output > 0.5:
precision = 1
else:
precision = 0
if precision == int(test_label[i]):
count += 1
return float(count) / test_sum
new_w, new_b = train_model(weight, bias)
acc = predict(new_w, new_b)
print(acc)
最终正确率为0.8465346534653465。
三、多元逻辑回归(未完待续)














 6309
6309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









